







1、简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
2、首先需要我们导入相关的jar包。
3、创建一个实体用来表示查询的信息。创建LuceneEntity。
package com.mhss.entity;
public class LuceneEntity {
private Integer id; //ID
private String title; //标题
private Double money; //金额
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Double getMoney() {
return money;
}
public void setMoney(double money) {
this.money = money;
}
public LuceneEntity(Integer id, String title, double money) {
super();
this.id = id;
this.title = title;
this.money = money;
}
public LuceneEntity() {
super();
}
}
4、创建Lucene方法,用于创建所有和查询索引。
package com.mhss.lucene;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.DoubleField;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
import com.mhss.entity.LuceneEntity;
/**
* Lucene 索引,用于创建索引,查询索引
* @author 梦幻逝水
*
*/
public class Lucene {
/**创建索引的文件位置**/
private static final String PATH = "D://lucene/";
/**
* 创建索引
*/
public static void createIndex(List<LuceneEntity> lucenes) {
Directory directory = null;
IndexWriter indexWriter = null;
try {
directory = FSDirectory.open(new File(PATH));
IndexWriterConfig iwConfig = new IndexWriterConfig(Version.LUCENE_46, new IKAnalyzer(true));
indexWriter = new IndexWriter(directory, iwConfig);
Document doc = null;
// 遍历信息创建索引
for (LuceneEntity lucene : lucenes) {
doc = new Document();
// 对title进行分词存储
doc.add(new TextField("title", lucene.getTitle(), Store.YES));
// 对id、money不分词存储
doc.add(new IntField("id", lucene.getId(), Store.YES));
doc.add(new DoubleField("money", lucene.getMoney(), Store.YES));
indexWriter.addDocument(doc);
}
indexWriter.close();
directory.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 从索引文件中根据问题检索答案
*
* @param content
* @return Knowledge
*/
@SuppressWarnings("deprecation")
public static List<LuceneEntity> searchIndex(String title) {
List<LuceneEntity> lucenesEntities = new ArrayList<LuceneEntity>();
try {
Directory directory = FSDirectory.open(new File(PATH));
IndexReader reader = IndexReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 使用查询解析器创建Query
QueryParser questParser = new QueryParser(Version.LUCENE_46, "title", new IKAnalyzer(true));
Query query = questParser.parse(QueryParser.escape(title));
