






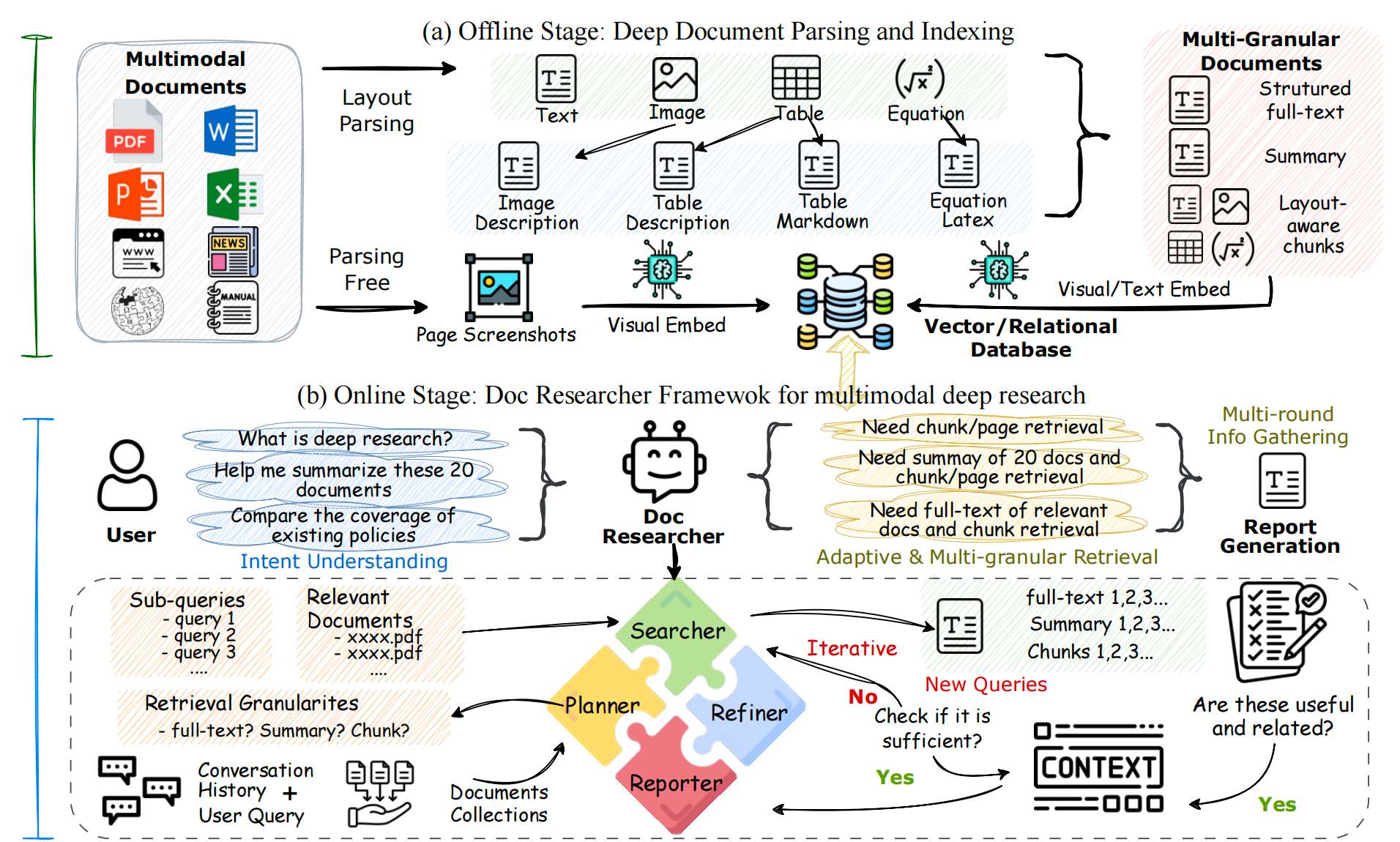
整体偏向工程实现,Doc-Researcher从名字可以看出,首先这个框架需要进行文档解析提取文档的图文多模态元素,文档解析相关技术链路《文档智能》。其次是多模态深度研究(通过迭代分解问题、积累证据、验证信息,实现多文档、多跳、多轮的深度推理。)和衔接两者的多模态检索架构。
下面简单看下思路。
方法架构
整体架构分三个模块:文档解析、多模态检索和多模态deepResearch。
模块1:深度多模态文档解析
与多数的《RAG》知识库构建组件相同,都需要对文档进行深度解析,尽可能的保留文档的所有元素信息。该框架使用的是MinerU解析文档中的(文本/表格/图表/公式)、边界框坐标(精确到页面像素,用于后续定位引用)等信息。表格/图表:用Qwen2.5-VL生成两类描述:(1)粗粒度摘要(如“2023年A股市值Top5行业分布表”):用于快速匹配查询意图;(2)细粒度描述(如“第一列是行业名称,第二列是市值占比,金融行业占比28%”):用于精确证据提取;
