







前言
理解操作系统有助于定位和排查线上疑难杂症,掌握内核的关键机制,可以加深对程序运行机制的理解,为编写高性能代码和解决性能问题提供强有力的底座支撑。
内核模块是上手Linux内核的一条门径,通过内核模块进而扒开Linux内核高深莫测的面纱。以内核模块为入手点,后续依次整理出内存管理、进程管理的相关内容;
一、背景
1.目标
a. 通过llaolao驱动梳理文件调用流程
b. 通过驱动来窥探文件系统
c. 通过ixgbe驱动注册流程,对网卡驱动有个感性认知
二、调试刘姥姥驱动
1. 实验环境
1. 1 实现环境介绍
以上调试环境均来自盛格塾
1. 2 触发条件
cat /proc/llaolao
流程分析: cat命令对应的进程,以/proc/llaolao作为全路径,触发系统调用。
下面函数调用栈即内核的整个流程
2. 函数调用栈

3. 调用逻辑解析

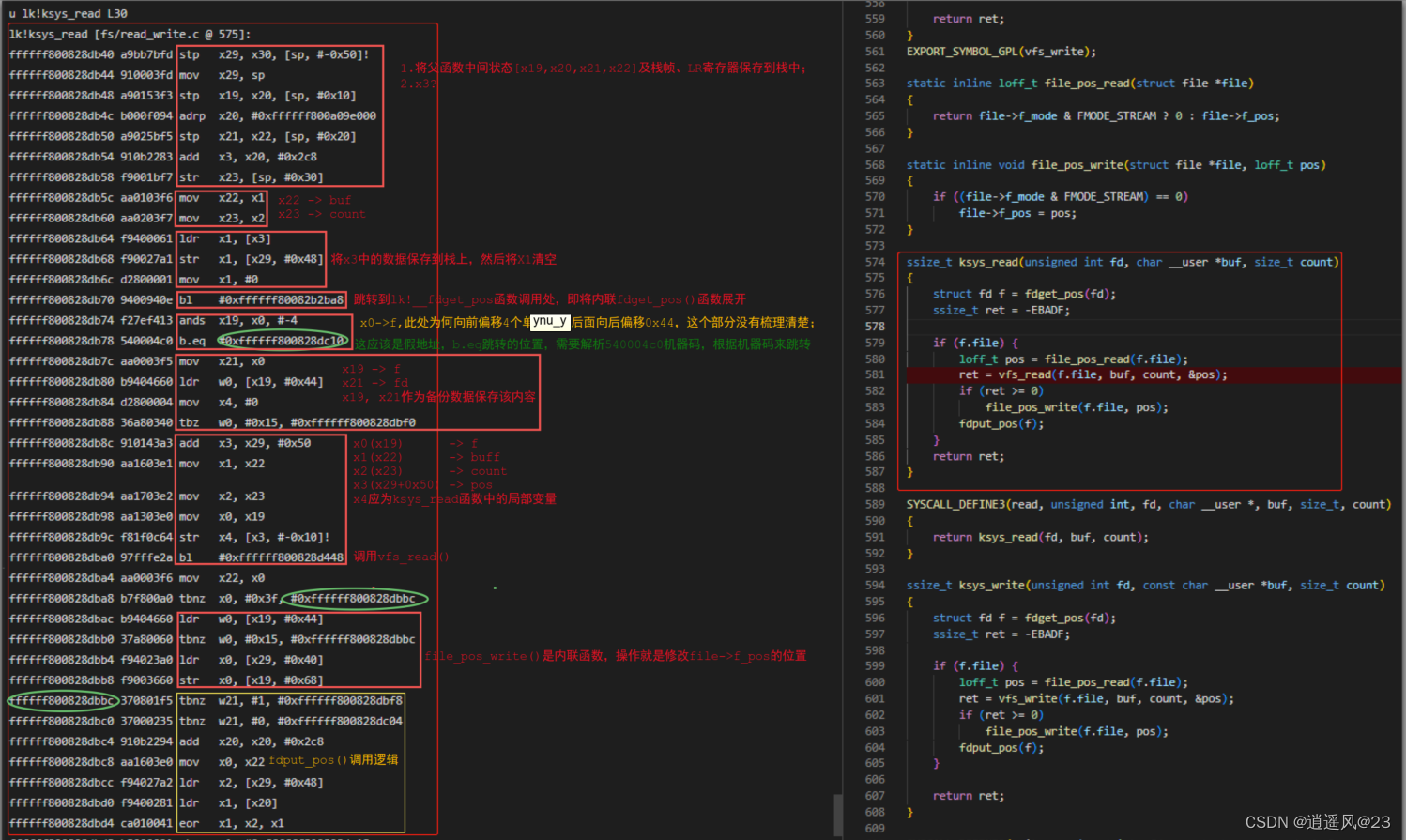
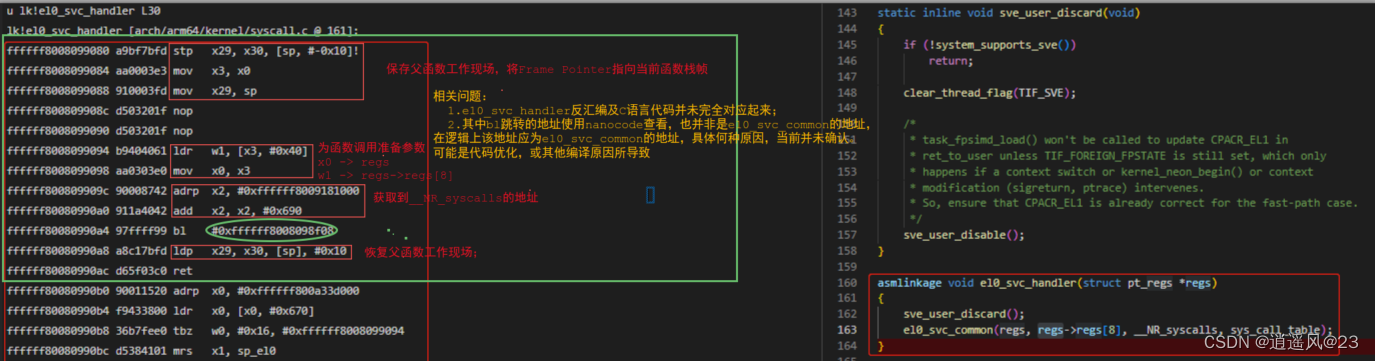
4. 汇编代码分析
4.1 第0帧proc_lll_read()函数
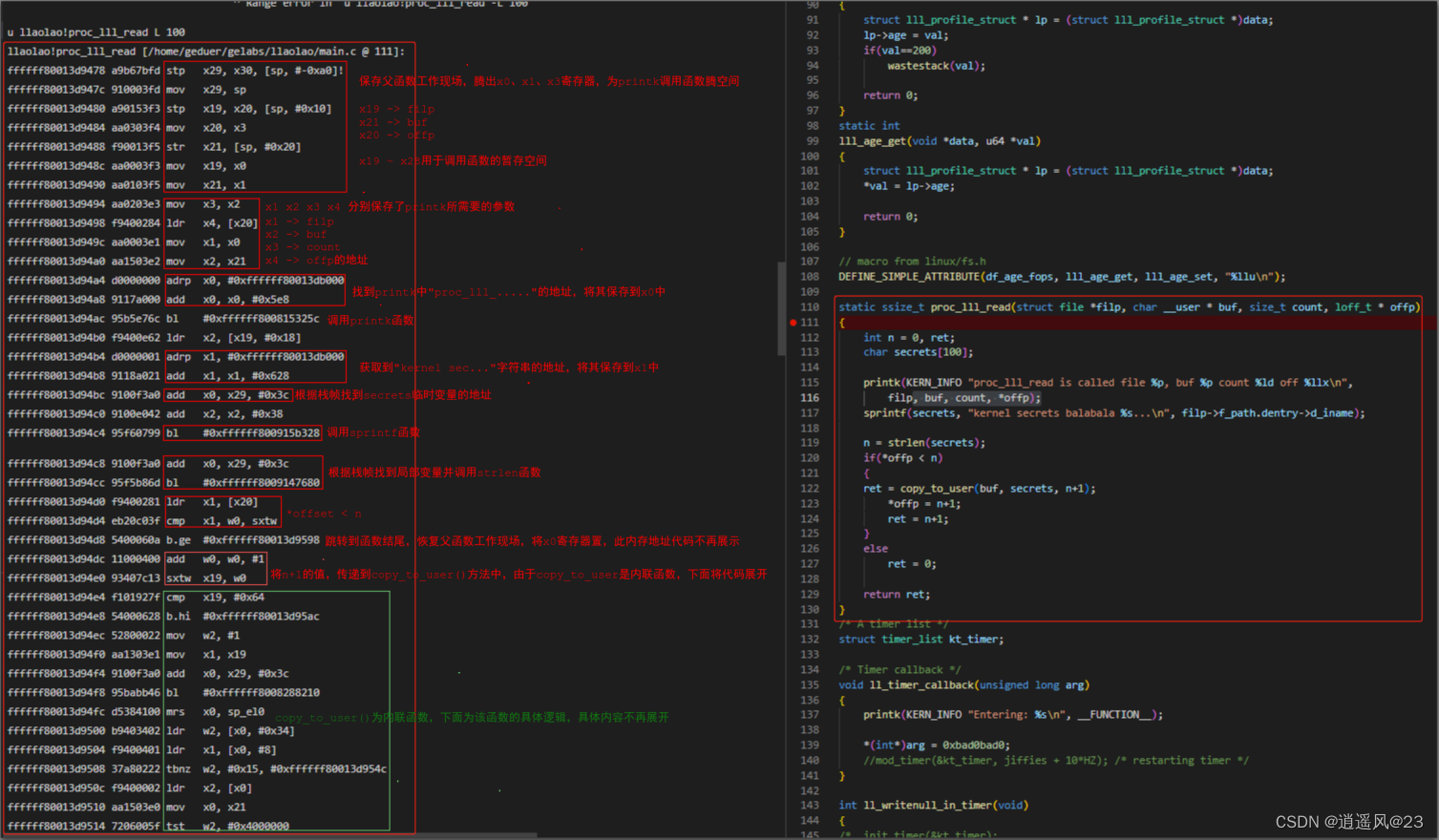

4.2 第1帧proc_reg_read()函数
