







在上一篇文章之中,小编简单的介绍了目前Python中主流的三大Web框架,分别是Django、Flask和FastAPI,并且介绍了它们的优缺点。
并且,我们快速的使用FastAPI搭建了一个简单的RestFul风格的接口,并且使用unicorn作为Web服务器,来向外提供服务。
最后,我们使用我们学习到的FastAPI知识,再结合大模型,向外搭建了一个简单的对话系统,以此来实现我们需要的流式传输。
但是实际上,上述的所有步骤,我们都写在了一个main.py文件当中,这是相当的耦合的,通常来讲,我们在软件开发当中,我们不希望我们整个系统的架构,过于耦合,这样会让整个代码难以维护。
所以,在这篇文章当中,我们会对FastAPI项目的整体架构做一个规划,以让我们的代码避免只写在main.py文件当中,这是相当难以扩展的。
在这篇文章当中,你可以学习到:
- 结构化的Python Web开发文件规划。
- 单例模式封装和在Python Web中的应用。
- 通用返回类封装。
- 通用配置类封装。
- 通用日志类封装。
- FastAPI多文件路由实现。
- FastAPI中间件配置。
文件规划
llm # 项目名称
--app # 存放项目路由和实体类的地方
--frame # 存放项目架构的地方,以后我们的大模型会在这里加载
--resources # 存放配置文件的文件夹
--main.py # 项目的主入口
--config.py # 项目的配置类
--README.md # 项目的readme文档
--conda_env_windows.yaml # 项目的conda导出的yaml环境文件(windows),以便于后续迁移
--conda_env_linux.yaml # 项目的conda导出的yaml环境文件(linux),以便于后续迁移
--run.sh # 项目启动的sh文件,用于在linux环境下快速部署
--stop.sh # 项目停止的sh文件,用于在linux环境下快速停止
--requirements.txt # 如果不使用conda环境安装,需要的包文件
--.gitignore # 项目的git上传文件
我们再来回顾一下,上一篇博客当中,我们写的一个标准的生产环境当中的Python Web项目架构。
当然,对于很多人来说,每一个标准的实现都不尽相同,但是小编还是很推荐这一套架构,因为我是认为,这样不管是对任何来说,都是一个很好理解和实现的架构。
app:它不存储任何架构相关的文件,它只存放项目路由、POJO等文件。
frame:只存放架构相关的文件,例如中间件、工具类、设计模式等。
resources:只存放资源类文件,例如application.yaml文件等。
单例模式
对任何一个学习计算机的人来说,单例模式并不罕见,甚至说是在我们日常的开发之中,这是一个相当常见的设计模式,不管是Spring框架管理的Bean默认情况下是单例,或者是各种超级Factory,都是以单例模式实现的。
以下是一个单例模式的简单介绍。
单例是一种创建型设计模式, 让你能够保证一个类只有一个实例, 并提供一个访问该实例的全局节点。
而对于Python来说,实现单例的方式也是相当简单,我们将单例模式放在我们的项目当中。
class SingletonMode(type):
"""
此模块实现了一个单例模式,用于确保在应用程序中只有一个实例存在。
如果你需要实现一个单例,可以用 Singleton 作为元类。
"""
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super().__call__(*args, **kwargs)
return cls._instances[cls]
放在下面这个位置。
这个模块实现了一个单例模式,往后所有的类,都可以将此类作为元类,以此实现单例模式。
全局配置类:config.py
对于全局配置,我们想要的是,它应该是全局单例模式的,因为配置文件是”死“的,在全局运行过程中,配置信息不会改变、
小编在这里选择了小编最喜欢的yaml配置文件,主要还是因为小编以前是最喜欢干Java,Spring的yaml配置文件我用的很顺手,所以我在这里也使用了yaml作为配置文件。
当然了,如果你喜欢,也可以使用xml、json等数据格式。
现在,我们要先安装适配于Python的Yaml文件解析器。
# 切换到你当前项目激活的conda虚拟环境
pip install PyYAML
因为我们刚才已经实现了一个单例设计模式,这次我们直接使用上面的单例模式作为元类,来实现config.py。
from frame.modes.SingletonMode import SingletonMode
import yaml
class AppConfig(metaclass=SingletonMode):
"""
全局配置类
在应用启动时,会扫描整个application.yaml配置文件
把配置项保存到config属性中
"""
def __init__(self):
self.config = None
self.is_load = False
self.load_config()
def load_config(self):
if self.is_load:
return
with open('./resources/application.yaml', 'r', encoding='utf-8') as f:
self.config = yaml.load(f.read(), Loader=yaml.FullLoader)
self.is_load = True
def get_config():
"""
返回全局配置
"""
return AppConfig().config
我们在这里,提供了全局方法,用于调用去获取配置类。
接着,我们在resources目录之下,创建一个application.yaml配置文件。但是实际上,你应该会有三个配置文件,分别是application.yaml(用于开发环境),application_test.yaml(用于测试环境),application_pro.yaml(用于生产环境)。
