







redis基础命令与使用场景
核心内容概览(待补充):
Redis 数据结构与命令使用
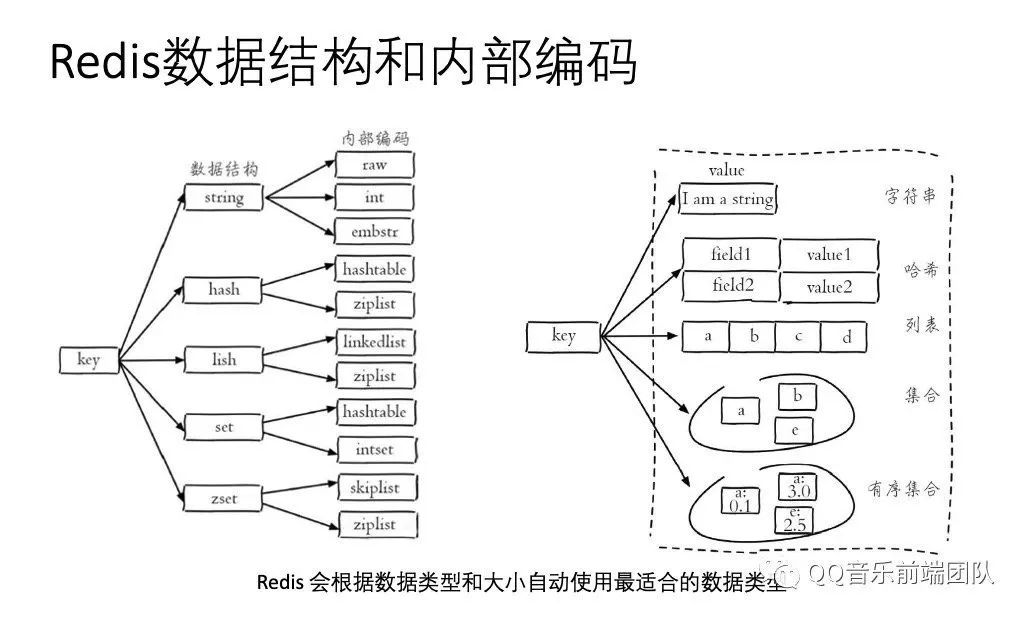
Redis 的数据结构有:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集 合)。但这些只是 Redis 对外的数据结构,实际上每种数据结构都有自己底层的内部编码实现,而且是多种实现, 这样 Redis 会在合适的场景选择合适的内部编码。
redis对象底层的八种数据结构:
REDIS_ENCODING_INT (long 类型的整数)
REDIS_ENCODING_EMBSTR embstr (编码的简单动态字符串)
REDIS_ENCODING_RAW (简单动态字符串)
REDIS_ENCODING_HT (字典)
REDIS_ENCODING_LINKEDLIST (双端链表)
REDIS_ENCODING_ZIPLIST (压缩列表)
REDIS_ENCODING_INTSET (整数集合)
REDIS_ENCODING_SKIPLIST (跳跃表和字典)
1.通用全局命令
常用全局命令
- keys:查看所有键
- dbsize:键总数
- exists key:检查键是否存在
- del key [key …]:删除键
- expire key seconds:键过期
- ttl key: 通过 ttl 命令观察键键的剩余过期时间
- type key:键的数据结构类型
2.String字符串使用
字符串 string 是 Redis 最简单的数据结构。Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。
字符串结构使用非常广泛,一个常见的用途就是缓存用户信息。我们将用户信息结构体 使用 JSON 序列化成字符串,然后将序列化后的字符串塞进 Redis 来缓存。同样,取用户 信息会经过一次反序列化的过程。
内部编码转换顺序
-
当保存的值为整数且值的大小不超过long的范围,使用整数编码存储
-
当字符串长度不超过44字节时,使用EMBSTR 编码
-
大于44字符时,使用raw编码
常用字符串命令
-
set key value [ex seconds][px milliseconds] [nx|xx]: 设置值,返回 ok 表示成功
- ex seconds:为键设置秒级过期时间。
- px milliseconds:为键设置毫秒级过期时间。
- nx:键必须不存在,才可以设置成功,用于添加。可单独用 setnx 命令替代
- xx:与 nx 相反,键必须存在,才可以设置成功,用于更新。可单独用 setxx 命令替代
-
get key:获取值
-
mset key value [key value …]:批量设置值,批量操作命令可以有效提高业务处理效率
-
mget key [key …]:批量获取值,批量操作命令可以有效提高业务处理效率
-
incr key:计数,返回结果分 3 种情况:
- 值不是整数,返回错误。
- 值是整数,返回自增后的结果。
- 键不存在,按照值为 0 自增,返回结果为 1。
-
decr(自减)、incrby(自增指定数字)、 decrby(自减指定数字)
字符串使用场景
- 缓存数据,提高查询性能。比如存储登录用户信息、电商中存储商品信息
- 可以做计数器(想知道什么时候封锁一个 IP 地址(访问超过几次)),短信限流
- 共享 Session,例如:一个分布式 Web 服务将用户的 Session 信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可 能会发现需要重新登录,为了解决这个问题,可以使用 Redis 将用户的 Session 进行集中管理,在这种模式下只要保证 Redis 是高可用和扩展性的,每次用户 更新或者查询登录信息都直接从 Redis 中集中获取,如图:


3.哈希 hash
哈希相当于 Java 中的 HashMap,以及 Js 中的 Map,内部是无序字典。实现原理跟 HashMap 一致。一个哈希表有多个节点,每个节点保存一个键值对。
与 Java 中的 HashMap 不同的是,rehash 的方式不一样,因为 Java 的 HashMap 在字典很大时,rehash 是个耗时的操作,需要一次性全部 rehash。
Redis 为了高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务中以及 hash 操作指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中。当搬迁完成了,就会使用新的 hash 结构取而代之。
当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。
