










安装配置Scala
1 下载scala
下载解压scala包:略
附:下载链接
http://www.scala-lang.org/download/2.10.4.html
移动scala到指定目录
mkdir /usr/local/scala
mv scala-2.10.4 /usr/local/scala
2 配置scala环境变量
export SCALA_HOME=/usr/local/scala/scala-2.10.4
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:$PATH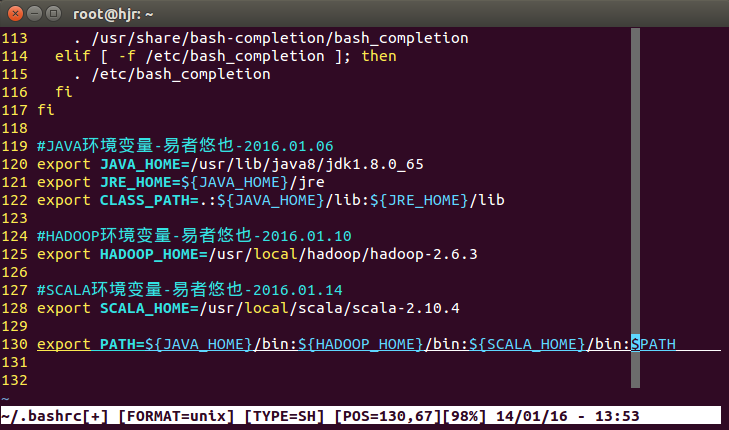
