







原创来自本人的公众号:阿嚏个技术
目前有很多采取深度学习的方式,进行图片验证码的文字识别,然后实现打码功能。本文采用darknet+yolo4的深度学习框架来实现图片文字识别,当然该框架可以做的事情很多,还能对视频内容进行标识识别。
相关的内容应该会分三期制作,本期内容主要是针对该系统在windows环境下的编译和运行,之前看了些文章和视频很少一次性编译成功的。我把整个编译过程录成了视频,特别是对编译过程中碰到的坑,进行了讲解,应该对有兴趣的同学有帮助。
darknet+yolo4在windows环境下的图片和视频内容识别,之一:windows环境下的编译和运行
1、资源文件
项目源码、安装文件以及其他文件放在网盘,可供大家下载,包括:
Darknet + Yolo4源码
CUDA 11.1(上面源码的darknet.vcxproj中默认的版本,否则需要修改该文件)
cuDNN 8.2
Opencv 4.5.5
VS2019
yolo4.weights
yolo3-tiny.weights
网盘链接:https://pan.baidu.com/s/17xSElt4P1BE-xLA9GIMGJA
提取码:xkqr
2、环境运行文件配置
1)复制CUDA文件
把C:\Program Files\NVIDIA GPU ComputingToolkit\CUDA\v11.1\extras\visual_studio_integration\MSBuildExtensions所有文件复制到C:\ProgramFiles (x86)\Microsoft VisualStudio\2019\Community\MSBuild\Microsoft\VC\v160\BuildCustomizations下
