






 本文详细描述了如何使用Selenium爬取巨量创意账户内千川视频的数据,包括登录、数据抓取、滑块验证解决方案以及数据处理过程,旨在提取视频类型、音乐类型、营销卖点和点击指数等关键指标。
本文详细描述了如何使用Selenium爬取巨量创意账户内千川视频的数据,包括登录、数据抓取、滑块验证解决方案以及数据处理过程,旨在提取视频类型、音乐类型、营销卖点和点击指数等关键指标。
目录
前言
本次复盘针对Selenium抓爬巨量创意账户内巨量千川素材的(1)视频类型(2)音乐类型(3)营销卖点(4)视频情节的点击指数、视频数量指数、具体类型数据并写入excel文档中。
本次复盘发现存在一些不足点:(1)未实操解决滑块验证问题【解决方案:采用CV2库进行滑块距离检测】;(2)对爬取的数据没有进行自动化处理,需要人工处理。
1 爬取准备工作
1.1 浏览器驱动下载
爬取浏览器之前需要先将浏览器驱动下载并导入python文件夹,下面以浏览器驱动获取(以Edge浏览器为例),首先通过设置检查浏览器当前版本
Edge浏览器驱动下载网址:Microsoft Edge WebDriver - Microsoft Edge Developer
Tips:其他浏览器驱动可以直接搜索http://t.csdn.cn/XbDTB获取网址
 点击完整目录,找到于自身浏览器版本一致或接近的驱动
点击完整目录,找到于自身浏览器版本一致或接近的驱动

进入网址选取与当前Edge版本最接近的驱动点击 ,下载并解压,将解压后的驱动放入python文件夹内,即可通过selenium库操作Edge浏览器
1.2 Python 运行所需库
from selenium import webdriver
from selenium.webdriver.common.by import By #元素定位
from selenium.webdriver import EdgeOptions,Keys #ChromeOptions用于浏览器操作,Keys用于传输键盘内容
import time #运行暂停(selenium进行点击等操作时候需要缓冲时间)为网页留够停留时间
from lxml import etree #解析HTML文档,将selenium获取的网页源码进行解析以便快速定位元素
import pandas as pd #处理爬取数据写入excel文档
#import re #用于数据的筛选
#from selenium.webdriver.common.action_chains import ActionChains #点击滑块移动(selenium鼠标操作库)