source .bashrc 使配置生效,显示安装的scala版本

3 测试scala运行环境
输入scala进入scala环境:
测试:12*12 回车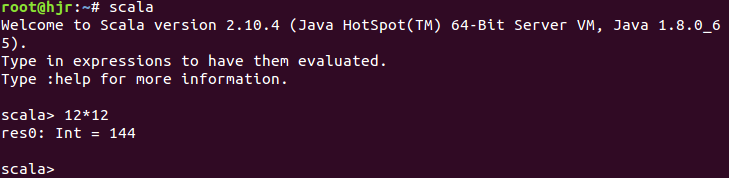
安装配置Spark1.6.0
1 下载Spark1.6.0
根据Hadoop选择对应版本下载Spark
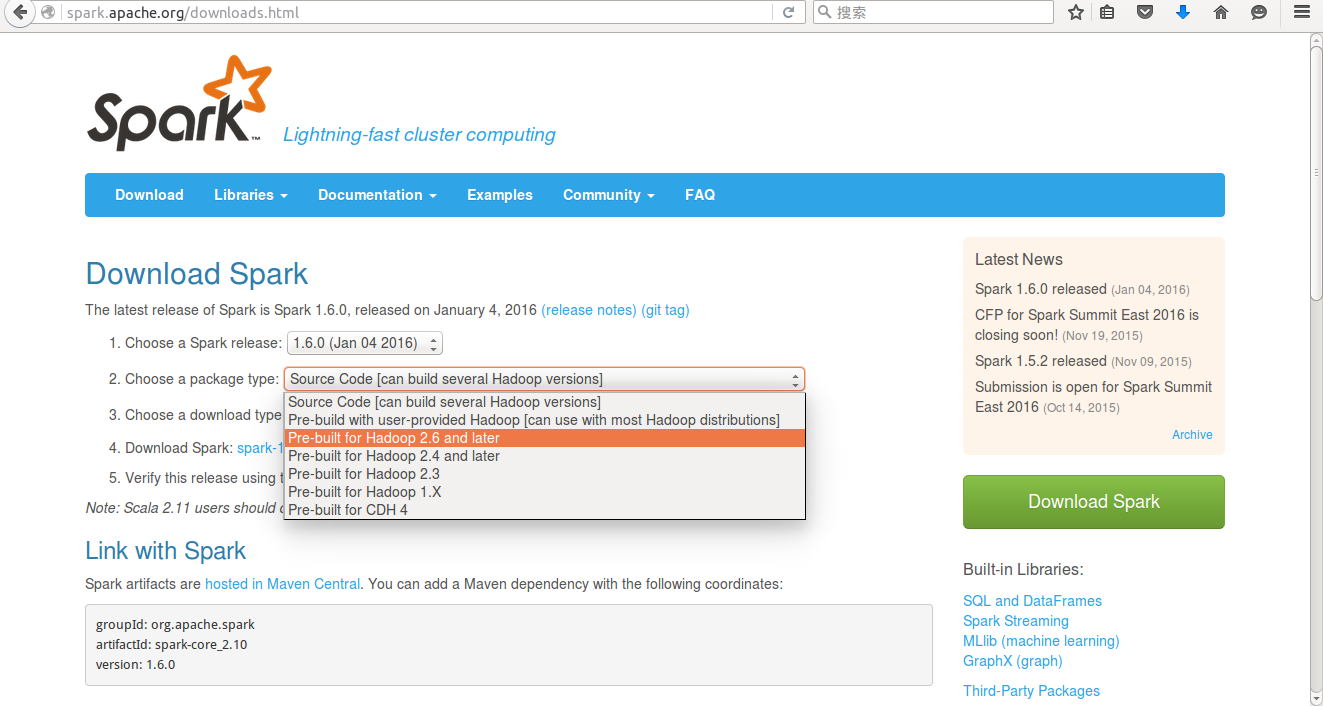
附:下载链接
http://spark.apache.org/downloads.html将下载解压后的spark移动到指定目录(/usr/local/spark)
