







一、why
夏天到来,当哥们儿想打开抖音刷到一些比较凉快的视频,动不动就上万的评论,手痒就想看看众位爱卿的虎狼之词,但是一条条翻可不是我们的风格,所以直接F12
二、How
(一)打开视频,打开开发者工具,开始抓包!
但是抓包时会碰到不停的弹VM文件,这就是一种简单的反扒机制,只需要右键单价左侧的断点,永不在此处暂停或者停用断点就能解决!
(二)分析各个包!
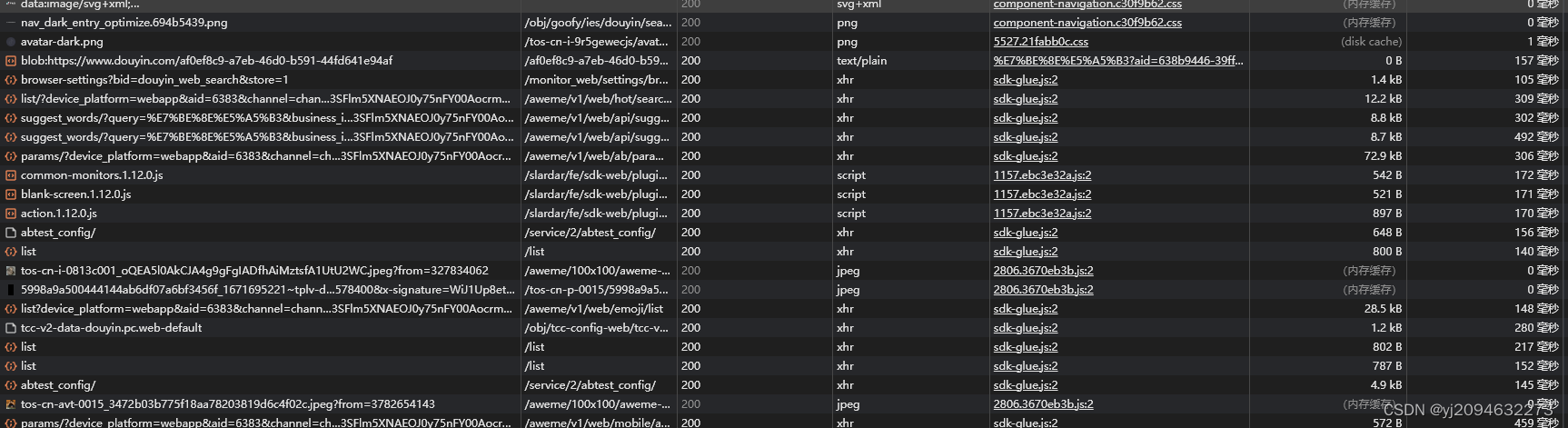
1.抓到的包正可谓是一堆shit,但是没办法,还是得挨个看,找到我们需要的那个请求!这时候就可以使用浏览器的过滤功能。我们需要的是获得服务器返回的评论数据,而不是CSS装饰文件,也不是JS执行文件,也不是图片视频等媒体文件,而是一种xhr/fetch请求。

所以在不选全部,选择Fetch/XHR
2.过滤之后就清爽很多了!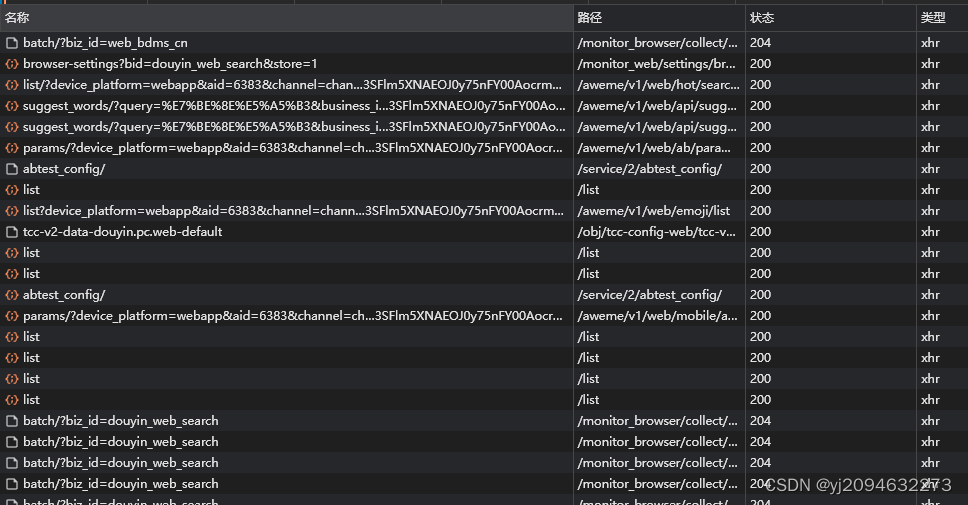
接下来就是一条条的筛选看返回的数据。
3.经过三七二十一秒的寻找就定位到了https://www.douyin.com/aweme/v1/web/comment/list/?device_platform=webapp&aid https://www.douyin.com/aweme/v1/web/comment/list/?device_platform=webapp&aid