#import cv2 #图像处理进行识别滑块图片位置首先导入所需要使用到的库,其中注释的库为未使用到但可以优化的内容所需要使用的库。
本文使用的是jupyter notebook软件进行Python编写,其中所需要的库可以进入Anaconda Powershell Prompt进行下载,使用pycharm的可直接win+r输入cmd后使用pip install *语句安装库
Tips:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium,国内下载可以使用清华镜像源进行下载速度更快(针对一些库,个人感觉平时用的库下载速度都还可以)

2 爬取工作
2.1 加载网页
在使用selenium前尝试使用requests库进行网页爬取,但发现获取的网页源码不完整导致无法获取数据内容,因此改用selenium进行从登录->查询->搜集的步骤
options=EdgeOptions() #用于设置浏览器启动参数,可以实现无窗口打开爬取
browser=webdriver.Edge(options=options)
'''
url='https://cc.oceanengine.com/login'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188',
'cookie':'x-jupiter-uuid=16915924718287320; s_v_web_id=f1d83ec2c3c4f96446698364201140107fcd2aac4d29dd85e1; _tea_utm_cache_4031=undefined; passport_csrf_token=1de0dfb1df4d6f9060b167b70fb354b6; passport_csrf_token_default=1de0dfb1df4d6f9060b167b70fb354b6; ttwid=1%7CMGJ2jfE8XyO5MUeuomVNPcDFk2gjNDpZ34E-GSgd4Ik%7C1691592478%7C581f76bf9ed054d323d1a1649e49a19ac3c105da98177acf2662d712f9de885d; ttcid=557955ae766143c6b0606c31ec79525129; tt_scid=d2J0LHktfCLq9hhl.oYd-OigE4tt7weQAkPsHjLWHD7SQTIgGZSHEAmfsYh6ZQ4Ldaa4; d_ticket=4e1af4167323346af41358716b5a1e60b2264; odin_tt=d2fbf9a3e6aa9da3e1543a2bcfbf20f88b39bd8519741587eee430a53d80c558d6d7e25b7fc1e6665a0b90bbd1b5083aec272f5ce48db7e41a8119652036fb1e; n_mh=kGDl51rtcD00QSbun1NPGxBFbpIuVI-zn25ePV67spI; sid_guard=1dfbedae37477b87ec9a464c32b57527%7C1691592621%7C5184000%7CSun%2C+08-Oct-2023+14%3A50%3A21+GMT; uid_tt=e29903b0d5266b87b5edd2a7a71caedd; uid_tt_ss=e29903b0d5266b87b5edd2a7a71caedd; sid_tt=1dfbedae37477b87ec9a464c32b57527; sessionid=1dfbedae37477b87ec9a464c32b57527; sessionid_ss=1dfbedae37477b87ec9a464c32b57527; sid_ucp_v1=1.0.0-KGE3NTNhZjMzNThhOWYzM2QwYjNmNzVkNDg1Yzk2MWIzOWQ4YzZmZjgKHwiH6-Ce9cywAhCtz86mBhiyDCAMMPj61KMGOAFA6gcaAmxmIiAxZGZiZWRhZTM3NDc3Yjg3ZWM5YTQ2NGMzMmI1NzUyNw; ssid_ucp_v1=1.0.0-KGE3NTNhZjMzNThhOWYzM2QwYjNmNzVkNDg1Yzk2MWIzOWQ4YzZmZjgKHwiH6-Ce9cywAhCtz86mBhiyDCAMMPj61KMGOAFA6gcaAmxmIiAxZGZiZWRhZTM3NDc3Yjg3ZWM5YTQ2NGMzMmI1NzUyNw; store-region=cn-cq; store-region-src=uid; csrftoken=3Kd_rnDc6jHmSpYOnVrkvwSv; MONITOR_WEB_ID=9b9ec4c0-19e0-46e0-aa0b-a5d59ec4d87a; MONITOR_DEVICE_ID=ef65df58-7ccd-4d9c-9e40-8dcb4e1999f0; msToken=hKfTafSdXlaKGQ7_uhC-GT1haWz28yCNoMAcf6b0-ReAPuUIkT9MkUVPaapRo16PXkYGNEa57GCoRWC7lZ1abQ4EI9q-lFgVblfBm0H8FZ70upWb0b9nx2oShpwmKsM='}
