










docker pull sequenceiq/spark:1.5.1
http://baidu.ku6.com/watch/8788485592428494013.html?page=videoMultiNeed


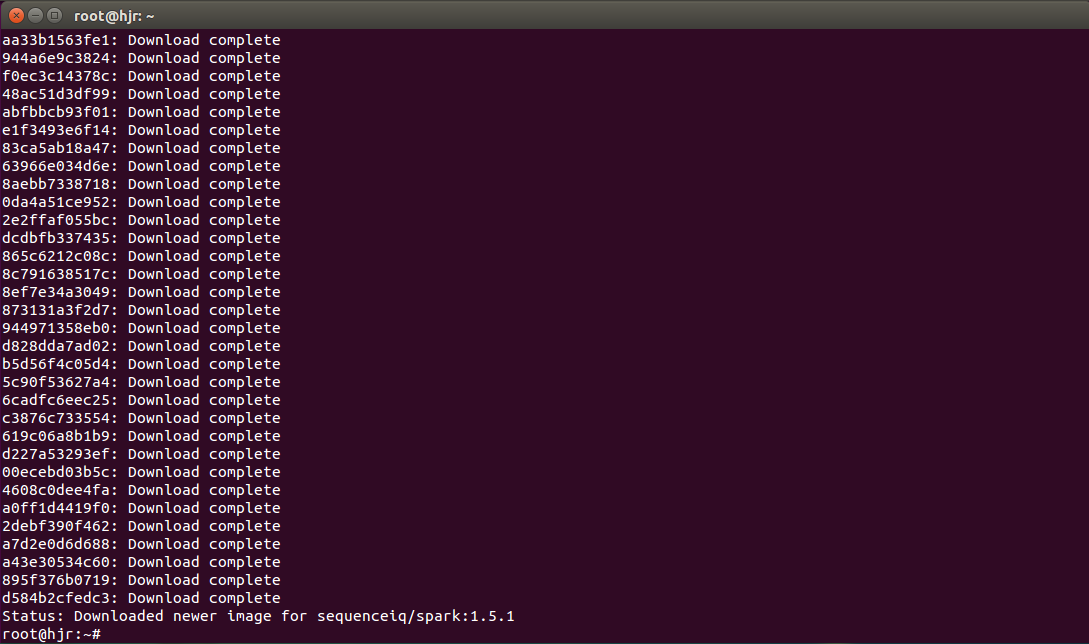
docker build –rm -t sequenceiq/spark:1.5.1
Running the image
1:
docker run -it -p 8088:8088 -p 8042:8042 -h sandbox sequenceiq/spark:1.5.1 bash
or
2:
docker run -d -h sandbox sequenceiq/spark:1.5.1 -d

#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (malloc) failed to allocate 358088704 bytes for committing reserved memory.
# Possible reasons:
# The system is out of physical RAM or swap space
# In 32 bit mode, the process