








上一篇文章我们讲到了ArrayList的实现,如果你有兴趣看源码的话会发现我们的实现有一部分就是照着源码拷贝的。从实现上我们知道了ArrayList的底层实现是数组,比数组方便的是可以自动扩容,可以存放任意类型。既然实现是数组那么数组有的优点他也有,比如访问数据快捷方便,直接访问下标值,访问第一个和第500个数据访问速度差不多。直接定位下标0或者下标499取值。同时它也有一些缺点,比如修改、删除数据比较麻烦,需要循环遍历所有数据,超出数组下标还要新建数组重新拷贝原数组。
我们知道LInkedList的实现原理是链表,使用链表实现的好处是添加和删除数据方便,但同时查找就比较困难。
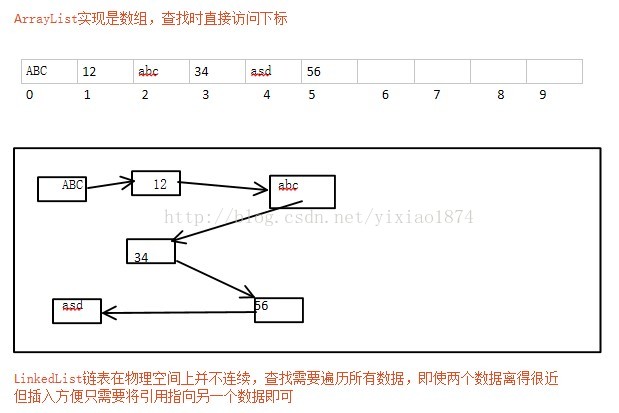
首先介绍一下链表,链表由一个一个的节点组成,每个节点就是一个对象,链表就是一个一个连起的对象,每个节点包含两部分信息,一部分是它本身需要存储的信息,如上图中的ABC、12、34,他本身是对象,自身又包含一个对象。另一部分信息是存储了该节点下一个节点的引用。你可以把链表想象成火车,每一节车厢就是一个节点,每个车厢存放着一些货物(信息)同时又与其他车厢联系。
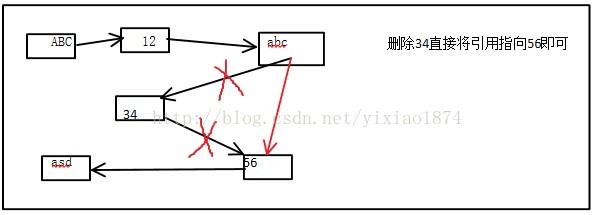
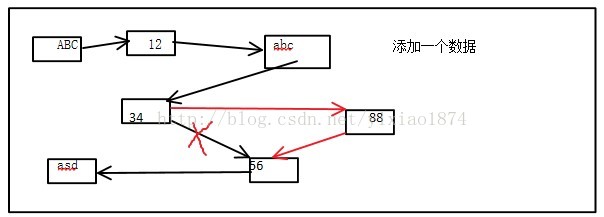
下面我们来动手实现LInkedList,常用方法跟ArrayList差不多,我们也是只实现这些方法。
public class MyLinkedList {
private Node head;
private Node tail;
int size;
//添加功能,先判断是否有元素,没有的话建立第一个元素,有的话往后面添加
public void add(Object obj){
Node n = null;
if(head==null){
n.obj= obj;
n.next = null;
n.prev = null;
tail = n;
head = n;
}else{
n.prev = tail;
n.obj = obj;
tail = n;
}
size++;
}
public Nodenode(int index){
Node temp = null;
if(head != null ){
temp = head;
for(int i = 0 ; i < index; i++){
temp = temp.next;
}
}
return temp;
}
//get()方法,需要循环遍历,比ArrayList慢
public Object get(intindex){
check(index);
Node temp = node(index);
if(temp!=null){
return temp.obj;
}else{
return null;
}
}
//下标检查
private void check(int index) {
if(index<0 || index >=size){
try {
throw new Exception();
} catch (Exceptione) {
e.printStackTrace();
}
}
}
//移除方法,直接改变引用的指向
public void remove(int index){
Node temp = node(index);
if(temp!= null){
Node up = temp.prev;
Node down = temp.next;
up.next = down;
down.prev = up;
}
size--;
}
}
//节点类包含一个Object对象信息,以及前一个节点和后一个节点的引用
class Node{
public Node(Objectobj, Node next, Node prev) {
super();
this.obj = obj;
this.next = next;
this.prev = prev;
}
public Objectobj;
public Node next;
public Node prev;
}














 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