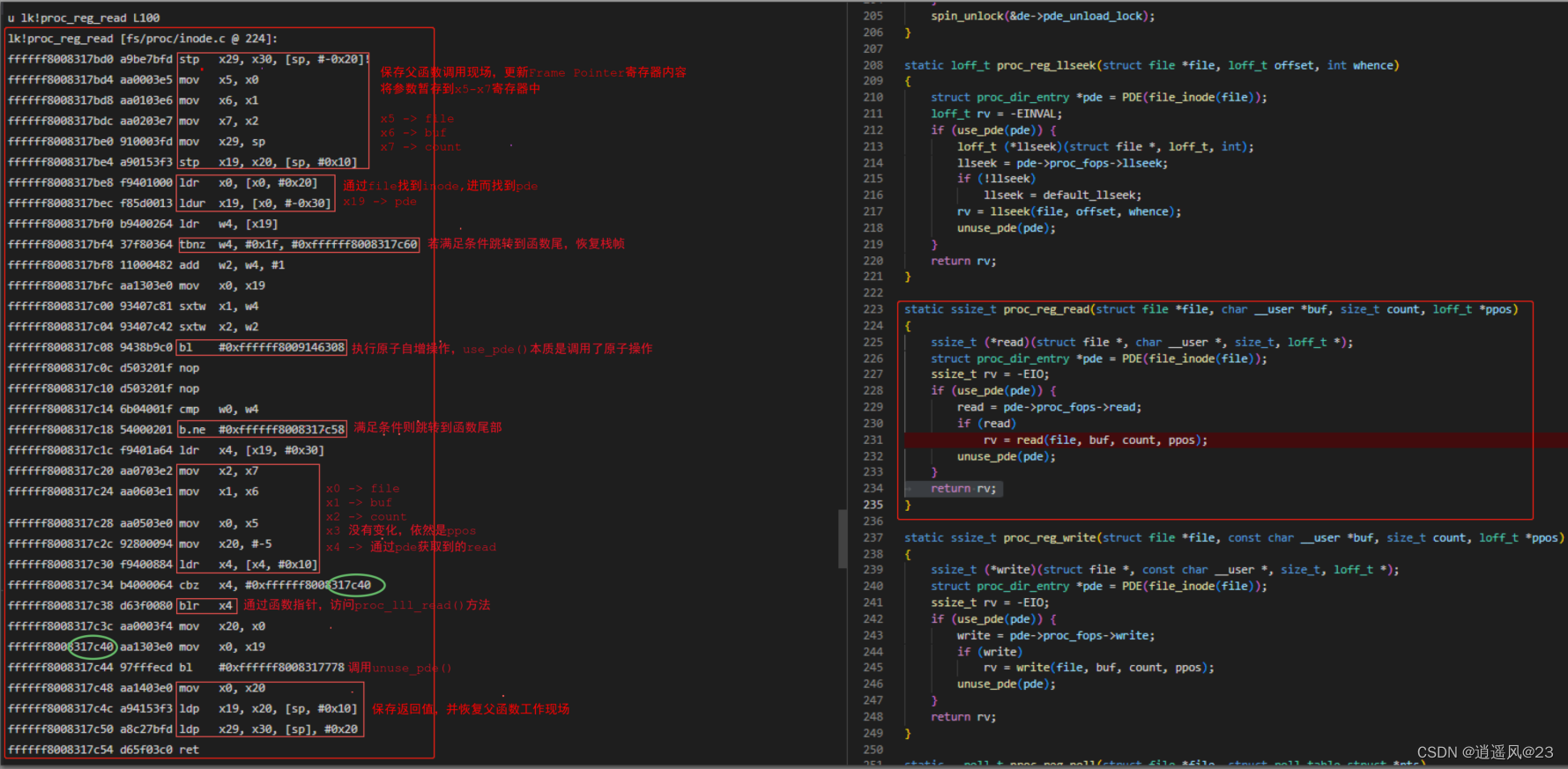
4.3 第2帧__vfs_read()函数
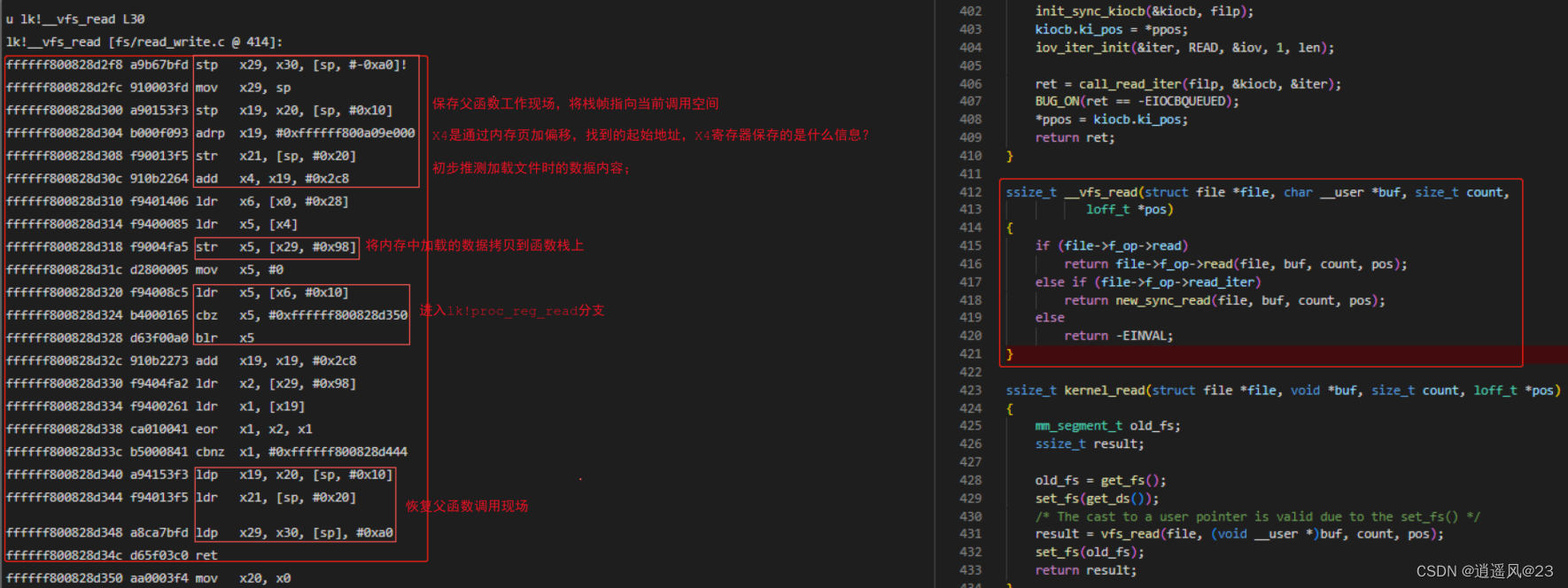
4.4 第3帧vfs_read()函数
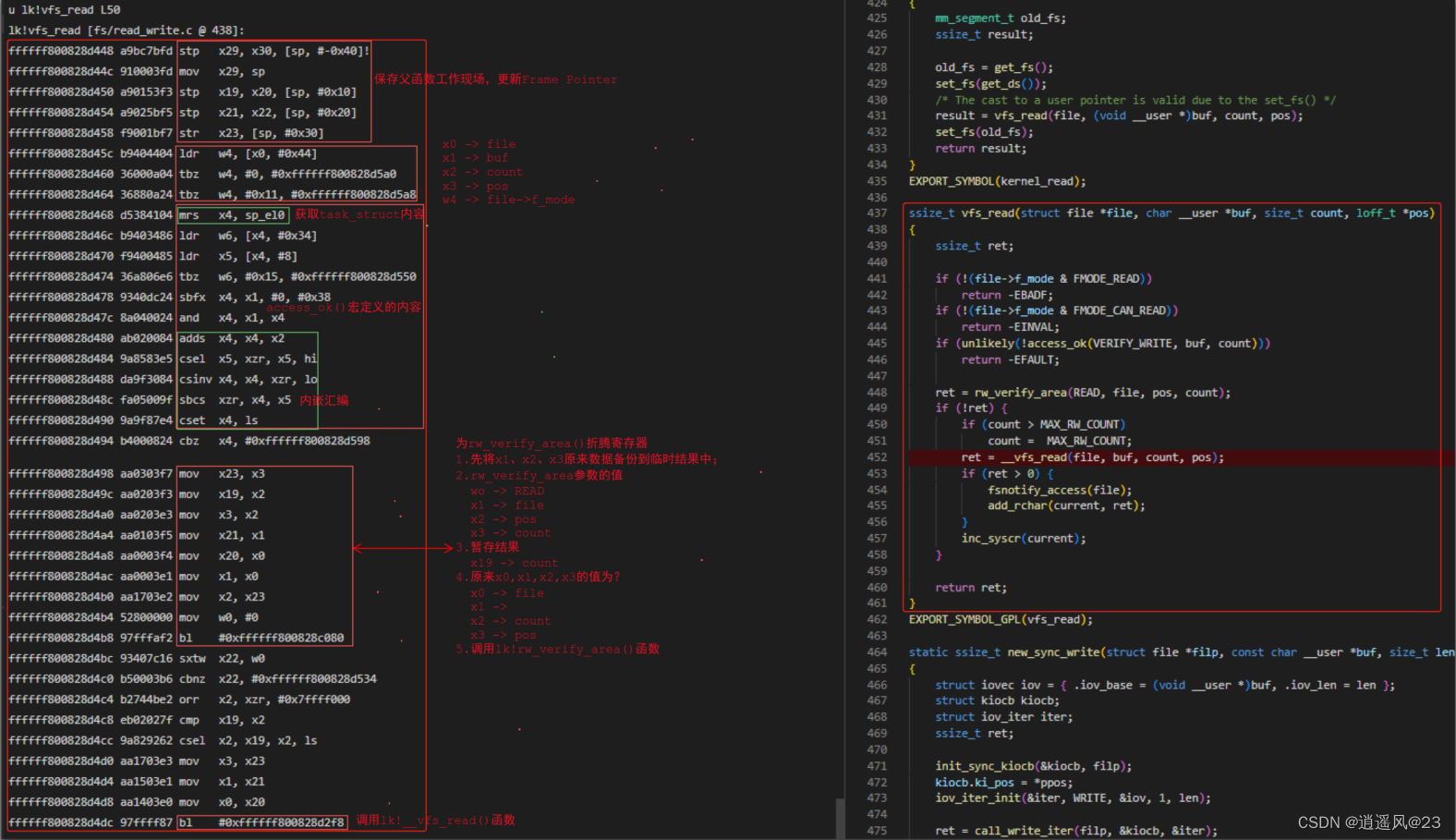