response=requests.get(url2,headers=headers)
str_html=response.content.decode()
print(str_html)
'''
url2='https://cc.oceanengine.com/inspiration/creative-hot/qianchuan/detail/7235138180152721419?appCode=999&period=3&listType=2&materialType=3'
browser.get(url2)
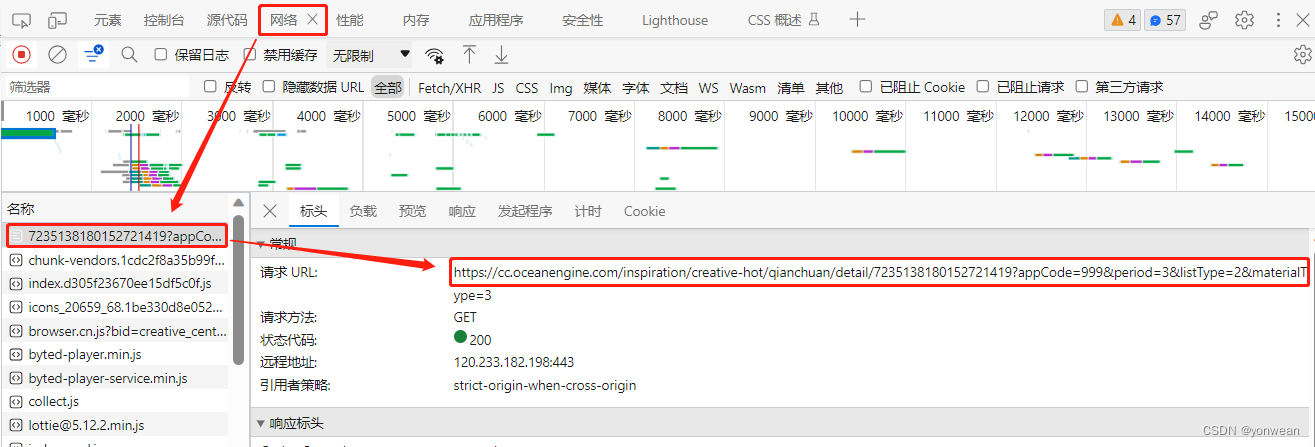
print(browser.title)其中url与cookie参数可以通过在巨量创意界面按F12进入开发窗口->网络->点击名称->请求url、cookie获取
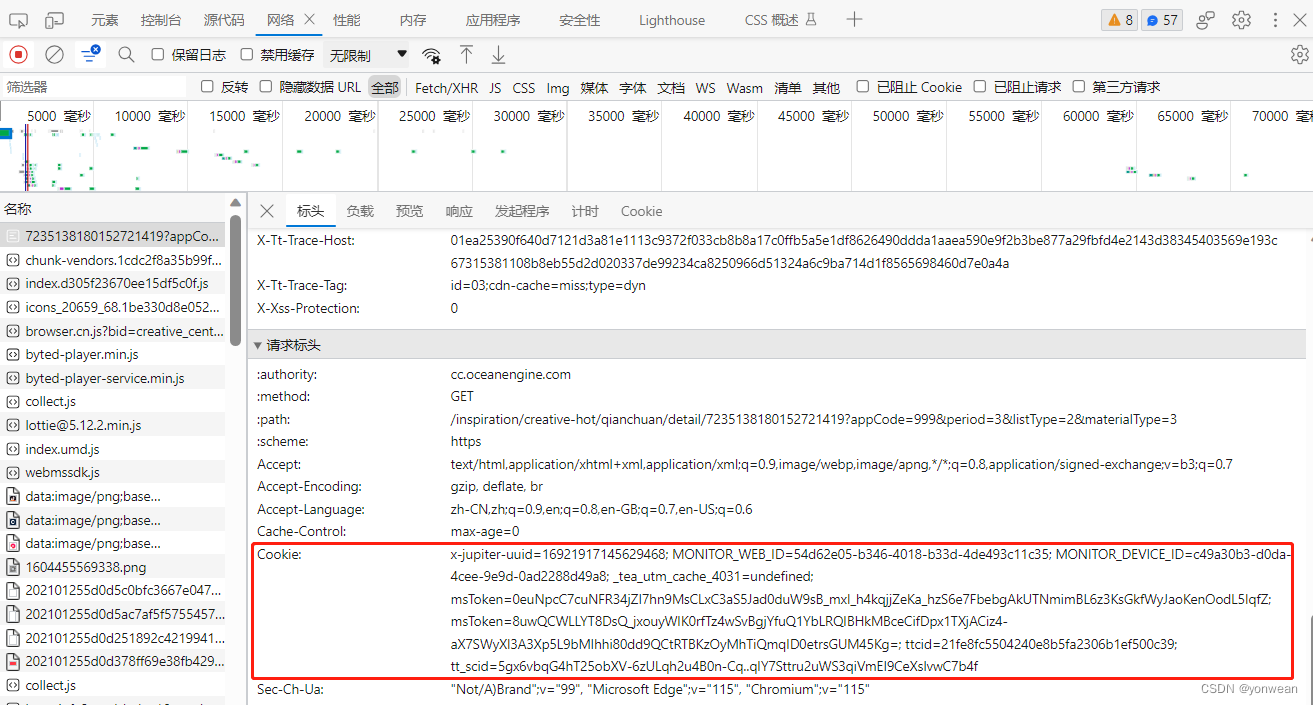
运行该段代码后将会打开Edge浏览器进入巨量创意网址的预登录界面
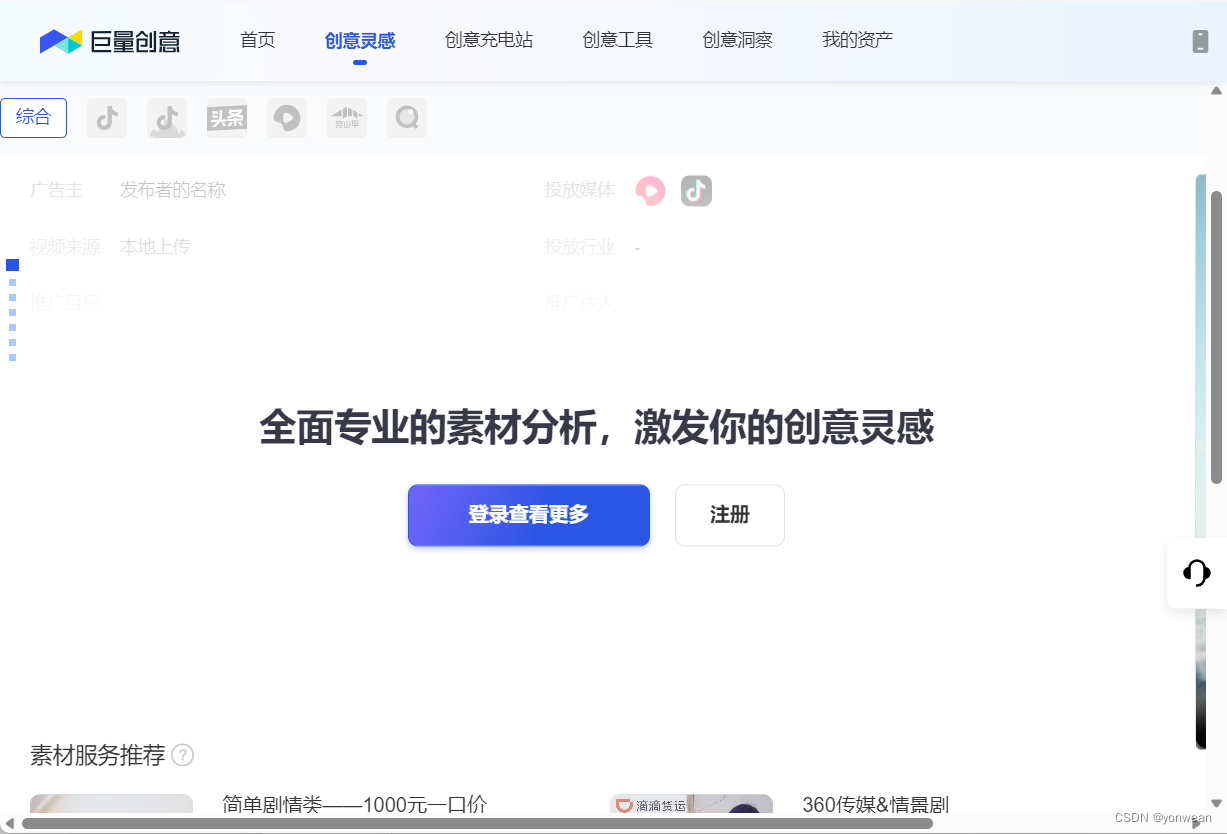 2.2 登录网站
2.2 登录网站
通过find_element函数可以通过不同属性进行元素定位(Tips:满大大写的详细易懂,推荐http://t.csdn.cn/x2PH2),click函数模拟鼠标点击(Tips:selenium常用函数->http://t.csdn.cn/7KFtj)
time.sleep(3)
button1=browser.find_element(By.XPATH,value='//*[@id="cc-app"]/section/header/div/div/div[3]/div[3]').click()
#账号密码登录,手动滑块
time.sleep(3)
email_input=browser.find_element(By.XPATH,value='.//*[@id="cc-login"]/section/div[4]/div[1]/div/div/span/input')
passport=browser.find_element(By.XPATH,value='.//*[@id="cc-login"]/section/div[4]/div[2]/div/div/span/input')
