









离散化的原始数据来自 Spark 源码包,离散化函数选用 spark ml 包中的 Bucketizer 方法。
- package ethink
- import org.apache.spark.sql.SQLContext
- import org.apache.spark.SparkConf
- import org.apache.spark.SparkContext
- import org.apache.spark.sql._
- import org.apache.spark.sql.types._
- import org.apache.spark.sql.Row
- import org.apache.spark.ml.feature.Bucketizer
- import org.apache.spark.mllib.linalg.SparseVector
- import org.apache.spark.mllib.linalg.DenseVector
- import org.apache.spark.sql.types.StructType
- import org.apache.spark.ml.feature._
- import org.apache.spark.mllib.regression.LabeledPoint
- import org.apache.spark.mllib.linalg.Vectors
- /**
- * author:Li Ruiqi
- * DataFrame的离散化重组
- */
- object fsTest2 {
- val conf = new SparkConf().setMaster("local").setAppName("RFChurnPredictionByDF")
- val sc = new SparkContext(conf)
- val sqlContext = new SQLContext(sc)
- import sqlContext.implicits._//DataFrame和RDD的隐式转换包
- def main(args: Array[String]): Unit = {
- val rawData = sc.textFile("D:/javaspace/spark161Test/data/mllib/lr_data.txt")
- /**
- * 1000 records (1 - label; 10 - features)
- */
- val records = rawData.map(line => line.split(" "))
- //设置(NumericalData)DataFrame的字段名-FieldName
- val TransString = new Array[String](11)
- TransString(0) = "label"
- for(i <- 1 to 10 ) {TransString(i) = "var" + (i).toString()}
- val schemaString = TransString
- val schema = StructType(schemaString.map(fieldName => StructField(fieldName,StringType,true)))
- val newData = records.map { r =>
- r.map(d => d.toDouble).mkString(",")
- }
- val rddRow = newData.map(_.split(",")).map(k => Row.fromSeq(k.toSeq))//RDD[Row]
- val rowDataFrame = sqlContext.createDataFrame(rddRow, schema)//DataFrame格式的label-NumericalData
- rowDataFrame.show()
- def FieldDiscretization(VarX:String, VarDis:String):DataFrame = { //定制的特征离散化函数
- val NumVar = rowDataFrame.select(VarX).map(k => k(0).toString.toDouble).collect()
- val dataFrameNumVar = sqlContext.createDataFrame(NumVar.map(Tuple1.apply)).toDF("features")
- val sortedVar = NumVar.sorted
- val splits = Array(NumVar.min,sortedVar(200),sortedVar(400),sortedVar(600),sortedVar(800),NumVar.max)
- val bucketizer = new Bucketizer()
- .setInputCol("features")
- .setOutputCol("bucketedFeatures")
- .setSplits(splits)
- val bucketedData = bucketizer.transform(dataFrameNumVar)
- // bucketedData.show()
- val DisVar = bucketedData.select("bucketedFeatures")//离散化之后的特征列
- .withColumnRenamed("bucketedFeatures", VarDis)
- DisVar
- // DisVar.show()
- }
- val Label = rowDataFrame.select("label")
- var zipOutCome = Label
- for(k <- 1 to 10){
- val Para1:String = "var" + k.toString()
- val Para2:String = "var" + k.toString() + "Dis"
- val VarDis = FieldDiscretization(Para1, Para2)
- val zipRDD = zipOutCome.rdd.zip(VarDis.rdd).map(x => Row.fromSeq(x._1.toSeq ++ x._2.toSeq))
- val zipSchame = StructType(zipOutCome.schema ++ VarDis.schema)
- zipOutCome = sqlContext.createDataFrame(zipRDD, zipSchame)
- }
- val disDataFrame = zipOutCome//离散化之后的DataFrame: label - features
- disDataFrame.show()
- /**
- * 普通的二维表格式转换成机器学习需要的DataFrame的Label和Feature格式
- */
- def twoDimTableToDFLabelAndFeature(inputDF: DataFrame):DataFrame = {
- val inputDFLabeledPoint = inputDF.map{row =>
- val rowToArray = row.toSeq.toArray.map(x => x.toString().toDouble)
- val label = rowToArray(0)
- val featuresArray = rowToArray.drop(1)
- val features = Vectors.dense(featuresArray)
- LabeledPoint(label,features)
- }
- import sqlContext.implicits._
- val outputDF = inputDFLabeledPoint.toDF("label","features")
- outputDF
- }
- val df = twoDimTableToDFLabelAndFeature(disDataFrame)
- df.show()
- }
- }
rowDataFrame.show()
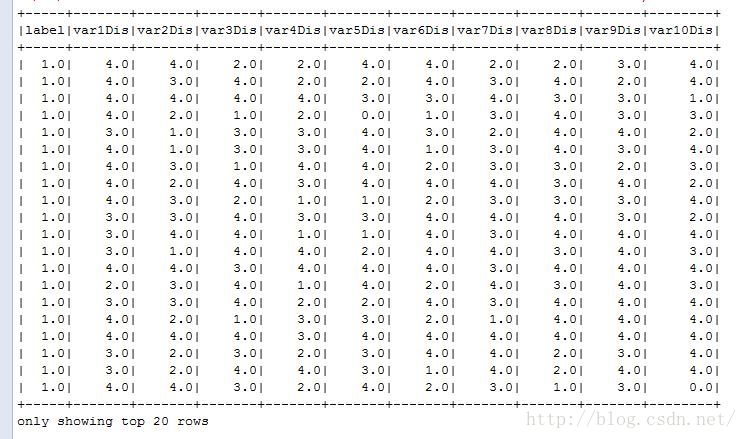
disDataFrame.show()
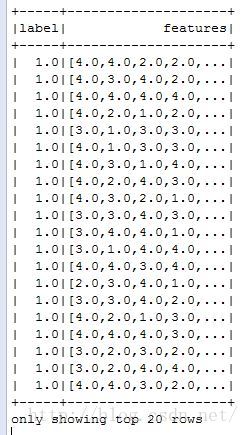
df.show()
参考文章:http://spark.apache.org/docs/latest/ml-features.html#bucketizer















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









