







一.安装Zookeeper(Kafaka依赖于zookeeper进行服务注册和管理)
1. 1 下载zookeeper:http://mirror.bit.edu.cn/apache/zookeeper/
1.2 解压 zookeeper-3.4.12 到 D:\software\zookeeper-3.4.12
1.3 复制D:\software\zookeeper-3.4.12\conf\zoo_sample.cfg并命名为:zoo.cfg
1.4 修改zoo.cfg配置文件的dataDir为:D:\software\zookeeper-3.4.12\data(手动创建data文件夹),修改端口clientPort为:12181(如果2181端口未被占用,则不需要进行端口修改)
1.5 配置zookeeper的环境变量:ZOOKEEPER_HOEM=D:\software\zookeeper-3.4.12,并编辑PATH,在变量值末尾添加: ;%ZOOKEEPER_HOEM%\bin;
1.6 启功zookeeper服务,打开cmd窗口输入:zkServer命令启动zookeeper服务
(无报错信息,则说明启动成功,图略)
二. 安装Kafka
2.1 下载kafka: http://kafka.apache.org/downloads.html
2.2 解压kafka 到 D:\software\kafka_2.11-2.1.0
2.3 在kafka_2.11-2.1.0目录下手动创建logs文件夹
2.4 修改配置文件:D:\software\kafka_2.11-2.1.0\config\server.properties中的log.dirs 为D:\software\kafka_2.11-2.1.0\logs,若zookeeper修改了默认端口,则还需要修改server.properties中zookeeper.connect 为 localhost:12181
2.5 启动kafaf服务:进入kafa的安装目录,在当前目录下新建cmd窗口:
输入一下命令:.\bin\windows\kafka-server-start.bat .\config\server.properties
(无报错信息,则说明启动成功,图略)
三. 测试
3.1 新建名称为test 的topics ,进入D:\software\kafka_2.11-2.1.0\bin\windows\目录,在当前目录下新建cmd窗口,并输入:
kafka-topics.bat --create --zookeeper localhost:12181 --replication-factor 1 --partitions 1 --topic test
3.2 新建消息生产者,进入D:\software\kafka_2.11-2.1.0\bin\windows\目录,在当前目录下新建cmd窗口,并输入:
kafka-console-producer.bat --broker-list localhost:9092 --topic test
3.3 新建消息消费者, 进入D:\software\kafka_2.11-2.1.0\bin\windows\目录,在当前目录下新建cmd窗口,并输入:
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test
测试结果:
在product窗口输入的信息,同时会显示在consumer窗口内。
Kafka简介
由Scala和Java编写,Kafka是一种高吞吐量的分布式发布订阅消息系统.
术语介绍
- Broker : Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic : 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition : Partition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer : 负责发布消息到Kafka broker
- Consumer : 消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group : 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
消费模式
为了照顾对MQ不是很了解的同学,先讲一下MQ的原理.一般MQ都是在服务端存储一个队列.生产者把消息丢到MQ server,消费者从MQ server消费.这样一来解决了生产者和消费者的高耦合问题,同时也解决了生产速度和消费速度差异导致的消费者跟不上生产者的生产速度而导致的消费者压力过大问题.
在kafka中的topic就是一系列队列的总称,称为一个主题.当然ActiveMQ和RabbitMQ中都有这个概念.一类消息都会丢到一个topic中去.
讲完topic我们讲一下partition(分区),这个东西是kafka独有的东西,也是kafka实现横向扩展和高并发的一个重要设计.我们试想一下,如果每个topic只有一个队列,随着业务增加topic里消息越来越多.多到一台server装不下了怎么办.为了解决这个问题,我们引入了partition这个概念.一个partition(分区)代表了一个物理上存在的队列.topic只是一组partition(分区)的总称,也就是说topic仅是逻辑上的概念.这样一来当topic上的消息越来越多.我们就可以将新增的partition(分区)放在其他server上.也就是说topic里边的partition(分区)可以分属于不同的机器.实际生产中,也基本都是这样玩的.
这里说一个特殊情况,有时我们创建了一个topic没有指定partition(分区)数量或者指定了partition(分区)数量为1,这时实际也是有一个默认的partition(分区)的,名字我忘记了.
从Producer(生产者)角度,一个消息丢到topic中任务就完成了.至于具体丢到了topic中的哪个partition(分区),Producer(生产者)不需要关注.这里kafka自动帮助我们做了负载均衡.当然如果我们指定某个partition(分区)也是可以的.这个大家官方文档和百度.
接下里我们讲Consumer Group(消费组),Consumer Group(消费组)顾名思义就是一组Consumer(消费者)的总称.那有了组的概念以后能起到什么作用.如果只有一组内且组内只有一个Consumer,那这个就是传统的点对点模式,如果有多组,每组内都有一个Consumer,那这个就是发布-订阅(pub-sub)模式.每组都会收到同样的消息.
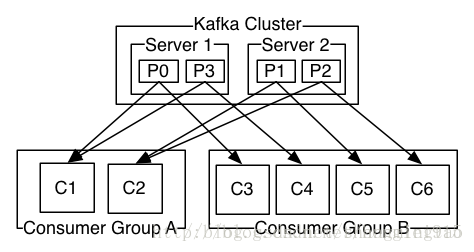
最后讲最难理解也是大家讨论最多的地方,partition(分区)和Consumer(消费者)的关系.首先,一个Consumer(消费者)的一个线程在某个时刻只能接收一个partition(分区)的数据,一个partition(分区)某个时刻也只会把消息发给一个Consumer(消费者).我们设计出来几种场景:
场景一: topic-1 下有partition-1和partition-2
group-1 下有consumer-1和consumer-2和consumer-3
所有consumer只有一个线程,且都消费topic-1的消息.
消费情况 : consumer-1只消费partition-1的数据
consumer-2只消费partition-2的数据
consumer-3不会消费到任何数据
原因 : 只能接受一个partition(分区)的数据
场景二: topic-1 下有partition-1和partition-2