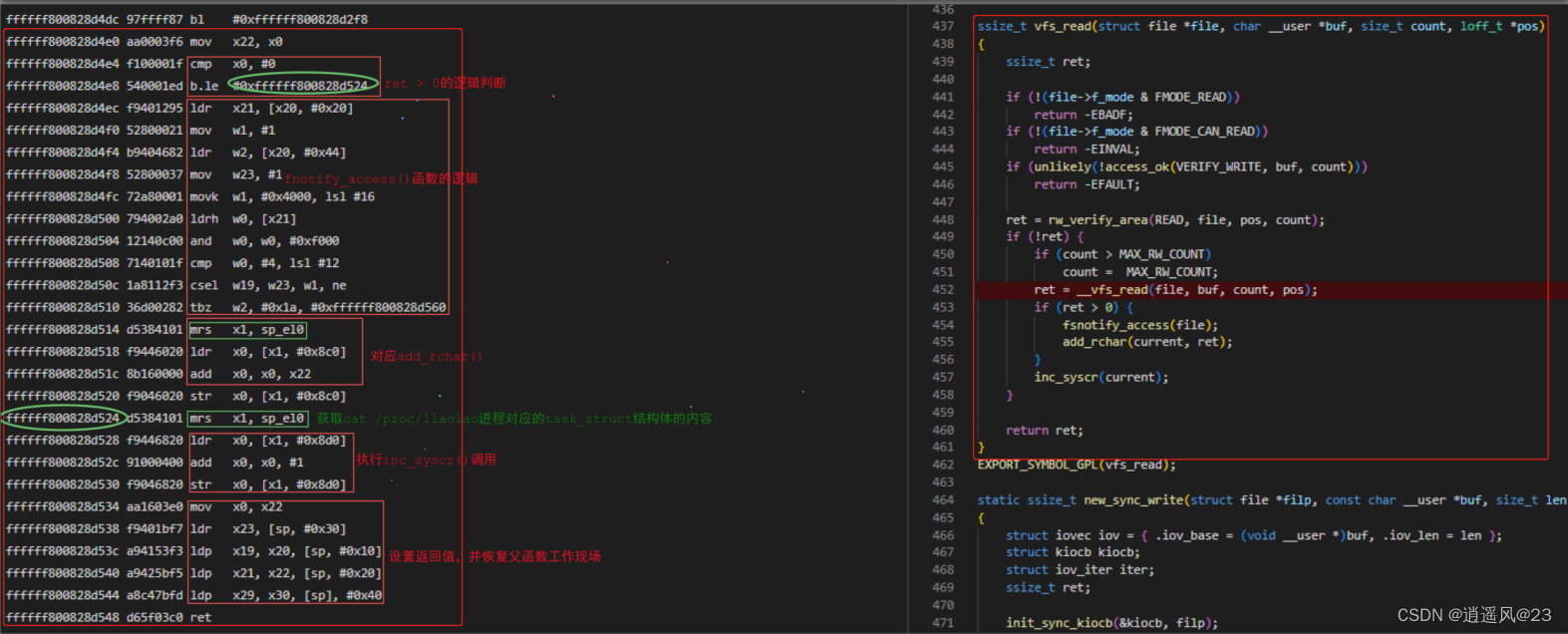
4.5 第4帧ksys_read()函数

4.6 第7帧el0_svc_handler()函数
5. 内容小结
5.1 ARMv8汇编基础
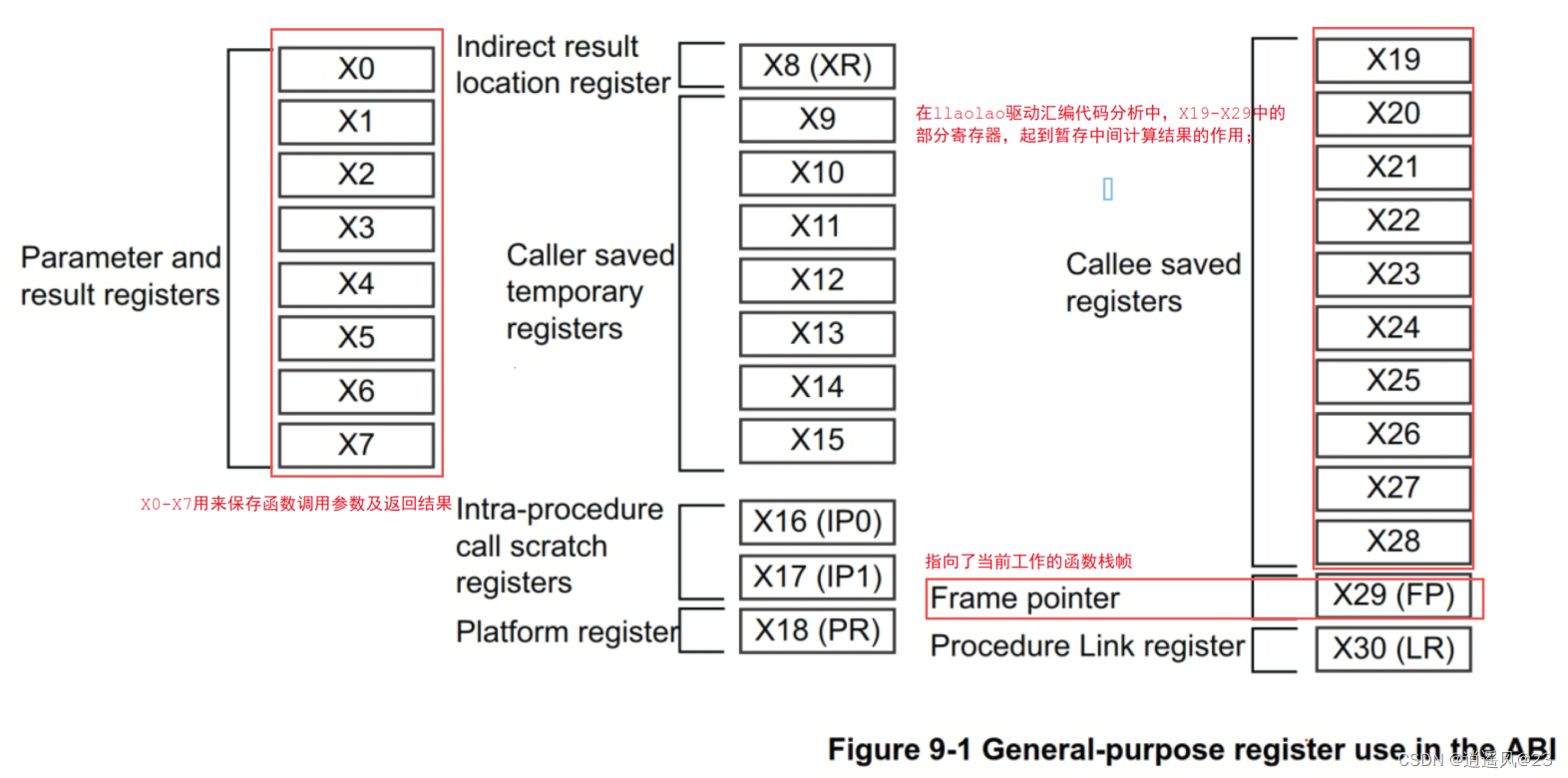
5.2 方法论小结
linux kernel代码量庞大,学习和调试难度大,该章节从宏观和微观两个角度来介绍;
a. 宏观角度 -> 业务流程
b. 微观角度 -> 具体实现 + 汇编代码;理解汇编代码逻辑结构,为内核调试奠定基础。
汇编代码总结
a.根据stp和ldp指令,确定函数的范围区间;
b.根据bl等指令找到子函数调用逻辑;
c.调用子函数前,为函数准备参数;
三 初探文件系统
1. 课前思考
1.1 问题域
a. 文件系统要解决哪些问题?
b.为什么抽象出虚拟文件系统?