多粒度分块策略
单一元素(如孤立表格)缺乏上下文,需通过布局分析模型合并生成多粒度单元。定义了4个核心粒度级别 G = { chunk, page, full, summary } G = \{\text{chunk, page, full, summary}\} G={chunk, page, full, summary}
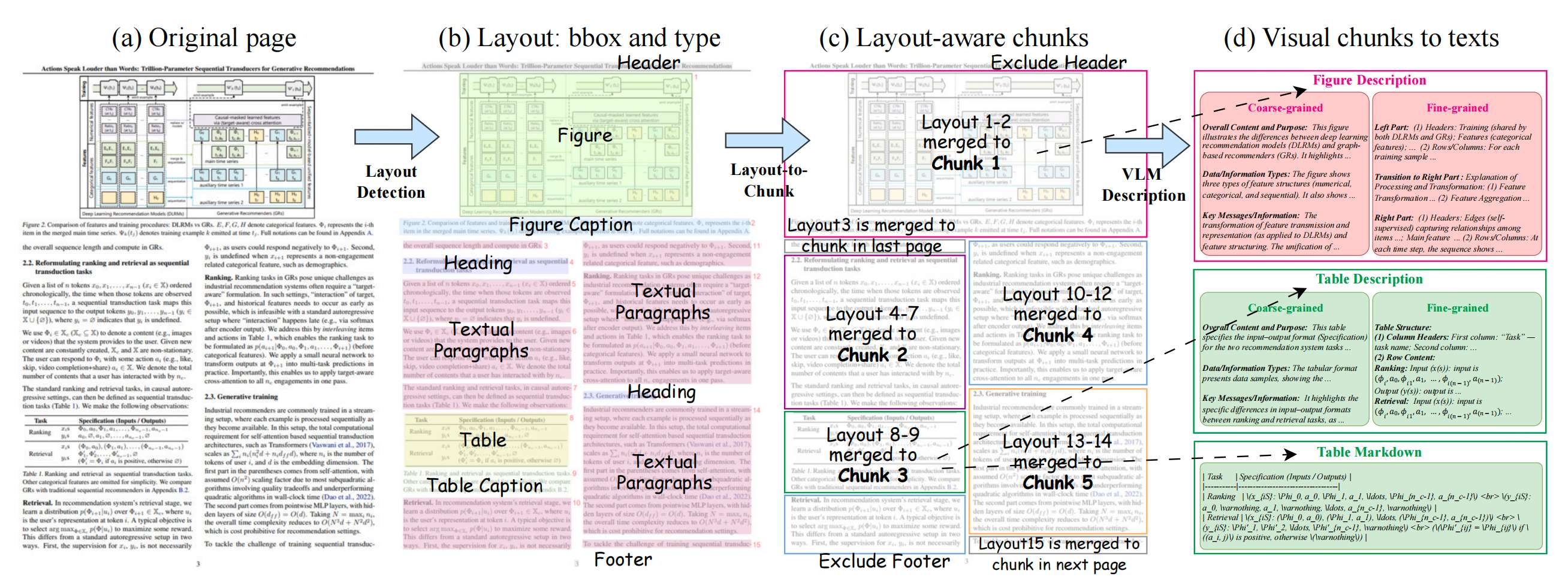
- Chunk(块) : 在章节边界内合并文本/表格/图表元素,限制最大长度(避免跨章节语义断裂),保留每个元素的边界框坐标
- Page(页面) :两种形式:
1. 合并单页所有元素(含文本+转录后的表格/公式);
2. 原始页面截图(用于纯视觉检索) - Full(全文) : 合并文档所有元素,形成完整结构化文本(含章节层级、公式LaTeX、表格描述)