2)复制cuDnn文件
把cuDnn压缩目录下cuda目录下的所有文件复制到C:\ProgramFiles\NVIDIA GPU Computing Toolkit\CUDA\v11.1
3、VS2019配置
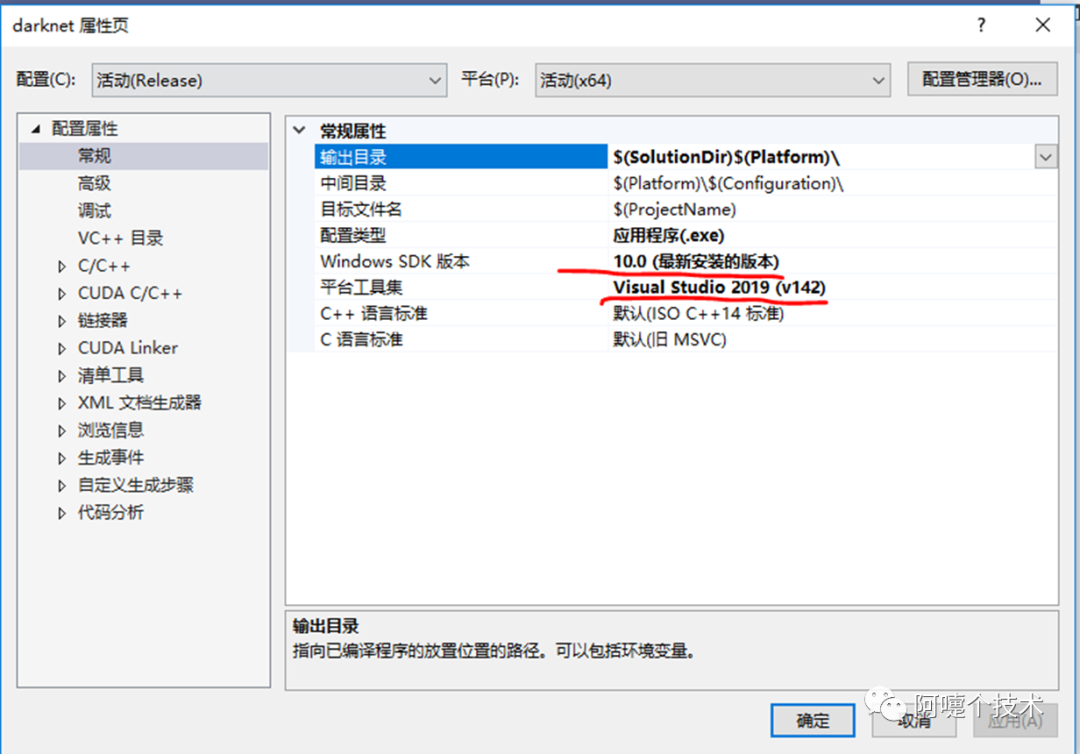
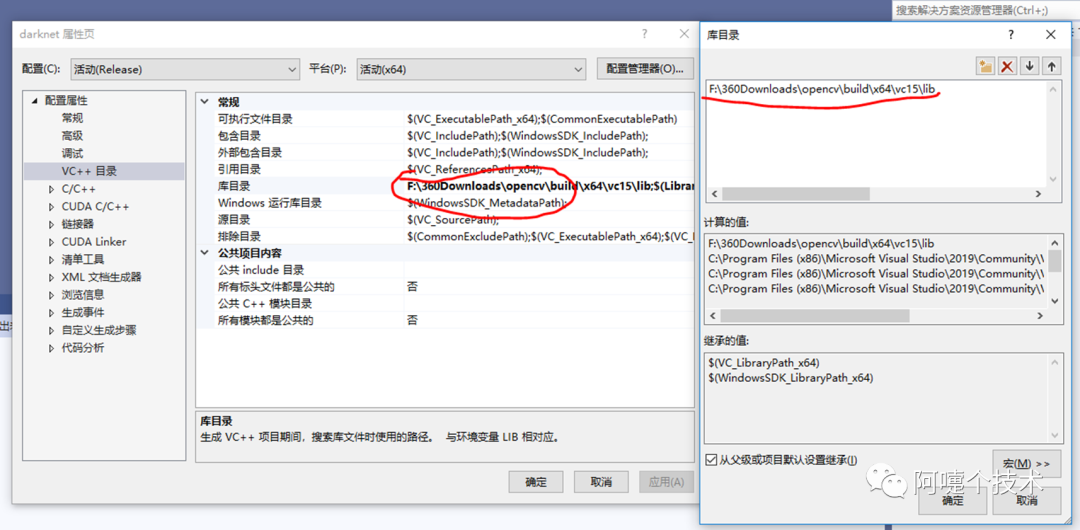
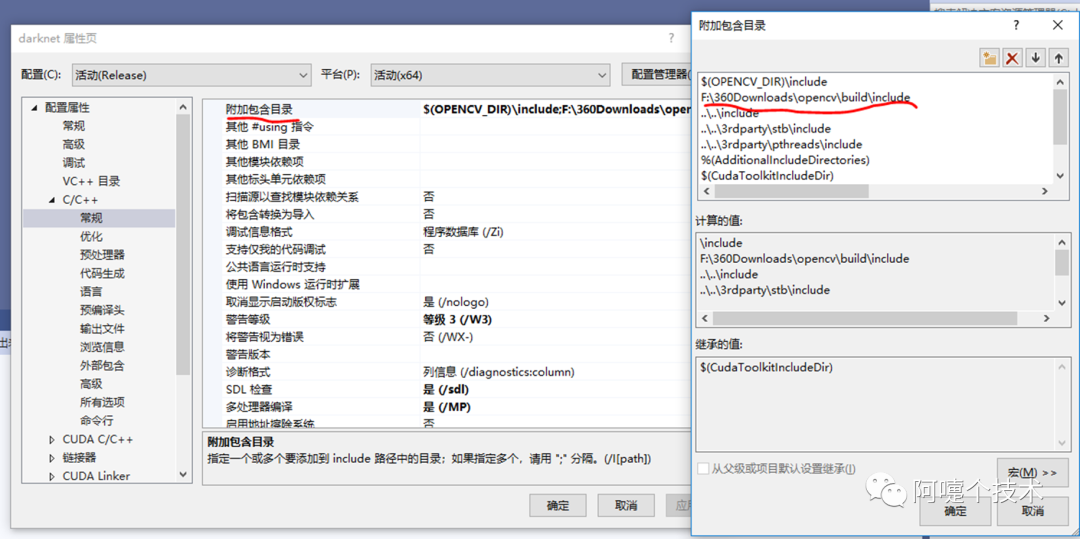
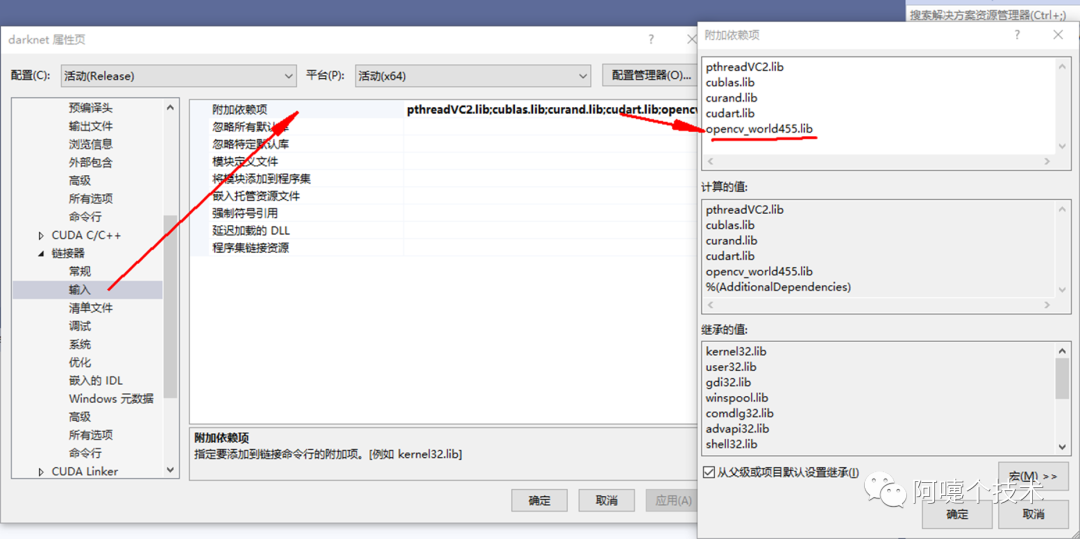
4、编译和运行
进行工程目录下的build->darknet目录,通过vs2019打开darknet.sln。然后把opencv\build\x64\vc15\bin下的opencv_videoio_ffmpeg455_64.dll、opencv_world455.dll,yolov4.weights,yolov3-tiny.weights复制到生成的darknet运行目录下,这样整个项目的运行环境就完成了。然后在powershell中通过下面2个命令,可以分别获得图片和视频上内容的识别和标注。
图片识别命令:.\darknet.exe detect .\cfg\yolov4.cfg .\yolov4.weights .\data\dog.jpg
视频识别命令:./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights .\data\dog.mp4
效果还是不错的,具体可见上面的视频。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









