









# 这个平台对于新手朋友十分友好,简单但又能同时锻炼多种能力,简单的逆向以及全站分析爬取等,在此和各位交流,分享我的方法与心得。
一、找到解密位置
点击翻页,多次可以看出看到接口是一个get的方法,载荷有pg,pgsz,total。
 响应是以5588开头的密文串,同时可以看到其他请求的密文的响应也是密文,只不过是开头的字符不一样。
响应是以5588开头的密文串,同时可以看到其他请求的密文的响应也是密文,只不过是开头的字符不一样。
此时找到解密位置方法很多,可以hookjson.parse,也可以在启动器呢打上断点,一步一步找,这次我们就一步一步找,前期可以快一点,一旦出现密文就要慢慢地单步调试咯。
启动器打上断点,点击下一页。
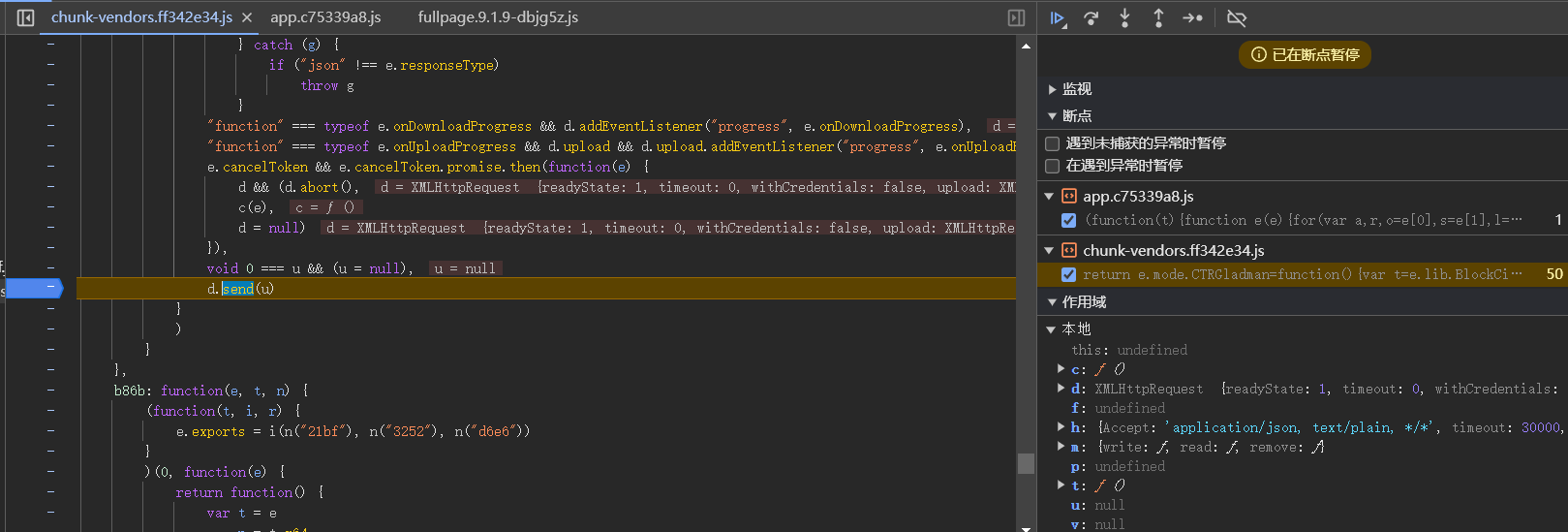
单步调试至出现密文。
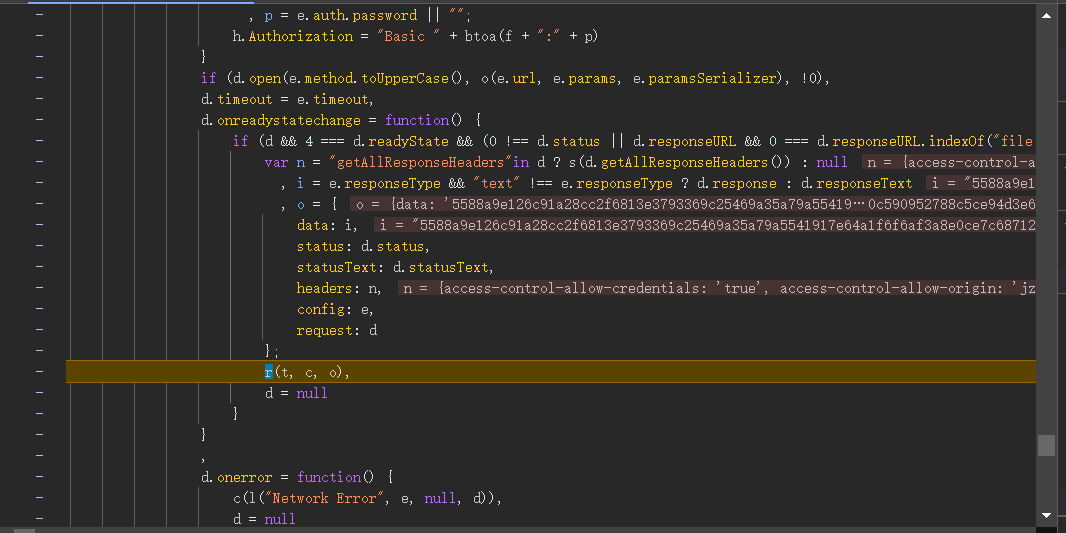
有点像的位置
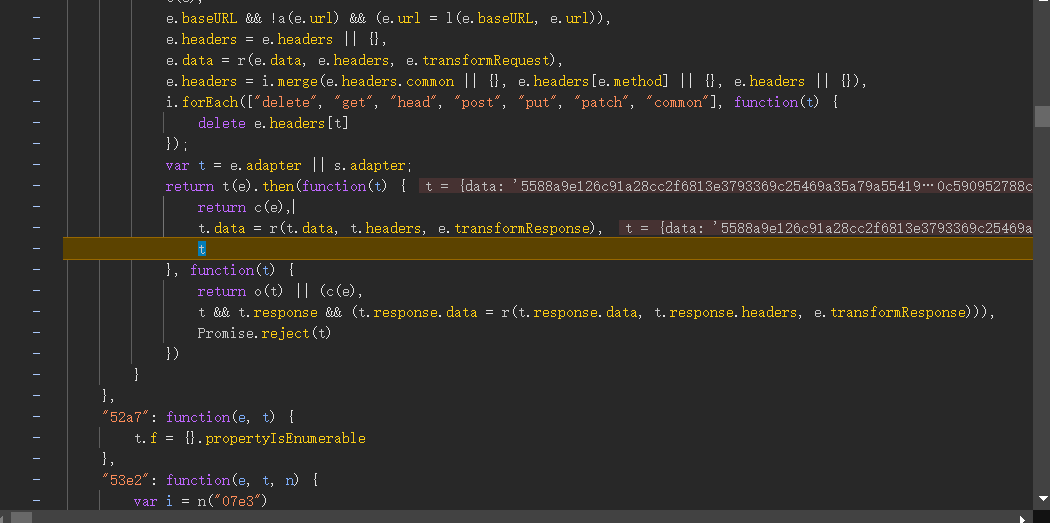
会不会是t.data = r(t.data, t.headers, e.transformResponse),一打印,欸嘿,不是这个!继续!
