







准备
Python环境
首先,是Python环境。
有两种选择,一种是去Python官网下载,网址是:https://www.python.org/downloads/;另外一种方法是到Anaconda官网下载,网址是:https://www.continuum.io/downloads。
Anaconda官网下载页面截图:
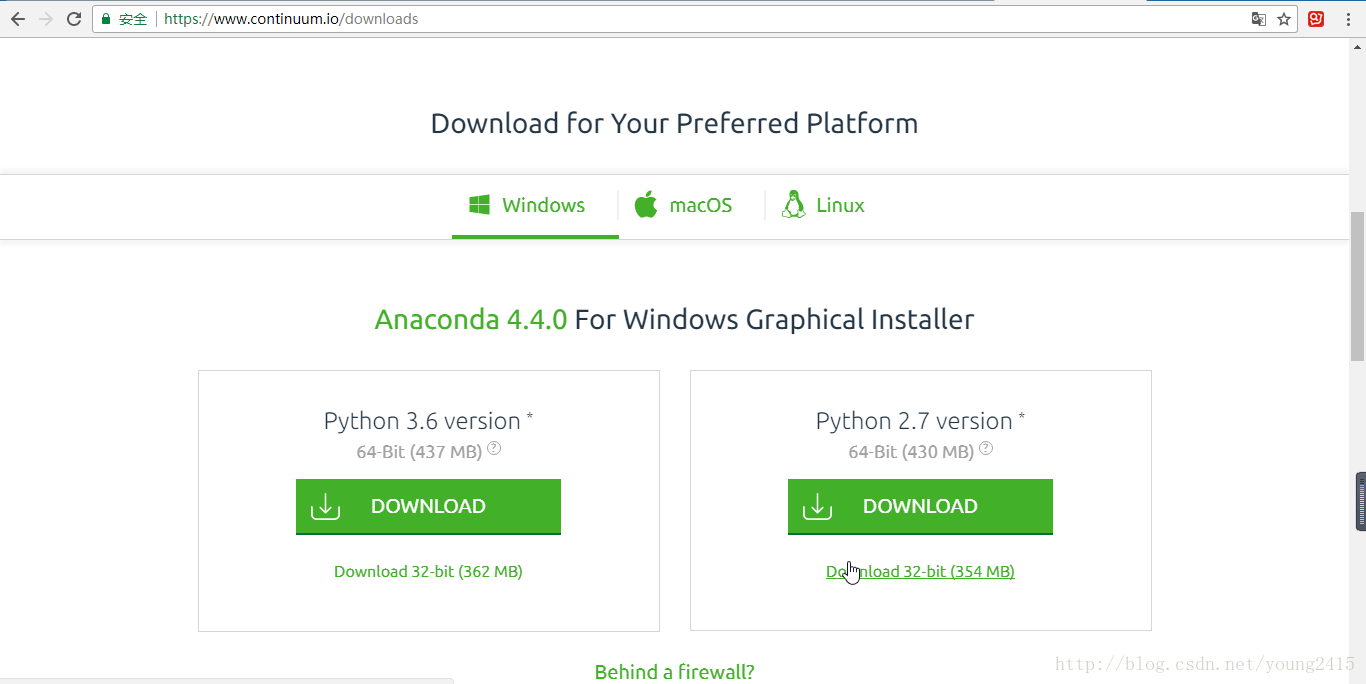
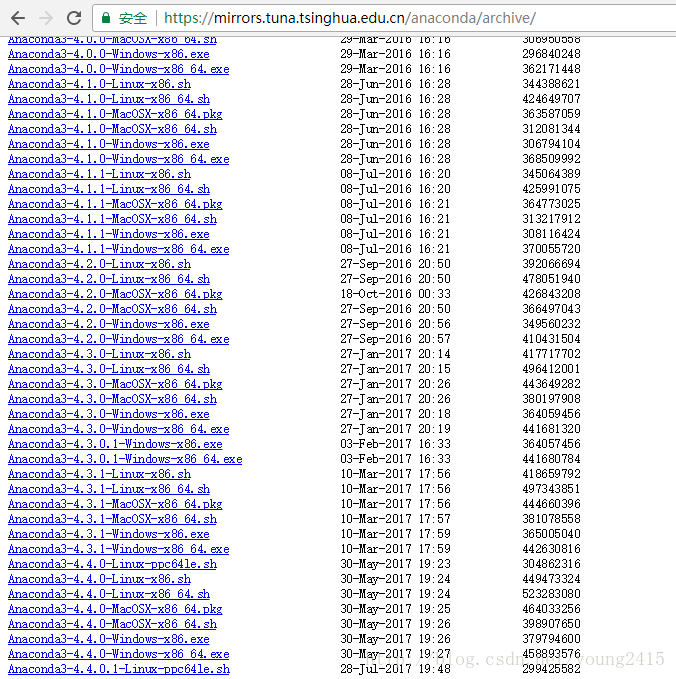
访问Anaconda官网需要翻墙,而且下载速度堪称龟速,但幸运的是,清华大学开源镜像站上面有Anaconda的安装镜像,大家可以去那里下载,下载速度也比较快,网址是:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