但是我们现在也只是开发,所以就先做一个配置文件,当然,如果你有需求,你也可以做三个配置文件。
下面是目前项目的结构。
通用返回类:Resp.py
我们一般在Web开发当中,我们会遵循某种形式的数据返回格式,并且我们需要保证,在每一次数据返回时,数据格式都保持一致,不管是报错,还是出现任何其它情况,这也是为了方便我们调试和调用端每次请求都能获得相同的数据格式,以来辨别服务端是否出现某种错误信息。
from pydantic import BaseModel
"""
项目通用返回类,此项目所有返回均使用此类返回
"""
class RespBody(BaseModel):
code: str = ""
msg: str = ""
data: dict = {}
def success(code: str = "200", msg: str = "success", data: dict = {}):
return RespBody(code=code, msg=msg, data=data)
def error(code: str = "500", msg: str = "error", data: dict = {}):
return RespBody(code=code, msg=msg, data=data)
这是一个简单的通用返回类,以让我们每次返回都可以返回相同的数据格式!
下面是当前项目的文件规划。
Yaml配置文件
现在,我们就可以把我们需要的配置信息,放在配置文件中了,目前为止,小编的配置文件是这样写的。
# 日志配置
logger:
# 打印的日志等级(info,debug,warning,error)
level: info
# 日志保存路径
save_path: "./resources/logs/"
# 模型配置
model:
model_type: "qwen2.5"
model_path: "你的模型地址"
我们把logs文件夹创建起来,接下来我们就准备制作日志工具类了。
全局日志工具类:logger_utils.py
对于我们日常开发来说,日志绝对是一个我们经常使用到的东西,不论消息打印,还是错误输出,或者是在服务器上部署的时候,当有问题查看日志,绝对是一个我们非常需要的工具。
所以,日志的重要性自不必多言。
import logging
from config import get_config
import os
from datetime import datetime
from frame.modes.SingletonMode import SingletonMode
"""
全局日志工具类(单例)
所有日志统一使用此类打印
"""
class LoggerUtils(metaclass=SingletonMode):
def __init__(self):
"""
当实例化时,初始化日志配置
设置日志记录等级和保存路径
并且添加两个日志打印器,一个打印在控制台,一个打印到文件
"""
self.logger = logging.getLogger()
self.save_path = get_config()["logger"]["save_path"]
self.set_level()
self.set_save_path()
def set_level(self):
"""
设置日志记录等级
"""
level = get_config()["logger"]["level"]
if level == "debug":
self.logger.setLevel(logging.DEBUG)
elif level == "info":
self.logger.setLevel(logging.INFO)
elif level == "warning":
self.logger.setLevel(logging.WARNING)
elif level == "error":
self.logger.setLevel(logging.ERROR)
def set_save_path(self):
"""
设置当前日志打印目录
如果目录不存在,则创建它,并且删除当前的日志打印器,重新添加一个
"""
self.save_path = os.path.join(get_config()["logger"]["save_path"], datetime.now().strftime("%Y-%m"))
# 查看当前目录是否存在
if not os.path.exists(self.save_path):
# 如果不存在,则创建它
os.makedirs(self.save_path)
# 并且遍历当前处理器
for handler in self.logger.handlers:
# 如果存在文件打印器,则移除它,添加一个文件打印器
if isinstance(handler, logging.FileHandler):
self.logger.removeHandler(handler)
self.logger.addHandler(logging.FileHandler(os.path.join(self.save_path, "log.txt"), encoding="utf-8"))
# 应对突发情况,校验是否有控制台打印器,如果没有,则添加一个
if not isinstance(handler, logging.StreamHandler):
self.logger.addHandler(logging.StreamHandler())
return
# 查看当前处理器是否是空数组
if len(self.logger.handlers) == 0:
# 如果是空数组,则添加一个文件打印器和一个控制台打印器
self.logger.addHandler(logging.FileHandler(os.path.join(self.save_path, "log.txt"), encoding="utf-8"))