https://www.douyin.com/aweme/v1/web/comment/list/?device_platform=webapp&aid
的接口,接下来就是分析这个接口的请求体和返回数据的格式与解析了!
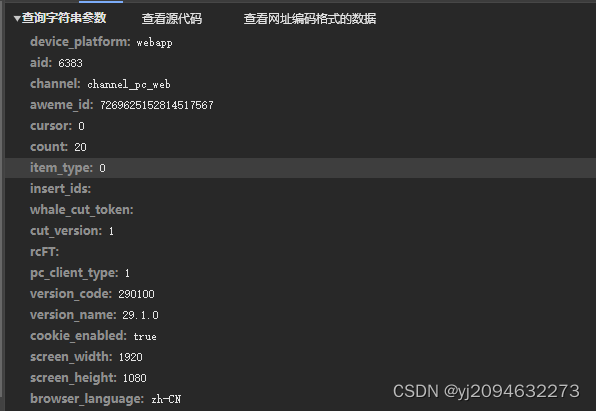
![]()
4.这个请求参数是不是看的脑瓜子嗡嗡的!这个时候我们就要理性思考了!是不是每一个参数都要在每一次请求的时候变化?所以我们就现抓一个视频的多次评论然后再抓不同视频的评论,看看参数的变化!
经过研究发现,aweme_id在同一视频的请求下是不变的,而cursor和count是变化的(其实就是cursor就是从第几条评论开始,count就是每次请求的评论数),至于webid就是你自己的账号,msToken和a_bogus的话有兴趣有能力的小伙伴可以去逆向一下,这个参数不变也是可以的。
5、直接右键选择cmd格式复制并在爬虫工具中将其转为python的requests请求!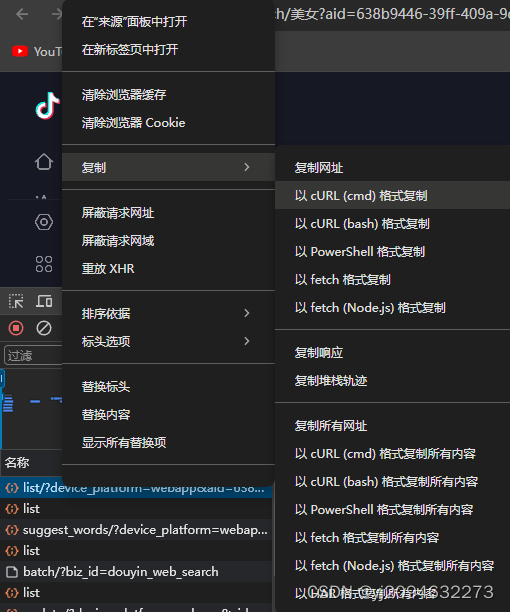
