









论文网址:https://arxiv.org/abs/1809.05679
可供参考网址:https://blog.csdn.net/weixin_42720033/article/details/93534127
文本图神经网络 (text GCN)
1.构建图
在GCN基础上进行的改造,主要改造在于提出将整个语料库构造成一个图。
结点是语料库中的每个(document + 字典中的word )所以建出来的图是挺大的,但实际上就是一个大的矩阵。
边只存在(document跟word)和(word跟word),也就是说document之间是没有边的,边的权值由下面的公式确定。
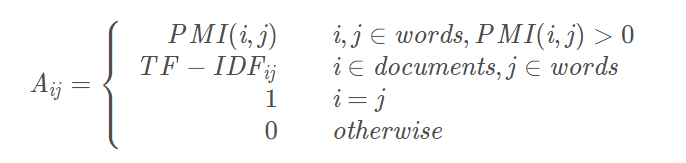
由上面的公式,(document跟word)之间的边用TF-IDF计算,计算方式:

(word跟word)之间的边的权值由PMI计算,计算方式如下:

2.使用GCN方法进行传递

在论文中,使用了两层的GCN进行传递,传递的计算如下:

3.训练
这个语料库中一部分文档是有标签的,只能根据这部分训练,训练完后推出这个语料库中的其它文档的类别。(所以就是说在实际使用它的时候,每次都要对自己的语料库进行构图、训练,不是很方便)

4.other
1.(document跟document)之间是没有边连接的,但是在经过两层后他们实际上有共通,因为document在第一层会考虑到和它相连的边,在第二层会继续往外考虑,所以(document跟document)有些边就共通了。
2.参数敏感性
不同滑窗大小会影响模型准确率。实验表明,滑窗越大,平均准确率随之提高,当滑窗到达某一临界值时,平均准确率有所降低。因为当滑窗设置过小时,不能有效保留全局词的共现信息;当滑窗设置过大时,每个滑窗内关联度不够紧密的边的比例有所增加。
不同的嵌入表示维度也会影响模型准确率。当第一层的嵌入维度过低时,会丢失一些标签信息;当嵌入维度过高时,对模型的分类能力没有改善,甚至需要更多的训练时间。因此,选择一个合适的嵌入维度很重要。
3.模型缺点
虽然Text GCN有很强的文本分类能力和词、文档嵌入表示能力,但是模型的主要局限在于Text GCN模型有内在传导性,无标签的测试文档doc节点包含在GCN的训练集中。换句话说,Text GCN不能快速产生嵌入表示,并预测没有出现过的文档。可能的解决方案有介绍归纳法和fast GCN模型。
未来可能会引入注意力机制并研究无监督Text GCN框架,用于大规模无标签Text数据集上的表示学习。















 2508
2508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