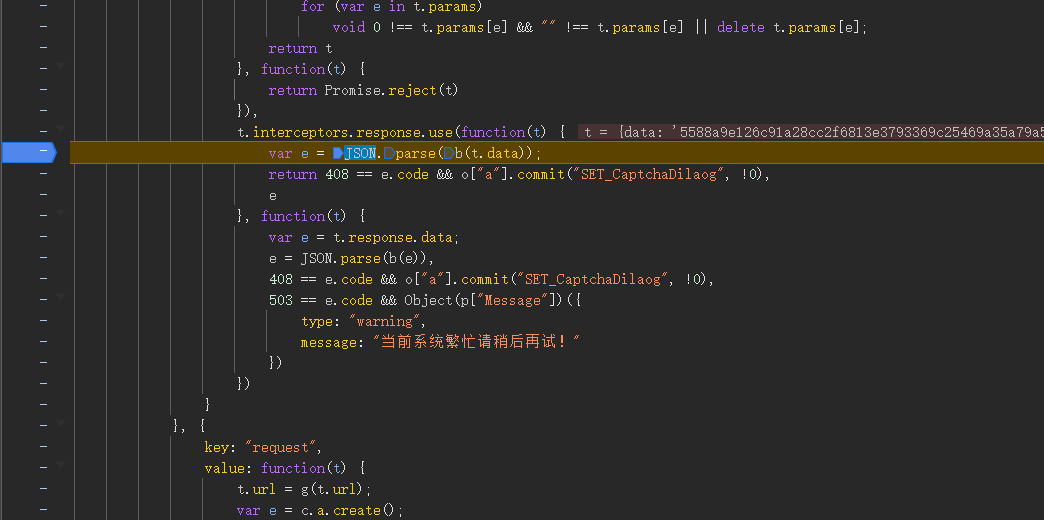
经过九九八十一难,终于找到了, var e = JSON.parse(b(t.data)),你看,hook json.parse也能找到吧!解密的函数就是b().
二、解密算法分析
那找到位置了就别磨蹭了啊,直接进去b方法中。
function b(t) {
var e = d.a.enc.Hex.parse(t)
, n = d.a.enc.Base64.stringify(e)
, a = d.a.AES.decrypt(n, f, {
iv: m,
mode: d.a.mode.CBC,
padding: d.a.pad.Pkcs7
})
, r = a.toString(d.a.enc.Utf8);
return r.toString()
}如果你对加密算法比较陌生的话,是不是看不出什么门道,但是你再看
// AES算法
const Crypto =require("crypto-js")
var key = Crypto.enc.Utf8.parse("")
var iv =Crypto.enc.Utf8.parse("")
var text =Crypto.enc.Utf8.parse("")
var result = Crypto.AES.encrypt(text,key,
{
iv: iv,
mode:Crypto.mode.CBC,
padding:Crypto.pad.Pkcs7
}).toString()
console.log(result)
// DES算法
const Crypto =require("crypto-js")
var key = Crypto.enc.Utf8.parse("123456")
var iv =Crypto.enc.Utf8.parse("1234565vnsjsbvskv lxv lxv")
var text =Crypto.enc.Utf8.parse("1234csfauyfasbubgfouabofgaogbuoag56")
var result = Crypto.DES.encrypt(text,key,
{
iv: iv,
mode:Crypto.mode.CBC,
padding:Crypto.pad.Pkcs7
}).toString()
console.log(result)AES还是DES?那么大的AES还没给你答案了吗?
还要继续扣代码吗?用标准库不香吗?
三、解密算法实现与检验
写一个标准的AES解密,把原网页js文中的密钥加上。
var CryptoJS = require("crypto-js");
var f = CryptoJS.enc.Utf8.parse("jo8j9wGw%6HbxfFn");
var m = CryptoJS.enc.Utf8.parse("0123456789ABCDEF");
function b(t) {
var e = CryptoJS.enc.Hex.parse(t);
var n = CryptoJS.enc.Base64.stringify(e);
var a = CryptoJS.AES.decrypt(n, f, {
iv: m,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
var r = a.toString(CryptoJS.enc.Utf8);
return r;
}复制一个返回的密文尝试进行解密,啊哦!
