









相关教程
- Protobuf(Protocol Buffers)超详细入门教程(跨平台序列化, C++, CMake)——更新于2022.01
- 【超详细】Protobuf(Protocol Buffers)proto3 与 proto2 的区别——更新于2022.01
- Protobuf(Protocol Buffers)超详细入门教程(跨平台序列化, Java)——更新于2022.01
- Protobuf(Protocol Buffers)超详细入门教程(跨平台序列化, Python)——更新于2022.01
- 【从零开始】在Windows中使用Linux——在WSL使用CLion、IDEA、PyCharm(安装到建立工程)——更新于2021.12
相关文献
- Protocol Buffers官网
- C++ Installation官网
- Python Installation官网
- Protocol Buffer Basics: Python
- Download Protocol Buffers(官方用例)
protocol buffers是谷歌的语言中立、平台中立、可扩展的结构化数据序列化机制——XML,但更小、更快、更简单。您可以一次定义数据的结构化方式,然后可以使用特殊生成的源代码轻松地使用各种语言(C++/ C#/ Dart/ Go/ Java/ Kotlin/ Python)在各种数据流中写入和读取结构化数据。
安装
C++ Installation - Unix
最简单的方式:
sudo apt install protobuf-compiler
如果你想使用最新版,安装教程可以参考C++ Installation官网
Python
pip install protobuf
如果你想自己编译,安装教程可以参考Python Installation官网
环境
我用的是WSL,对于Linux类似,如果环境上有问题可以参考:【从零开始】在Windows中使用Linux——在WSL使用CLion、IDEA、PyCharm(安装到建立工程)——更新于2021.12
Protobuf3 0基础上手例子
我们从官网下载最新的Download Protocol Buffers(官方用例)作为例子如下:
使用PyCharm新建工程:
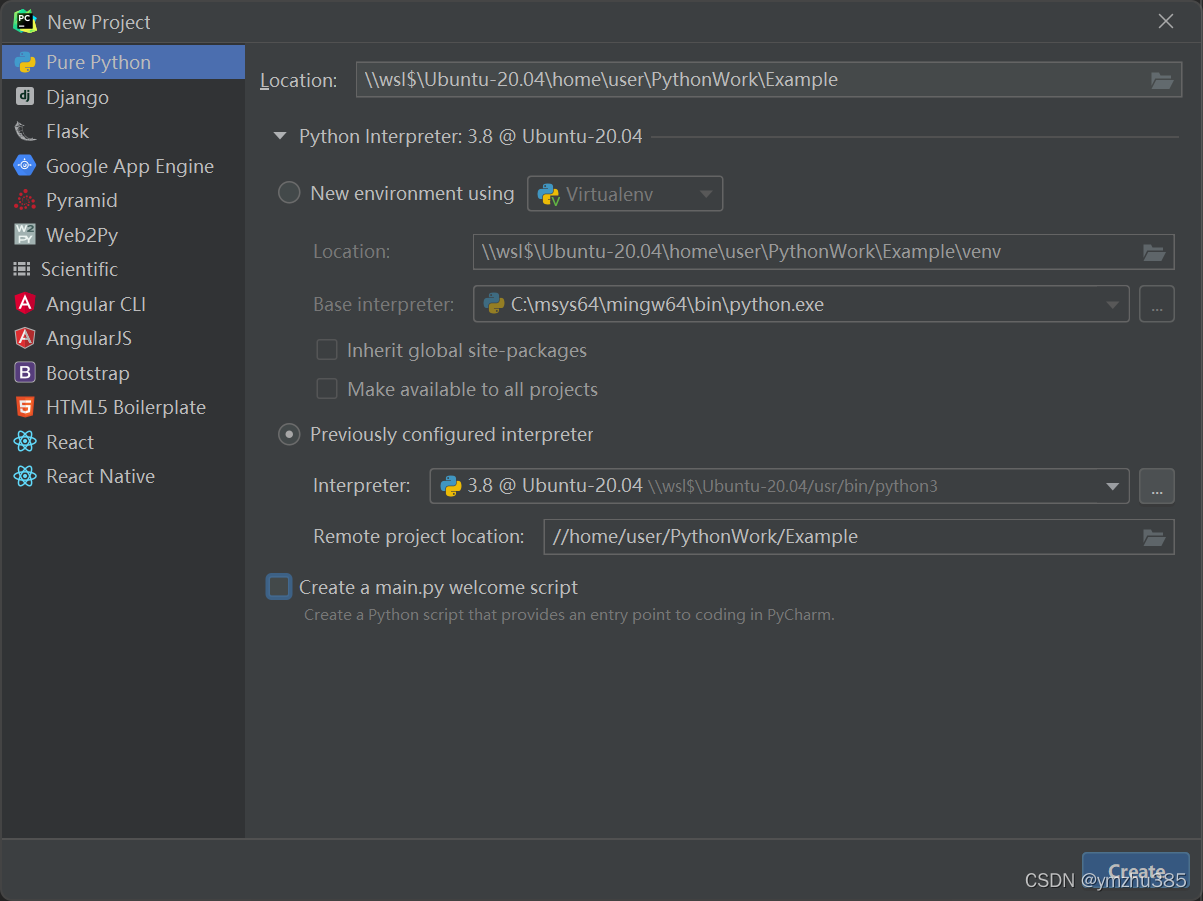
当前目录下创建addressbook.proto:

// See README.txt for information and build instructions.
