






530.二叉搜索树的最小绝对差 (双指针)
给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。
示例:

提示:树中至少有 2 个节点
思路
题目中要求在二叉搜索树上任意两节点的差的绝对值的最小值。
注意是二叉搜索树,二叉搜索树可是有序的。(我一开始没有立马想到!!!说明对二叉树的性质还不够了解!)
遇到在二叉搜索树上求什么最值啊,差值之类的,就把它想成在一个有序数组上求最值,求差值,这样就简单多了
一、递归
1.转化为数组
那么二叉搜索树采用中序遍历,其实就是一个有序数组。
在一个有序数组上求两个数最小差值,这是不是就是一道送分题了。
最直观的想法,就是把二叉搜索树转换成有序数组,然后遍历一遍数组,就统计出来最小差值了(我看完卡子哥思路发现就是利用二叉树性质时,我也是这么想的)。
代码如下:
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);//--左
vec.push_back(root->val); // 将二叉搜索树转换为有序数组--中
traversal(root->right);//--右
}
public:
int getMinimumDifference(TreeNode* root) {
vec.clear();
traversal(root);
if (vec.size() < 2) return 0;
int result = INT_MAX;//先初始化为最大值
for (int i = 1; i < vec.size(); i++) { // 统计有序数组的最小差值
result = min(result, vec[i] - vec[i-1]);//善用min和max函数真的可以简化代码(我的弱点)
}
return result;
}
};
以上代码是把二叉搜索树转化为有序数组了
2.双指针
其实在二叉搜素树中序遍历的过程中,我们就可以直接计算了。
需要用一个pre节点记录一下cur节点的前一个节点。
如图:
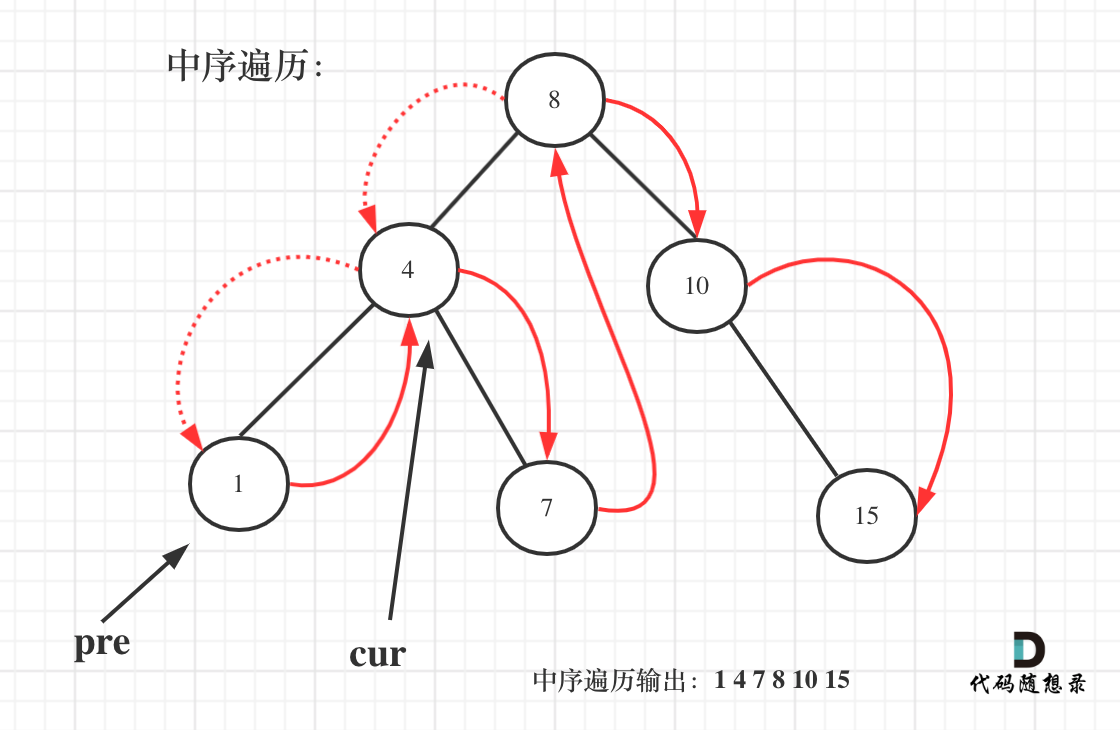
一些同学不知道在递归中如何记录前一个节点的指针,其实实现起来是很简单的,大家只要看过一次,写过一次,就掌握了。
代码如下:
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中,并且排除了cur刚刚走到二叉搜索树最小值结点时pre还等于NULL的情况
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
是不是看上去也并不复杂。
二、迭代
看过这两篇二叉树:听说递归能做的,栈也能做! (opens new window),二叉树:前中后序迭代方式的写法就不能统一一下么? (opens new window)文章之后,不难写出两种中序遍历的迭代法。