self.logger.addHandler(logging.StreamHandler())
def info(self, msg):
self.set_save_path()
self.logger.info(datetime.now().strftime("INFO: " + "%Y-%m-%d %H:%M:%S") + ": " + msg)
def error(self, msg):
self.set_save_path()
self.logger.error(datetime.now().strftime("ERROR: " + "%Y-%m-%d %H:%M:%S") + ": " + msg)
def debug(self, msg):
self.set_save_path()
self.logger.debug(datetime.now().strftime("DEBUG: " + "%Y-%m-%d %H:%M:%S") + ": " + msg)
def warning(self, msg):
self.set_save_path()
self.logger.warning(datetime.now().strftime("WARNING: " + "%Y-%m-%d %H:%M:%S") + ": " + msg)
def get_logger():
return LoggerUtils()
此日志打印类属于单例模式,元类是我们刚开始写的单例模式。
除此之外,此python文件还向外提供一个方法,用于获取日志工具类。
全局LLM工具类:model_utils.py
因为我们需要在FastAPI启动时,加载模型,并且保证模型实例在整个FastAPI程序运行过程之间,只会初始化一次,那么我们也需要使用单例模式。
from transformers import AutoModelForCausalLM, AutoTokenizer
from config import get_config
from frame.modes.SingletonMode import SingletonMode
config = get_config()
class ModelUtils(metaclass=SingletonMode):
"""
用于加载模型
此类继承自单例模式,确保模型在每一个进程中,只加载一次
"""
def __init__(self):
self.model = None
self.tokenizer = None
self.get_model()
def get_model(self):
"""
获得当前模型
"""
if self.model is None:
# 加载模型
self.model = AutoModelForCausalLM.from_pretrained(config["model"]["model_path"], trust_remote_code=True, device_map="cuda").eval()
# 加载分词器
self.tokenizer = AutoTokenizer.from_pretrained(config["model"]["model_path"], trust_remote_code=True)
return self.model, self.tokenizer
def get_model():
"""
获得当前的模型和分词器
"""
return ModelUtils().get_model()
实际上,这里只是一个简单的,普通的实现,以让大家熟悉一下单例模式的应用,但是在下一个章节中,我们将会对模型进行抽象,使用模板方法模式来实现多态,以让我们可以简单的在生产环境和开发环境切换不同的模型。
多POJO
现在,让我们为了接下来的多路由配置做准备,也就是做实体类。
POJO,对于做Java的人来说,这并不是一个很陌生的词汇,它的特点就是通常只包含一些属性和对应的getter/setter方法,通常用来存储和访问对象。
但是在FastAPI里面,POJO也是一样,不过它换了另外一种叫法,那就是model,也是为了存储和访问对象,这是Pydantic带来的魔法,也是FastAPI极高性能的原因。
Pydantic通常用于数据验证和解析。它提供了一种简单且直观的方式来定义数据模型,并使用这些模型对数据进行验证和转换。
我们在上一篇文章中,就是用了Pydantic来定义的数据模型,这次,我们需要把这些东西拆除出来,单独放在app.models目录之中。
from typing import List
from pydantic import BaseModel
from app.models.chat_message import ChatMessage
class ChatRequest(BaseModel):
"""
接收前端传来的消息请求
question:需要询问的消息
history:历史消息,如果没有历史消息,则返回空列表,表示是新一轮的会话
"""
question: str = ""
history: List[ChatMessage] = []
from typing import Literal
from pydantic import BaseModel
class ChatMessage(BaseModel):
"""
此类是一个聊天消息类,主要用于描述一个聊天消息,包括消息的角色、内容、名称。
role:此参数仅仅只接收四种值(字符串),分别是"user"、"assistant"、"system",用于限制传入角色类型,以免错误地传入其他角色信息。
content:此参数接收一个字符串类型,用于描述对应角色的内容
"""
role: Literal["user", "assistant", "system"]
content: str = ""

多路由配置:stream_router.py
在很多时候,我们将功能(RestFul接口)都写在一个文件当中,我们认为是臃肿的,并且是相当难以维护的!