size limit was hit
# Possible solutions:
# Reduce memory load on the system
# Increase physical memory or swap space
# Check if swap backing store is full
# Use 64 bit Java on a 64 bit OS
# Decrease Java heap size (-Xmx/-Xms)
# Decrease number of Java threads
# Decrease Java thread stack sizes (-Xss)
# Set larger code cache with -XX:ReservedCodeCacheSize=
# This output file may be truncated or incomplete.
#
# Out of Memory Error (os_linux.cpp:2726), pid=1851, tid=139714598016768
#
# JRE version: (7.0_51-b13) (build )
# Java VM: Java HotSpot(TM) 64-Bit Server VM (24.51-b03 mixed mode linux-amd64 compressed oops)
# Failed to write core dump. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again
#
--------------- T H R E A D ---------------
Current thread (0x00007f11d0008800): JavaThread "Unknown thread" [_thread_in_vm, id=1884, stack(0x00007f11d6ec1000,0x00007f11d6fc2000)]
Stack: [0x00007f11d6ec1000,0x00007f11d6fc2000], sp=0x00007f11d6fc01f0, free space=1020k
Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
V [libjvm.so+0x992f4a] VMError::report_and_die()+0x2ea
V [libjvm.so+0x4931ab] report_vm_out_of_memory(char const*, int, unsigned long, char const*)+0x9b