因为递归的本质就是栈,所以其实用栈能解决所有需要使用递归的问题;递归最重要的特性就是可以先遍历到最后的结点,然后再回溯处理——栈因为有先进后出、后进先出的性质,所以也可以实现“先遍历到最后的结点,然后再回溯处理”
下面我给出其中的一种中序遍历的迭代法,代码如下:
class Solution {
public:
int getMinimumDifference(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int result = INT_MAX;
while (cur != NULL || !st.empty())
{
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
}
else {
cur = st.top();
st.pop();
if (pre != NULL) { // 中
result = min(result, cur->val - pre->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};
总结
遇到在二叉搜索树上求什么最值,求差值之类的,都要思考一下二叉搜索树可是有序的,要利用好这一特点。
501.二叉搜索树中的众数
给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。
假定 BST 有如下定义:
-
结点左子树中所含结点的值小于等于当前结点的值
-
结点右子树中所含结点的值大于等于当前结点的值
-
左子树和右子树都是二叉搜索树
例如:
给定 BST [1,null,2,2],

返回[2].
提示:如果众数超过1个,不需考虑输出顺序
进阶:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
我的思路:用一个数组或者哈希表来存储每个出现过的数值的出现次数,但是这个好像空间开销蛮大的。(看完卡子哥思路后,我发现卡子哥说的不是二叉搜索树的情况的解决办法——》但是这是个二叉搜索树,所以我在中序遍历的时候只要用一个变量来记录相邻项出现相同数值的次数,并且用一个数组来动态存储当前出现频率最高的数值(用数组是因为可能有几个数值出现的频率相同)——看完卡子哥的思路以后,我发现卡子哥的思路和我的一样
卡子哥思路
这道题目呢,递归法我从两个维度来讲。
首先如果不是二叉搜索树的话,应该怎么解题,是二叉搜索树,又应该如何解题,两种方式做一个比较,可以加深大家对二叉树的理解。
一、迭代法
1.不是二叉搜索树
如果不是二叉搜索树,最直观的方法一定是把这个树都遍历了,用map统计频率,把频率排个序,最后取前面高频的元素的集合。
具体步骤如下:
(1)这个树都遍历了,用map统计频率
至于用前中后序哪种遍历也不重要,因为就是要全遍历一遍,怎么个遍历法都行,层序遍历都没毛病!