right=browser.find_element(By.XPATH,value='.//*[@id="cc-login"]/section/div[6]/div/div/div')
email_input.send_keys('账号')
passport.send_keys('密码')
right.click()
button2=browser.find_element(By.XPATH,value='.//*[@id="cc-login"]/section/div[7]/button').click()time.sleep操作是为了给程序缓冲时间,既selenium的运行速度与网络有关,如果在同一页面的操作则不需要休眠操作,否则就必须进行休眠不然会报错,因为网页未跳转或显示是无法定位元素,运行结果如下
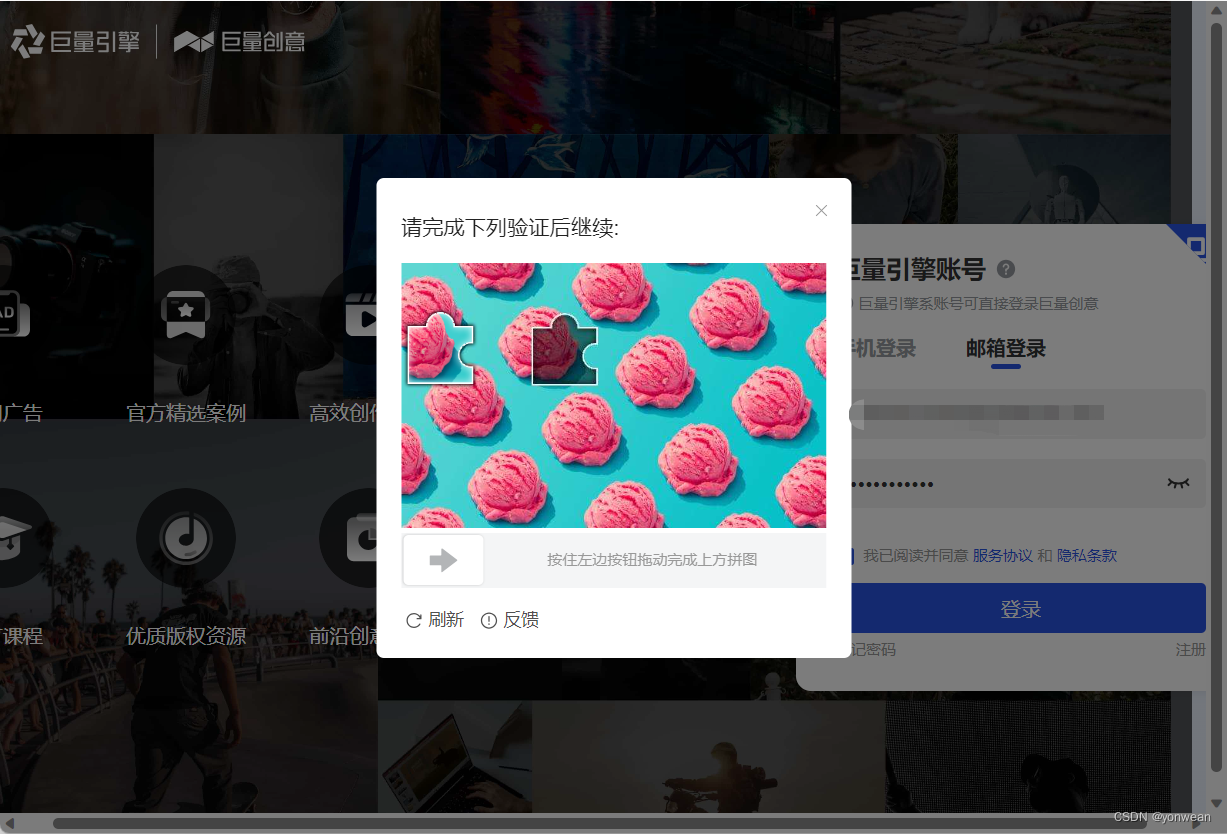
该部分需要手动滑块,因此设置了较长的休眠时间以便手动操作;可先获取验证原图与滑块图片url,通过cv2库进行移动距离判断(借鉴博主:钢铁の洪流,文章:http://t.csdn.cn/yqhSg)
def findpic(target='fadebg.png', template='slider.png'): # 缺口背景图路径, 滑块图片路径
target_rgb = cv2.imread(target) # 读取缺口背景图
target_gray = cv2.cvtColor(target_rgb, cv2.COLOR_BGR2GRAY) # 将缺口背景图 BGR格式转换成灰度图片
template_rgb = cv2.imread(template, 0) # 读取滑块图,第二个参数0表示灰度模式
res = cv2.matchTemplate(target_gray, template_rgb, cv2.TM_CCOEFF_NORMED) # 模板匹配,在大图中找小图
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
return max_loc[0]
2.3 进入指定千川视频搜索
time.sleep(5)
#关闭无用窗口
xx=browser.find_element(By.XPATH,value='.//*[@id="cc-app"]/section/div/div[2]/div/div/div[2]').click()