内部编码转换顺序
同时满足以下条件时使用ziplist
- 元素的长度小于 64 字节;
- 列表中数据个数少于512个
否则使用dict编码(两个hashtable的数组)
常用哈希命令
- hset key field value:设置值
- hget key field:获取值
- hdel key field [field …]:删除 field
- hlen key:计算 field 个数
- hmset key field value [field value …]:批量设置 field-value
- hmget key field [field …]:批量获取 field-value
- hexists key field:判断 field 是否存在
- hkeys key:获取所有 field
- hvals key:获取所有 value
- hgetall key:获取所有的 field-value
- incrbyfloat 和 hincrbyfloat:就像 incrby 和 incrbyfloat 命令一样,但是它们的作 用域是 filed
哈希使用场景
-
Hash 也可以同于对象存储,比如存储用户信息,与字符串不一样的是,字符串是需要将对象进行序列化(比如 json 序列化)之后才能保存,而 Hash 则可以讲用户对象的每个字段单独存储,这样就能节省序列化和反序列的时间。如下:
-
此外还可以保存用户的购买记录,比如 key 为用户 id,field 为商品 i d,value 为商品数量。同样还可以用于购物车数据的存储,比如 key 为用户 id,field 为商品 id,value 为购买数量等等
4.列表(lists)
Redis 中的 lists 相当于 Java 中的 LinkedList,实现原理是一个双向链表(其底层是一个快速列表),即可以支持反向查找和遍历,更方便操作。插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。
内部编码转换顺序
Redis3.2之前的底层实现方式:压缩列表ziplist 或者 双向循环链表linkedlist
当list存储的数据量比较少且同时满足下面两个条件时,list就使用ziplist存储数据:
- list中保存的每个元素的长度小于 64 字节;
- 列表中数据个数少于512个
Redis3.2及之后的底层实现方式:quicklist
quicklist是一个双向链表,而且是一个基于ziplist的双向链表,quicklist的每个节点都是一个ziplist,结合了双向链表和ziplist的优点。
常用列表命令
-
rpush key value [value …]:从右边插入元素
-
lpush key value [value …]:从左边插入元素
-
linsert key before|after pivot value:向某个元素前或者后插入元素
-
lrange key start end:获取指定范围内的元素列表,
lrange key 0 -1可以从左到右获取列表的所有元素 -
lindex key index:获取列表指定索引下标的元素
-
llen key:获取列表长度
-
lpop key:从列表左侧弹出元素
-
rpop key:从列表右侧弹出
-
lrem key count value:删除指定元素,lrem 命令会从列表中找到等于 value 的元素进行删除,根据 count 的不同 分为三种情况:
- ·count>0,从左到右,删除最多 count 个元素。
- count<0,从右到左,删除最多 count 绝对值个元素。
- count=0,删除所有。
-
ltrim key start end:按照索引范围修剪列表
-
lset key index newValue:修改指定索引下标的元素
-
blpop key [key …] timeout 和 brpop key [key …] timeout:阻塞式弹出
列表使用场景
- 热销榜,文章列表(比如,博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用redis的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。)
- 实现工作队列(利用 lists 的 push 操作,将任务存在 lists 中,然后工作线程再用 pop 操作将任务取出进行执行 ),例如消息队列
- 最新列表,比如最新评论
使用参考:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
5.set 集合和 zset 有序集合