这里采用前序遍历,代码如下:
// map<int, int> key:元素,value:出现频率
void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历
if (cur == NULL) return ;
map[cur->val]++; // 统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
(2)把统计的出来的出现频率(即map中的value)排个序
有的同学可能可以想直接对map中的value排序,还真做不到,C++中如果使用std::map或者std::multimap可以对key排序,但不能对value排序(知识漏洞)。
所以要把map转化数组即vector,再进行排序,当然vector里面放的也是pair<int, int>类型的数据,第一个int为元素,第二个int为出现频率。
代码如下:
bool static cmp (const pair<int, int>& a, const pair<int, int>& b)
{
return a.second > b.second; // 按照频率从大到小排序
}
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); // 给频率排个序
(3)取前面高频的元素
此时数组vector中已经是存放着按照频率排好序的pair,那么把数组最前面的元素取出来就可以了。
代码如下:
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++)
{
// 取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
整体C++代码如下:
class Solution {
private:
void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历
if (cur == NULL) return ;
map[cur->val]++; // 统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second;
}
public:
vector<int> findMode(TreeNode* root) {
unordered_map<int, int> map; // key:元素,value:出现频率
vector<int> result;
if (root == NULL) return result;
searchBST(root, map);
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); // 给频率排个序
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++) {
// 取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
}
};
所以如果本题没有说是二叉搜索树的话,那么就按照上面的思路写
2.是二叉搜索树
既然是搜索树,它中序遍历就是有序的。
如图:
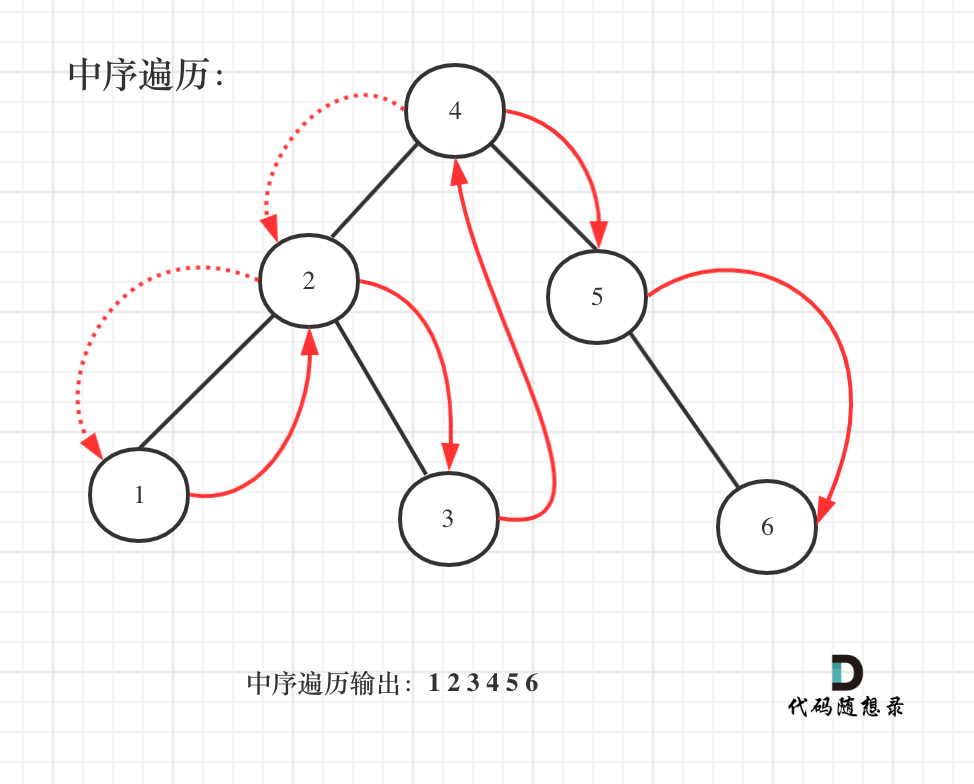
中序遍历代码如下:
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
(处理节点) // 中
searchBST(cur->right); // 右
return ;
}
遍历有序数组的元素出现频率,从头遍历,那么一定是相邻两个元素作比较,然后就把出现频率最高的元素输出就可以了。
关键是在有序数组上的话,好搞,在树上怎么搞呢?
在二叉树:搜索树的最小绝对差 (opens new window)中我们就使用了pre指针和cur指针的技巧,这次又用上了。
弄一个指针指向前一个节点,这样每次cur(当前节点)才能和pre(前一个节点)作比较。
而且初始化的时候pre = NULL,这样当pre为NULL时候,我们就知道这是比较的第一个元素。
代码如下:
if (pre == NULL) { // 第一个节点
count = 1; // 频率为1
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
此时又有问题了,因为要求最大频率的元素集合(注意是集合,不是一个元素,可以有多个众数),如果是数组上大家一般怎么办?
应该是先遍历一遍数组,找出最大频率(maxCount),然后再重新遍历一遍数组把出现频率为maxCount的元素放进集合。(因为众数有多个)
这种方式遍历了两遍数组。
那么我们遍历两遍二叉搜索树,把众数集合算出来也是可以的。
但这里其实只需要遍历一次就可以找到所有的众数。
那么如何只遍历一遍呢?