所以,对于一个成熟的框架来讲,做多路由配置,和分文件编写,这应该是标配,FastAPI也提供了这样的服务,那就是APIRouter()。
此类主要用于组织和分组路由,从而使代码结构更加清晰和可维护。
现在,让我们使用这个类,将流式传输接口抽出来。
from threading import Thread
from fastapi import APIRouter
from starlette.responses import StreamingResponse
from transformers import TextIteratorStreamer
from app.models.chat_request import ChatRequest
from frame.https import Resp
from frame.utils.model_utils import get_model
"""
此路由只适配stream流式传输
"""
model, tokenizer = get_model()
api = APIRouter()
@api.post("/chat/stream")
async def chat_stream(request: ChatRequest):
"""
通用流式传输接口
"""
# 组装历史消息
history = []
for message in request.history:
history.append({"role": message.role, "content": message.content})
history.append({"role": "user", "content": request.question})
# 构造模型输入
model_inputs = tokenizer.apply_chat_template(history,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt").to("cuda")
# 添加文本stream流
streamer = TextIteratorStreamer(
tokenizer=tokenizer,
timeout=60,
skip_prompt=True,
skip_special_tokens=True
)
# 设置参数
generate_kwargs = {
"input_ids": model_inputs,
"streamer": streamer,
"max_length": 204800
}
# 设置参数
generate_kwargs = {
"input_ids": model_inputs,
"streamer": streamer,
"max_length": 204800
}
# 启动线程
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
# 设置迭代器
def gen():
for new_token in streamer:
if new_token:
yield "{}\n".format(Resp.success(data={"answer": new_token}).json())
yield "{}\n".format(Resp.success(data={"answer": "[Done]"}).json())
# 返回流式输出
return StreamingResponse(gen(), media_type="text/event-stream")
接着,我们来修改我们的启动类,也就是main.py。
main.py
将main.py改一下,变成下面这样样子,这样就会变得更加简洁了,main.py只负责调用其它的get方法和启动程序,剩下的,就交给其它各自类去实现。
from fastapi import FastAPI
from app.router import stream_router
from config import get_config
from frame.utils.logger_utils import get_logger
from frame.utils.model_utils import get_model
# 在FastAPI启动之前,初始化配置
config = get_config()
logger = get_logger()
model, tokenizer = get_model()
# 初始化FastAPI
app = FastAPI()
# 挂载路由
app.include_router(stream_router.api)
# 程序主入口
if __name__ == "__main__":
# 导入unicorn服务器的包
import uvicorn
# 运行服务器
# 监听地址:0.0.0.0,端口:6732,单进程,日志输出级别是error
uvicorn.run(app, host="0.0.0.0", port=6732, workers=1, log_level="error")
这样一看,就简洁的多了!
测试
因为我们使用了通用返回类,所以我们的测试函数也需要修改。
import requests
import json
import time
# api请求地址
url = "http://127.0.0.1:6732/chat/stream"
# 设置头部信息
headers = {
'Content-Type': 'application/json',
}
# 设置历史记录和整段对话
history = []
message = ""
# 循环提问
while True:
# 用户输入
user_input = input("Human (or 'exit' to quit): ")
if user_input.lower() == "exit":
break
# 设置请求信息
payload = json.dumps({
"question": user_input,
"history": history
})
message = ""
start_time = time.time()
# 发送stream请求
response = requests.request("POST", url, headers=headers, data=payload, stream=True)
# 逐行读取响应
for line in response.iter_lines():
if line:
line_object = json.loads(line.decode('utf-8'))
# 取出data中的数据
line_object_data = line_object['data']
if line_object_data['answer'] == '[Done]':
break
print(line_object_data['answer'], end='', flush=True)
message += line_object_data['answer']
end_time = time.time()
elapsed_time = end_time - start_time
# 添加历史记录
history.append({"role":"user", "content": user_input})
history.append({"role":"assistant", "content": message})
print(f"\nTotal time taken: {elapsed_time:.2f} seconds")
本来是直接输出的,现在我们需要将数据使用json反编码一下,然后取出data中的数据,在进行输出。
FastAPI当中的中间件
实际上,我们在完成上述的任务之后,一个基础的大模型框架就已经搭建完毕了,甚至你如果你不在意,都可以直接上生产…
但是为了整个系统的健壮性,我们还需要加入其它组件,比如全局异常捕获、日志打印和接口拦截等前置设置。
所以,这个时候我们就需要使用中间件了。
按照小编的理解,中间件就相当于是拦截器,在请求来的时候,先经过一遍拦截器,然后再把请求接入到路由之中。
但是,又和拦截器不尽相同,按照FastAPI官方文档的解释如下。
- 它接收你的应用程序的每一个请求.