group-1 下有consumer-1
consumer只有一个线程,且消费topic-1的消息.
消费情况 : consumer-1先消费partition-1的数据
consumer-1消费完partition-1数据后开始消费partition-2的数据
原因 : 这里是kafka检测到当前consumer-1消费完partition-1处于空闲状态,自动帮我做了负载.所以大家看到这里在看一下上边那句话的”某个时刻”
特例: consumer在消费消息时必须指定topic,可以不指定partition,场景二的情况就是发生在不指定partition的情况下,如果consumer-1指定了partition-1,那么consumer-1消费完partition-1后哪怕处于空闲状态了也是不会消费partition-2的消息的.
进而我们总结出了一条经验,同组内的消费者(单线程消费)数量不应多于topic下的partition(分区)数量,不然就会出有消费者空闲的状态,此时并发线程数=partition(分区)数量.反之消费者数量少于topic下的partition(分区)数量也是不理想的,原因是此时并发线程数=消费者数量,并不能完全发挥kafka并发效率.
最后我们看下上边的图,Consumer Group A的两个机器分别开启两个线程消费P0 P1 P2 P3的消息Consumer Group B的四台机器单线程消费P0 P1 P2 P3的消息就可以了.此时效率最高.
搭建Kafka环境
安装Kafka
下载:http://kafka.apache.org/downloads.html
-
tar zxf kafka-<VERSION>.tgz -
cd kafka-<VERSION>
启动Zookeeper
启动Zookeeper前需要配置一下config/zookeeper.properties:
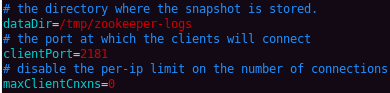
接下来启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties启动Kafka Server
启动Kafka Server前需要配置一下config/server.properties。主要配置以下几项,内容就不说了,注释里都很详细:
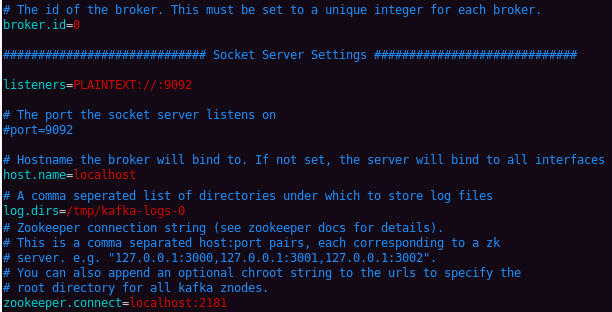
然后启动Kafka Server:
bin/kafka-server-start.sh config/server.properties创建Topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test查看创建的Topic
bin/kafka-topics.sh --list --zookeeper localhost:2181启动控制台Producer,向Kafka发送消息
-
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test -
This is a message -
This is another message -
^C
启动控制台Consumer,消费刚刚发送的消息
-
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning -
This is a message -
This is another message
删除Topic
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test注:只有当delete.topic.enable=true时,该操作才有效
配置Kafka集群(单台机器上)
首先拷贝server.properties文件为多份(这里演示4个节点的Kafka集群,因此还需要拷贝3份配置文件):
-
cp config/server.properties config/server1.properties -
cp config/server.properties config/server2.properties -
cp config/server.properties config/server3.properties
修改server1.properties的以下内容:
-
broker.id=1 -
port=9093 -
log.dir=/tmp/kafka-logs-1
同理修改server2.properties和server3.properties的这些内容,并保持所有配置文件的zookeeper.connect属性都指向运行在本机的zookeeper地址localhost:2181。注意,由于这几个Kafka节点都将运行在同一台机器上,因此需要保证这几个值不同,这里以累加的方式处理。例如在server2.properties上:
-
broker.id=2 -
port=9094 -
log.dir=/tmp/kafka-logs-2
把server3.properties也配置好以后,依次启动这些节点:
-
bin/kafka-server-start.sh config/server1.properties & -
bin/kafka-server-start.sh config/server2.properties & -
bin/kafka-server-start.sh config/server3.properties &
Topic & Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
现在在Kafka集群上创建备份因子为3,分区数为4的Topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 4 --topic kafka说明:备份因子replication-factor越大,则说明集群容错性越强,就是当集群down掉后,数据恢复的可能性越大。所有的分区数里的内容共同组成了一份数据,分区数partions越大,则该topic的消息就越分散,集群中的消息分布就越均匀。
然后使用kafka-topics.sh的--describe参数查看一下Topic为kafka的详情:

输出的第一行是所有分区的概要,接下来的每一行是一个分区的描述。可以看到Topic为kafka的消息,PartionCount=4,ReplicationFactor=3正是我们创建时指定的分区数和备份因子。
另外:Leader是指负责这个分区所有读写的节点;Replicas是指这个分区所在的所有节点(不论它是否活着);ISR是Replicas的子集,代表存有这个分区信息而且当前活着的节点。
拿partition:0这个分区来说,该分区的Leader是server0,分布在id为0,1,2这三个节点上,而且这三个节点都活着。
再来看下Kafka集群的日志:

其中kafka-logs-0代表server0的日志,kafka-logs-1代表server1的日志,以此类推。
从上面的配置可知,id为0,1,2,3的节点分别对应server0, server1, server2, server3。而上例中的partition:0分布在id为0, 1, 2这三个节点上,因此可以在server0, server1, server2这三个节点上看到有kafka-0这个文件夹。这个kafka-0就代表Topic为kafka的partion0。














 1712
1712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