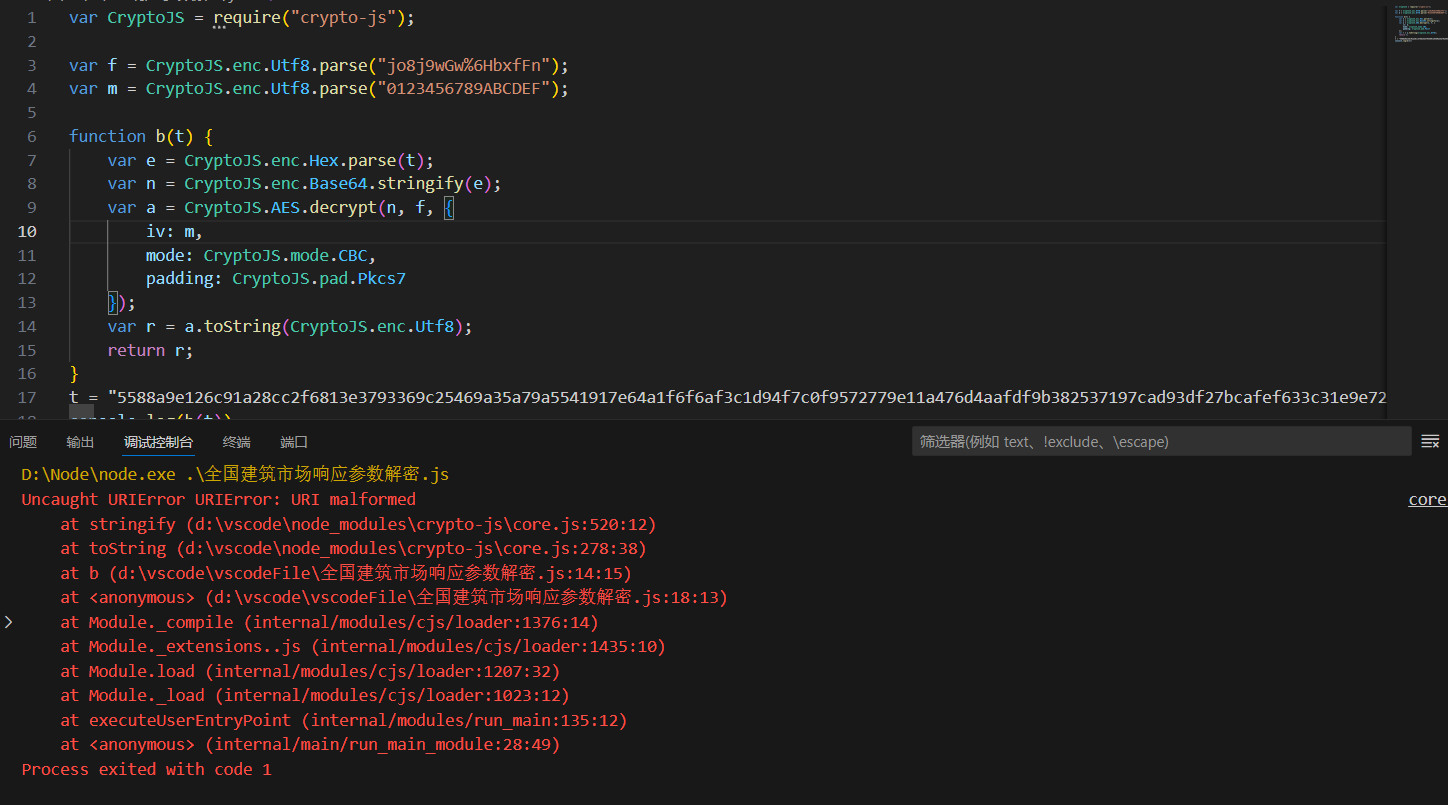 错了!哈哈哈!难道是猜错了不是标准算法?嗯哼?算法的解密密钥会不会有问题?搜索f =,你猜怎么着?不只一个地方有声明了密钥,还有一个 f = d.a.enc.Utf8.parse("Dt8j9wGw%6HbxfFn");再试试搜 m =,就一个地方。所以把f换了。
