






一、背景
数据二十条之一:建立数据来源可确认、使用范围可界定、流通过程可追溯、安全风险可防范的数据可信流通体系
信任四要素:
①身份可确认 ②利益可依赖 ③能力有预期 ④行为有后果
数据可信流通满足条件:
- 内循环:数据持有方在自己的运维安全域内对自己的数据使用和安全拥有全责
- 外循环 :数据要素在离开持有方安全域后,持有方依然拥有管控需求和责任
二、传统数据安全方法——运维信任
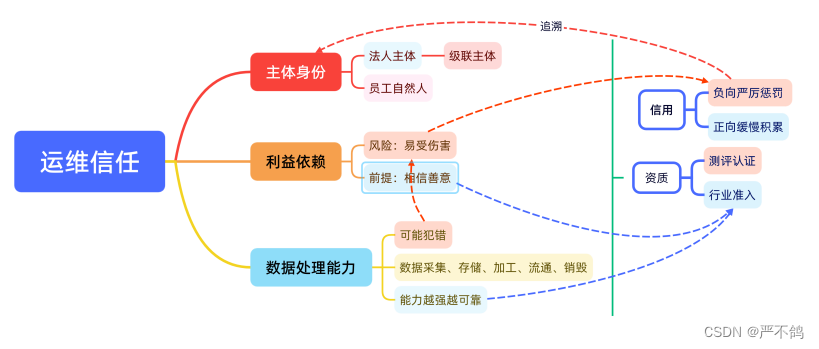
(截自sf隐私计算课程第二期第一课)
存在问题:在外循环中数据离开持有方安全域后导致责任主体不清,利益诉求不一致,能力参差不齐,责任链路难追溯。
三、从运维信任到技术信任
3.1 基础
基于密码学与可信计算技术的数据可信流通全流程保障
- 身份可确认:可信数字身份;
- 利益能对齐:使用权跨域管控;
- 能力有预期:通用安全分级测评;
- 行为有后果:全链路审计。
3.2 可信数字身份
- CA证书:验证机构实体
• 基于公私钥体系
• 权威机构注册 - 远程验证(Remote Attestation):验证数字应用实体
• 基于硬件芯片可信根(TPM/TCM)与可信计算体系
• 验证网络上某节点运行的是指定的软件和硬件
3.3 使用权跨域管控
数据持有者在数据(包括密态)离开其运维安全域后,依然能够对数据如何加工使用进行决策,防泄露防滥用,对齐上下游利益诉求
3.4 安全分级测评
不可能三角:安全要求,功能复杂度,单位成本
目的:通过对数据进行安全分级测评,进而采用不同的技术,如FHE、MPC、TEE等。
3.5 全链路审计
覆盖原始数据到衍生数据,责任界定。
• 原始数据: 损失最大、责任难界定、注意API直连
• 密态数据:损失最小
• 衍生数据:有损失、依赖于信息熵损耗、责任能界定















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