c. 从冯·诺依曼体系结构的角度来认识文件系统的地位及价值
1.2 个人理解
a. 文件系统负责文件组织、存储、查找及数据加载;在Unix/Linux系统中,一切设备皆文件,设备管理是文件系统的重要组成部分;
b. 虚拟文件系统与设计模式中的抽象工厂模式如出一辙,向用户提供统一的接口,屏蔽底层业务逻辑细节,兼容不同的文件系统;
c. 冯·诺依曼体系架构是以内存为中心的存储程序思想,虽然内存是核心,但内存容量有限且无法永久存储,因此IO很好的解决了这个问题;
2.宏观视图
2.1 逻辑视图

2.2 读文件过程
a. 进程通过系统调用向内发发起读文件操作;
b. 系统根据系统中断号,在系统调用表中选择相应的系统调用;
c. 通过进程task_struct找到文件描述符,查看该文件是否有缓存,若已缓存则直接读取;
d. 若无缓存,进一步找到dentry及inode信息,并将相应信息缓存内存中,并在AddressSpace记录其相关信息;
e. 若AddressSpace中出现缓存缺页,则产生缺页中断,根据inode信息加载磁盘中相应的数据信息;
3.理解四大对象
在Unix/Linux系统中,将外设统一抽象为文件,文件系统负责文件的组织和管理,VFS屏蔽底层具体的设备/文件系统,向用户提供统一的访问接口。Linux kernel抽象出四大核心对象用于文件系统的组织和管理,SuperBlock和inode用于组织文件系统,file对象记录了进程访问文件的上下文,dentry为文件名和inode建立映射关系,提高系统访问效率;
3.1 超级块
在Linux系统中存在N个文件系统(如ext2),kernel用super_block来组织所有文件系统,并以链表的形式组织起来;
每个文件系统拥有唯一的设备编号、文件系统类型、文件系统操作方法、inode数及inode相关信息;
文件系统初始化时确定了inode的个数;
下面截取了部分代码以供参考
struct super_block { //
struct list_head s_list; //超级块链表
dev_t s_dev; //超级块对应的设备编号
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type; //具体文件系统类型
const struct super_operations *s_op; //具体文件类型的操作方法
struct dentry *s_root;
/***/
const struct xattr_handler **s_xattr;
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; /* 某一具体文件系统所有的inode节点 */
spinlock_t s_inode_wblist_lock;
struct list_head s_inodes_wb; /* 回写节点内容 */
} __randomize_layout;
3.2 inode
文件系统中文件的逻辑概念就是用inode来描述的,且每个文件都拥有唯一的inode编号,即使用ls命令所列举出的文件。
inode节点记录了inode所属用户、用户组、访问及修改时间、所在设备ID、file_operations等相关信息,字段信息可参考所截取的代码;
struct inode {
kuid_t i_uid; //用户ID
kgid_t i_gid; //用户组权限
const struct inode_operations *i_op; //inode操作对象
struct super_block *i_sb; //所属超级块
struct address_space *i_mapping; //缓存数据
unsigned long i_ino; //每个文件都拥有唯一的ino;
dev_t i_rdev;
loff_t i_size;
struct timespec64 i_atime; //文件访问、修改时间
struct timespec64 i_mtime;
struct timespec64 i_ctime;
const struct file_operations *i_fop; //inode对应的文件操作
void *i_private; /* fs or device private pointer */
} __randomize_layout;
3.3 file
问题场景:当多个进程同时访问磁盘上的同一个文件时,并且每个进程访问文件的位置不同,如何将访问的上下文记录下来?
super_block和inode解决了文件组织和存储的问题,当多进程访问文件时,可大致分为两部分信息:①文件原始信息,即inode数据;②进程访问文件的上下文;如果每个进程访问文件时,将文件的原始均拷贝一份,那将非常浪费空间;inode和file可认为是两个维度的信息,一个是进程访问文件的动态信息,一个是文件存储的静态信息;但两者会有交互,某个进程会写文件,会修改静态的原始数据;
file数据结构记录了进程访问文件的上下文 【备注:在2.x内核中,file结构体与super_block耦合在一起】
struct file {
struct path f_path; // 文件路径
struct inode *f_inode;// 指向文件的原始信息
const struct file_operations *f_op; //每个文件对应的操作方法
atomic_long_t f_count; //文件引用计数
loff_t f_pos; // 访问文件的位置
struct fown_struct f_owner;
struct address_space *f_mapping;
} __randomize_layout __attribute__((aligned(4)));;
3.4 dentry
内存和磁盘的访问时间至少相差一个数量级,检索一个文件有可能会多次访问磁盘,导致大量的Cache miss,严重影响系统性能。通过dentry缓存inode的内容,可减少内存及磁盘访问,提高系统性能;
struct dentry {
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
} __randomize_layout __attribute__((aligned(4)));;
四 理解网卡驱动
1.课前思考
1.1 问题域
a. 如何组织和管理硬件设备及驱动程序?
b. 外部设备是如何接入到操作系统的?相关的系统接口是什么?
c. 计算机系统是如何访问设备存储空间的?设备是如何与计算机系统进行通信?
d. 外部设备与计算机系统交互的内容都有哪些?如何访问硬件设备的物理内存?外设如何与CPU之间进行交互?
e. 驱动模型都有哪些数据结构?他们之间的逻辑关系是什么?
f. 驱动模型中核心的概念都有哪些?
g. 设备发现的逻辑是什么?设备和驱动匹配的逻辑是什么?