错了!哈哈哈!难道是猜错了不是标准算法?嗯哼?算法的解密密钥会不会有问题?搜索f =,你猜怎么着?不只一个地方有声明了密钥,还有一个 f = d.a.enc.Utf8.parse("Dt8j9wGw%6HbxfFn");再试试搜 m =,就一个地方。所以把f换了。
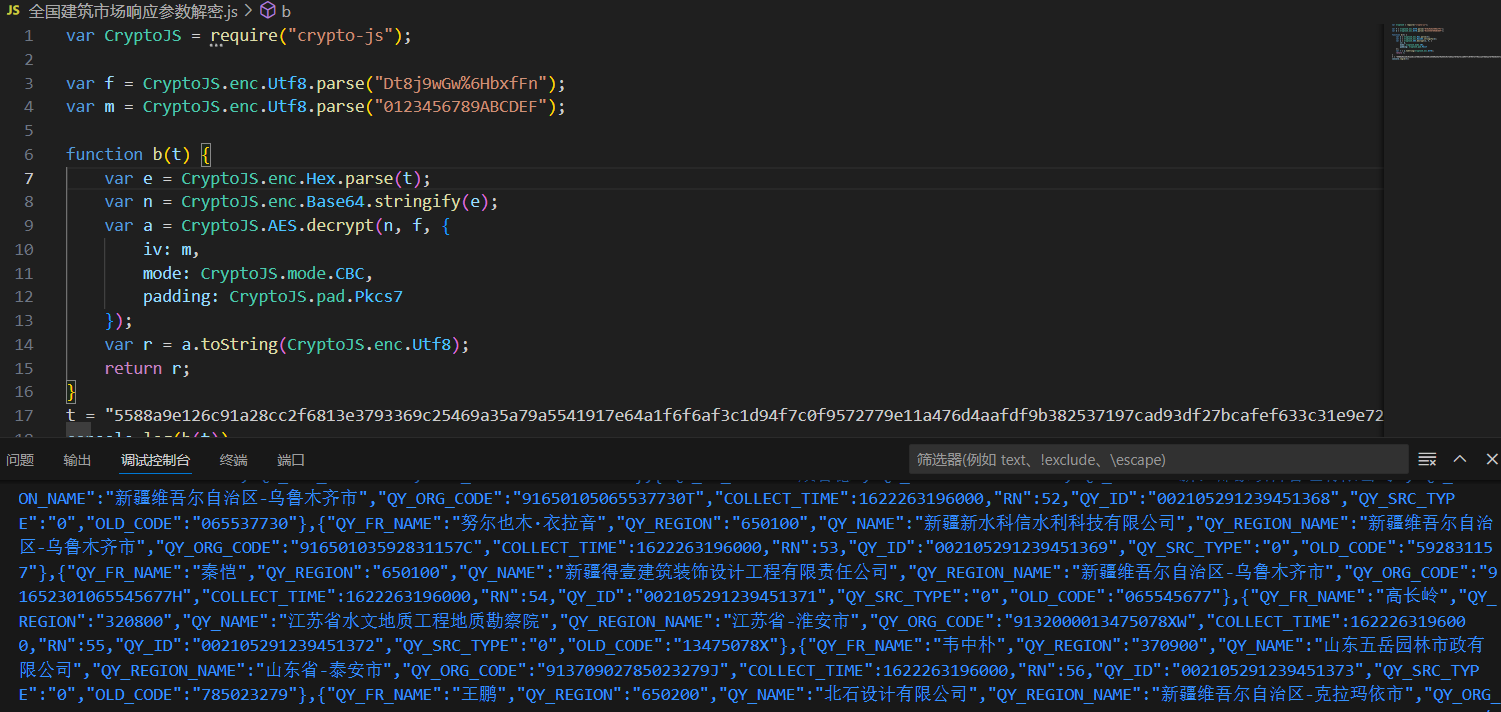
怎么着,差点就怀疑自己了,这不就拿捏了么!