mkdir /usr/local/spark
mv spark-1.6.0-bin-hadoop2.6 /usr/local/spark
2 配置Spark环境变量
export SPARK_HOME=/usr/local/spark/spark-1.6.0-bin-hadoop2.6
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH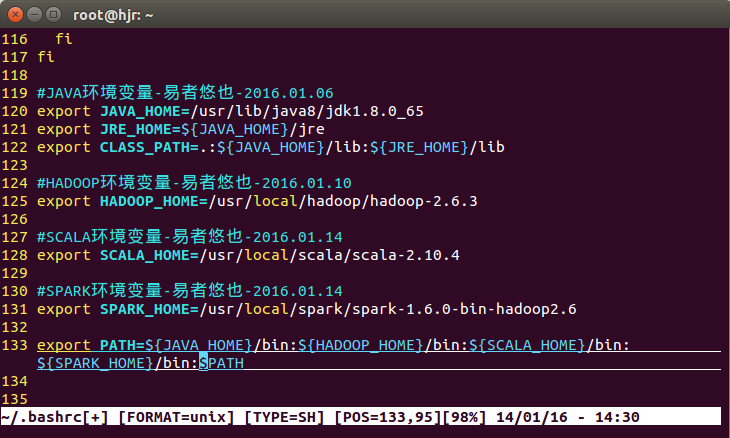
注:source .bashrc 使配置生效
3 配置Spark