- 然后它可以对这个请求做一些事情或者执行任何需要的代码.
- 然后它将请求传递给应用程序的其他部分 (通过某种路径操作).
- 然后它获取应用程序生产的响应 (通过某种路径操作).
- 它可以对该响应做些什么或者执行任何需要的代码.
- 然后它返回这个响应.
那就让我们来实战做一下这个中间件吧!
全局异常捕获中间件
所有的中间件,都需要继承自**BaseHTTPMiddleware**这个类。
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.requests import Request
from starlette.responses import Response, JSONResponse
from frame.utils.logger_utils import get_logger
logger = get_logger()
class ErrorMiddleware(BaseHTTPMiddleware):
"""
中间件,此中间被插入到Starlette的请求处理管道中
此中间将将位于全部链的最后一跳,所有的请求,在返回时,全部response都第一个通过此中间件拦截,如果有错误,则全部在这里进行处理,并且提供统一返回接口
"""
def __init__(self, app, header_namespace: str):
super().__init__(app)
# 自定义参数,用于定义middleware的header名称空间
self.header_namespace = header_namespace
async def dispatch(self, request: Request, call_next) -> Response:
"""放行当前请求,然后在返回时提供错误的统一返回消息"""
try:
response = await call_next(request)
if response.status_code != 200:
response_body = [chunk async for chunk in response.body_iterator]
response_body = response_body[0].decode("utf-8")
logger.error(f"Error code: {response.status_code}, Error message: {response_body}")
response = JSONResponse(
content={"code": str(response.status_code), "msg": str(response_body)},
status_code=response.status_code)
except Exception as e:
logger.error(str(e))
response = JSONResponse(content={"code": str(500), "msg": str(e)}, status_code=500)
return response
我们从上述代码之中,可以看到异常捕获的逻辑,在请求到来时,不对它做任何处理。
只有response不为成功时,或者直接抛出异常的话,才会被捕获,这样我们的全局异常捕获中间件就完成了。
拦截IP中间件
我们在开发的时候,我们首先想到的是,我们的应用只会对特定IP开放,而不想要其它IP去访问我们的业务,这个时候,我们就需要拦截中间件,来帮我们实现这个功能了。
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.requests import Request
from starlette.responses import Response, JSONResponse
from config import get_config
from frame.utils.logger_utils import get_logger
logger = get_logger()
config = get_config()
class InterceptMiddleware(BaseHTTPMiddleware):
"""
中间件,此中间被插入到Starlette的请求处理管道中
此中间将将位于全部链的第一位,所有的请求,到这里将会被拦截,除了特定ip地址,其他的全部拦截
"""
def __init__(self, app, header_namespace: str):
super().__init__(app)
# 自定义参数,用于定义middleware的header名称空间
self.header_namespace = header_namespace
async def dispatch(self, request: Request, call_next) -> Response:
"""拦截当前请求,看ip是否在允许的ip列表中,如果在,则放行,如果不在,则返回错误信息"""
# 获取当前请求的ip
current_ip = request.client.host
# 如果0.0.0.0不在允许的ip列表中,则判断当前ip是否在允许的ip列表中,否则则全部放行
if "0.0.0.0" not in config["intercept"]["ip_allow_list"]:
# 如果当前ip不在允许的ip列表中,则返回错误信息
if current_ip not in config["intercept"]["ip_allow_list"]:
logger.error(f"ip:{current_ip} is not allowed")
# 返回错误信息
return JSONResponse(content={"code": "403", "msg": "Ip is not allowed"}, status_code=403)