juliangchuangyi=browser.find_element(By.XPATH,value='.//*[@id="cc-app"]/section/header/div/div/div[2]/div[2]/div[1]/a/div').click()
time.sleep(3)
wozhidaole=browser.find_element(By.XPATH,value='./html/body/div[5]/div/div/div[3]/div/button').click()
juliangqianchuan=browser.find_element(By.XPATH,value='.//*[@id="app"]/section/main/div/div/div[1]/div/div[3]/div[2]/div[2]/a/div/span').click()
time.sleep(3)
search_inf=browser.find_element(By.XPATH,value='//*[@id="app"]/section/main/div/div/div[2]/div/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[1]/input')
search_inf.send_keys('耳机')
#模拟键盘回车键
search_inf.send_keys(Keys.ENTER)
time.sleep(3)
browser.find_element(By.XPATH,value='//*[@id="app"]/section/main/div/div/div[2]/div/div/div[2]/div/div/div[3]/div/div[1]/div/img').click()
time.sleep(2)
browser.find_element(By.XPATH,value='//*[@id="app"]/section/main/div/div/div[2]/div/div/div[2]/div/div/div[3]/div/div[4]/div[2]/div[2]/button').click()运行代码后会搜索有关“耳机”内容素材并且打开新网页
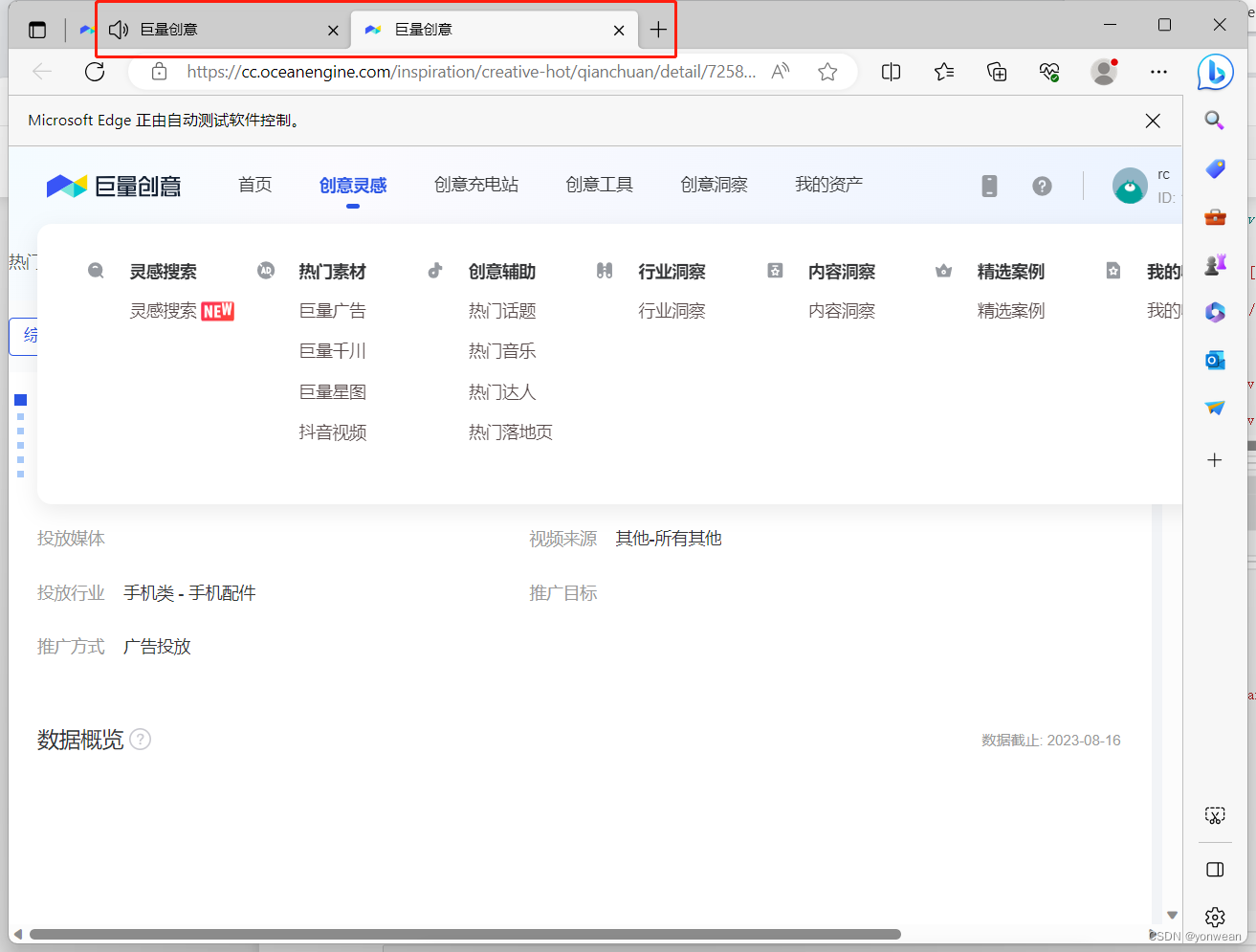
此时注意获取网页句柄,切换至新开网页否则会再旧网页进行操作;这边网页句柄的存储顺序个人认为为打开网页的先后顺序
#获取网页句柄
time.sleep(3)
handles = browser.window_handles
browser.switch_to.window(handles[1])#切换到第2个界面,解决网页跳转问题目标数据为网页中表格内的数据