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
添加SPARK配置信息
export JAVA_HOME=/usr/lib/java8/jdk1.8.0_65
export SCALA_HOME=/usr/local/scala/scala-2.10.4
export SPARK_MASTER_IP=hjr
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.6.3/etc/hadoop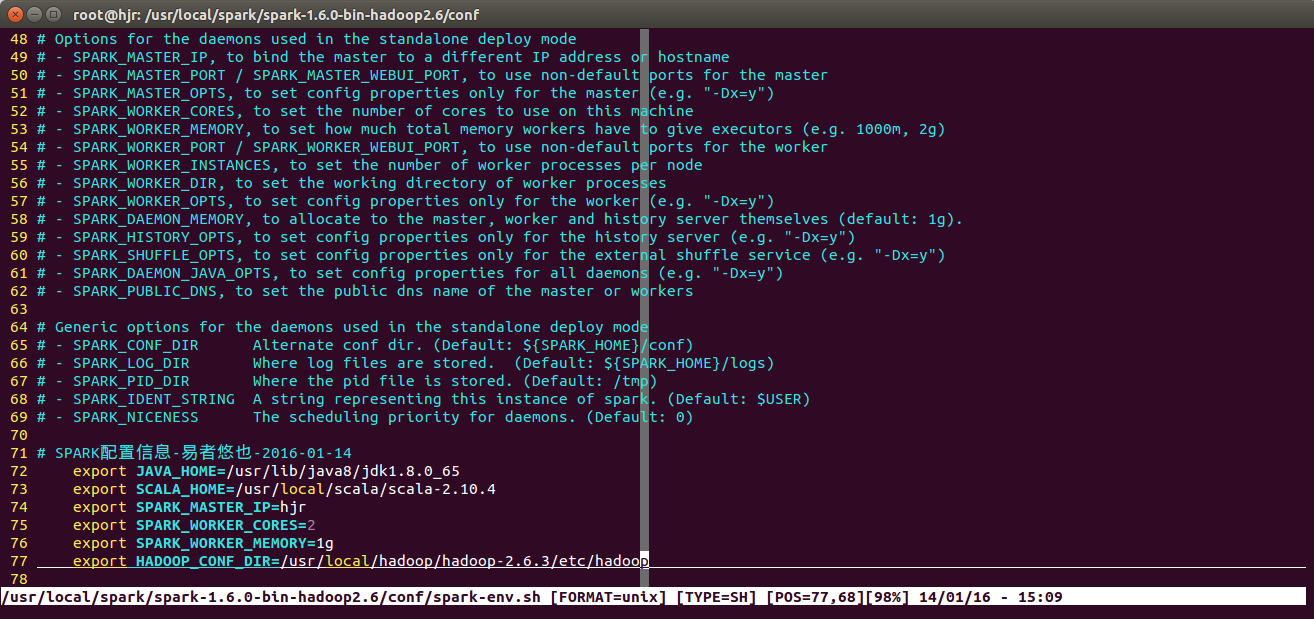
cp slaves.template slaves