//
// Note: START and END tags are used in comments to define sections used in
// tutorials. They are not part of the syntax for Protocol Buffers.
//
// To get an in-depth walkthrough of this file and the related examples, see:
// https://developers.google.com/protocol-buffers/docs/tutorials
// [START declaration]
syntax = "proto3";
package tutorial;
import "google/protobuf/timestamp.proto";
// [END declaration]
// [START java_declaration]
option java_multiple_files = true;
option java_package = "com.example.tutorial.protos";
option java_outer_classname = "AddressBookProtos";
// [END java_declaration]
// [START csharp_declaration]
option csharp_namespace = "Google.Protobuf.Examples.AddressBook";
// [END csharp_declaration]
// [START go_declaration]
option go_package = "../tutorial";
// [END go_declaration]
// [START messages]
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
google.protobuf.Timestamp last_updated = 5;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person people = 1;
}
// [END messages]
创建文件add_person.py:
#! /usr/bin/env python
# See README.txt for information and build instructions.
import addressbook_pb2
import sys
try:
raw_input # Python 2
except NameError:
raw_input = input # Python 3
# This function fills in a Person message based on user input.
def PromptForAddress(person):
person.id = int(raw_input("Enter person ID number: "))
person.name = raw_input("Enter name: ")
email = raw_input("Enter email address (blank for none): ")
if email != "":
person.email = email
while True:
number = raw_input("Enter a phone number (or leave blank to finish): ")
if number == "":
break
phone_number = person.phones.add()
phone_number.number = number
type = raw_input("Is this a mobile, home, or work phone? ")
if type == "mobile":
phone_number.type = addressbook_pb2.Person.MOBILE
elif type == "home":
phone_number.type = addressbook_pb2.Person.HOME
elif type == "work":
phone_number.type = addressbook_pb2.Person.WORK
else:
print("Unknown phone type; leaving as default value.")
# Main procedure: Reads the entire address book from a file,
# adds one person based on user input, then writes it back out to the same
# file.
if len(sys.argv) != 2:
print("Usage:", sys.argv[0], "ADDRESS_BOOK_FILE")
sys.exit(-1)
address_book = addressbook_pb2.AddressBook()
# Read the existing address book.
try:
with open(sys.argv[1], "rb") as f:
address_book.ParseFromString(f.read())
except IOError:
print(sys.argv[1] + ": File not found. Creating a new file.")
