







1、 编译程序的任务是把源语言程序翻译成目标程序,有些编译程序在编译过程中,不产生中间语言,而是直接从源语言程序翻译成目标语言程序。

以上编译过程省略了中间语言,它不利于编译所产生的目标代码的优化.为了产生高质量的代码,可以将源语言程序首先翻译成一种特殊形式的中间语言代码形式,并对其进行优化,然后再将它翻译成最终的目标代码。
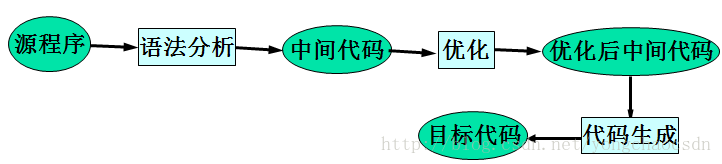
中间代码
中间代码也叫中间语言
(Intermediate code /language)是:源程序的一种内部表示,不依赖目标机的结构,复杂性介于源语言和机器语言之间。
中间代码的优点
1、逻辑结构清楚;
2、利于不同目标机上实现同一种语言;
3、利于进行与机器无关的优化;
语义分析
在词法分析和语法分析之后,编译程序要完成语义分析和翻译工作。由于编译器完成的分析是静态定义的,所以,语义分析也可称作静态语义分析 (taticsemantic analysis)。
语义分析的具体工作
1、类型检查;
2、控制流检查;
3、一致性检查;
4、相关名字检查
语法制导翻译
对文法中的每个产生式都附加一个语义动作或语义子程序,且在语法分析过程中,每当需要使用一个产生式进行推导或规约时,语法分析程序除执行相应的语法分析动作之外,还要执行相应地语义动作或语义子程序。每个语义子程序都指明了相应产生式中各个符号的具体含义,并规定了使用该产生式进行分析时所应采取的语义动作。
由此可见:抽象文法符号的具体语义信息,是在语法分析同步的语义处理过程中获取和加工的。
属性文法
将语义以“属性”的形式附加到各文法符号上,再根据产生式所蕴含的语义,给出每个文法符号的属性的求值规则,从而形成一种带有语义属性的前后文无关文法,即属性文法。
属性
一个文法符号X的语义信息我们称之为语义属性或简称为属性(Atrributes)
X.TYPE表示为X的类型
X.VAL表示为X的值
例:
对于文法:E→E+T | T
T→ digit
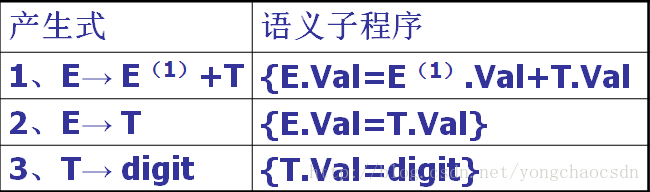
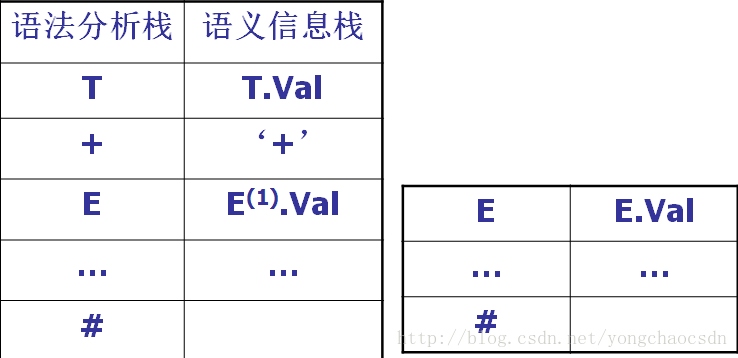
语法制导翻译的实质
根据文法中每个产生式所蕴含的语义,为其配备一个(或多个)语句或子程序,对所要完成的功能进行描述,在语法分析过程中,当分析器使用该产生式进行语法分析时(不论是推导还是规约),除完成语法分析动作之外,还将调用为其配备的语义子程序,进行相应地语义处理,完成语义翻译工作。
中间代码常见的几种形式
1、后缀式
2、图表示法
抽象语法树、DAG图
3、三地址代码
三元式、四元式、间接三元式
后缀式
后缀式是波兰逻辑学家卢卡西维奇(J.Lukasiewicz)提出的一种对表达式的表示方法:每一运算符都置于其运算对象之后,即操作数写在前面,算符写在后面。
它的特点是:表达式中各个运算是按运算符出现的顺序进行的,故无需用括号来指示运算顺序,因而又称为无括号式。