如果嫌python调用js麻烦的话,也可以用python实现解密算法。
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import binascii
import base64
key = "Dt8j9wGw%6HbxfFn".encode('utf-8')
iv = "0123456789ABCDEF".encode('utf-8')
def decrypt(hex_str):
encrypted_bytes = binascii.unhexlify(hex_str)
encrypted_base64 = base64.b64encode(encrypted_bytes)
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypted_bytes = unpad(cipher.decrypt(base64.b64decode(encrypted_base64)), AES.block_size)
return decrypted_bytes.decode('utf-8')
# 示例使用
hex_string = "5588…………………………"
decrypted_message = decrypt(hex_string)
print(decrypted_message)
四、python爬虫并保存数据
这里就直接上代码了,欢迎各位大佬指正!
import requests
import execjs
import json
import warnings
from datetime import datetime
warnings.filterwarnings("ignore")
import pandas
def get_row_data(pg):
"""
获取加密后的数据
:param pg: 页码
:return:
"""
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Referer": "https://jzsc.mohurd.gov.cn/data/company",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"accessToken": "jkFXxgu9TcpocIyCKmJ+tfpxe/45B9dbWMUXhdY7vLVtP8KWPv0YyDiGL/a3LQn+hpUUKvcMtoMqfGfwdLCb8g==",
"^sec-ch-ua": "^\\^Chromium^^;v=^\\^124^^, ^\\^Google",
"sec-ch-ua-mobile": "?0",
"^sec-ch-ua-platform": "^\\^Windows^^^",
"timeout": "30000",
"v": "231012"
}
cookies = {
"Hm_lvt_b1b4b9ea61b6f1627192160766a9c55c": "1721526143",
"Hm_lpvt_b1b4b9ea61b6f1627192160766a9c55c": "1721526143",
"HMACCOUNT": "E700A2F1CF62483E"
}
url = "https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list"
params = {
"pg": pg,
"pgsz": "15",
"total": "450"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
return response.text
def dencrypt(data):
"""
解密
:param data:
:return:
"""
with open("dencrypt.js", "r", encoding="utf-8") as f:
file = f.read()
js = execjs.compile(file)
return json.loads(js.call("b", data))['data']['list']
def transform_time(timestamp):
date_time = datetime.fromtimestamp(timestamp)
# 格式化为"几年几月"的字符串
formatted_date = date_time.strftime("%Y年%m月%d日")
return formatted_date
def add_data(dencrypt_data: list, all_list: list):
"""
添加数据
:param all_list:
:param dencrypt_data:
:return:
"""
for per in dencrypt_data:
QY_FR_NAME = per['QY_FR_NAME'] # 企业法人名称
QY_NAME = per['QY_NAME'] # 企业名称
QY_ORG_CODE = per['QY_ORG_CODE'] # 企业统一社会信用代码
QY_ID = per['QY_ID']
COLLECT_TIME = transform_time(int(str(per['COLLECT_TIME'])[0:-3])) # 注册时间
all_list.append([QY_FR_NAME, QY_NAME, QY_ORG_CODE, QY_ID, COLLECT_TIME])
return all_list
def save_data(all_list: list):
"""
保存数据
"""
pandas.DataFrame(all_list, columns=['企业法人名称', '企业名称', '企业统一社会信用代码', '身份ID', '收集时间']).to_csv(
'企业信息.csv', index=False, encoding='gbk')
def main():
total_list = []
for i in range(0, 30):
try:
data = get_row_data(i)
dencrypt_data = dencrypt(data)
total_list = add_data(dencrypt_data, total_list)
except:
print('搜索第' + str(i + 1) + '页失败')
save_data(total_list)
if __name__ == '__main__':
main()

















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









