






CART模型,即
Classification And
Regression Trees。C是适合symbolic,R适合numeric。它和一般回归分析类似,是用来对变量进行解释和预测的工具,也是数据挖掘中的一种常用算法。如果因变量是连续数据,相对应的分析称为
回归树,如果因变量是分类数据,则相应的分析称为
分类树。
决策树是一种倒立的树结构,它由内部节点、叶子节点和边组成。其中最上面的一个节点叫根节点。 构造一棵决策树需要一个训练集,一些例子组成,每个例子用一些属性(或特征)和一个类别标记来描述。构造决策树的目的是找出属性和类别间的关系,一旦这种关系找出,就能用它来预测将来未知类别的记录的类别。这种具有预测功能的系统叫决策树分类器。
如果一个人必须去选择在很大范围的情形下性能都好的、同时不需要应用开发者付出很多的努力并且易于被终端用户理解的分类技术的话,那么分类树方法是一个强有力的分类。
分类树
在分类树下面有两个关键的思想。第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
递归划分
让我们用变量y表示因变量(分类变量output),用x1, x2, x3,...,xp表示自变量input。通过递归的方式把关于变量x的p维空间划分为disjoint不重叠的矩形。
首先,一个自变量被选择,比如xi和xi的一个值si,比方说选择si把p维空间为两部分(这里原文其实举了regression tree的例子):一部分是p维的超矩形,其中包含的点都满足xi<=si(numeric input),另一个p维超矩形包含所有的点满足xi>si。接着,这两部分中的一个部分通过选择一个变量和该变量的划分值以相似的方式被划分。这导致了三个矩形区域(从这里往后我们把超矩形都说成矩形)。
随着这个过程的持续,我们得到的矩形越来越小。这个想法是把整个x空间划分为矩形,其中的每个小矩形都尽可能是同构的或“纯”的(熵也在这过程趋于0)。“纯”的意思是(矩形)所包含的点都属于同一类。
这是一个很简单的CART的范例,大概是上节课DM的内容以及这次作业
分类-回归树模型(CART)在R语言中的实现
其算法的优点在于:1)可以生成可以理解的规则。2)计算量相对来说不是很大。3)可以处理多种数据类型。4)决策树可以清晰的显示哪些变量较重要。
下面以一个例子来讲解如何在R语言中建立树模型。为了预测身体的肥胖程度,可以从身体的其它指标得到线索,例如:腰围、臀围、肘宽、膝宽、年龄。
下面以一个例子来讲解如何在R语言中建立树模型。为了预测身体的肥胖程度,可以从身体的其它指标得到线索,例如:腰围、臀围、肘宽、膝宽、年龄。
#首先载入所需软件包
library(mboost)
library(rpart)
library(maptree)
#读入样本数据
data('bodyfat')
#建立公式
formular=DEXfat~age+waistcirc+hipcirc+elbowbreadth+kneebreadth
#用rpart命令构建树模型,结果存在fit变量中
fit=rpart(formular,method='anova',data=bodyfat)
#直接调用fit可以看到结果
n= 71
node), split, n, deviance, yval
* denotes terminal node
1) root 71 8535.98400 30.78282
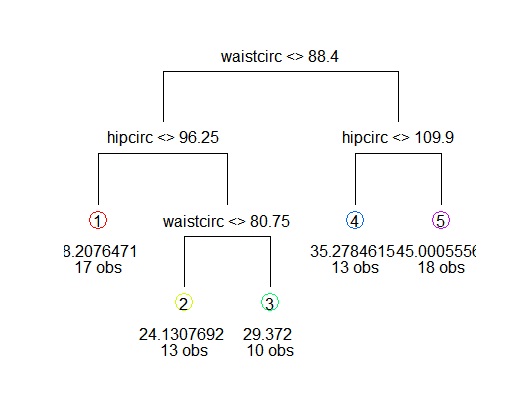
2) waistcirc< 88.4 40 1315.35800 22.92375
4) hipcirc< 96.25 17 285.91370 18.20765 *
5) hipcirc>=96.25 23 371.86530 26.40957
10) waistcirc< 80.75 13 117.60710 24.13077 *
11) waistcirc>=80.75 10 98.99016 29.37200 *
3) waistcirc>=88.4 31 1562.16200 40.92355
6) hipcirc< 109.9 13 136.29600 35.27846 *
7) hipcirc>=109.9 18 712.39870 45.00056 *
#也可以用画图方式将结果表达得更清楚一些
draw.tree(fit)
#首先观察模型的误差等数据
printcp(fit)
Regression tree:
rpart(formula = formula, data = bodyfat)
Variables actually used in tree construction:
[1] hipcirc waistcirc
Root node error: 8536/71 = 120.23
n= 71
CP nsplit rel error xerror xstd
1 0.662895 0 1.00000 1.01364 0.164726
2 0.083583 1 0.33710 0.41348 0.094585
3 0.077036 2 0.25352 0.42767 0.084572
4 0.018190 3 0.17649 0.31964 0.062635
5 0.010000 4 0.15830 0.28924 0.062949
#调用CP(complexity parameter)与xerror的相关图,一种方法是寻找最小xerror点所对应的CP值,并由此CP值决定树的大小,另一种方法是利用1SE方法,寻找xerror+SE的最小点对应的CP值。
plotcp(fit)

#用prune命令对树模型进行修剪(本例的树模型不复杂,并不需要修剪)
pfit=prune(fit,cp= fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"])
#模型初步解释:腰围和臀围较大的人,肥胖程度较高,而其中腰围是最主要的因素。
#利用模型预测某个人的肥胖程度
ndata=data.frame(waistcirc=99,hipcirc=110,elbowbreadth=6,kneebreadth=8,age=60)
predict(fit,newdata=ndata)
*本文主要参考了Yanchang Zhao的文章:“R and Data Mining: Examples and Case Studies”
翻译部分 原文http://plantecology.syr.edu/fridley/bio793/cart.html
什么时候该使用CART而不是一般线性规划GLM或者一般加性模型GAM?当预测变量们彼此之间有依赖关系的时候,CART模型的递归结构能更好的揭示这些依赖关系。例如说,土壤含水量的影响在很大程度上以非线性的方式依赖于土壤质地,物种出现的CART模型比在GLMS甚至是GAMS有更大可能发现。当你有很好的理由怀疑非加变量之间的相互作用,或有很多变量,不知道什么有没有依赖,那么试试树模型。
如果你只是有几个变量,并普遍预期简单的直线或曲线相关,相对简单的(或没有)的相互作用,树模型将只返回使用太多参数近似的实际关系(颠簸,而不是光滑) 。树模型也有overfit的倾向,从而导致过度诠释。最后,因为他们不涉及一个光滑函数拟合数据,树模型输出对于输入变量的微小变化可能过于敏感。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