如果 频率count 等于 maxCount(最大频率),当然要把这个元素加入到结果集中(以下代码为result数组),代码如下:
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
问题:result怎么能轻易就把元素放进去了呢,万一,这个maxCount此时还不是真正最大频率呢?
所以下面要做如下操作:
频率count 大于 maxCount的时候,不仅要更新maxCount,而且要清空结果集(以下代码为result数组),因为结果集之前的元素都失效了。
if (count > maxCount) { // 如果计数大于最大值
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
关键代码都讲完了,完整代码如下:(只需要遍历一遍二叉搜索树,就求出了众数的集合)
class Solution {
private:
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
TreeNode* pre = NULL;
vector<int> result;
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
// 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
searchBST(cur->right); // 右
return ;
}
public:
vector<int> findMode(TreeNode* root) {
count = 0;
maxCount = 0;
TreeNode* pre = NULL; // 记录前一个节点
result.clear();
searchBST(root);
return result;
}
};
二、迭代法(一刷没看)
只要把中序遍历转成迭代,中间节点的处理逻辑完全一样。
二叉树前中后序转迭代,传送门:
下面我给出其中的一种中序遍历的迭代法,其中间处理逻辑一点都没有变(我从递归法直接粘过来的代码,连注释都没改,哈哈)
代码如下:
class Solution {
public:
vector<int> findMode(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
vector<int> result;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top();
st.pop(); // 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};
236. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
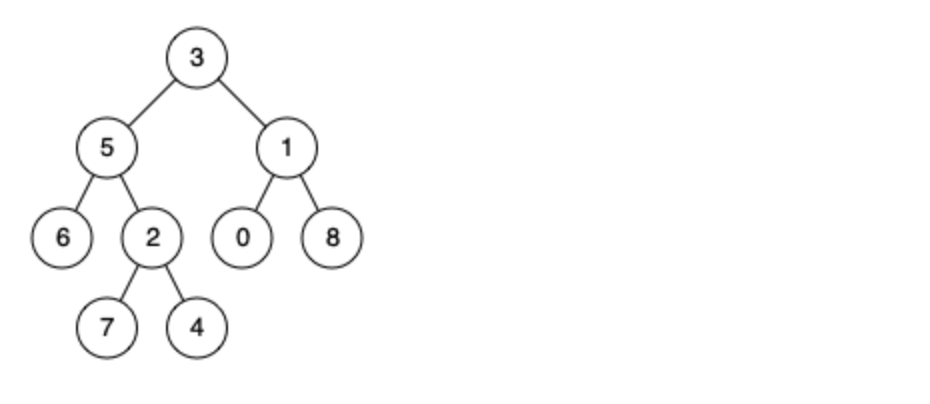
示例 1: 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出: 3 解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
示例 2: 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出: 5 解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
说明:
-
所有节点的值都是唯一的。
-
p、q 为不同节点且均存在于给定的二叉树中
思路
遇到这个题目首先想的是要是能自底向上查找就好了,这样就可以找到公共祖先了。
那么二叉树如何可以自底向上查找呢?