1.2 个人理解
内核管理外设,提供了接入系统的接口。计算机系统需要和外设进行交互,访问外设物理存储空间;外设以异步的方式进行工作,以中断的方式与CPU进行交互。每个外设均需要配置物理内存空间、响应中断、驱动与设备匹配标识,需要将这些配置信息与业务逻辑解耦合,在计算机发展过程中提出了PnP的解决方案,在ARM中以DTS的形式来实现灵活配置硬件的所需的相关数据。
设备驱动主要包括以下几个方面逻辑:①框架接入代码,包括驱动模板(ixgbe_driver)及操作方法(ixgbe_netdev_ops);②业务逻辑,涉及到具体设备的相关业务细节,如ixgbe,有数据链路层、物理层、存储信息
2.网卡注册流程
2.1 宏观视图

2.2 注册流程
2.2.1 触发驱动注册
内核模块是接入kernel的一种方式,insmod触发了驱动注册流程,module_init()为接入kernel的入口函数
2.2.2 总线中注册驱动
pci_register_driver()为将驱动程序接入到驱动管理框架的接口,在执行过程中触发用户业务逻辑(ixgbe_probe),创建/sys/devxxx目录
2.2.3 触发驱动挂载逻辑
驱动挂载逻辑主要包括:为设备配置物理地址空间、设置中断、创建设备并将设备注册到系统中;
2.2.4 将ixgbe_poll方法注册到napi_hash结构中
kernel使用vector + hashtable的设计方式,很好的兼顾了性能和扩展性,hashtable为设备动态注册提供了便利
2.2.4 DTS
DTS中包含中断、物理内存地址空间、设备编号等信息。操作系统在加载时,解析DTS相关配置文件,在设备驱动注册时,根据设备编号来配置中断号、物理内存等相关信息
2.3 网卡收包流程
a. 网卡收到网络包;
b. 网卡把数据DMA到内存中;
c. 网卡向CPU发出硬中断,CPU相应硬中断,简单处理后触发软中断;
d. ksoftirq内核线程根据中断向量表,找到注册到napi_hash中的ixgbe_poll方法,开始收包;
e. 数据帧被从RingBuffer中摘下,生成skb进入协议栈,进入协议栈处理逻辑;
五 闲侃学习内核的思路
5.1 学习的难点
a. 内核代码量庞大,数据结构关联度高,函数调用路径长;
b. 涉及知识面广,涉及硬件、编译器、汇编等方面;
5.2 个人理解
a. 拥有宏观和微观视角,即拥有大局观和小处着手的能力。从业务需求和技术发展的宏观角度来入手,建立大局观,从上到下的视角来梳理代码。
问题场景是什么 → 为解决问题抽象出哪些概念 → 抽象出哪些数据结构 → 深入某个技术细节。以内存管理为例:为什么要有内存(由图灵机和冯·诺依曼体系架构决定)? → 内存发展中遇到了哪些问题(内存贵而且不够用,是稀有资源) → 虚拟内存技术 → 物理内存和虚拟内存如何组织,两者如何交互的?→ 以用户进程视角,其物理内存和虚拟内存是如何组织的?→ 深入某个技术细节
b. 操作系统为硬件的大管家,站在管理的角度来理解内核。如设备管理,内核提供了设备管理的框架,这部分提供了组织和管理的作用,框架一般包括:接入模块、触发用户逻辑模块;
c. 从多角度思考内核;内核内容繁杂,可尝试从计算机工作过程、应用程序使用资源、内核提供高效组织资源使用资源及提供优质服务的角度;
d. 拥有穿针引线的能力,用问题及宏观视图作为骨架将数据结构和关键流程串联起来;
e. 内核代码只是冰山一角,要挖掘代码背后的问题场景,其解决问题的思路以及代码设计的高明处;
f. 不结合实际的哲学是空洞的,不结合细节的方法是绣花枕头。方法只是为了看清事情的脉络,有方法有细节才能更好掌握内核。
六 后记
以上为内核学习的思路及内容整理,主要以图示的方式来展示并未涉及太多细节
学习内核要拥有大局观等很多思想均来自于张银奎老师,张老师是学习内核路上的良师,在这里感谢张老师
参考资料:
《在调试器下理解计算机系统》
《在调试器下理解Armv8》
《深入理解Linux网络》















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