V [libjvm.so+0x81338e] os::Linux::commit_memory_impl(char*, unsigned long, bool)+0xfe
V [libjvm.so+0x81383f] os::Linux::commit_memory_impl(char*, unsigned long, unsigned long, bool)+0x4f
V [libjvm.so+0x813a2c] os::pd_commit_memory(char*, unsigned long, unsigned long, bool)+0xc
V [libjvm.so+0x80daea] os::commit_memory(char*, unsigned long, unsigned long, bool)+0x2a
V [libjvm.so+0x87fcd3] PSVirtualSpace::expand_by(unsigned long)+0x53
V [libjvm.so+0x880c69] PSYoungGen::initialize_virtual_space(ReservedSpace, unsigned long)+0x89
V [libjvm.so+0x8815e0] PSYoungGen::initialize(ReservedSpace, unsigned long)+0x50
错误代码
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000eaa80000, 358088704, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (malloc) failed to allocate 358088704 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /usr/local/spark-1.5.1-bin-hadoop2.6/bin/hs_err_pid1959.log

bash-4.1# cat /proc/meminfo shows
MemTotal: 2040736 kB
MemFree: 75800 kB
MemAvailable: 108704 kB
Buffers: 28624 kB
Cached: 109588 kB
SwapCached: 60224 kB
Active: 866236 kB
Inactive: 895504 kB
Active(anon): 793784 kB
Inactive(anon): 841408 kB
Active(file): 72452 kB
Inactive(file): 54096 kB