回溯啊,二叉树回溯的过程就是从低到上。
后序遍历(左右中)就是天然的回溯过程,可以根据左右子树的返回值,来处理中节点的逻辑。
接下来就看如何判断一个节点是节点q和节点p的公共祖先呢。
首先最容易想到的一个情况:如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。 即情况一:
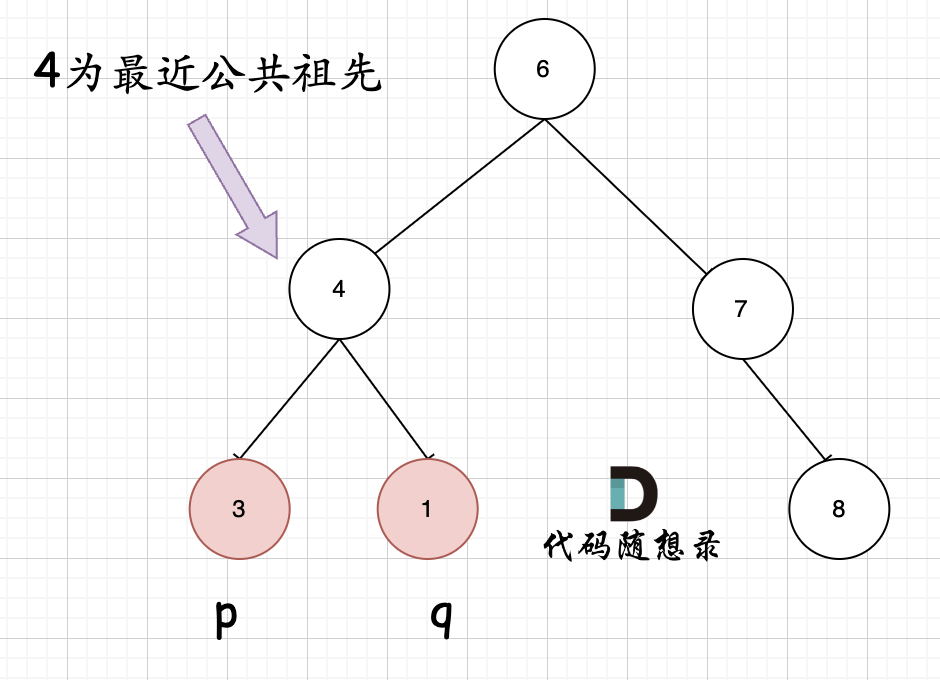
判断逻辑是 如果递归遍历遇到q,就将q返回,遇到p 就将p返回,那么如果 左右子树的返回值都不为空,说明此时的中节点,一定是q 和 p 的最近祖先。
那么有录友可能疑惑,会不会左子树 遇到q 返回,右子树也遇到q返回,这样并没有找到 q 和p的最近祖先。
这么想的录友,要审题了,题目强调:二叉树节点数值是不重复的,而且一定存在 q 和 p。
但是很多人容易忽略一个情况,就是节点本身p(q),它拥有一个子孙节点q(p)。
情况二:
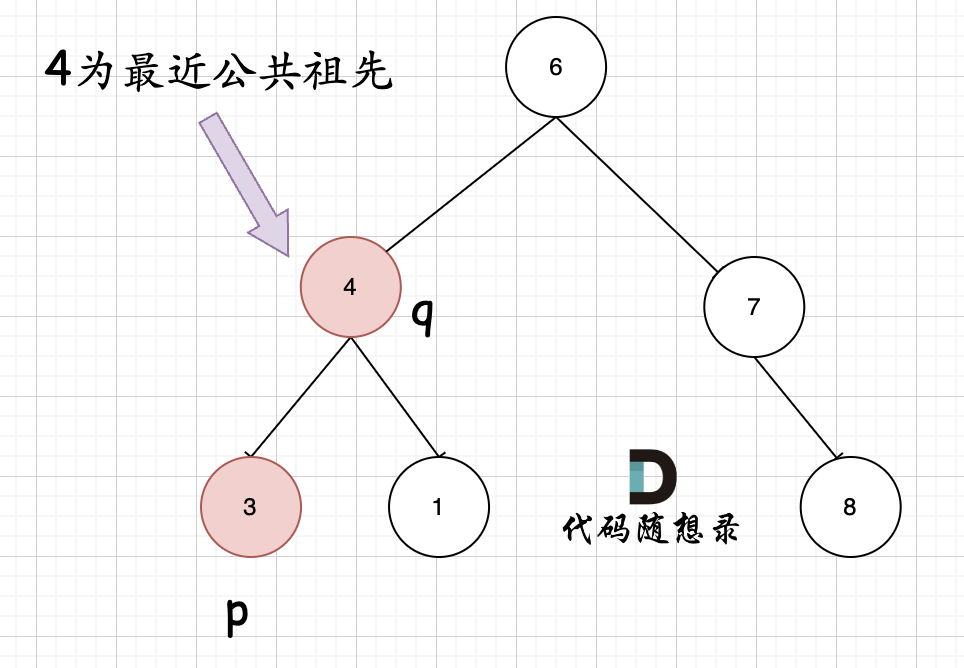
其实情况一 和 情况二 代码实现过程都是一样的,也可以说,实现情况一的逻辑,顺便包含了情况二。
因为遇到 q 或者 p 就返回,这样也包含了 q 或者 p 本身就是 公共祖先的情况。
这一点是很多录友容易忽略的,在下面的代码讲解中,可以再去体会。
递归三部曲:
-
确定递归函数返回值以及参数
需要递归函数返回值,来告诉我们是否找到节点q或者p,那么返回值为bool类型就可以了。
但我们还要返回最近公共节点,可以利用上题目中返回值是TreeNode * ,那么如果遇到p或者q,就把q或者p返回,返回值不为空,就说明找到了q或者p。
