







构造简单驱动在内核态死循环场景,第二个write_lock在当前cpu上一直自旋(线程处于R状态),造成内核soft lockup,
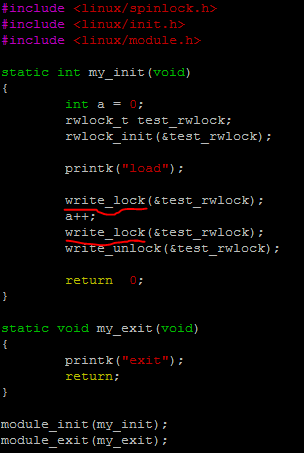
238214 root 20 0 13240 1964 1832 R 100.0 0.0 5124099h insmod
[275512.284998] watchdog: BUG: soft lockup - CPU#11 stuck for 22s! [insmod:238214]
[275512.285665] RIP: 0010:queued_write_lock_slowpath+0x4f/0x80
[275512.285675] Call Trace:
[275512.285676] ? 0xffffffffc0943000
[275512.285678] _raw_write_lock+0x1e/0x30
[275512.285680] my_init+0x48/0x70 [test_rwlock]
[275512.285682] do_one_initcall+0x51/0x1b0
[275512.285684] ? kmem_cache_alloc_trace+0xa0/0x1c0
[275512.285685] do_init_module+0x60/0x205
[275512.285688] load_module+0x21b6/0x2950
[275512.285690] ? m_show+0x1c0/0x1c0
[275512.285693] SYSC_finit_module+0xa9/0x100
[275512.285696] SyS_finit_module+0xe/0x10
[275512.285698] do_syscall_64+0x6c/0x1b0
[275512.285699] entry_SYSCALL64_slow_path+0x25/0x25
此时用kill -6,-9均无法将该线程杀死,其中缘由涉及到内核对信号(signal)的处理机制,
先理论分析一下内核线程应不应该被kill -9信号杀死。
假设一个内核线程获取了一个mutex锁后由于某种原因进入了sleep状态(可能是要获取另一个锁,如mutex,因获取不到而睡眠等待),而这个时候向该线程发送一个kill -9信号,系统先把kill信号挂载到该线程的pending list上,然后信号的后续发送流程中会将该线程唤醒,然后该线程在内核态继续运行,然后在他运行过程中被一个中断打断(还没有运行到释放mutex锁的代码之前被打断),然后处理完中断从中断返回内核态(该线程在被中断前在内核态运行,所以中断返回后也是返回内核态)的路径中,内核发现该线程pending list上挂的有未处理的信号,就处理kil -9的信号将该线程杀死。该线程被杀死后就再无机会释放他之前获取到的mutex锁,其他等待该锁的线程就再无机会被唤醒(正常是被该线程调用muetx_unlock释放锁时唤醒)并获取该锁。这样内核就变得紊乱了。
通过实际代码分析,实际也是这样,
对于处于运行状态(TASK_RUNNING)的线程,信号发送后挂到目标线程的信号队列,进程返回用户态的时候在 do_notify_resume() 中处理信号。对一个线程发送一个信号以后,并没有硬中断发生,只是简单把信号挂载到目标线程的信号 pending 队列上去,信号真正得到执行的时机是线程执行完异常/中断返回到用户态的时刻,如下图示:
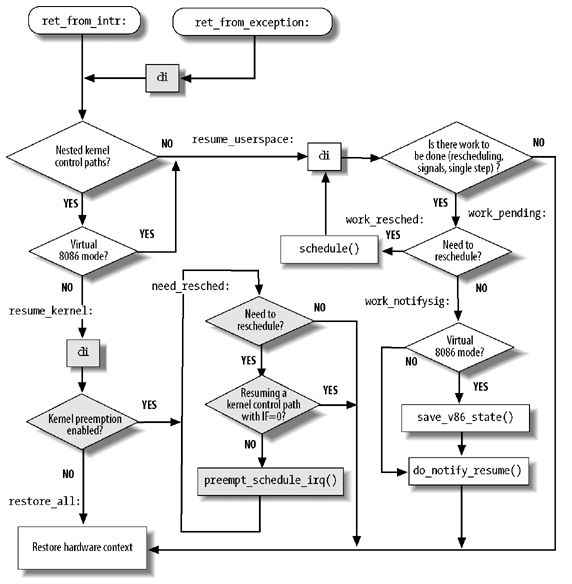
让信号看起来是一个异步中断的关键就是,正常的用户进程是会频繁的在用户态和内核态之间切换的(这种切换包括:系统调用、缺页异常、系统中断…),所以信号能很快的能得到执行。但这也带来了一点问题,内核进程是不响应信号的,除非它刻意的去查询。所以通常情况下我们无法通过kill命令去杀死一个内核进程。
对于阻塞状态的进程又怎么样来响应信号呢?
让一个进程进入阻塞状态,我们可以选择让其进入可中断(TASK_INTERRUPTIBLE)或者不可中断(TASK_UNINTERRUPTIBLE)状态,比如 mutex 操作分为 mutex_lock() 和 mutex_lock_interruptible()。所谓的可中断和不可中断就是说是否可以被中断信号打断:如果进程处于可中断(TASK_INTERRUPTIBLE)状态,信号发送函数会直接唤醒进程,让进程处理完内核态操作去返回用户态,让进程迅速去执行信号处理函数;如果进程处于不可中断(TASK_UNINTERRUPTIBLE)状态俗称为 D 进程,信号只会挂到信号队列,但是没有机会去立即执行。
kernel/signal.c:
- __send_signal() -> complete_signal() -> signal_wake_up() -> signal_wake_up_state()
参考:
http://kernel.meizu.com/linux-signal.html
https://www.oreilly.com/library/view/understanding-the-linux/0596005652/ch04s09.html

















 1540
1540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