- Summary(摘要) : 用LLM对“Full”粒度文本生成摘要,突出核心结论/结构

模块2:多模态检索架构
三种检索范式的设计与对比:
- 纯视觉检索 :以“Page”粒度的原始截图为检索单元,用视觉模型(如Jina-embedding-v4)直接编码截图为向量,匹配查询的视觉特征(需将查询转视觉向量或用跨模态模型匹配)
- 纯文本检索 :以“Chunk/Page/Full/Summary”粒度的文本转录结果为单元(含OCR文本、表格/图表描述、公式LaTeX),用文本嵌入模型(如BGE-M3)编码匹配
- 混合检索 :结合两种范式:(1)文本检索器编码“Chunk/Full/Summary”的文本;(2)视觉检索器编码“Page/Chunk”的截图;(3)融合两类检索结果(如加权排序)
模块3:多模态Deep Research
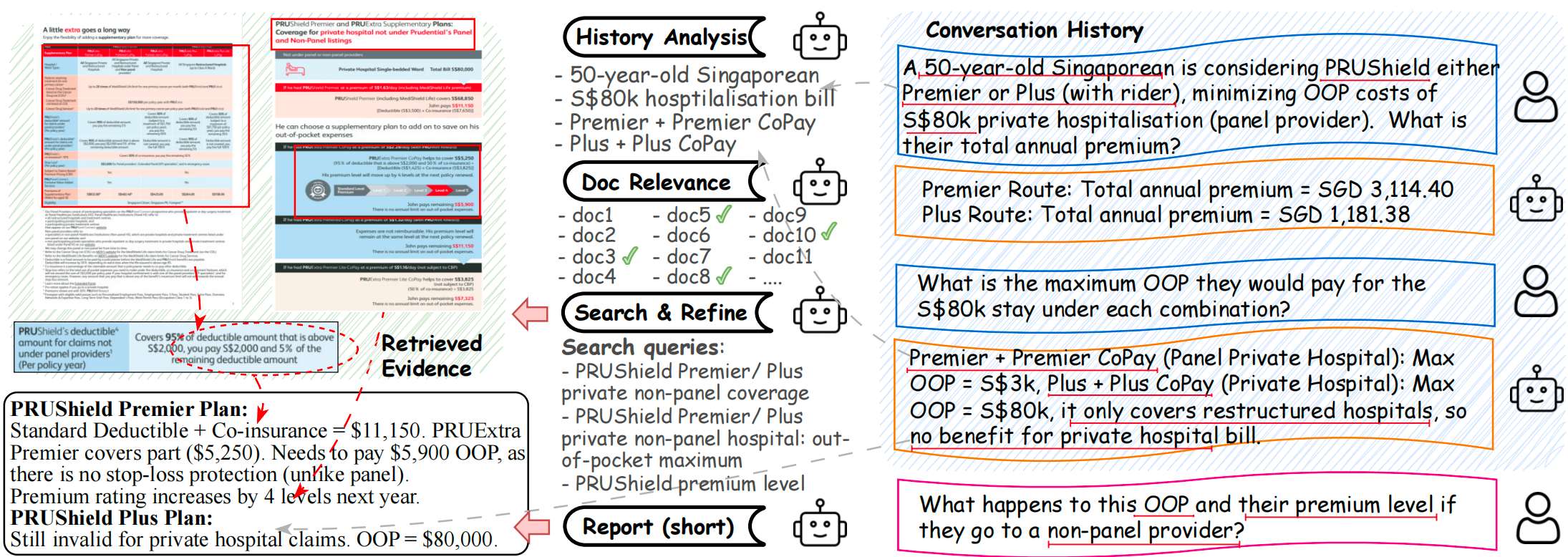
