







如果您是要做交通轨迹方面的研究,那么地图匹配你一定会遇到,因为要进行后续研究,在数据预处理阶段,必须要做的工作之一就是地图匹配,现在地图匹配算法已经很成熟了,并且已存在开源的代码可用了,那么本文主要就是把从数据,到算法到程序这整个环节走通,做一个总结。
开源地图-OpenStreetMap
OpenStreetMap(OSM)是一款由网络大众共同打造的免费开源、可编辑的地图服务。它是利用公众集体的力量和无偿的贡献来改善地图相关的地理数据。作为一个开源地图,虽然国内数据还不是很完善,但是不管怎样能从上面直接下载地图数据呀,真是极大的方面的我们的生活可科学研究。如果没有他,还真是寸步难行。
下面首先介绍介绍一下如何下载openstreemap的数据,然后介绍一下它的数据格式。
下载数据
在openstreet官网点击导出,然后选择都市摘录,对于中国,里面有北京,上海,广州,成都,重庆等大城市可供下载。我们选择下载北京的数据。

有四中类型的数据,然后数据格式有SHAPEFILE,GEOJSON,OSM PBF,OSM XML等,需要什么样的数据以及什么格式的数据,点击下载即可。
下载之后,如果想要查看数据,这里介绍一个工具QGIS,我下载的数据为beijing_china.osm2pgsql-geojson,里面有三个layer的数据,分别为:
- beijing_china_osm_line.geojson
- beijing_china_osm_point.geojson