结论
从以上两个例子我们可得出:
1、在两种表示中,运算对象出现的顺序相同;
2、在后缀表示中,运算符按实际计算顺序从左到右排列,且每一运算符总是跟在运算对象之后。
图表示法- 抽象语法树
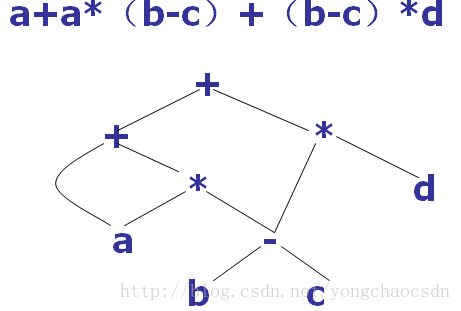
在语法树中去掉一些对翻译不必要的信息后,获得的更有效的源程序的中间表示,这种经过变换后的语法树称为抽象语法树。
在抽象语法树中,操作符和关键字都不作为叶子节点出现,而是把它们作为内部节点,即这些叶子节点的父节点。
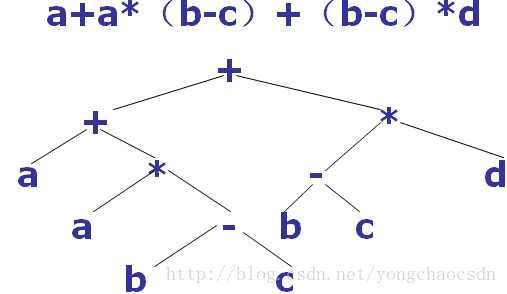
抽象语法树的表示方法
1、每一个结点用一个记录来表示,该记录包括一个运算符域和若干个指向子结点的指针域。
例: a:=b*-c+b*-c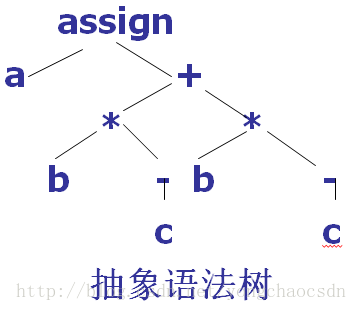
方法1
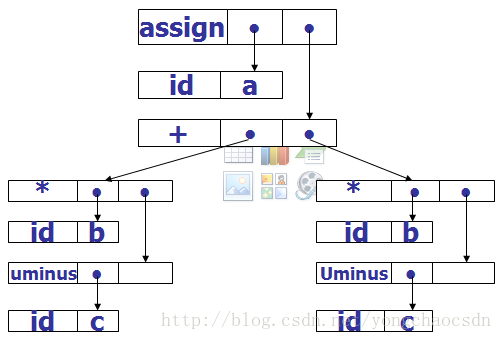
方法2
把所有的结点安排在一个记录的数组中,结点的位置或索引作为指向地点的指针。
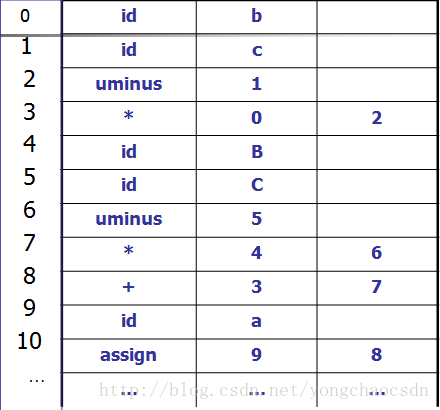
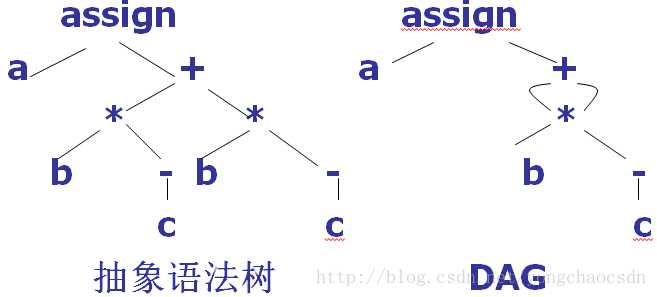
图表示法-DAG图
DAG(Directed Acyclic Graph)有向无循环图
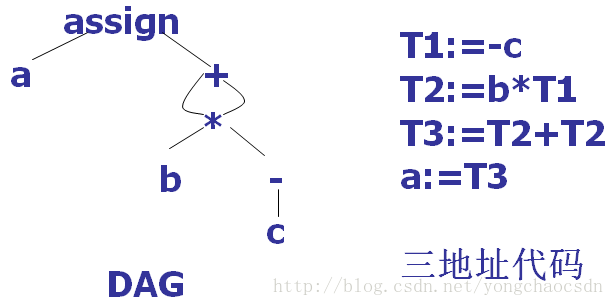
对表达式中的每个子表达式,DAG都有一个结点,一个内部结点代表一个操作符,他的孩子代表操作数。在一个DAG中代表公共子表达式的节点具有多个父结点(与抽象语法树中公共子表达式被表示为重复的子树不同)
例: a:=b*-c+b*-c
三地址代码
三地址代码最基本的用法形式:
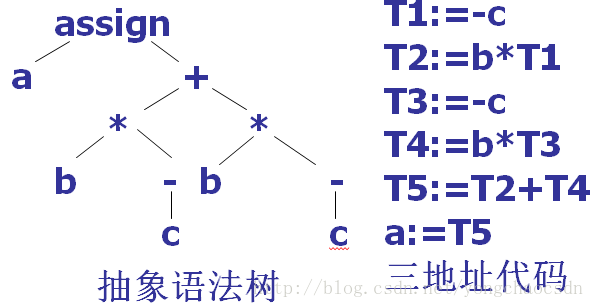
x:=y op z
其中x、y、z为名字、常数或编译时产生的临时变量;op代表运算符号。每个语句的右边只能有一个运算符。
例如:x+y*z可以翻译为:
T1:=y*z
T2:=x+T1
T1、T2位编译时产生的临时变量
三地址代码可以看成是抽象语法树一种线性表示
三地址代码可以看成是DAG的一种线性表示
三地址码的各种形式:
赋值语句翻译为三地址码的属性文法
三地址代码 — 四元式
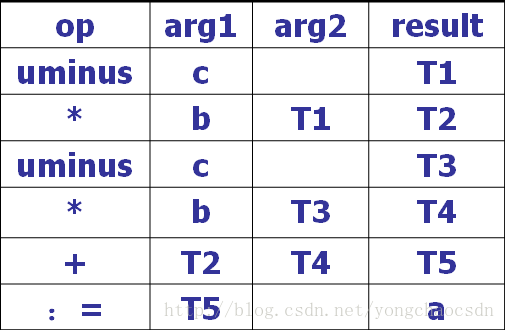
四元式实际上是一种“三地址语句”的等价表示,是一个带有四个域的记录结构。它
的一般形式为:
(op,arg1,arg2,result)
需要指出的是:每个四元式只能有一个运算符,所以,一个复杂的表达式只能由多个四元式构成的序列表示。
例:a:=b*-c+b*-c
三地址代码-三元式
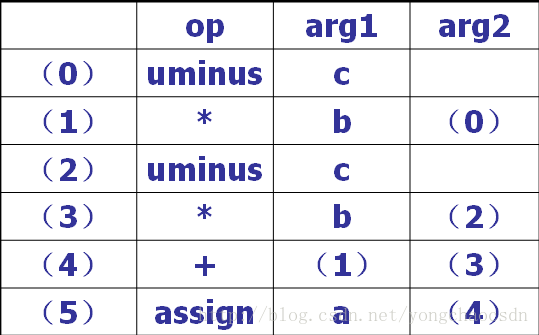
三元式顾名思义就是带有三个域的记录结构,他的一般形式为
(i)(op,arg1,arg2)
其中,(i)为三元式的编号,也代表了该式的运算结果,op,arg1,arg2的含义与四元式类似,区别在于arg可以是某三元式的序号,表示用该三元式的结果作为运算对象。
例:a:=b*-c+b*-c
三元式和四元式的比较
相同点:
1、无论在一个三元式序列还是四元式序列中,各个三元式或四元式都是按相应表达式的实际运算顺序出现的;
2、对同一表达式而言,所需的三元式或
四元式的个数一般都是相同的。
不同点:
1、由于三元式没有result字段,且不需要临时变量,故三元式比四元式占用的存储空间少;
2、在进行代码优化处理时,常常需要挪动一些运算的位置,这对于三元式序列来说是很困难的,但对于四元式来说,由于四元式之间的相互联系是通过临时变量来实现的,所以,更改其中一些四元式给整个系列带来的影响就比较小。
三地址代码-间接三元式
建立两个与三元式有关的表格,一个称为三元式表,用于存放各三元式本身;另一个称为执行表,它按照三元式的执行顺序,依次列出相应各三元式在三元式表中的位置,也就是说我们用一个三元式表连同执行表来表示中间代码。通常我们称这种表示方法为间接三元式。
三元式
x:=(a+b)*c
b:=a+b
y:=c*(a+b)
(1)(+,a,b) (5) (+,a,b)
(2)(*,(1),c) (6)(*,c,(5))
(3)(:=,x,(2)) (7)(:=,y,(6))
(4)(:=,b,(1))
间接三元式
执行表 三元式表
(1) (1)(+,a,b)
(2) (2)(*,(1),c)
(3) (3)(:=,x,(2))
(4) (4)(:=,b,(1))
(1) (5)(:=,y,(2))
(2)
(5)
三元式与间接三元式之间的区别
1、由于间接三元式在执行表中已经依次列出每次要执行的那个三元式,若其中有相同的三元式,则仅需在三元式表中保存其中之一,即三元式的项数一般比执行表的项数少;
2、当进行代码优化需要挪动运算顺序时,则只需对执行表进行相应地调整,而不必再改动三元式本身,这样,就避免了前面讲到的因改变三元式的顺序所引起的麻烦。
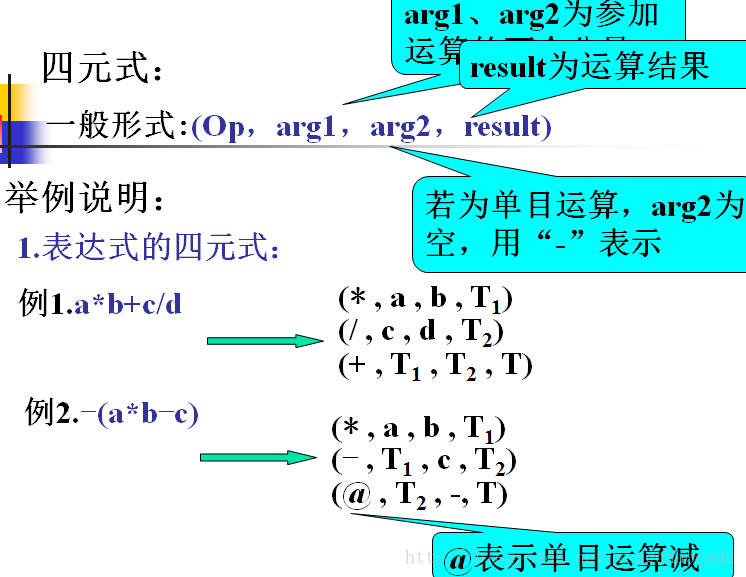