# Add an address.
PromptForAddress(address_book.people.add())
# Write the new address book back to disk.
with open(sys.argv[1], "wb") as f:
f.write(address_book.SerializeToString())
创建文件list_people.py:
#! /usr/bin/env python
# See README.txt for information and build instructions.
from __future__ import print_function
import addressbook_pb2
import sys
# Iterates though all people in the AddressBook and prints info about them.
def ListPeople(address_book):
for person in address_book.people:
print("Person ID:", person.id)
print(" Name:", person.name)
if person.email != "":
print(" E-mail address:", person.email)
for phone_number in person.phones:
if phone_number.type == addressbook_pb2.Person.MOBILE:
print(" Mobile phone #:", end=" ")
elif phone_number.type == addressbook_pb2.Person.HOME:
print(" Home phone #:", end=" ")
elif phone_number.type == addressbook_pb2.Person.WORK:
print(" Work phone #:", end=" ")
print(phone_number.number)
# Main procedure: Reads the entire address book from a file and prints all
# the information inside.
if len(sys.argv) != 2:
print("Usage:", sys.argv[0], "ADDRESS_BOOK_FILE")
sys.exit(-1)
address_book = addressbook_pb2.AddressBook()
# Read the existing address book.
with open(sys.argv[1], "rb") as f:
