







 本文介绍了如何使用Python结合Selenium2和Chrome浏览器模拟登录新浪微博的移动端。首先,详细说明了获取和放置chromedriver.exe的步骤,然后讲解如何安装或获取selenium库。最后,给出了具体的实现代码并提供了参考资料。
本文介绍了如何使用Python结合Selenium2和Chrome浏览器模拟登录新浪微博的移动端。首先,详细说明了获取和放置chromedriver.exe的步骤,然后讲解如何安装或获取selenium库。最后,给出了具体的实现代码并提供了参考资料。
使用 python+Selenium2+chrome模拟用户登录新浪微博移动端
1、获取chromedriver.exe
1.1、获取chromedriver.exe
下载地址(google)请自备梯子
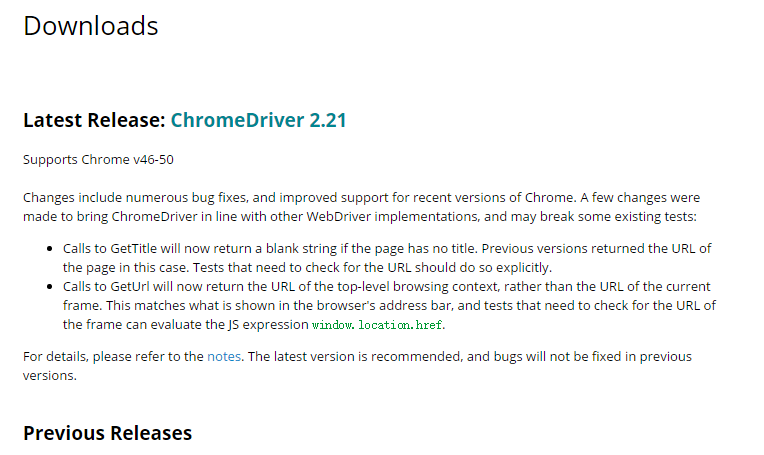
下载地址:http://chromedriver.storage.googleapis.com/index.html?path=2.21/
根据自己的版本进行下载,我这里用的chrome是50+的我下载最新的了2.21
1.2、放到工作目录
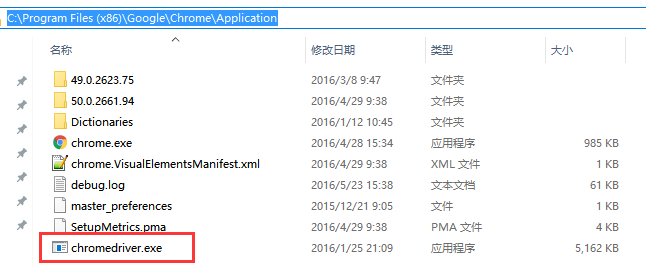
下载好后放到自己的chrome目录下(一般找到自己的chrome浏览器快捷方式打开所在位置就是chromedriver.exe要存放的位置了)
我的在这里
2、获取selenium
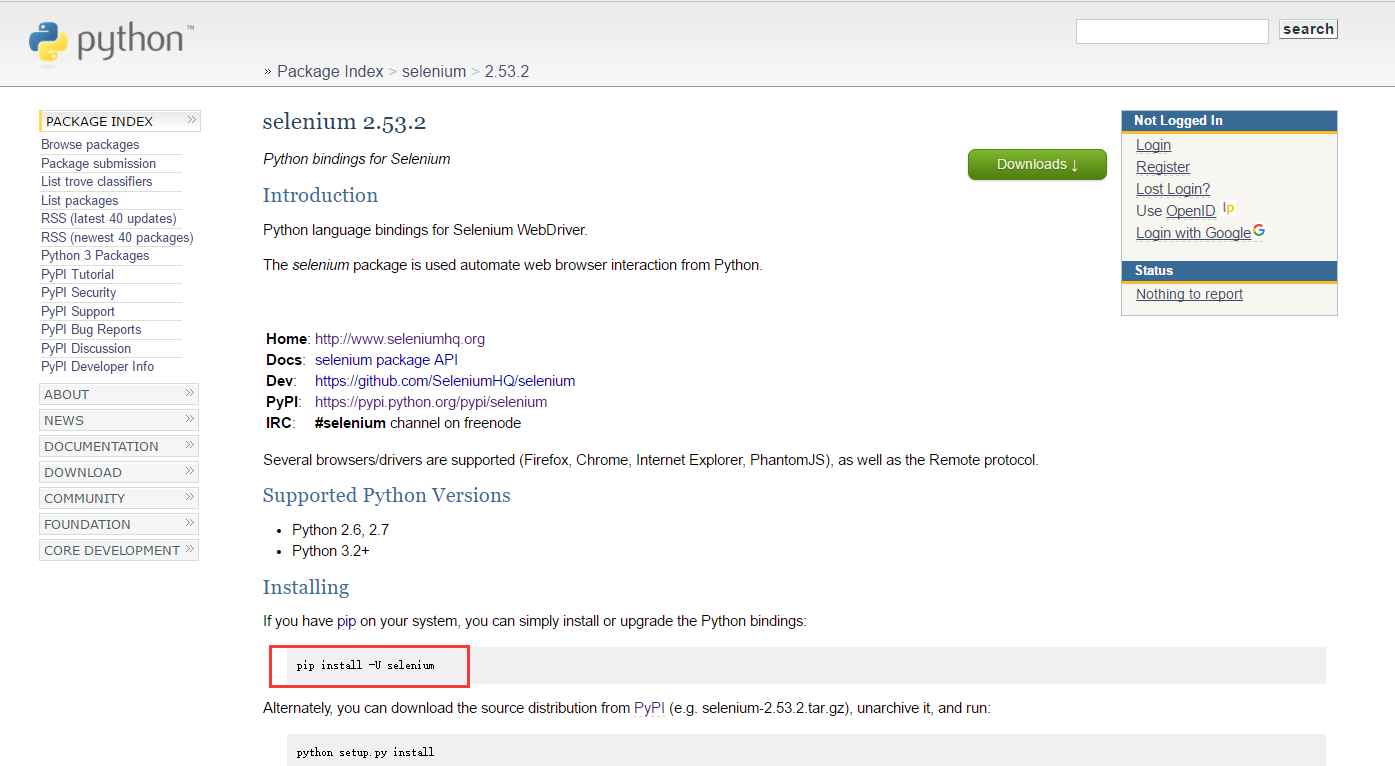
如果你系统上面有pip的话,直接可以使用下面的方法就可以安装了:
pip install -U selenium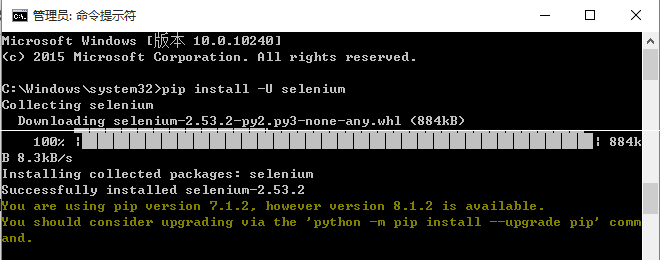
如果你没有就只能通过下载到本地方式安装了 这里不再累述可以到上面的链接自行下载安装了。
下载地址: https://pypi.python.org/pypi/selenium
里面还有一些例子可以进行参考
3、实现代码
# -*- coding: UTF-8 -*-
import os
from time import sleep
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
# 初始化配置
def initWork():
# 初始化配置根据自己chromedriver位置做相应的修改
chromedriver = "C:\Progr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3967
3967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