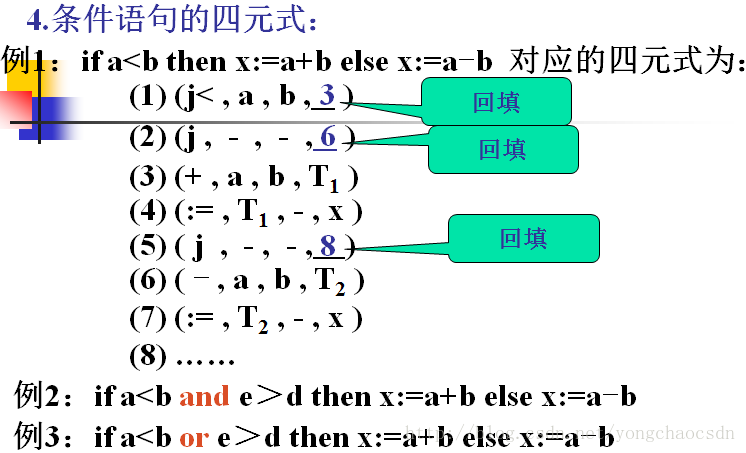
语法制导的翻译方法:
就是对文法中的每个产生式都附加一个
语义动作或语义子程序,且在语法分析过程中,每当需要使用一个产生式进行推导或归约时,语法分析程序除执行相应的语法分析动作之外,还要执行相应地语义动作或语义子程序。每个语义子程序都指明了相应产生式中各个符号的具体含义,并规定了使用该产生式进行分析时所应采取的语义动作
这种模式既把语法分析与语义处理分开,又
令其平行地进行,让其在同一遍扫描中同时完成语法分析和语义处理两项工作。
7.2 说明语句的翻译
一.过程中的说明语句
说明语句的翻译,主要工作是填符号表、分配地址
说明语句的文法产生式及语义动作如下:

7.3 赋值语句的翻译
7.3.1 简单算术表达式及赋值语句的翻译
简单算术表达式及赋值语句的产生式及语义动作如下:

Lookup为查符号表过程
Emit过程用于生成三地址码指令语句并送往输出文件
7.3.2数组元素的引用
一、数组元素的地址计算
1、一维数组
设数组A[low..n],每个元素占w个单元,则
LOC(A[i])=base+(i-low)*w
=i*w+(base-low*w)
其中varpart=i*w C=low*w
conspart=base-C
即地址 D= varpart+conspart
2、二维数组(按行存放)
设 i1,i2的下界为low1,low2,数组是n1×n2,每个元素占w个单元,则
LOC(A[i1,i2])=base+((i1-low1)*n2+i2-low2)*w
=(i1*n2+i2)*w+(base-(low1*n2+low2)*w)
其中varpart=(i1*n2+i2)*w
C=(low1*n2+low2)*w)
conspart=base-C
即地址D=varpart+conspart

例:
A [x] 地址可变部分为x*W, 应生成指令:
(T’:=X*W)
A [x,y] 地址可变部分为(x*n2+y) *W, 应生成指令:
(T1:=X*n2)
(T1:=T1+y)
(T’:=T1*W)
A [x,y,z]地址可变部分为((x*n2+y)*n3+z) *W, 应生成指令:
(T1:=X*n2)
(T1:=T1+y)
(T2:=T1*n3)
(T3:=T2+z)
(T’:=T3*W)
地址不变部分的指令为: (T=A-C)
地址结果指令为: (T’’=T[T’])
二、赋值语句中数组元素的翻译

含数组元素的赋值语句的文法

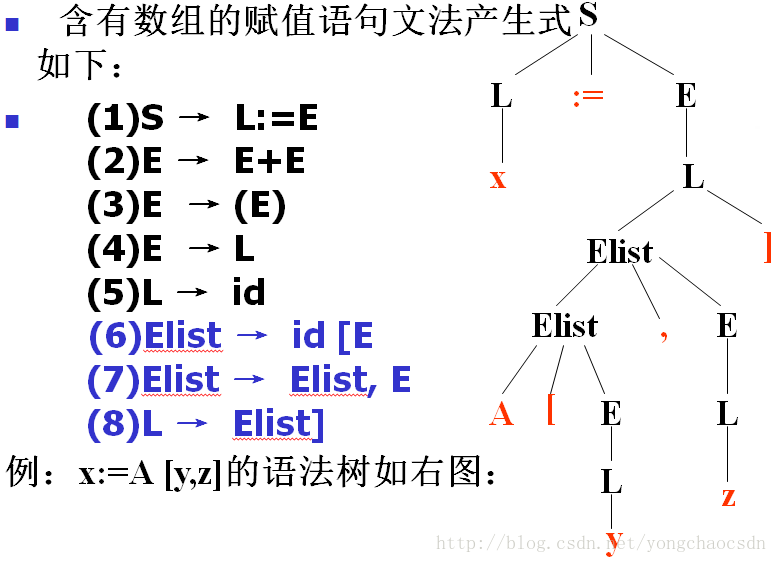


7.4布尔表达式的翻译

















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