得到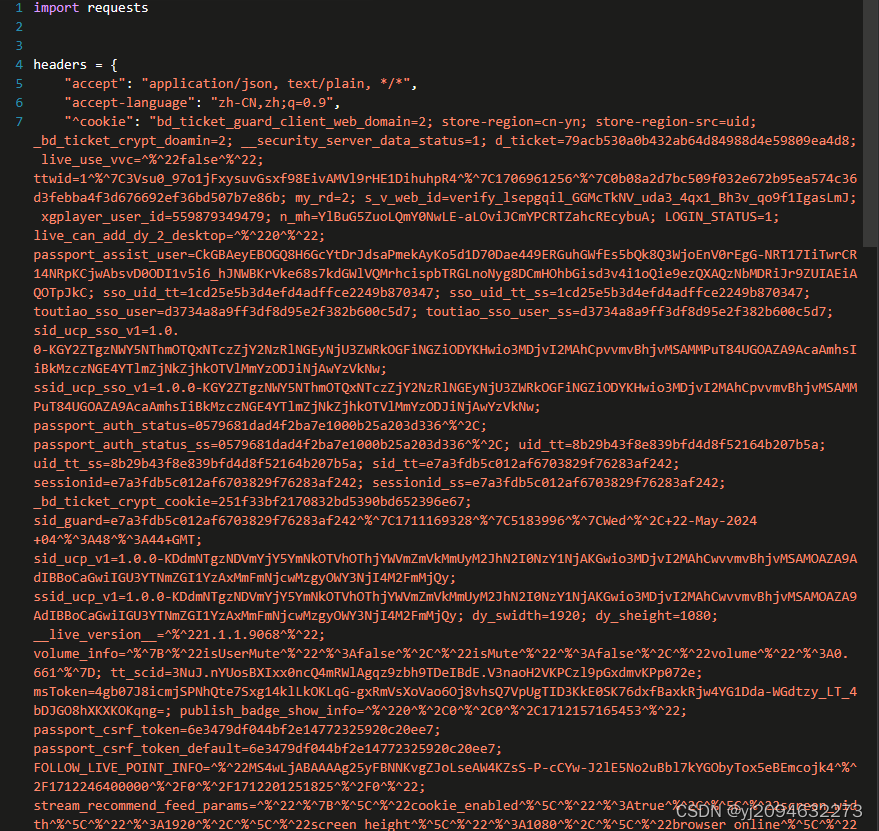
然后将其复制到我们的python文件里,运行。这时候有的同学可能就会发现就输出了一个<Response [200]>,没有其他输出,这其实是因为在换格式时一些小问题,我们只要找到类似![]() https之前的^删除,如果还是不行,就去headers里把类似的格式改一改。最后就可以看到
https之前的^删除,如果还是不行,就去headers里把类似的格式改一改。最后就可以看到 的数据输出了。
的数据输出了。
6.至于如果要批量获得,我们就要把请求封装成函数,然后把cursor、count和aweme_id作为参数传入。

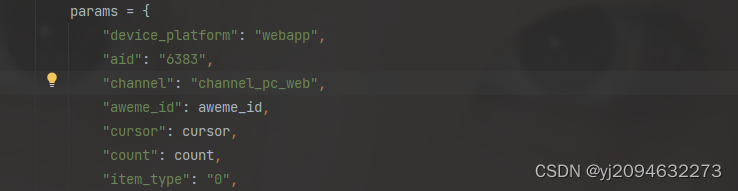
简易的代码可以为:
 至此我们就达成了第一步的第一步!后续还会有更新喔!还有二级评论和数据处理!
至此我们就达成了第一步的第一步!后续还会有更新喔!还有二级评论和数据处理!

















 1700
1700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