- beijing_china_osm_polygon.geojson
如果,我们想要查看每个层数据可视化是怎样的,就可以用QGIS
beijing_china_osm_line.geojson :
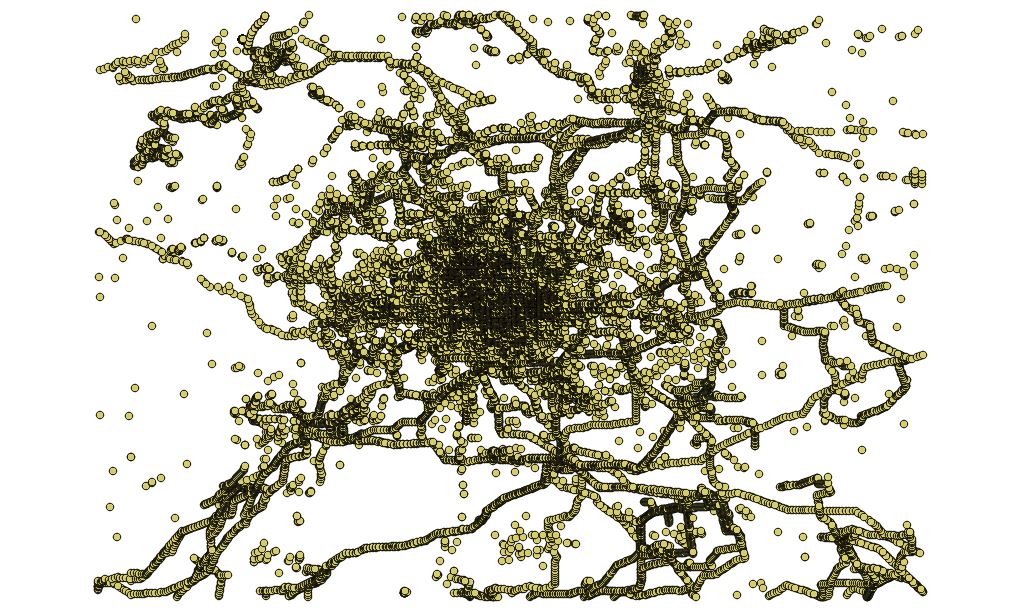
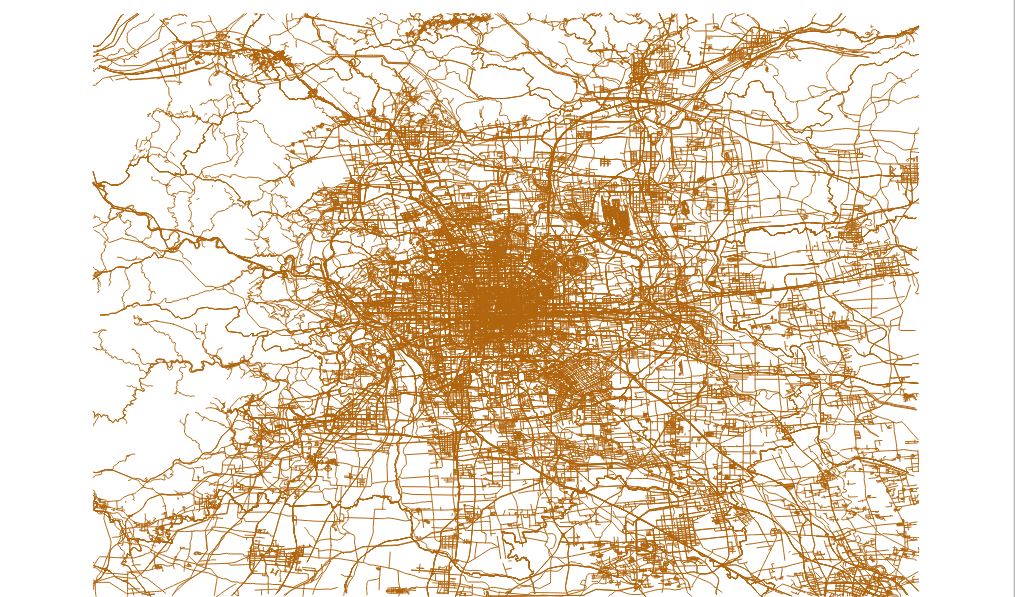
beijing_china_osm_line.geojson :
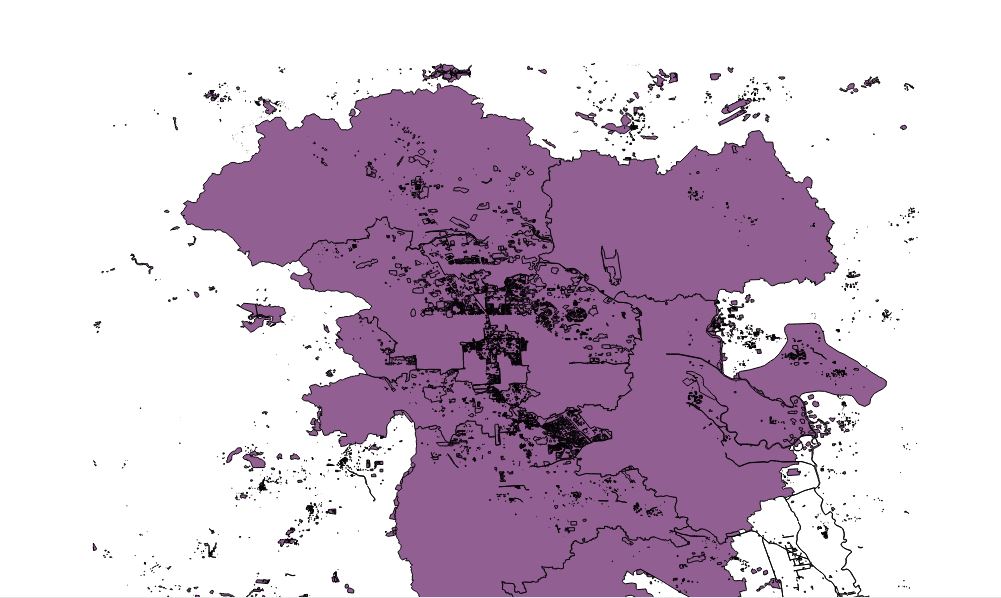
beijing_china_osm_polygon.geojson:
这样能可视化,是不是很方便,对于数据的介绍可以参考这篇博客: OpenStreetMap初探(二)——osm的数据结构
地图匹配算法
关于地图匹配算法介绍的不错的博客有:
地图匹配实践
基于隐马尔可夫的地图匹配算法
上面两篇博客很不错,尤其是第二篇,有兴趣可看看!
地图匹配就是,把车辆的行驶轨迹和电子地图数据库中的道路网进行比较,在地图上找出与行驶轨迹最相近的路线,并将实际定位数据映射到直观的数字地图上。
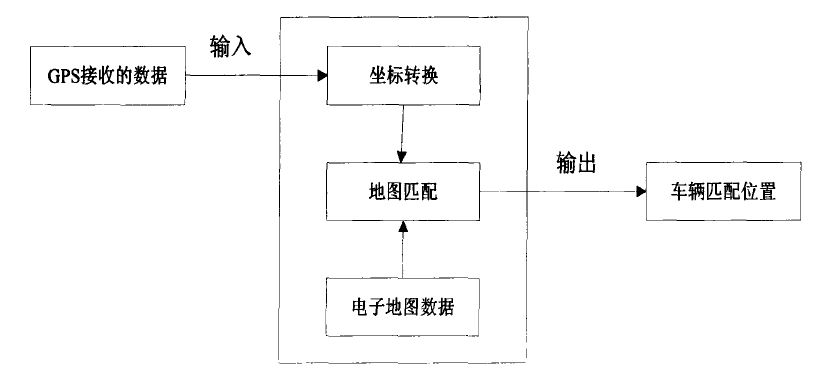
常用方法:
1、基于几何的方法
点到点,点到线,线到线
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