通过多智能体协作的迭代流程,模拟人类“分解问题→搜索证据→验证补充→合成结论”的研究过程。
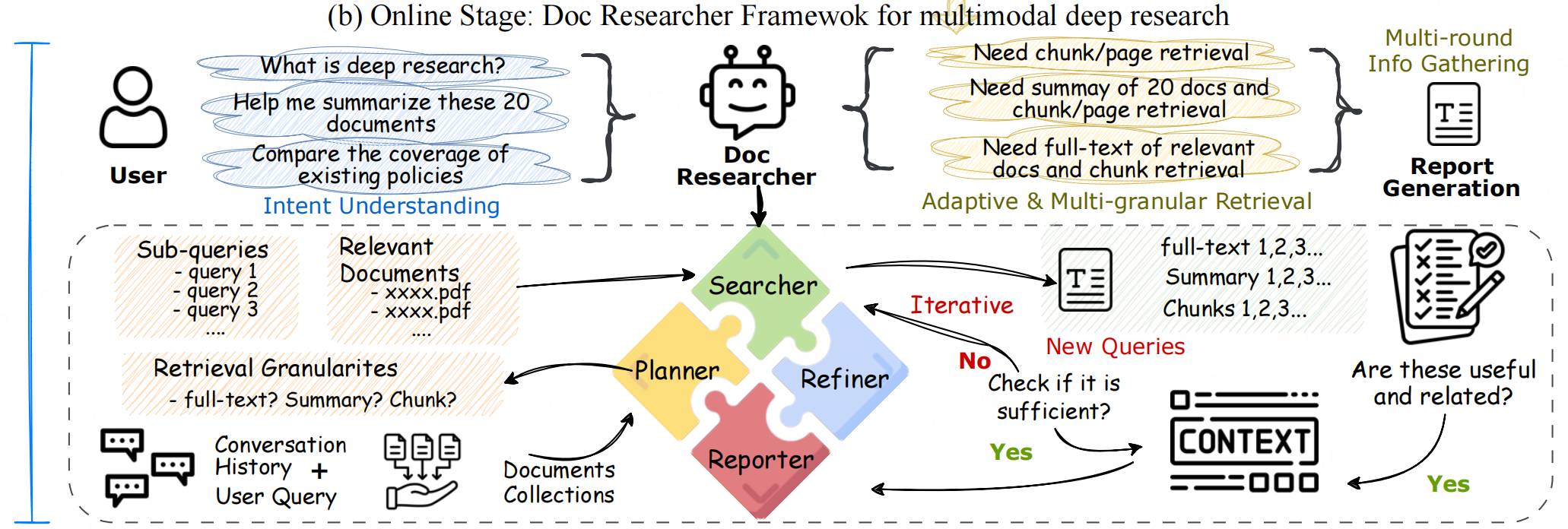
如上图,系统包含4个Agent:
1. 规划器(Planner)
输入:用户查询、对话历史、文档集合
输出:1. 过滤后相关文档子集(缩小搜索范围);2. 最优检索粒度(如摘要 / 块 / 页面);3. 细化子查询(分解复杂问题)
2. Searcher+ Refiner
核心是通过多轮搜索-精炼循环,逐步补充高质量证据,避免单轮检索的“证据不足”或“噪声过多”问题:
- Searcher:证据初筛,基于多模态检索架构(文本 / 视觉 / 混合),获取初始多模态证据(文本块、表格截图、图表等)
- Refiner:证据提纯,1. 去重(删除重复证据);2. 相关性过滤(剔除无关内容);3. 输出精炼后高质量证据
3. Reporter