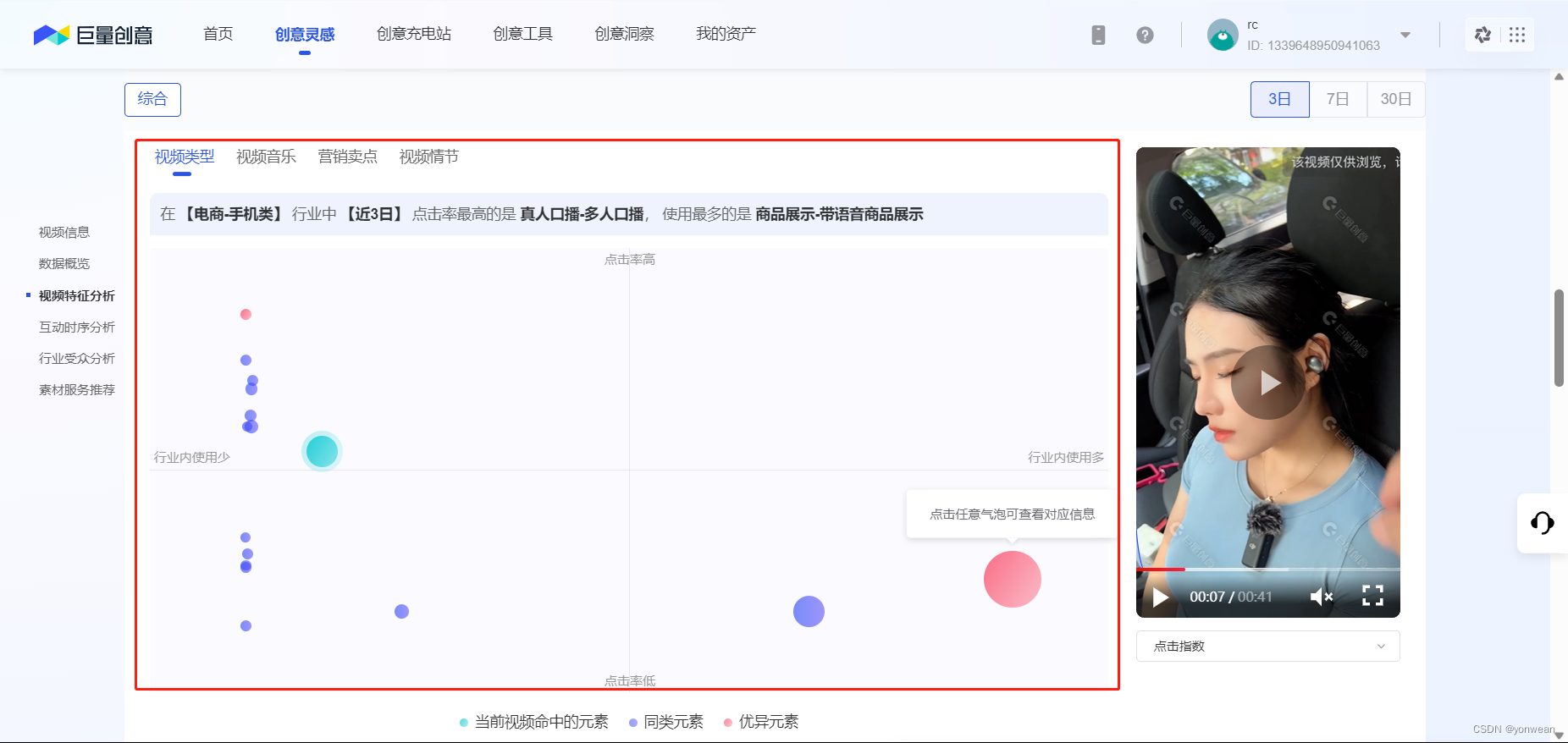
通过开发者控制台能发现存储规律
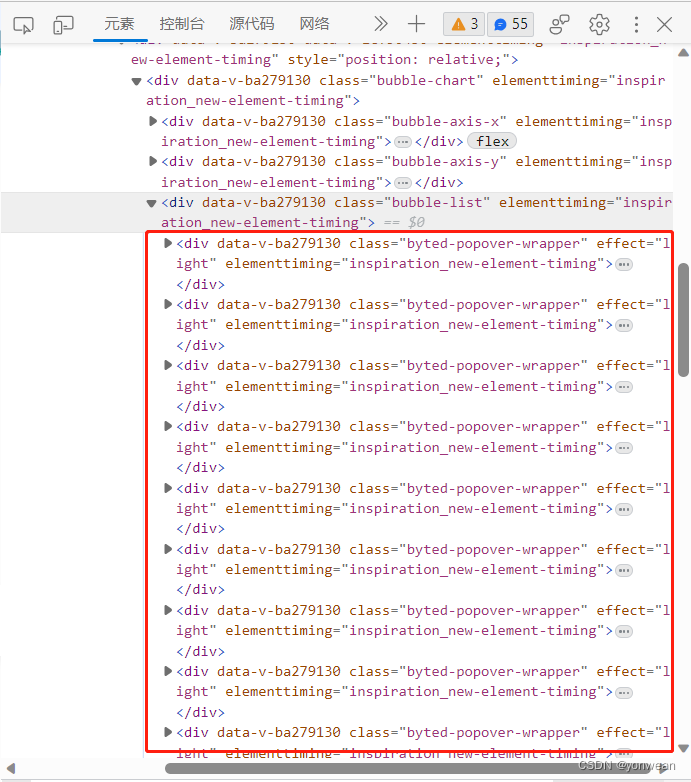
通过遍历与元素定位操作模拟点击分别收集(1)视频类型(2)音乐类型(3)营销卖点(4)视频情节的点击指数、视频数量指数、具体类型数据并存入excel
time.sleep(3)
current_page=browser.page_source
tree=etree.HTML(current_page)
result=etree.tostring(tree).decode('utf-8')
#视频内获取数据
type_name=['视频类型','视频音乐','营销卖点','视频情节']
click_paths=['//*[@id="j-section-feature"]/div[2]/div[1]/span[1]','//*[@id="j-section-feature"]/div[2]/div[1]/span[2]','//*[@id="j-section-feature"]/div[2]/div[1]/span[3]','//*[@id="j-section-feature"]/div[2]/div[1]/span[3]']
for click_node in click_paths:
browser.find_element(By.XPATH,value=click_node).click()#点击跳转
lists=tree.xpath('.//*[@id="j-section-feature"]/div[2]/div[2]/div[1]/div[2]/div[1]/div[3]/div')
for typ in type_name:
for alist in lists:
vedio_name=alist.xpath('.//div[@class=\'bui-popover-body\']/h3/text()')
click_per=alist.xpath('.//div[@class=\'bui-popover-body\']/ul/li[1]/text()')
num_per=alist.xpath('.//div[@class=\'bui-popover-body\']/ul/li[2]/text()')
data_list.append({typ:vedio_name,'点击指数':click_per,'数量指数':num_per})