代码如下:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
-
确定终止条件
遇到空的话,因为树都是空了,所以返回空。
那么我们来说一说,如果 root == q,或者 root == p,说明找到 q p ,则将其返回,这个返回值,后面在中节点的处理过程中会用到,那么中节点的处理逻辑,下面讲解。
代码如下:
if (root == q || root == p || root == NULL) return root;
-
确定单层递归逻辑
值得注意的是 本题函数有返回值,是因为回溯的过程需要递归函数的返回值做判断,但本题我们依然要遍历树的所有节点。
我们在二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值? (opens new window)中说了 递归函数有返回值就是要遍历某一条边,但有返回值也要看如何处理返回值!
如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树呢?
搜索一条边的写法:
if (递归函数(root->left)) return ; if (递归函数(root->right)) return ;
搜索整个树写法:
left = 递归函数(root->left); // 左 right = 递归函数(root->right); // 右 left与right的逻辑处理; // 中
看出区别了没?
在递归函数有返回值的情况下:如果要搜索一条边,递归函数返回值不为空的时候,立刻返回,如果搜索整个树,直接用一个变量left、right接住返回值,这个left、right后序还有逻辑处理的需要,也就是后序遍历中处理中间节点的逻辑(也是回溯)。
那么为什么要遍历整棵树呢?直观上来看,找到最近公共祖先,直接一路返回就可以了。
如图:
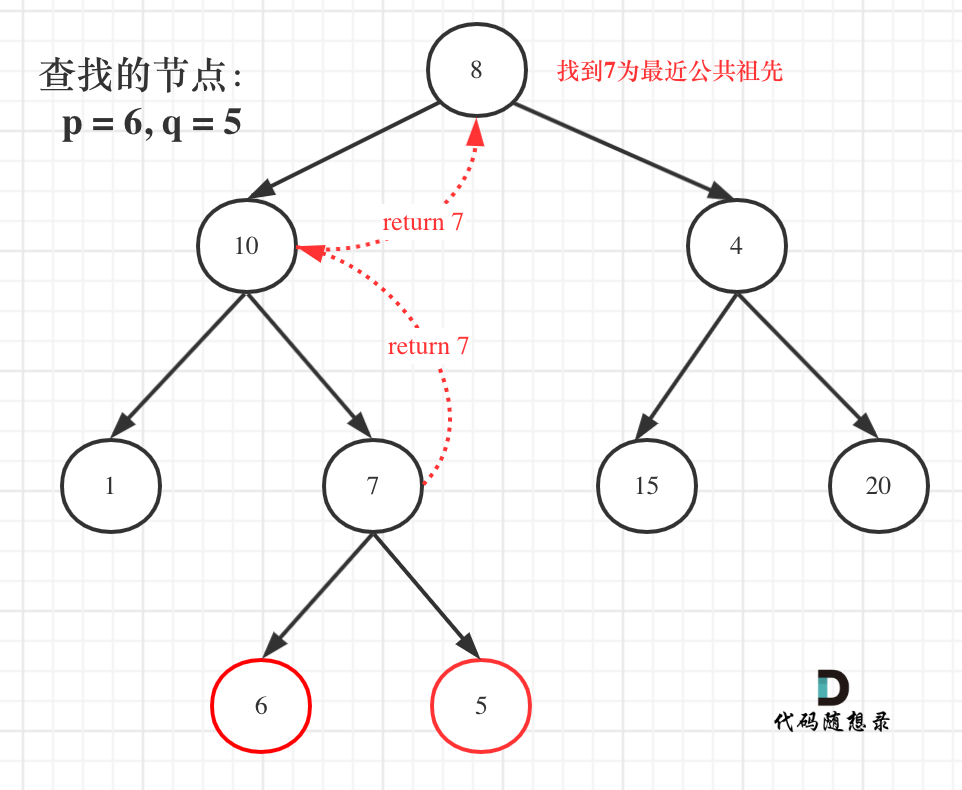
就像图中一样直接返回7,多美滋滋。
但事实上还要遍历根节点右子树(即使此时已经找到了目标节点了),也就是图中的节点4、15、20。
因为在如下代码的后序遍历中,如果想利用left和right做逻辑处理, 不能立刻返回,而是要等left与right逻辑处理完之后才能返回。
left = 递归函数(root->left); // 左 right = 递归函数(root->right); // 右 left与right的逻辑处理; // 中
所以此时大家要知道我们要遍历整棵树。知道这一点,对本题就有一定深度的理解了。
那么先用left和right接住左子树和右子树的返回值,代码如下:
TreeNode* left = lowestCommonAncestor(root->left, p, q); TreeNode* right = lowestCommonAncestor(root->right, p, q);
如果left 和 right都不为空,说明此时root就是最近公共节点。这个比较好理解
如果left为空,right不为空,就返回right,说明目标节点是通过right返回的,反之依然。
这里有的同学就理解不了了,为什么left为空,right不为空,目标节点通过right返回呢?
如图:
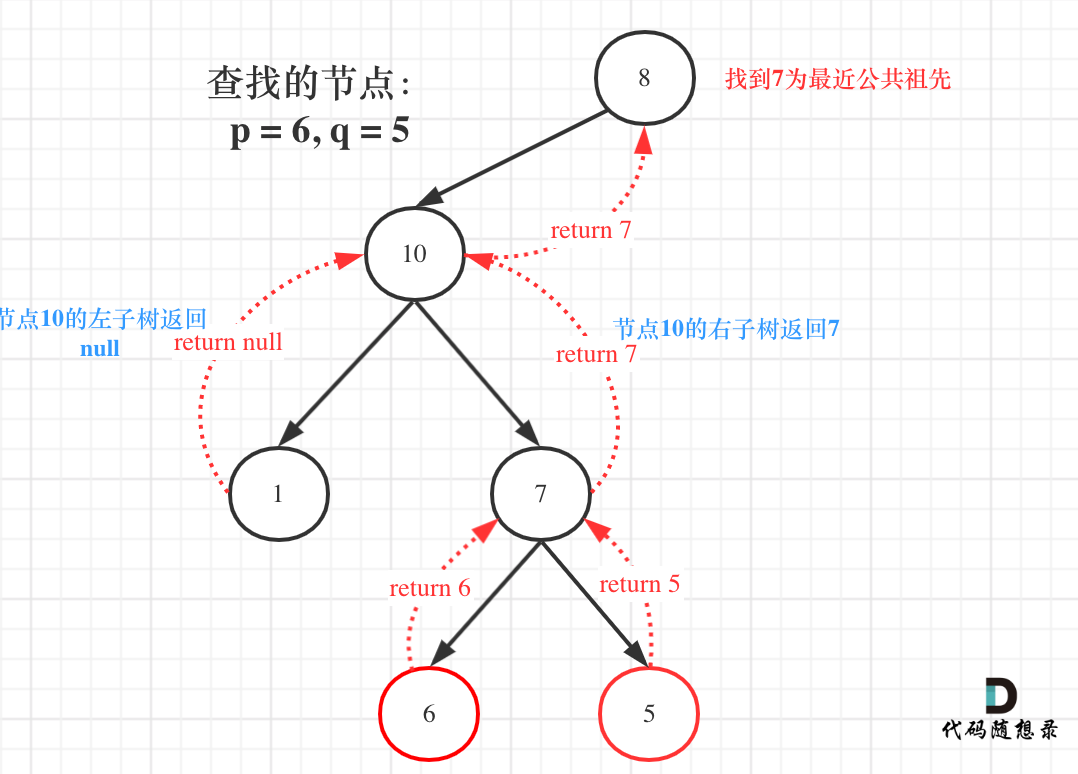
图中节点10的左子树返回null,右子树返回目标值7,那么此时节点10的处理逻辑就是把右子树的返回值(最近公共祖先7)返回上去!