输入:用户查询、累计精炼证据、解析阶段记录的引用元数据(证据对应的文档ID、页面ID、边界框坐标);
输出:多模态报告,特点:
- 自动插入证据中的表格/图表截图(而非仅文本描述),并搭配解释
- 每个结论后标注证据来源,用户可直接定位到原始文档位置验证,解决LLM生成“幻觉”问题;
- 根据查询类型生成对应结构
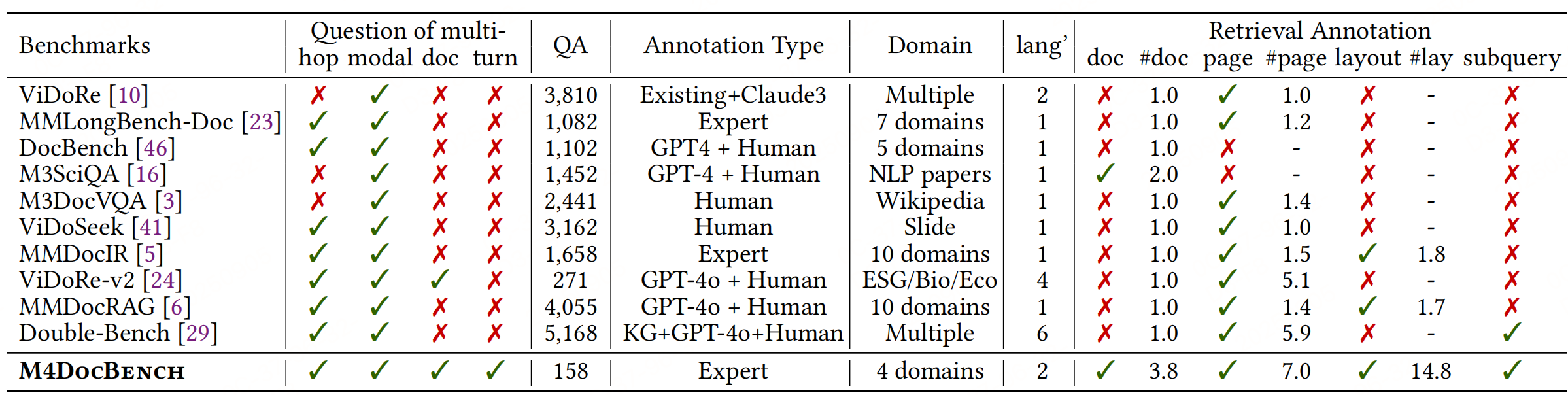
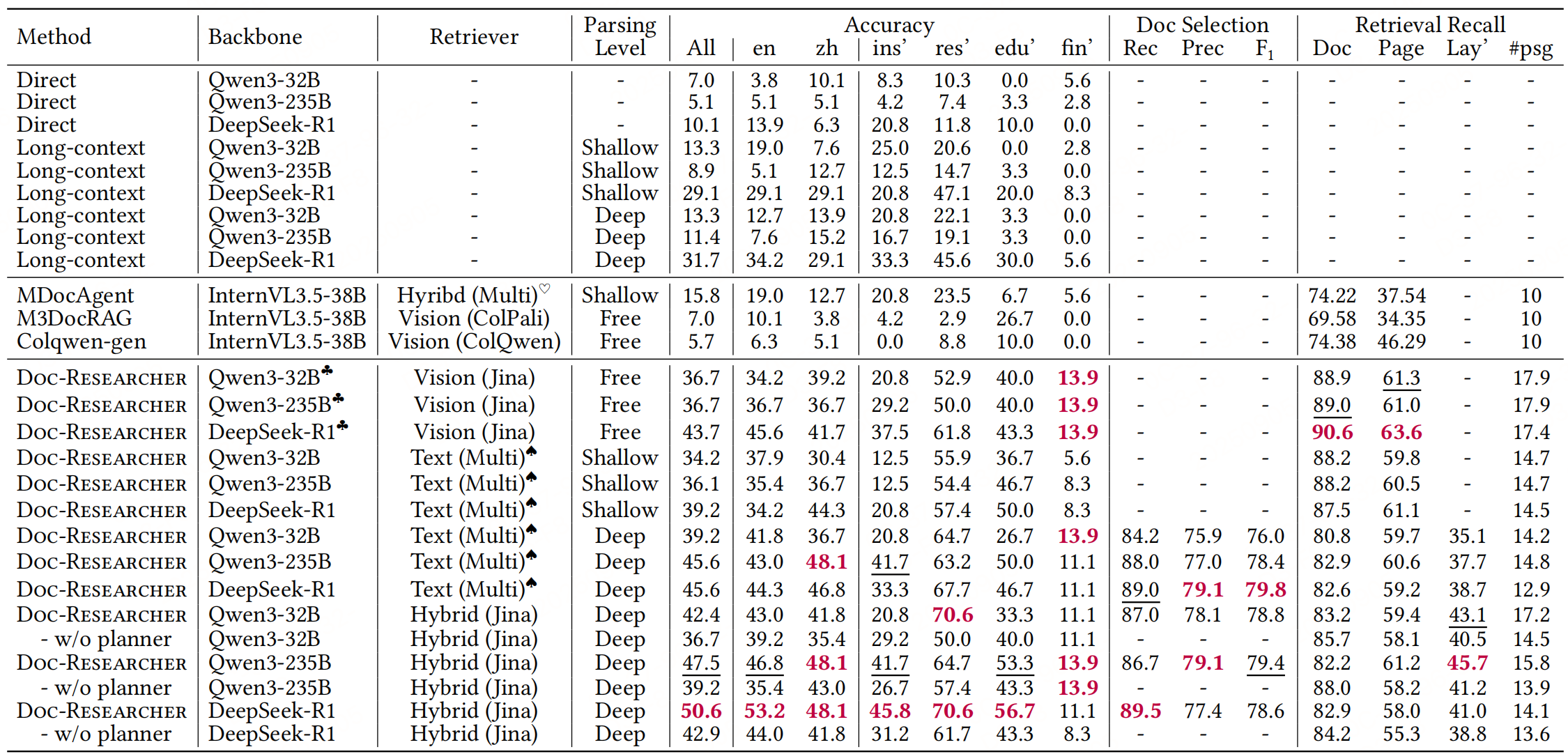
实验性能
参考文献:Doc-Researcher: A Unified System for Multimodal Document
Parsing and Deep Research,https://arxiv.org/pdf/2510.21603v1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