// 检索得分最高的文档,第二个参数控制索引出来的数量。
TopDocs topDocs = searcher.search(query, 3);
if (topDocs.totalHits > 0) {
ScoreDoc[] scoreDoc = topDocs.scoreDocs;
for (ScoreDoc sd : scoreDoc) {
Document doc = searcher.doc(sd.doc);
LuceneEntity lucene = new LuceneEntity();
lucene.setId(doc.getField("id").numericValue().intValue());
lucene.setMoney(new Double(doc.get("money")));
lucene.setTitle(doc.get("title"));
lucenesEntities.add(lucene);
}
}
reader.close();
directory.close();
} catch (Exception e) {
lucenesEntities = null;
e.printStackTrace();
}
return lucenesEntities;
}
/**
* 删除文件夹内所有的内容
* @param file
*/
private static void deleteAll(File file) {
if(file != null){
if (file.isFile()) {
file.delete();
} else {
File[] files = file.listFiles();
if(files == null) return;
for (int i = 0; i < files.length; i++) {
deleteAll(files[i]);
files[i].delete();
}
if (file.exists()) // 如果文件本身就是目录 ,就要删除目录
file.delete();
}
}
}
public static void main(String[] args) {
List<LuceneEntity> lucenesEntities = new ArrayList<LuceneEntity>();
LuceneEntity l1 = new LuceneEntity(1,"连衣裙裙子",30d);
LuceneEntity l2 = new LuceneEntity(2,"半身裙裙子",40d);
LuceneEntity l3 = new LuceneEntity(3,"裤裙",50d);
LuceneEntity l4 = new LuceneEntity(4,"上衣",19.9d);
LuceneEntity l5 = new LuceneEntity(5,"裤子",39d);
LuceneEntity l6 = new LuceneEntity(6,"打底裤",100d);
lucenesEntities.add(l1);
lucenesEntities.add(l2);
lucenesEntities.add(l3);
lucenesEntities.add(l4);
lucenesEntities.add(l5);
lucenesEntities.add(l6);
//为避免创建索引是,新索引与就索引重复,造成测试结果误差。
deleteAll(new File(PATH));
//创建索引
Lucene.createIndex(lucenesEntities);
//检索索引信息
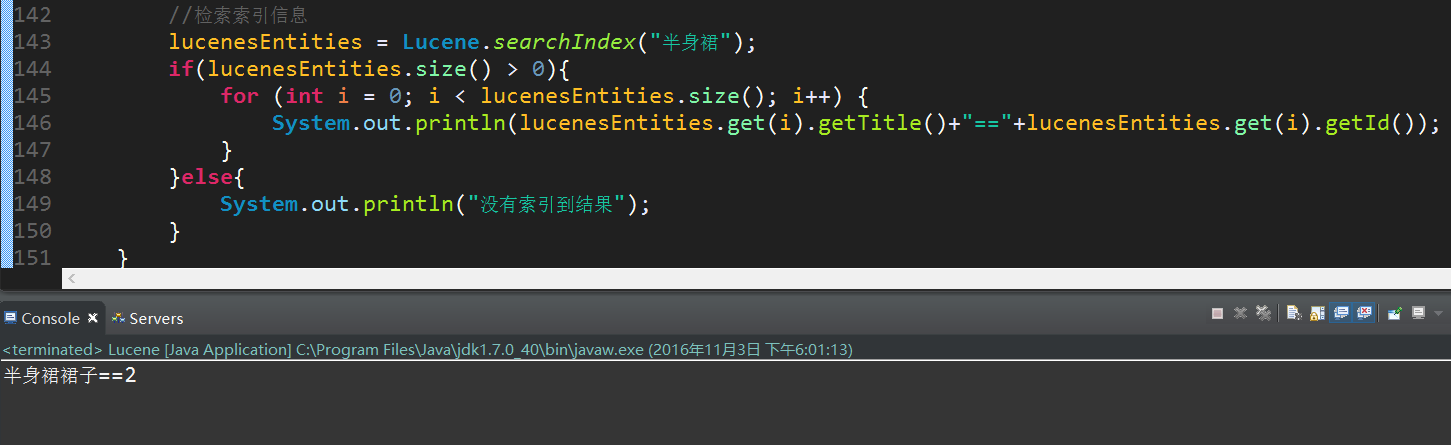
lucenesEntities = Lucene.searchIndex("半身裙");
if(lucenesEntities.size() > 0){
for (int i = 0; i < lucenesEntities.size(); i++) {
System.out.println(lucenesEntities.get(i).getTitle()+"=="+lucenesEntities.get(i).getId());
}
}else{
System.out.println("没有索引到结果");
}
}
}
5、运行结果
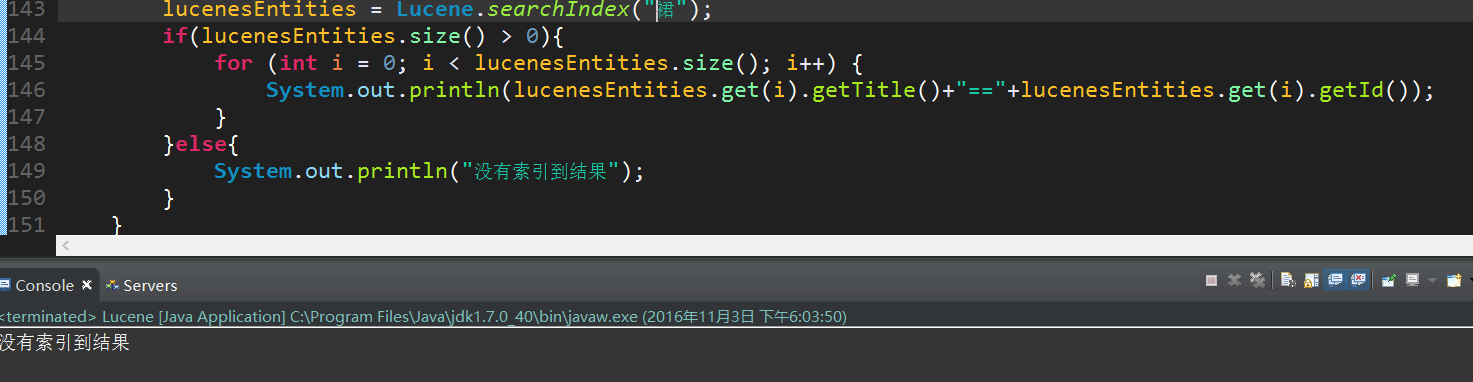
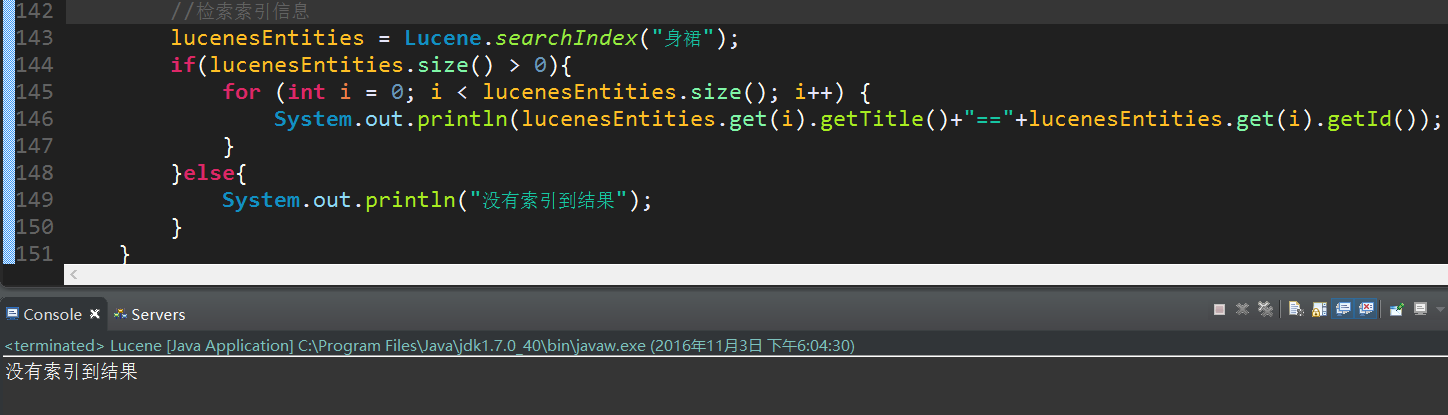
并且Lucene在分词上做的也非常好,例如查询的不是一个单词,即使有标题中有这几个字,也不认为是相关项而被忽略。
Demo源代码下载:https://www.yangjiace.xyz/















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