这里也很重要,可能刷过这道题目的同学,都不清楚结果究竟是如何从底层一层一层传到头结点的。
那么如果left和right都为空,则返回left或者right都是可以的,也就是返回空。
代码如下:
if (left == NULL && right != NULL) return right;
else if (left != NULL && right == NULL) return left;
else { // (left == NULL && right == NULL)
return NULL;
}
那么寻找最小公共祖先,完整流程图如下:
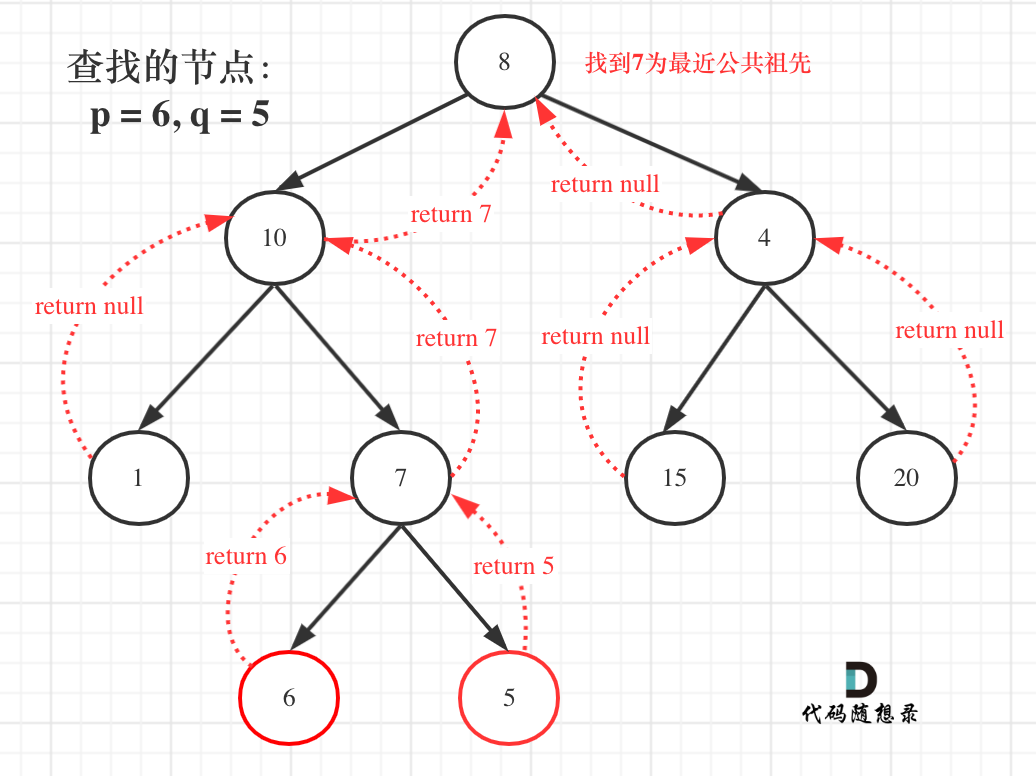
从图中,大家可以看到,我们是如何回溯遍历整棵二叉树,将结果返回给头结点的!
整体代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == q || root == p || root == NULL) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left != NULL && right != NULL) return root;
if (left == NULL && right != NULL) return right;
else if (left != NULL && right == NULL) return left;
else { // (left == NULL && right == NULL)
return NULL;
}
}
};
稍加精简,代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == q || root == p || root == NULL) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left != NULL && right != NULL) return root;
if (left == NULL) return right;
return left;
}
};















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