Redis 的集合相当于 Java 语言里面的 HashSet 和 JS 里面的 Set,它内部的键值对是无序的唯一的。Set 集合中最后一个 value 被移除后,数据结构自动删除,内存被回收。
zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结构。它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫着「跳跃列表」(后面会简单介绍)的数据结构。
内部编码转换顺序
set:
同时满足以下两个条件时使用inset编码
- 存储的数据都是整数
- 存储的数据元素个数小于512个
否则使用dict编码(两个hashtable的数组)
zset:
满足下面两个条件时,使用ziplist存储数据(每个元素增加一个紧挨在一起的保存分数的节点):
- list中保存的每个元素的长度小于 64 字节;
- 列表中数据个数少于512个
否则使用skiplist
常用集合命令
- sadd key element [element …]:添加元素,返回结果为添加成功的元素个数
- srem key element [element …]:删除元素,返回结果为成功删除元素个数
- smembers key:获取所有元素
- sismember key element:判断元素是否在集合中,如果给定元素 element 在集合内返回 1,反之返回 0
- scard key:计算元素个数,scard 的时间复杂度为 O(1),它不会遍历集合所有元素
- spop key:从集合随机弹出元素,从 3.2 版本开始,spop 也支持[count]参数。
- srandmember key [count]:随机从集合返回指定个数元素,[count]是可选参数,如果不写默认为 1
- sinter key [key …]:求多个集合的交集
- suinon key [key …]:求多个集合的并集
- sdiff key [key …]:求多个集合的差集
常用有序集合命令
-
zadd key score member [score member …]:添加成员,返回结果代表成功添加成员的个数。Redis3.2 为 zadd 命令添加了 nx、xx、ch、incr 四个选项:
- nx:member 必须不存在,才可以设置成功,用于添加
- xx:member 必须存在,才可以设置成功,用于更新
- ch:返回此次操作后,有序集合元素和分数发生变化的个数
- incr:对 score 做增加,相当于后面介绍的 zincrby
-
zcard key:计算成员个数
-
zscore key member:计算某个成员的分数
-
zrank key member 和 zrevrank key member:计算成员的排名,zrank 是从分数从低到高返回排名,zrevrank 反之
-
zrem key member [member …]:删除成员
-
zincrby key increment member:增加成员的分数
-
zrange key start end [withscores] 和 zrevrange key start end [withscores]:返回指定排名范围的成员,zrange 是从低到高返回,zrevrange 反之。
-
zrangebyscore key min max [withscores][limit offset count] 和 zrevrangebyscore key max min [withscores][limit offset count] 返回指定分数范围的成员,其中 zrangebyscore 按照分数从低到高返回,zrevrangebyscore 反之
-
zcount key min max:返回指定分数范围成员个数
-
zremrangebyrank key start end:删除指定排名内的升序元素
-
zremrangebyscore key min max:删除指定分数范围的成员
-
zinterstore 和 zunionstore 命令求集合的交集和并集,可用参数比较多,可用到再查文档
有序集合相比集合提供了排序字段,但是也产生了代价,zadd 的时间 复杂度为 O(log(n)),sadd 的时间复杂度为 O(1)。
集合和有序集合使用场景
- 给用户添加标签
- 给标签添加用户
- 根据某个权重进行排序的队列的场景,比如游戏积分排行榜,设置优先级的任务列表,学生成绩表等
文章参考:https://mp.weixin.qq.com/s/-3fcK4WspGk6SEsaVrdx8A
https://mp.weixin.qq.com/s/7ct-mvSIaT3o4-tsMaKRWA















 1387
1387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