# 否则则放行
response = await call_next(request)
return response
可以看到,我们的业务逻辑是,只要是白名单里,有0.0.0.0这个ip地址,则对所有的ip放行,这是因为我们在开发的时候,有可能会接触到一些多机协调的任务,所以我们才专门添加一个这个配置。
然后,我们相应的,Yaml文件也要跟着改。
# 日志配置
logger:
# 打印的日志等级(info,debug,warning,error)
level: info
# 日志保存路径
save_path: "./resources/logs/"
# 模型配置
model:
model_type: "qwen2.5"
model_path: "你的模型地址"
# http拦截器配置
intercept:
ip_allow_list:
# 允许访问的ip地址
- 0.0.0.0

日志中间件
日志中间件自然不用多说,直接看代码。
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.requests import Request
from starlette.responses import Response
from frame.utils.logger_utils import get_logger
logger = get_logger()
class LogMiddleware(BaseHTTPMiddleware):
"""
中间件,此中间被插入到Starlette的请求处理管道中
此中间将将位于全部链的倒数第二位,所有的请求都会在请求走之后,在这里打印。
"""
def __init__(self, app, header_namespace: str):
super().__init__(app)
# 自定义参数,用于定义middleware的header名称空间
self.header_namespace = header_namespace
async def dispatch(self, request: Request, call_next) -> Response:
"""当请求响应时,打印日志"""
response = await call_next(request)
logger.info(f"{request.client.host}:{request.client.port} - '{request.method} {request.url.path}' {response.status_code}")
return response
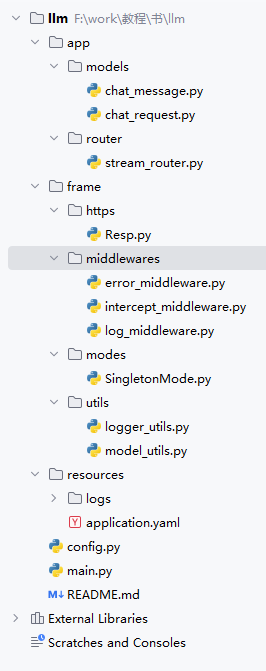
在main.py中挂载中间件
在FastAPI中,你写完中间件还不能用,必须要在FastAPI上挂载中间件。
from fastapi import FastAPI
from app.router import stream_router
from config import get_config
from frame.middlewares.error_middleware import ErrorMiddleware
from frame.middlewares.intercept_middleware import InterceptMiddleware
from frame.middlewares.log_middleware import LogMiddleware
from frame.utils.logger_utils import get_logger
from frame.utils.model_utils import get_model
# 在FastAPI启动之前,初始化配置
config = get_config()
logger = get_logger()
model, tokenizer = get_model()
# 初始化FastAPI
app = FastAPI()
# 挂载路由
app.include_router(stream_router.api)
# 挂载中间件
app.add_middleware(ErrorMiddleware, header_namespace="X-error")
app.add_middleware(LogMiddleware, header_namespace="X-log")
app.add_middleware(InterceptMiddleware, header_namespace="X-intercept")
# 程序主入口
if __name__ == "__main__":
# 导入unicorn服务器的包
import uvicorn
# 运行服务器
# 监听地址:0.0.0.0,端口:6732,单进程,日志输出级别是error
uvicorn.run(app, host="0.0.0.0", port=6732, workers=1, log_level="error")
FastAPI的中间件,遵行先进后执行的原则,所以大家要注意一点。
总结
在本节课中,我们学习到了项目中的文件规划,并且手写了一个Python当中的单例模式。并且学习了如何使用FastAPI组织一个大型项目架构。
除此之外,我们还封装了一堆工具和中间件,我希望让大家通过看这一篇文章,就可以触类旁通,明白FastAPI各种组件的搭配和使用(不光是这个项目,这一套架构相当通用)。
好了,下一篇文章,我会将咱们的目光,再次转向大模型,因为现在大模型的调用,还是哒咩哒灭!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









