





Information Theory
IT provides a powerful framework for dealing withsymbolic data.(和numeric相对)
y : symbolic attribute of arity Ay
• Information content 信息含量of one of Ay values of y, yi:
I(yi) = -log2 p(yi) 负的yi概率的对数,
• It is expressed in bits
• 可以理解成“惊讶程度”。 Ay的概率越大,信息含量越小,越不值得一提
举例:
• 属性“颜色”有红绿蓝三种可能
• 一共1000条记录: 红350 绿450 蓝200
I(y=blue) = -log2(0.2)= -log(0.2)/log(2) = 2.322 bits
I(y=red) = -log2(0.35) = -log(0.35)/log(2) = 1.515 bits
I(y=green) = -log2(0.45) = -log(0.45)/log(2) = 1.152 bits
如果yi的概率是1,那么信息含量为零,因为,不要取样也知道,没什么新信息,没什么可以surprise的
信息含量不能小于零
熵:
如果有一枚理想的硬币,其出现正面和反面的机会相等,则抛硬币事件的熵等于其能够达到的最大值。我们无法知道下一个硬币抛掷的结果是什么,因此每一次抛硬币都是不可预测的。
另一个稍微复杂的例子是假设一个随机变量X,取三种可能值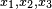 ,概率分别为
,概率分别为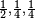 ,那么编码平均比特长度是:
,那么编码平均比特长度是: 。其熵为3/2。
。其熵为3/2。
因此熵实际是对随机变量的比特量和顺次发生概率相乘再总和的数学期望。
高确定性,低信息含量,低熵
Information Gain
如何测量,使用symbolic attribute x 来预测另一个symbolic attribute y时,x的作用大小?
IG(y,x) = H(y) - H(y|x)y本身的熵 - 在x情况下y的熵

如果已经完全知道第二个随机变量  的前提下,随机变量
的前提下,随机变量  的信息熵还有多少。也就是 基于 的 的信息熵,用
的信息熵还有多少。也就是 基于 的 的信息熵,用  表示。
表示。
对称: IG(x,y)=H(x)-H(x|y)=H(y)-H(y|x)=IG(y,x)
如果是完全相关, H(y|x)=H(x|y)=0, IG(y,x)=H(y), IG(x,y)=H(x)
如果完全不相干, H(y|x)=H(y), H(x|y)=H(x), IG(y,x)=IG(x,y)=0 知道了x完全没有帮助
Decision Trees learning
1. 使用最大IG的predictor(一个input列)做决策树的root节点; 不一定是IG(还有GINI index)但是这里拿IG做例子
2. 根据该input列划分数据
3. 对于每个子集进行(1)的递归
如果input列是numeric的,就找"最好"的二元分割点。该点不需要是mean或者median什么的,标准应该是Most informative splitting dimension:
子集们X’={XA,XB} to 来预测Y,最大程度的降低Y的uncertainty,此处用IG来表示















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