df=pd.DataFrame(data_list)
df.to_csv('手机类别视频汇总.xlsx',encoding='utf-8',index=False)此时如果要继续查找“影音数码”视频的相关数据则需要先通过句柄控制返回搜索界面,同搜索“耳机”内容一致进行操作
time.sleep(3)
handles = browser.window_handles
browser.switch_to.window(handles[0])#切换到第2个界面,解决网页跳转问题
time.sleep(3)
search_inf=browser.find_element(By.XPATH,value='//*[@id="app"]/section/main/div/div/div[2]/div/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[1]/input')
search_inf.send_keys(Keys.CONTROL,'a')
search_inf.send_keys('影音娱乐')
search_inf.send_keys(Keys.ENTER)
time.sleep(3)
browser.find_element(By.XPATH,value='.//*[@id="app"]/section/main/div/div/div[2]/div/div/div[2]/div/div/div[3]/div/div[1]/div/img').click()
time.sleep(2)
browser.find_element(By.XPATH,value='//*[@id="app"]/section/main/div/div/div[2]/div/div/div[2]/div/div/div[3]/div/div[4]/div[2]/div[2]/button').click()
值得注意的是,搜索网页中搜索框有“耳机”内容需要进行清楚,这里曾使用clear函数进行清除但无响应,因此选择模拟ctrl+a全选内容框修改内容,获取方式同“耳机”视频获取方式相同便不再赘述。
3 数据处理
通过to_csv函数保存数据,此次学习没有使用正则语言已经pandas库进行数据处理,学习路程还很长
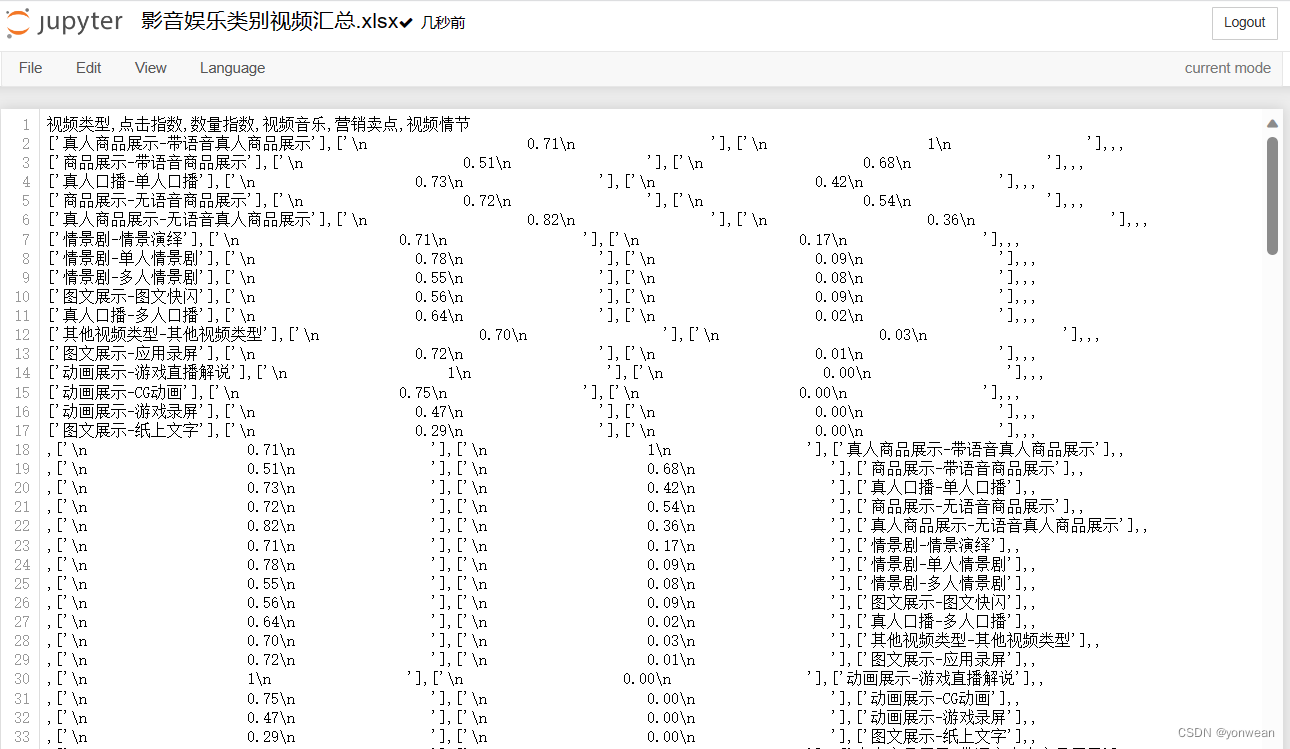
认清平庸好好学习,早日摆脱**公司!-rc


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