address_book.ParseFromString(f.read())
ListPeople(address_book)
在PyCharm左下角打开Terminal:
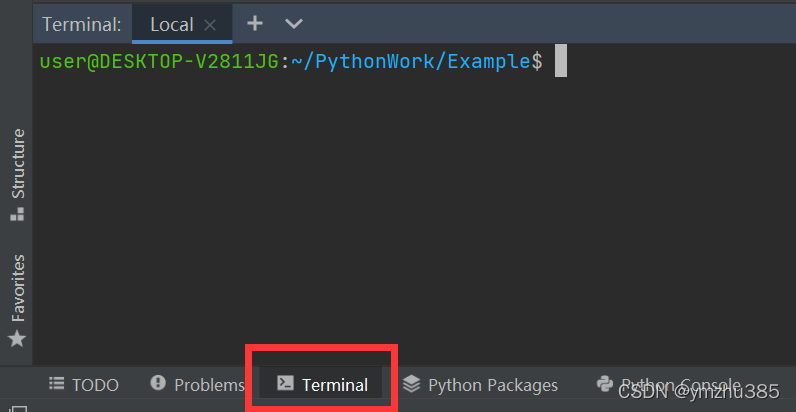
输入:
protoc -I=./ --python_out=./ addressbook.proto
这时候我们会发现生成了以下文件:
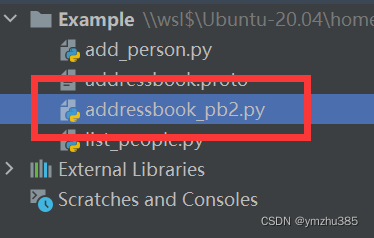
之后,Run | Edit configuration 里添加 Python:
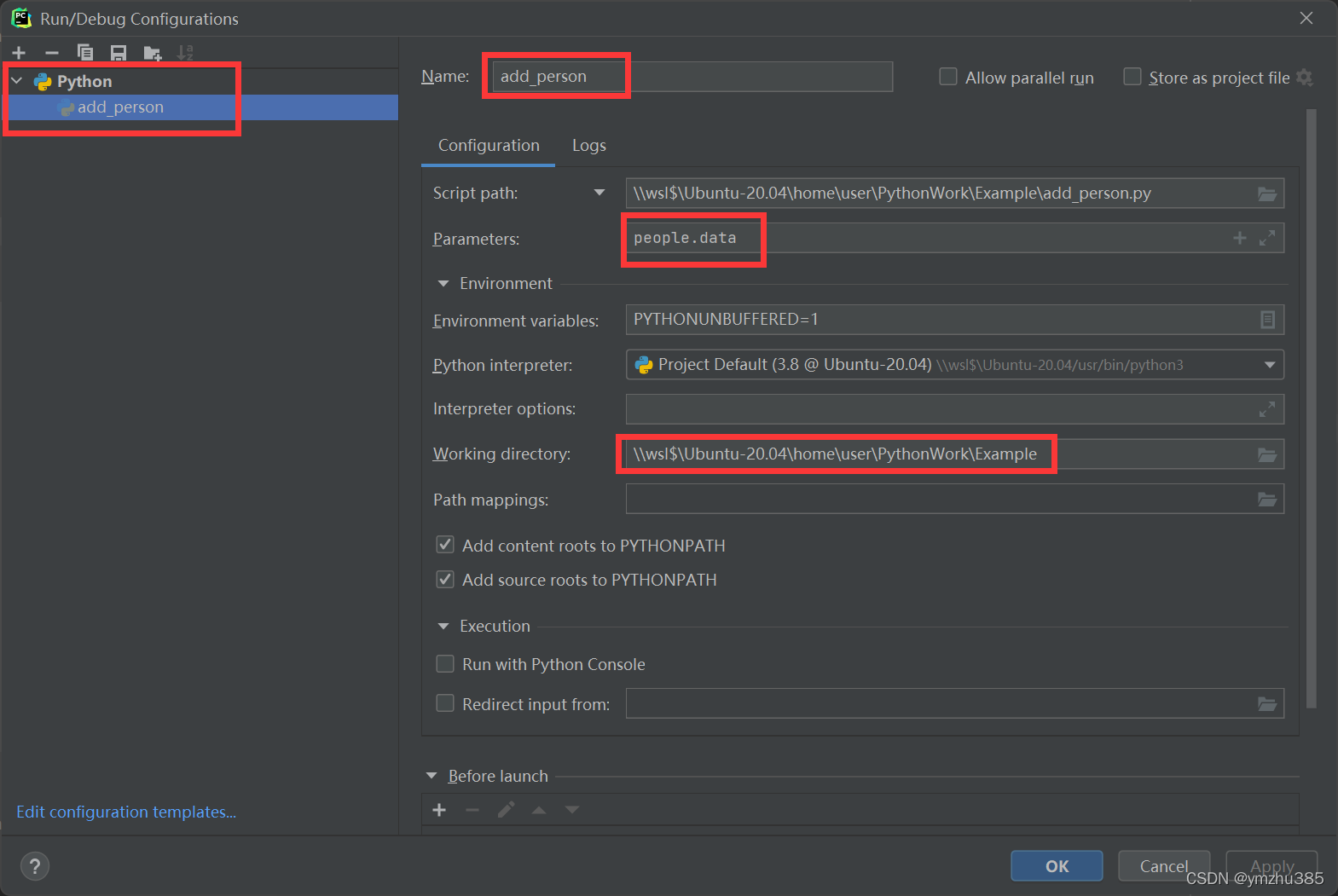
我们点选run:

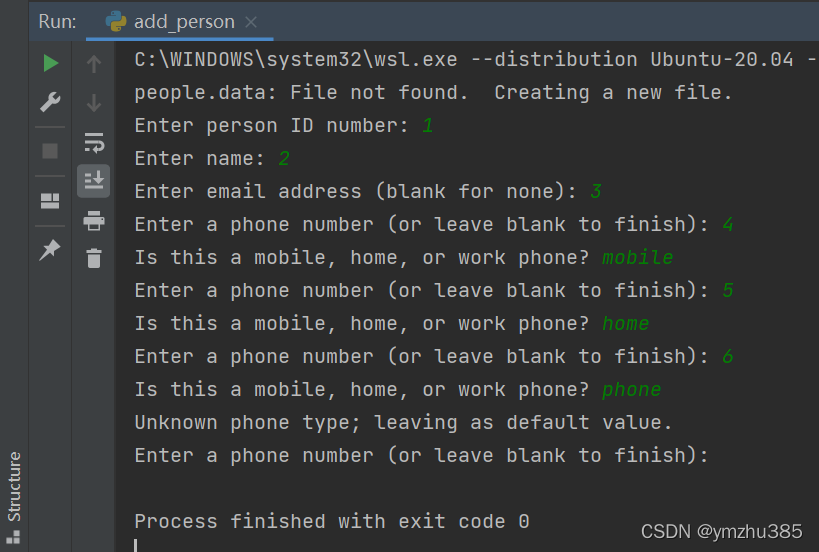
然后在Run窗口里输入你想存入的数据:
同样的,Run | Edit configuration 里添加 Python:
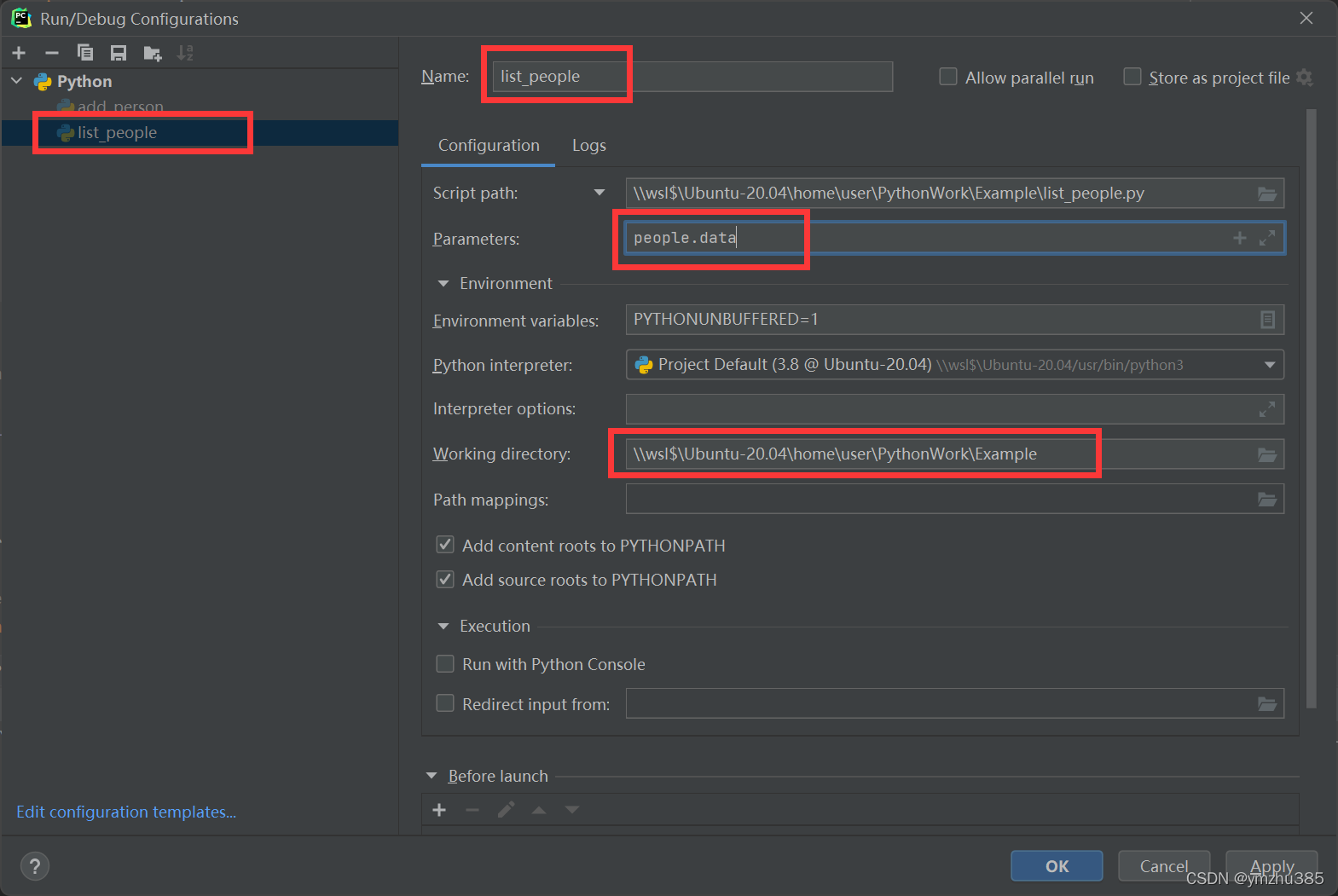
我们点选run:

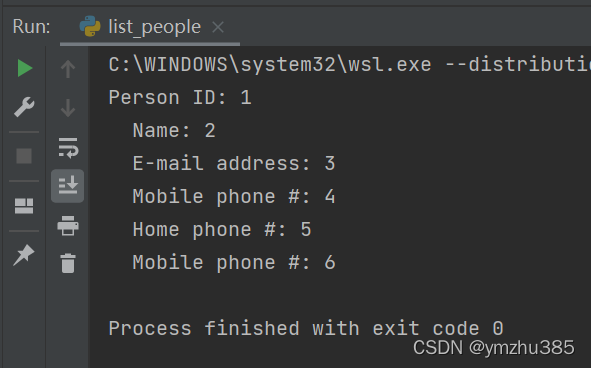
在Run窗口中会打印出我们刚才存入的数据:














 1529
1529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