Unevictable: 32 kB
Mlocked: 32 kB
SwapTotal: 1046524 kB
SwapFree: 45888 kB
Dirty: 256 kB
Writeback: 0 kB
AnonPages: 1563940 kB
Mapped: 69960 kB
Shmem: 11636 kB
Slab: 98648 kB
SReclaimable: 37960 kB
SUnreclaim: 60688 kB
KernelStack: 23056 kB
PageTables: 34744 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 2066892 kB
Committed_AS: 7412308 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 295844 kB
VmallocChunk: 34359420732 kB
HardwareCorrupted: 0 kB
AnonHugePages: 679936 kB
CmaTotal: 0 kB
CmaFree: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 180096 kB
DirectMap2M: 1916928 kB
cat: shows: No such file or directory
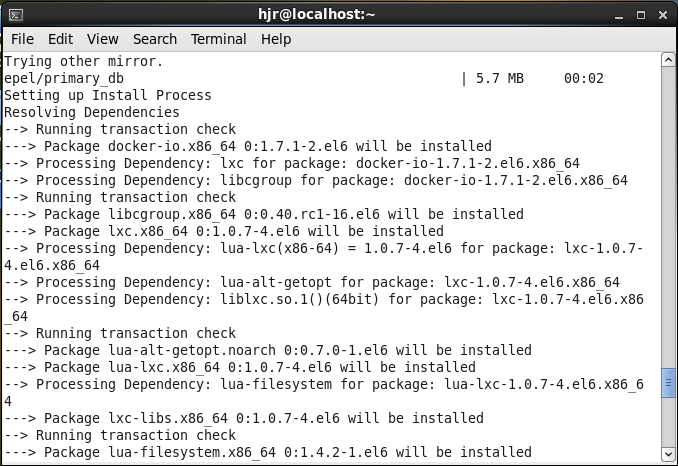
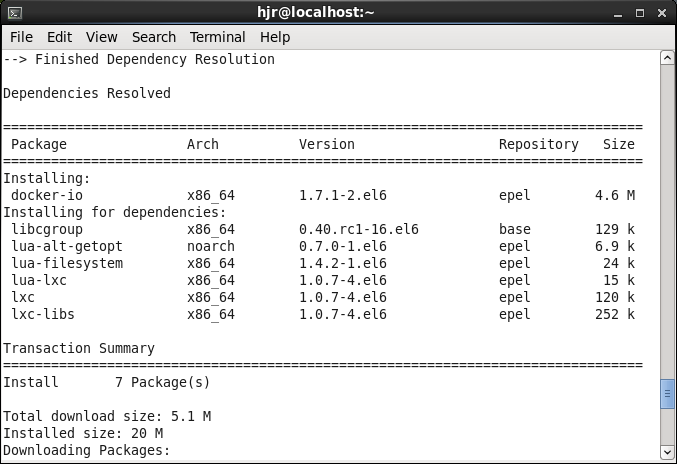
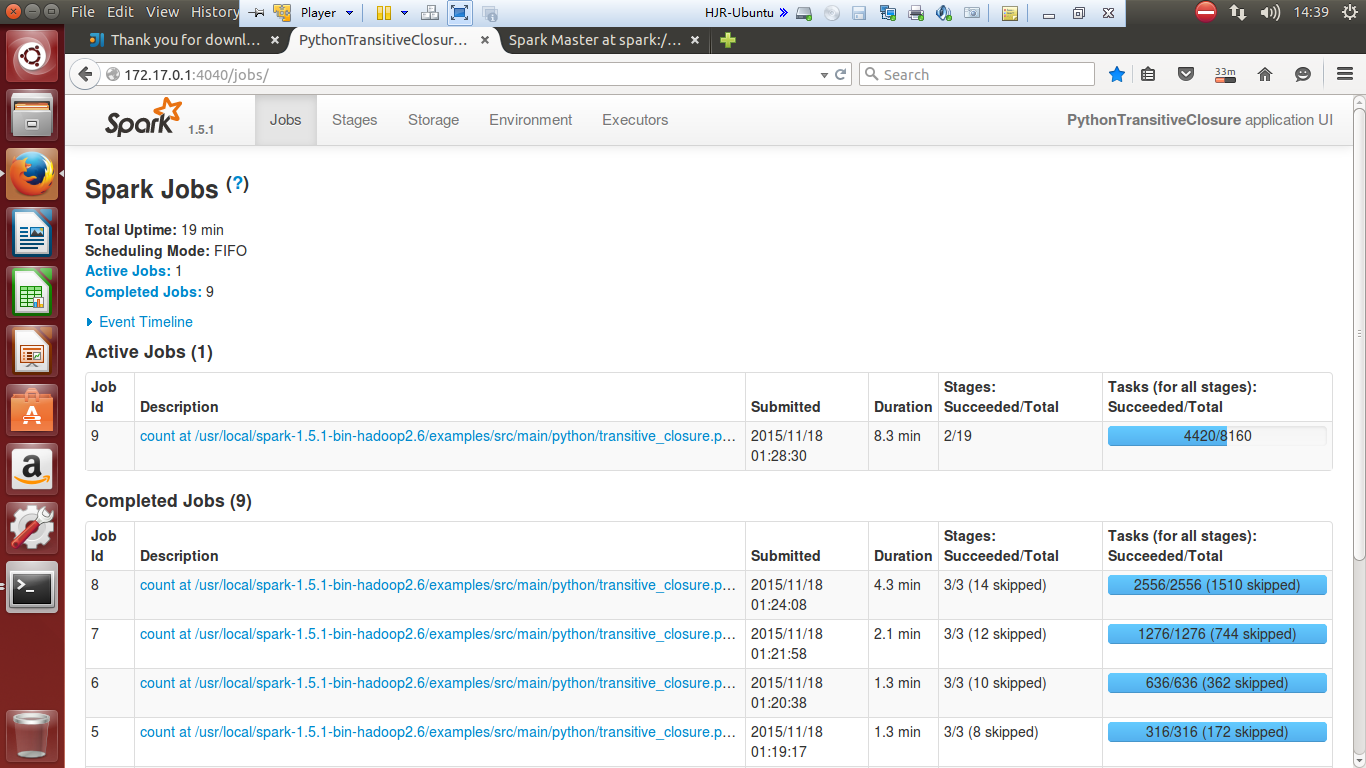
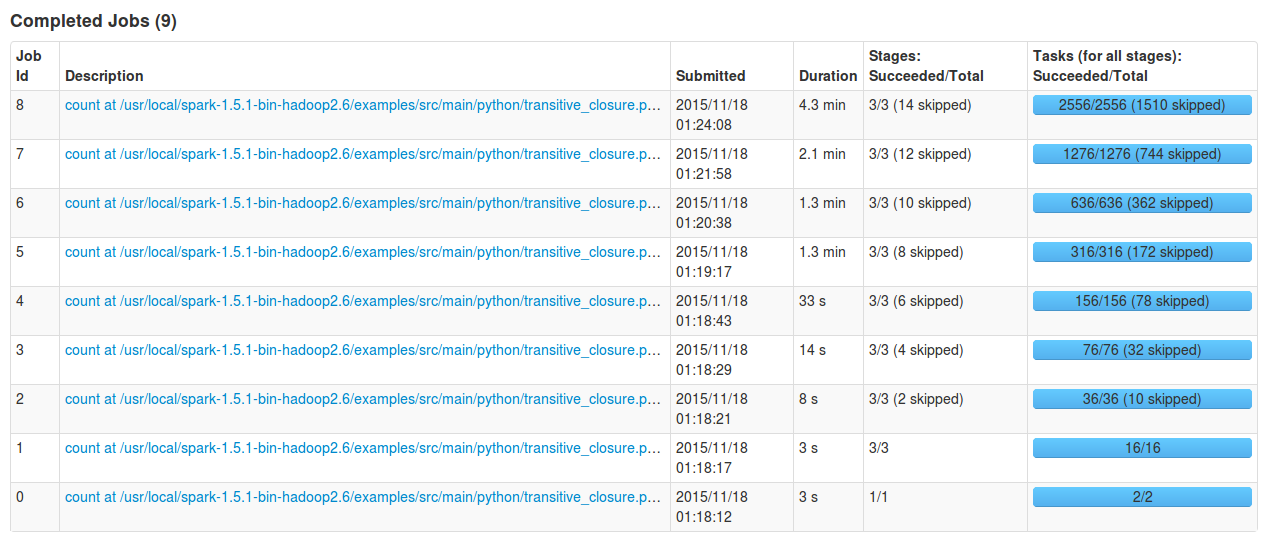
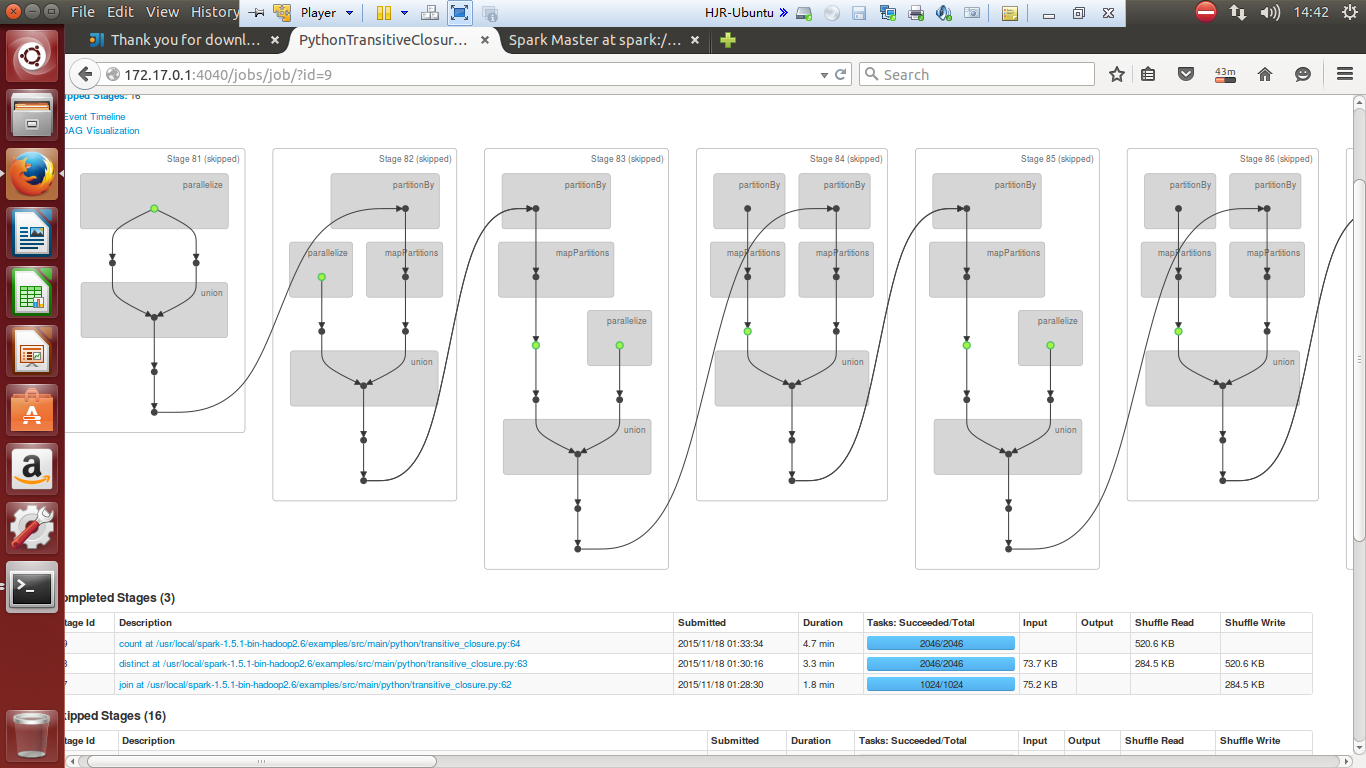
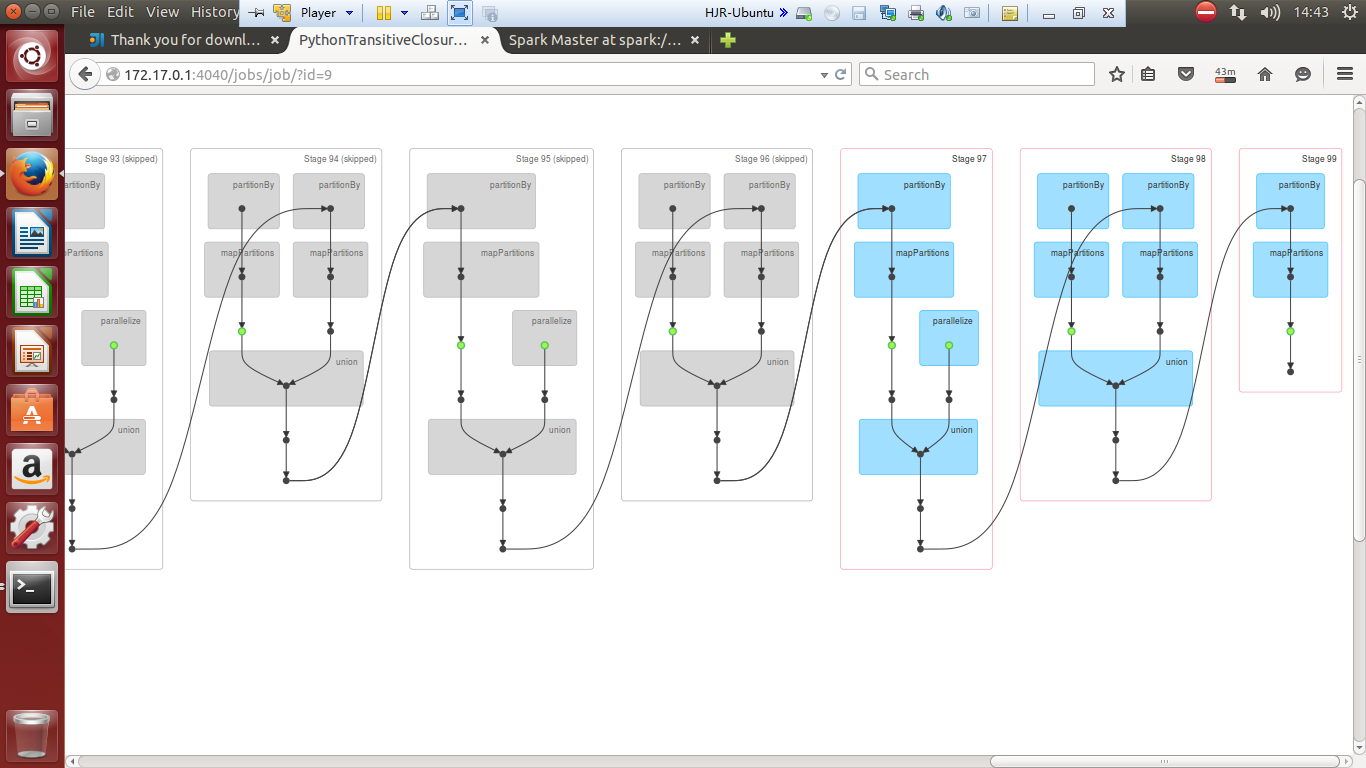
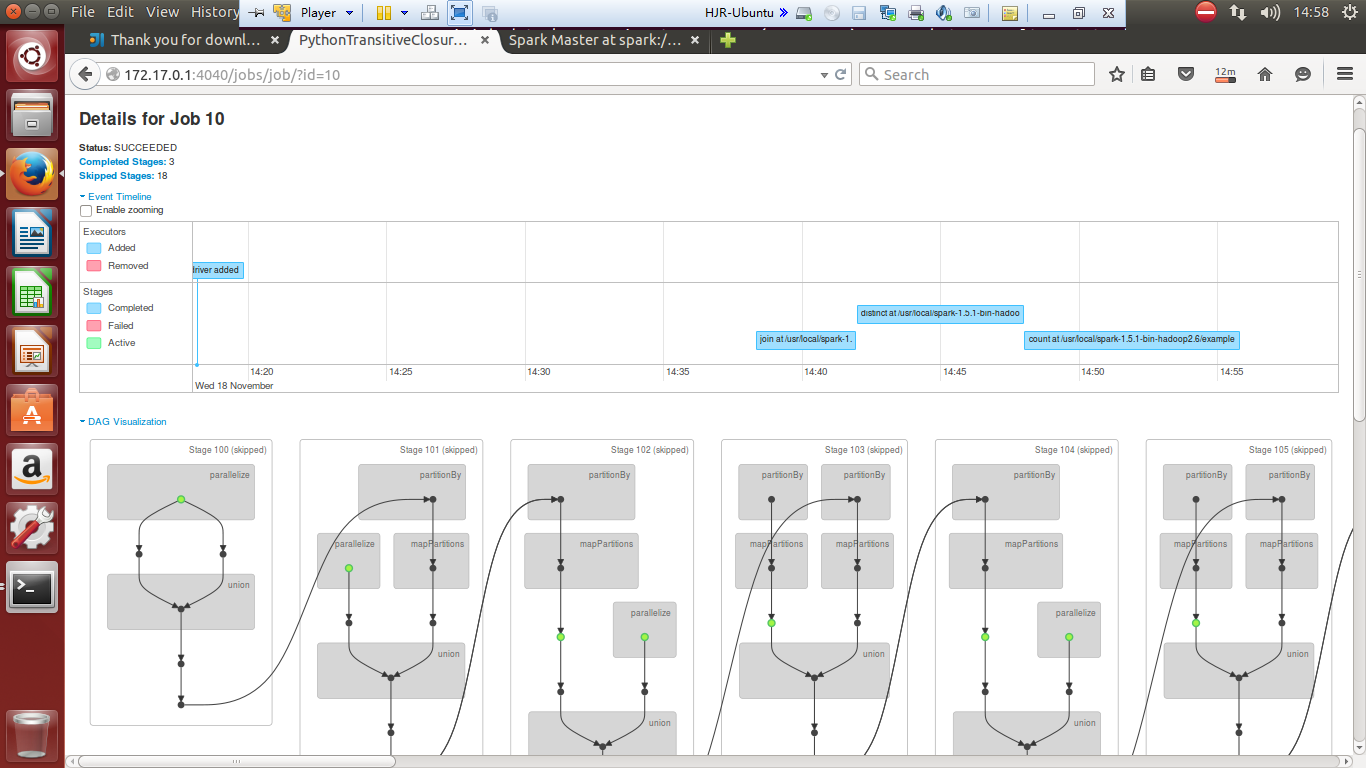
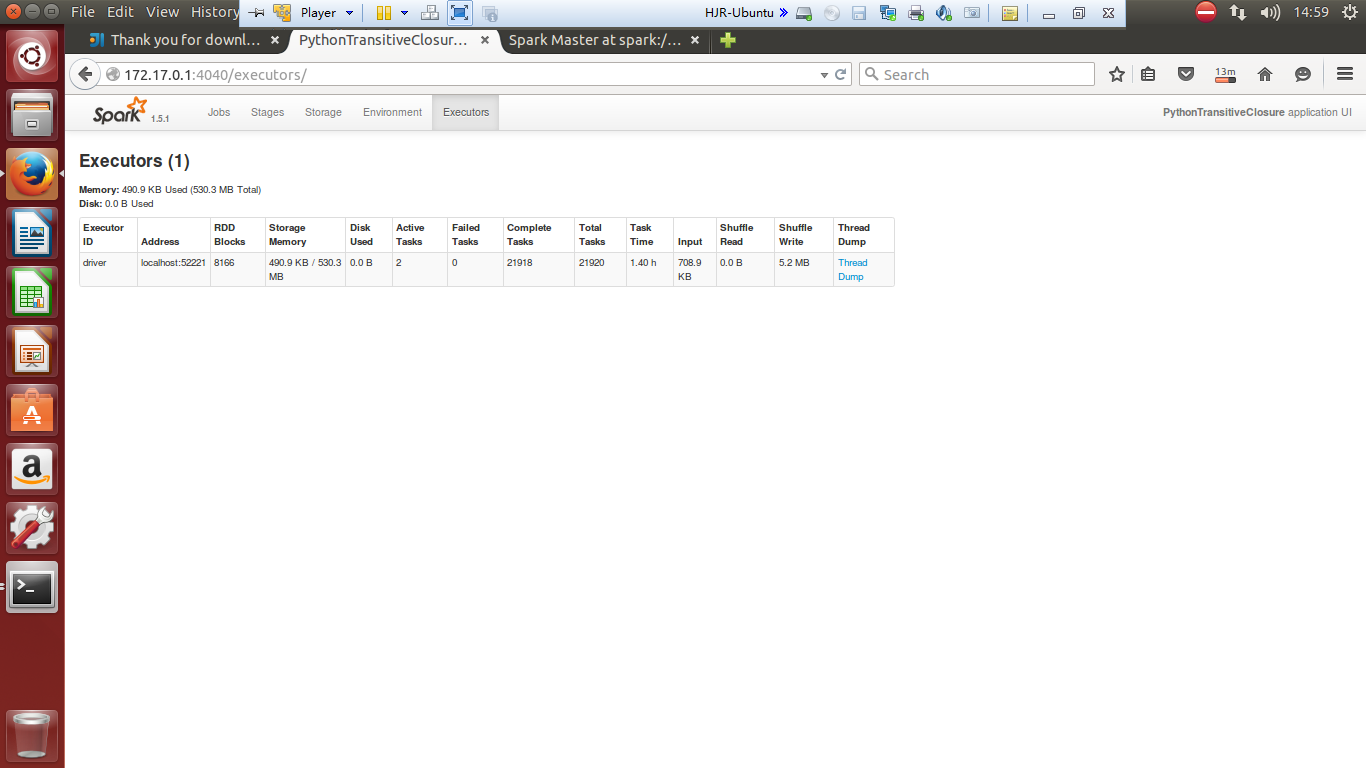
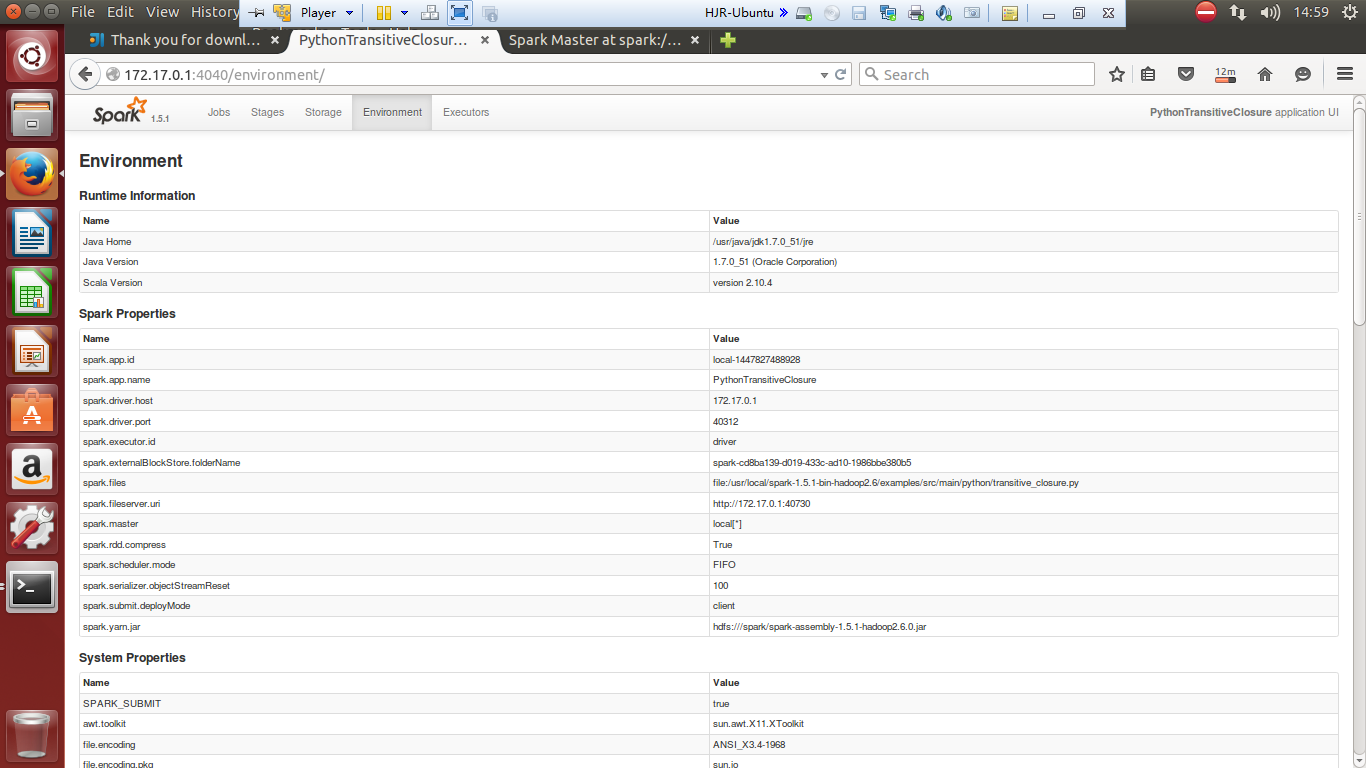
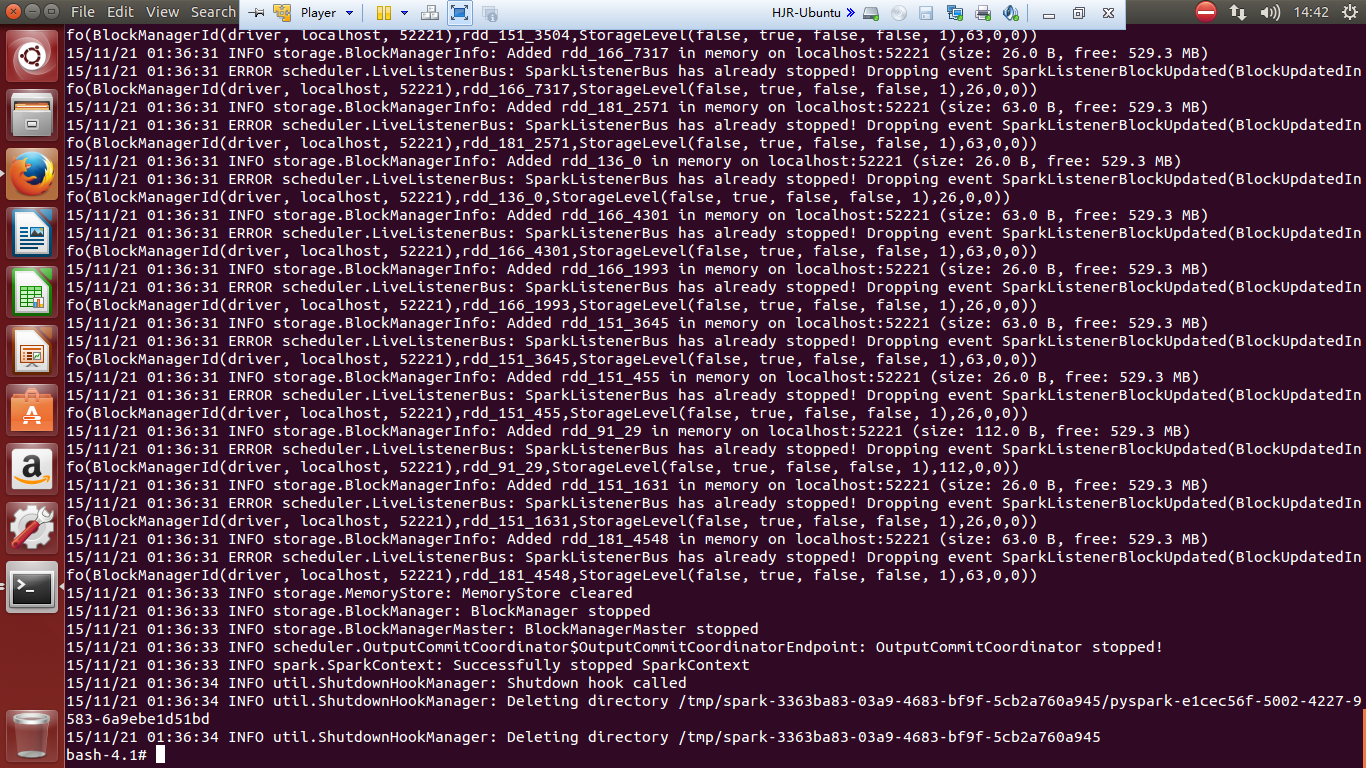
试运行截图记录
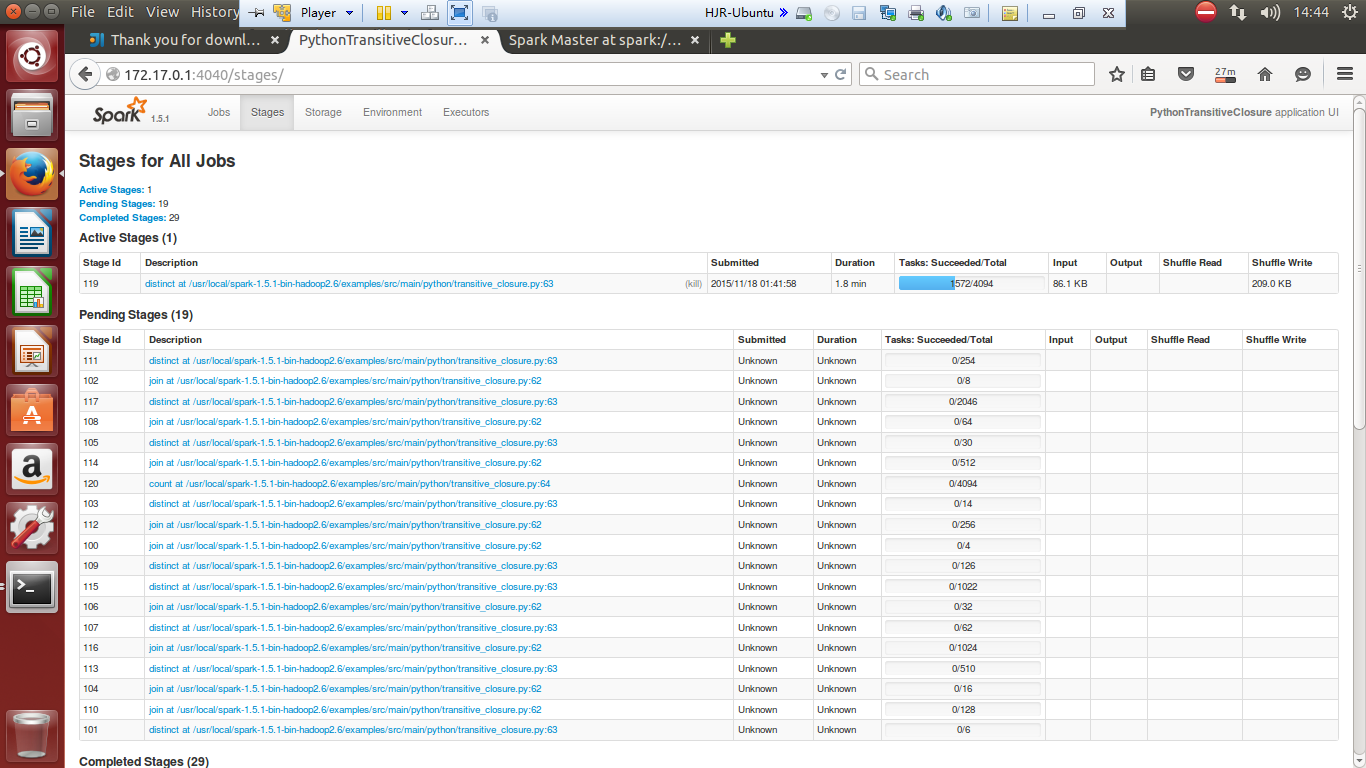
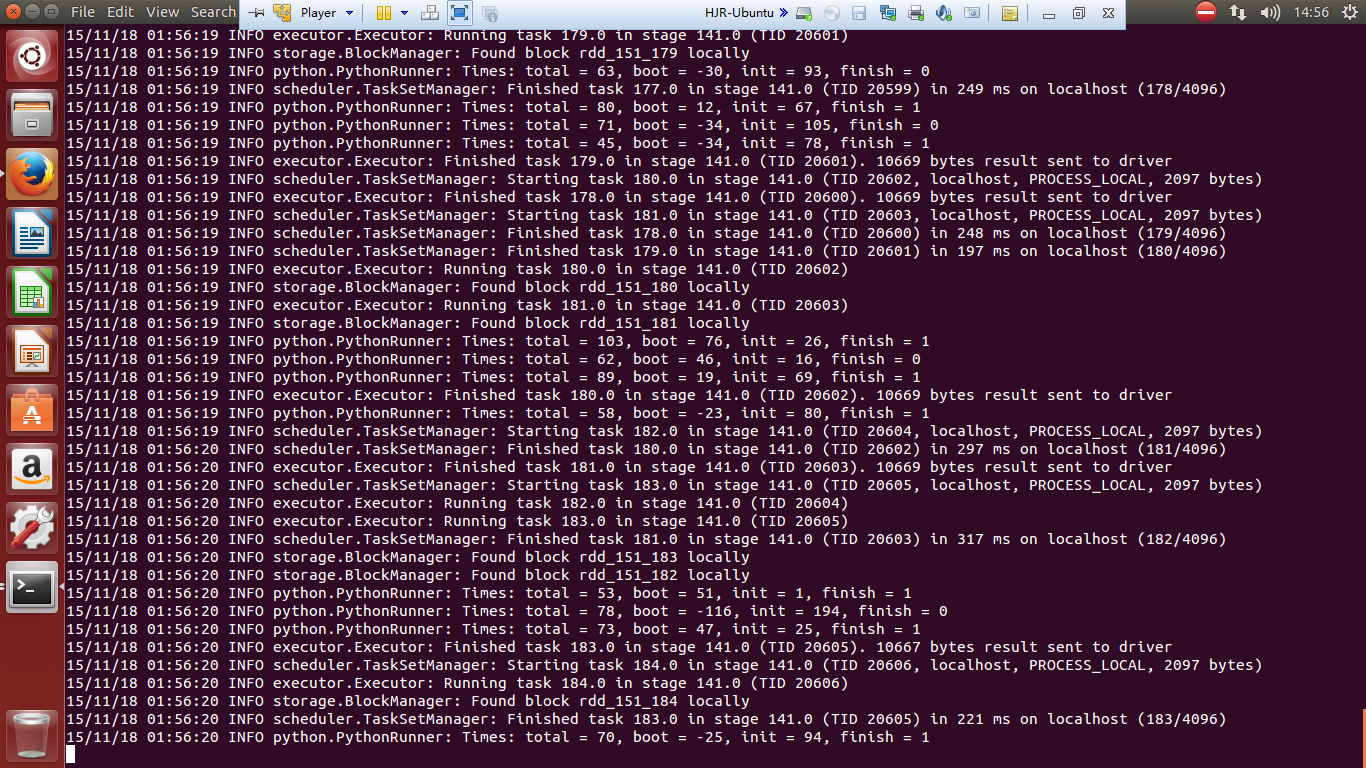
./bin/spark-submit examples/src/main/python/transitive_closure.py
