







计算图:是包含节点和边的网络。本节定义所有要使用的数据,也就是张量(tensor)对象(常量、变量和占位符),同时定义要执行的所有计算,即运算操作对象(Operation Object,简称 OP)。
每个节点可以有零个或多个输入,但只有一个输出。
图定义和执行的分开设计。
每个会话都需要使用 close() 来明确关闭,而 with 格式可以在运行结束时隐式关闭会话。
TensorFlow 还允许使用 with tf.device() 命令来使用具有不同计算图形对象的特定设备(CPU/GPU)
run(fetches,feed_dict=None,options=None,run_metadata)
运算结果的值在 fetches 中提取;在示例中,提取的张量为 v_add。run 方法将导致在每次执行该计算图的时候,都将对与 v_add 相关的张量和操作进行赋值。如果抽取的不是 v_add 而是 v_1,那么最后给出的是向量 v_1 的运行结果:
{1,2,3,4}
此外,一次可以提取一个或多个张量或操作对象,例如,如果结果抽取的是 [v_1,v_2,…,v_add],那么输出如下:
{array([1,2,3,4]),array([2,1,5,3]),array([3,3,8,7])}
zero_t = tf.zeros([2,3],tf.int32)
test = tf.zeros_like(a)
range_t = tf.linspace(2.0,5.0,5)
#We get:[2. 2.75 3.5 4.25 5.]
range_t = tf.range(10)
随机生成的张量受初始种子值的影响。要在多次运行或会话中获得相同的随机数,应该将种子设置为一个常数值。当使用大量的随机张量时,可以使用 tf.set_random_seed() 来为所有随机产生的张量设置种子。以下命令将所有会话的随机张量的种子设置为 54:
tf.set_random_seed(54)
tf.random_crop(t_random,[2,5],seed=12)
这里,t_random 是一个已经定义好的张量。这将导致随机从张量 t_random 中裁剪出一个大小为 [2,5] 的张量。
变量的定义将指定变量如何被初始化,但是必须显式初始化所有的声明变量。在计算图的定义中通过声明初始化操作对象来实现:
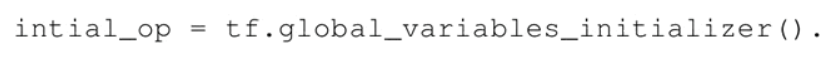
保存变量:使用 Saver 类来保存变量,定义一个 Saver 操作对象:
saver = tf.train.Saver()
用 tf.convert_to_tensor() 可以将给定的值转换为张量类型
tf.eye(5) #返回大小为5的单位矩阵
对于变量,要初始化,可以使用全部初始化函数 或者 单个进行初始化
1.全部初始化:
init_op = tf.global_variables_initializer()
sess.run(init_op)
2.单个优化 a_var.initializer.run():需要注意的是要在sess之后写
tf.summary.FileWriter(‘summart_dir’,sess.graph)
#tensorboard --logdir=C:\Users\Administrator\Desktop\python工程\tf1.x\summart_dir
tf.matmul(a,b) #矩阵乘法,和a @ b相同
a * b #是对应的元素相乘
tf.div(a,b) #矩阵除法
tf.scalar(2,a) 相当于2 * a
以 DNN 为例,通常需要知道损失项(目标函数)如何随时间变化。在自适应学习率的优化中,学习率本身会随时间变化。可以在 tf.summary.scalar OP 的帮助下得到需要的术语摘要。假设损失变量定义了误差项,我们想知道它是如何随时间变化的:
loss = tf…
tf.summary.scalar(‘loss’,loss)
TensorFlow 将支持的 CPU 设备命名为“/device:CPU:0”(或“/cpu:0”),第 i 个 GPU 设备命名为“/device:GPU:I”(或“/gpu:I”)。















 3533
3533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