vim slaves注意 IP 地址:
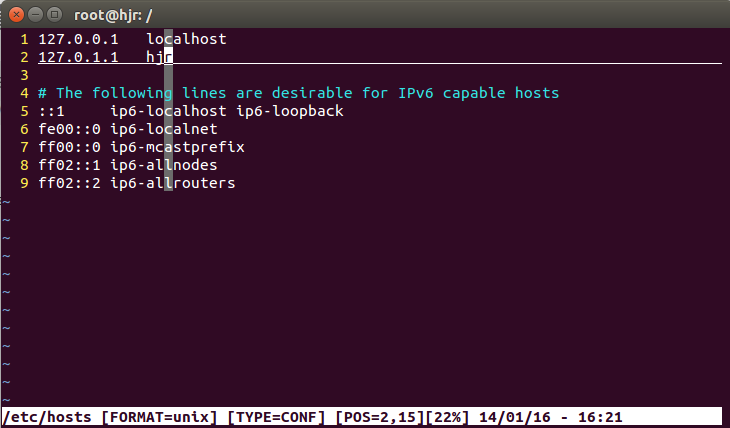
添加节点:
hjr 或者 127.0.1.1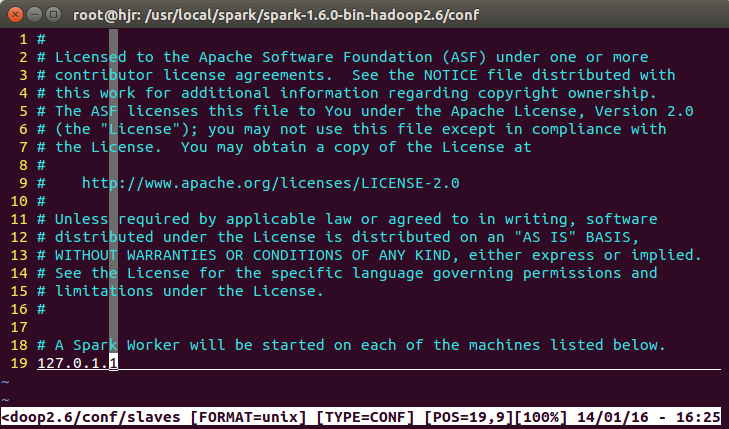
4 启动Spark,查看集群状况
cd /usr/local/spark/spark-1.6.0-bin-hadoop2.6
启动:
./start-all.shjps查看进程:多了一个Master和Worker进程
启动:spark-shell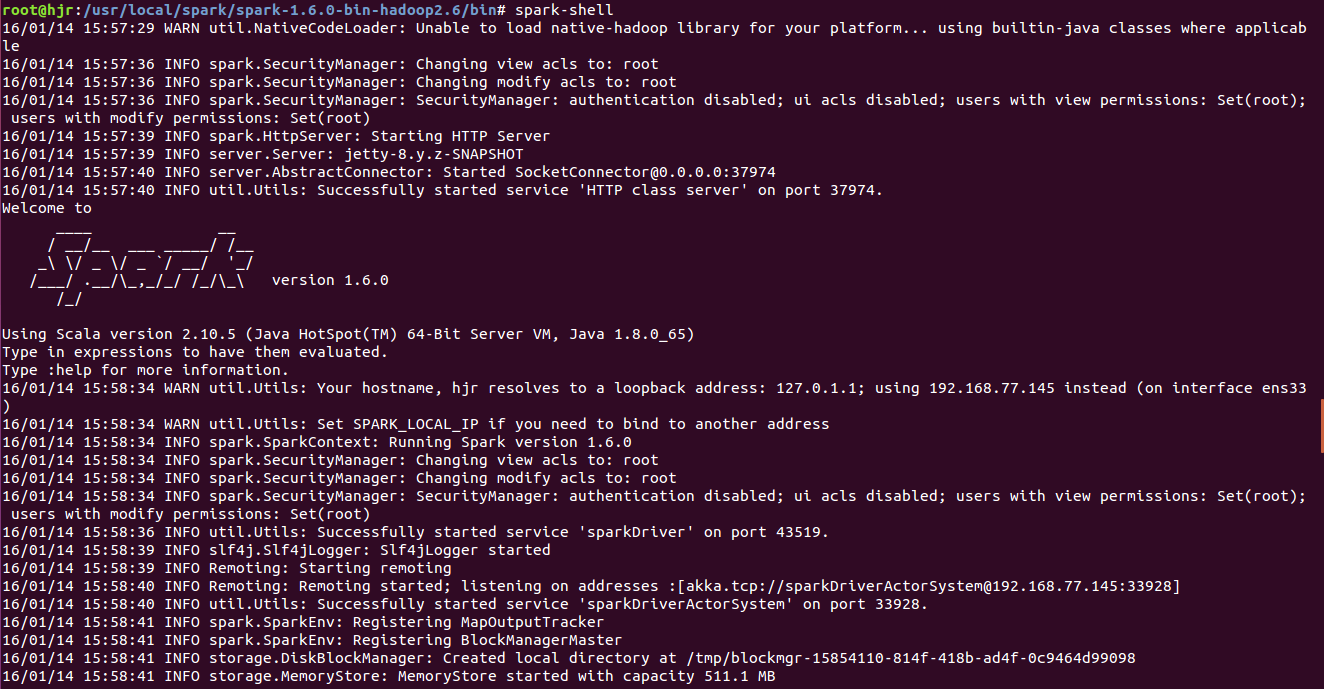