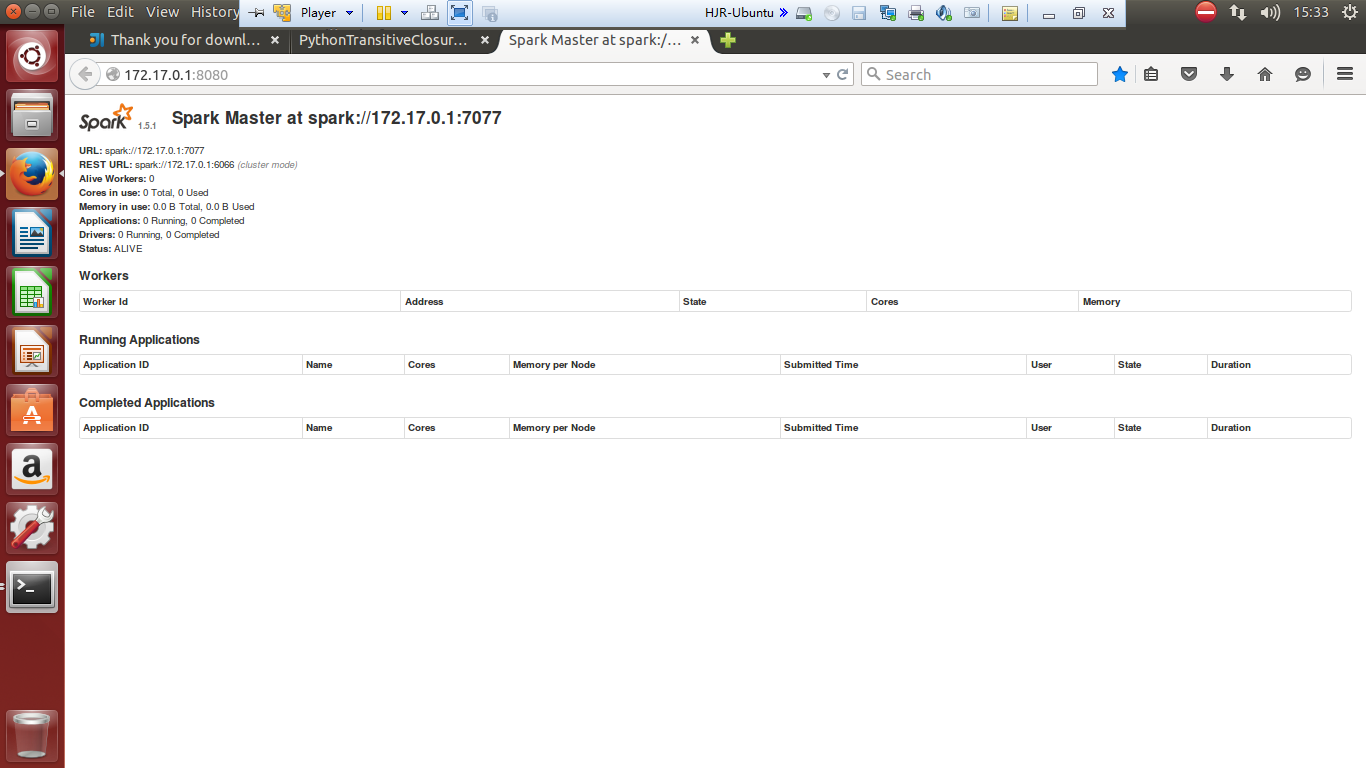
Spark源码编译
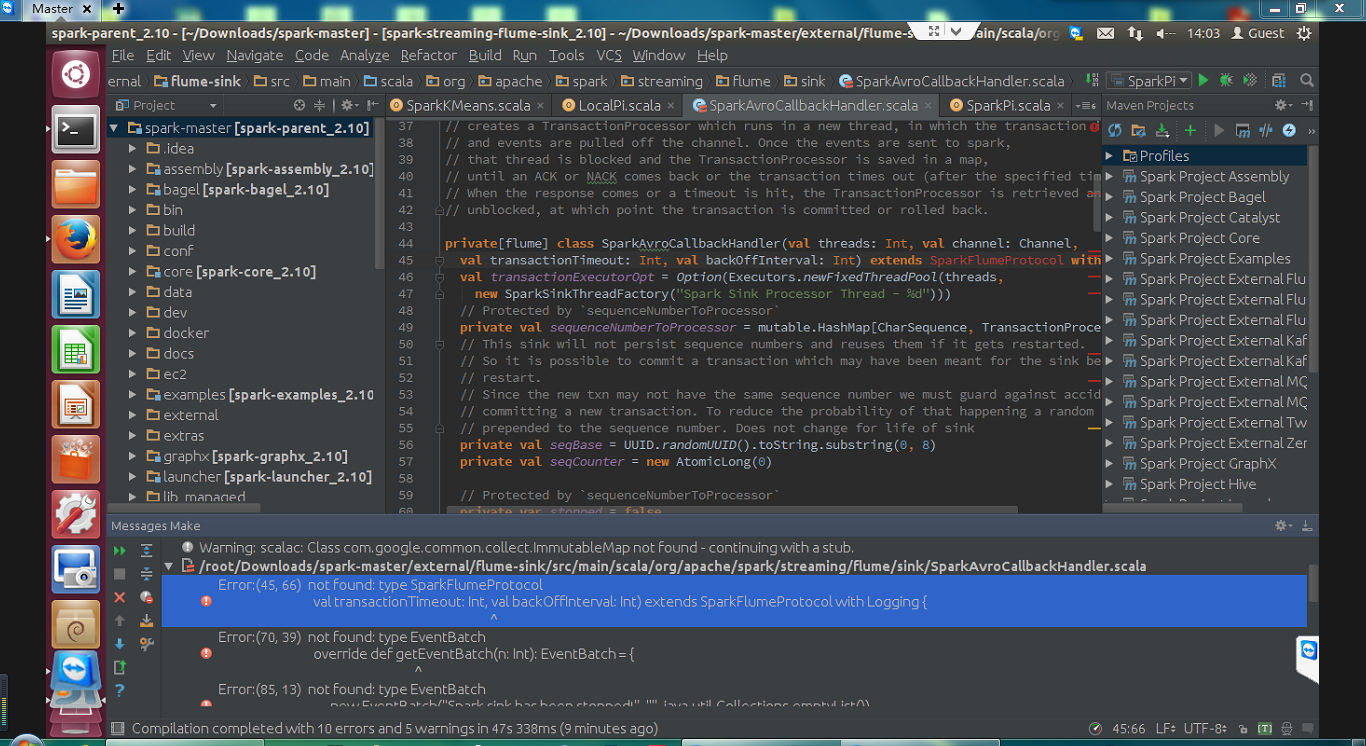
Error:(45, 66) not found: type SparkFlumeProtocol
val transactionTimeout: Int, val backOffInterval: Int) extends SparkFlumeProtocol with Logging {
Error:(70, 39) not found: type EventBatch
override def getEventBatch(n: Int): EventBatch = {
Error:(80, 22) not found: type EventBatch
def getEventBatch: EventBatch = {
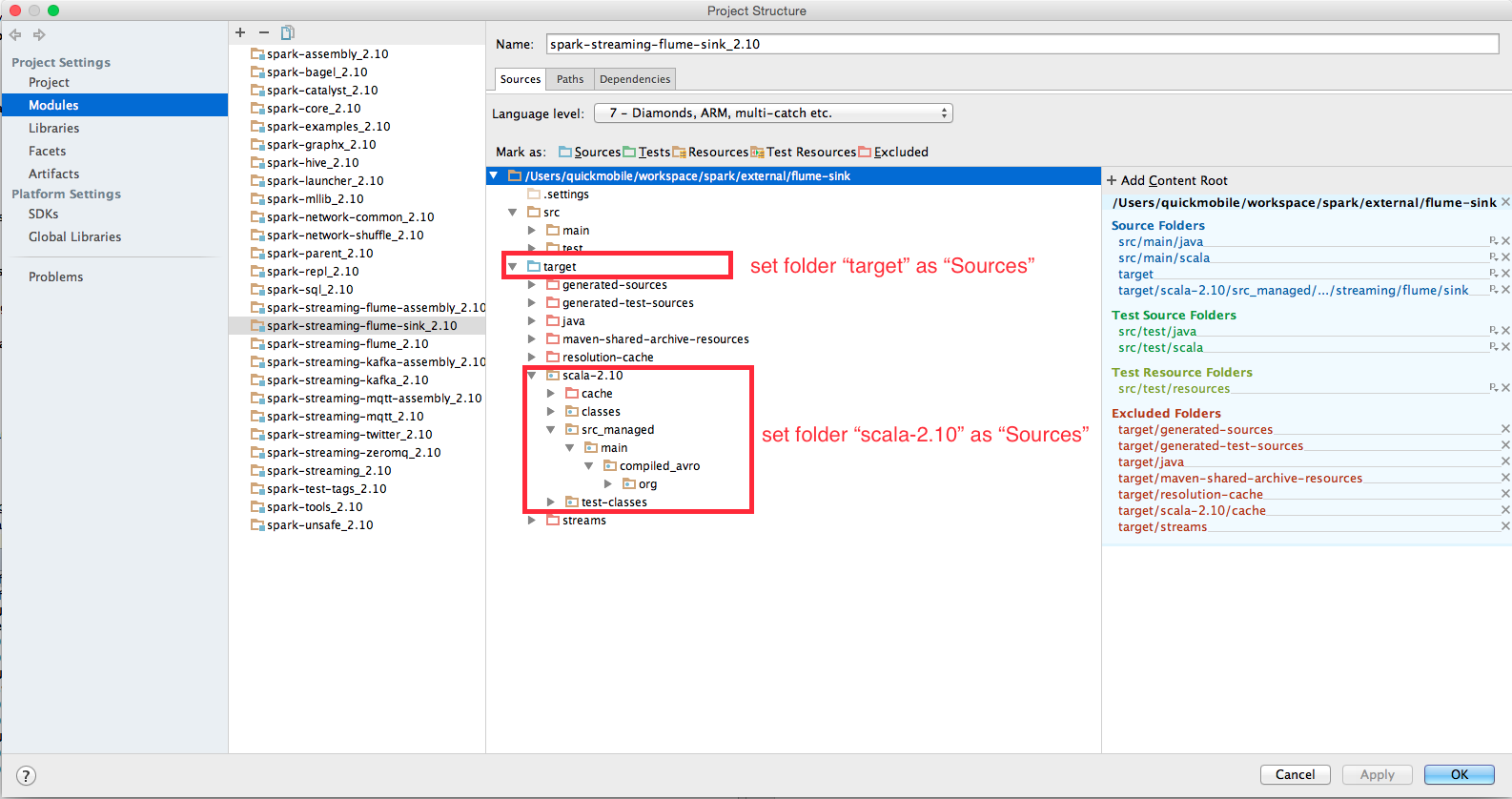
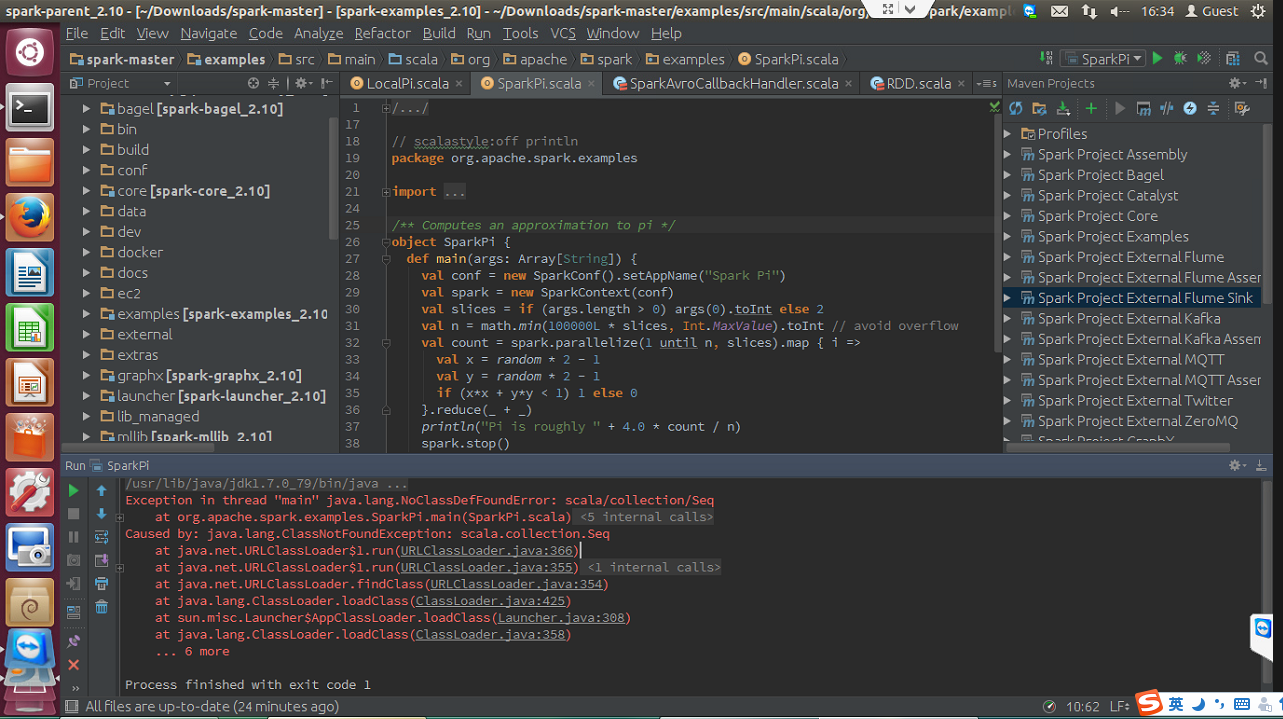
















 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