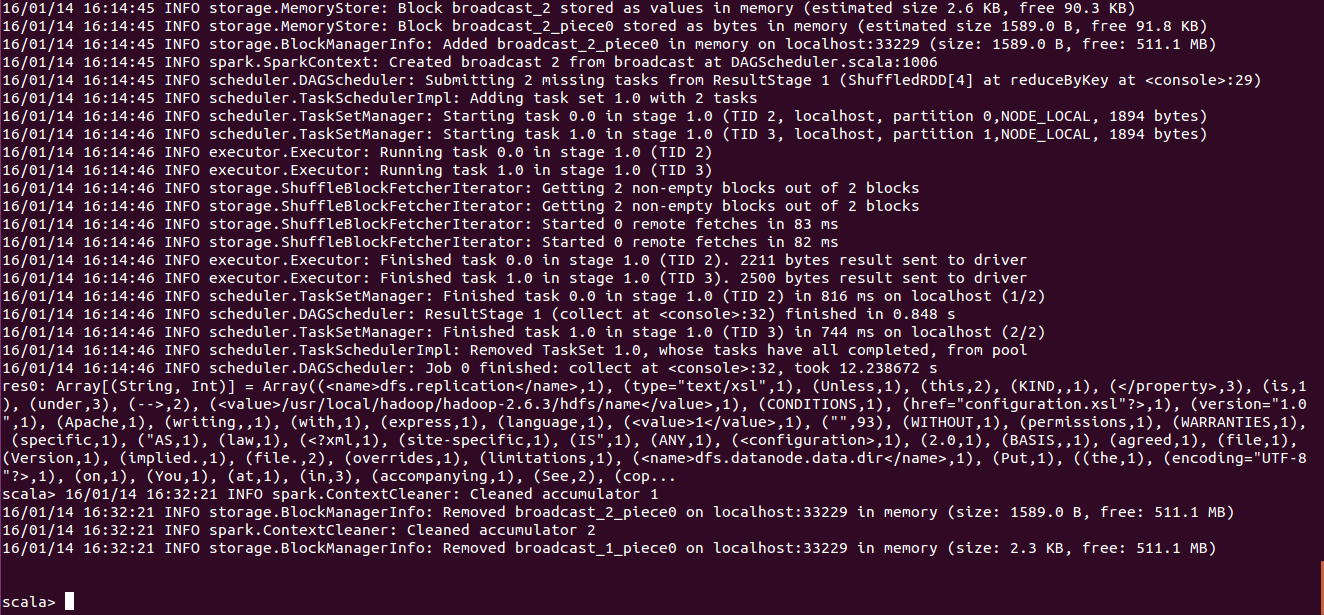
测试运行:
val file=sc.textFile("hdfs:/hjr/hdfs-site.xml")
val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
count.collect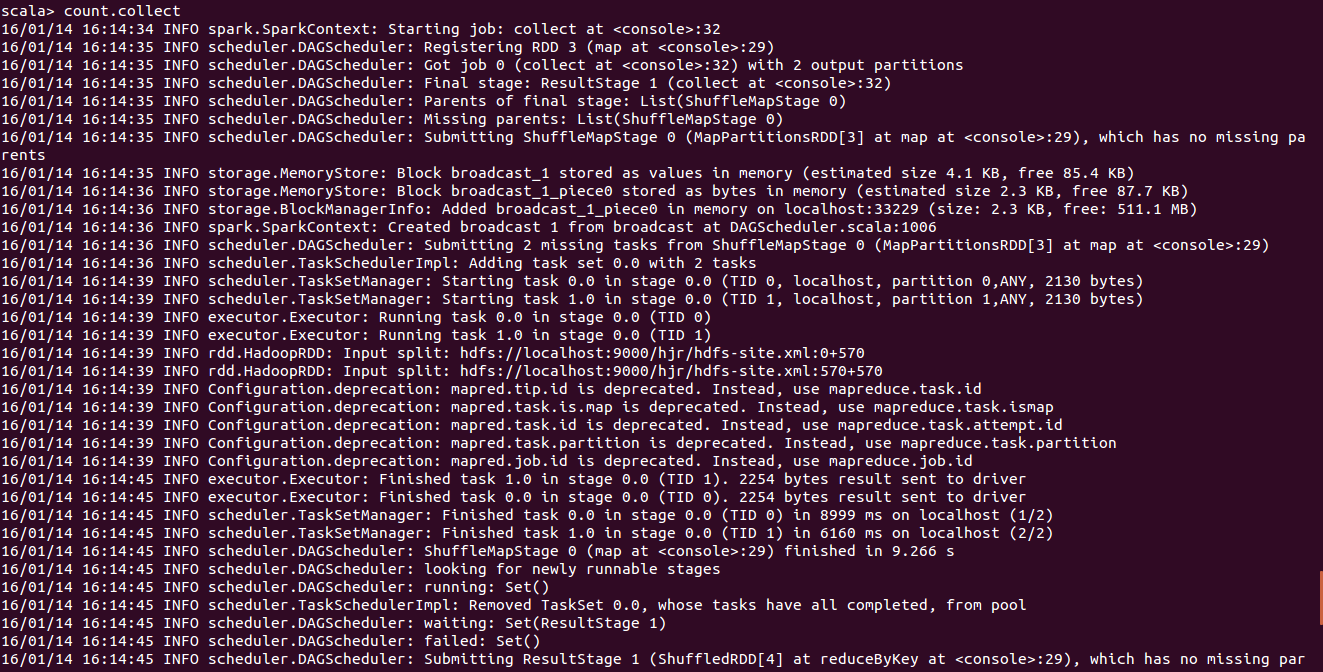
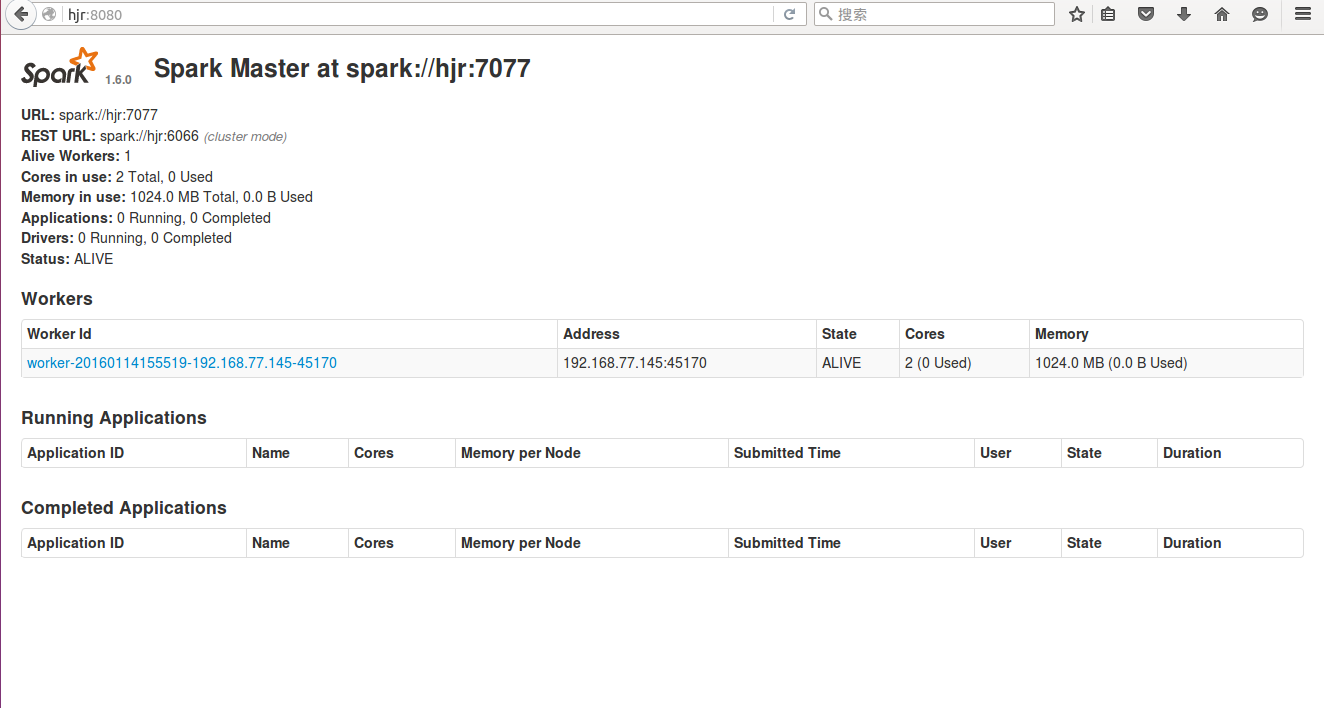
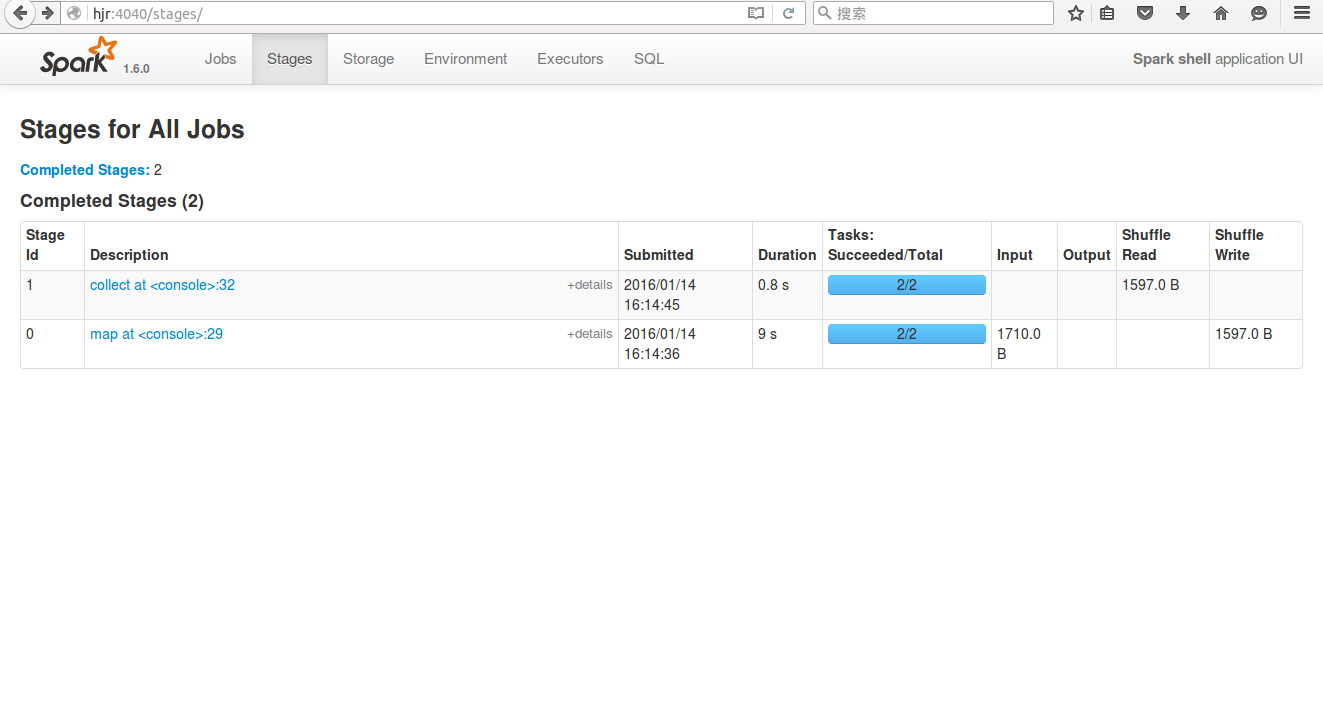
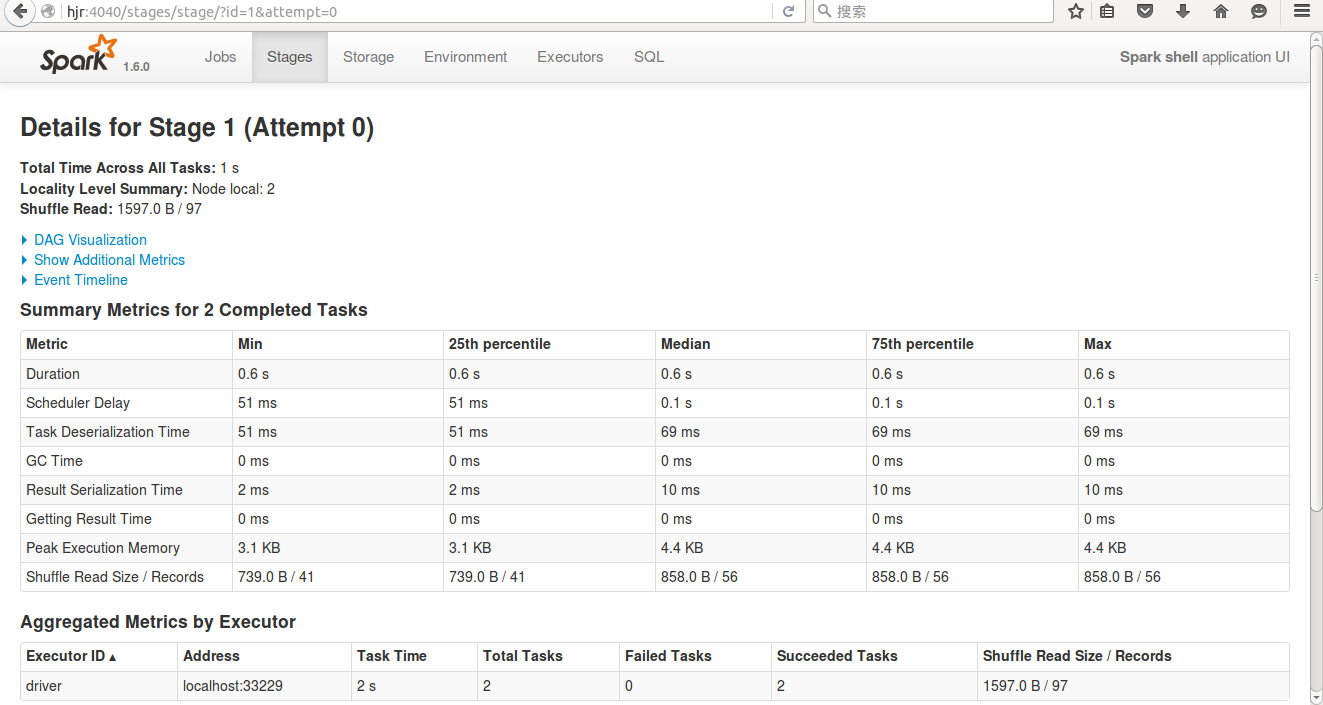
Spark UI:

附:Spark History Server 配置
1
vim /conf/spark-defaults.confspark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:9000/SparkHistoryServerLogs
spark.history.ui.port 18088
spark.history.fs.logDirectory hdfs://localhost:9000/SparkHistoryServerLogs2
vim spark-env.sh起作用:(localhost:9000 — 路径和hadoop配置文件core-site.xml对应)
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18088 -Dspark.history.fs.logDirectory=hdfs://localhost:9000/SparkHistoryServerLogs"3
hadoop fs -mkdir /SparkHistoryServerLogs















 6393
6393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