博主强烈推荐大家安装Anaconda,因为接下来我们还需要安装几个工具包,对Windows用户来说,使用Python原生环境安装是非常困难的,而使用Anaconda则容易的多,而且Anaconda里面也内嵌了Python编程环境。
由于博主安装的是Anaconda,所以下面以Anaconda为例继续讲解。
安装Anaconda也很容易,下载Anaconda镜像后,双击运行即可开始安装。
requests、BeautifulSoup4、jupyter工具包
安装好Anaconda后,打开命令行,进入Anaconda安装目录下的Scripts目录,如图:
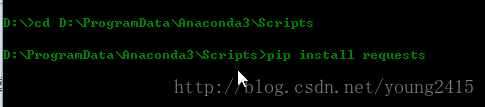
输入“pip install requests”,回车,安装requests;
输入“pip install BeautifulSoup4”,回车,安装BeautifulSoup4;
输入“pip install jupyter”,回车,安装jupyter;
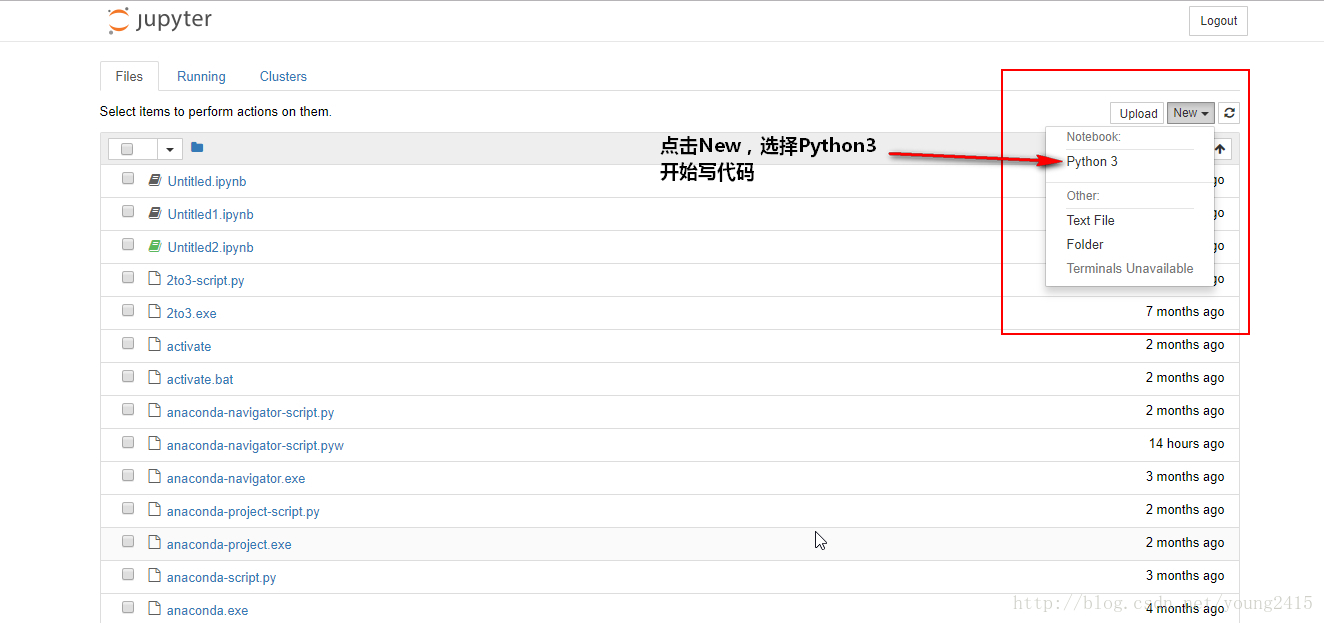
安装好后,输入“jupyter notebook”打开jupyter
如图:
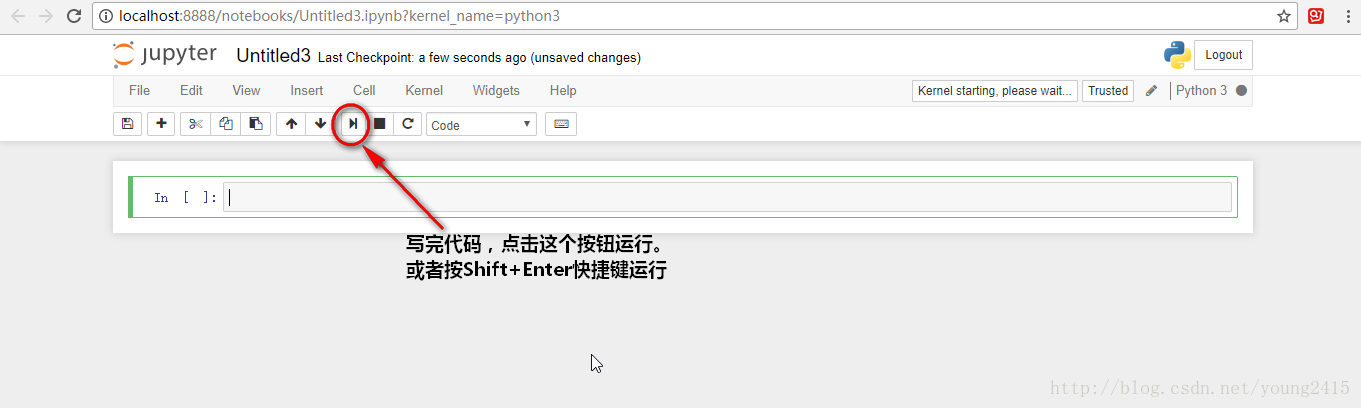
编写
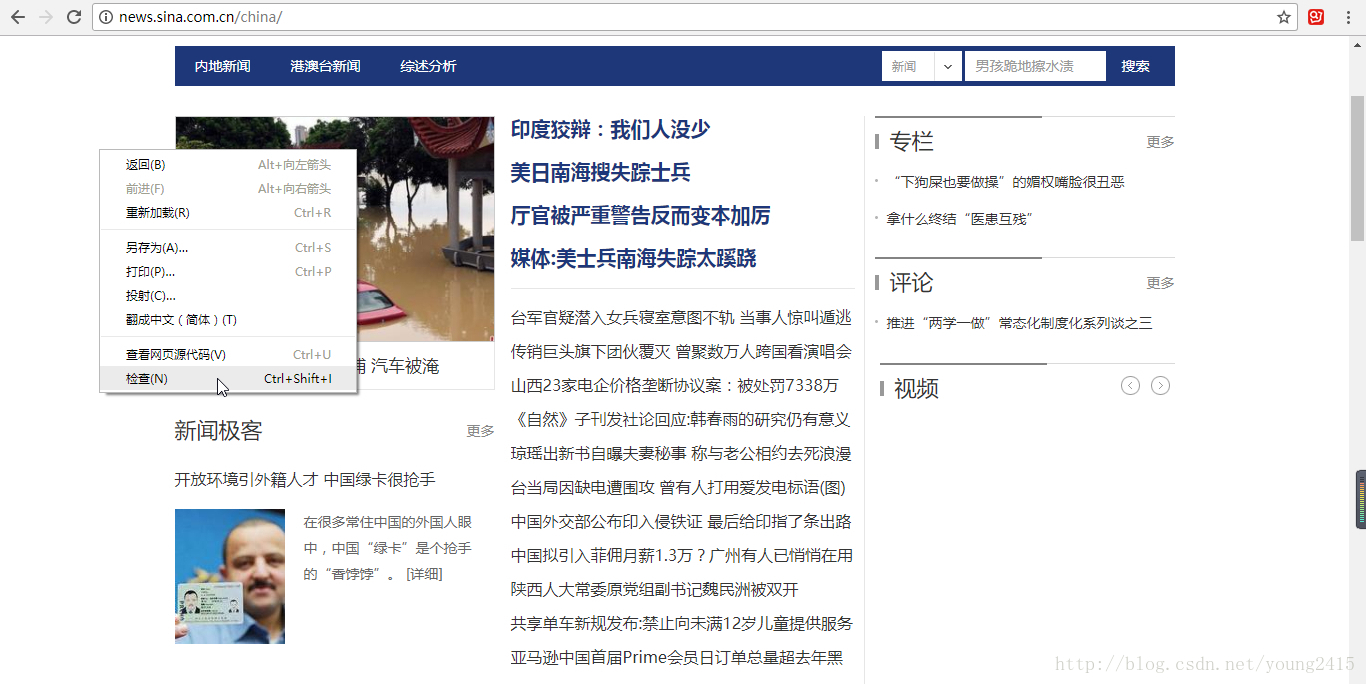
打开新浪网,点击鼠标右键—>点击检查,或者直接按F12打开开发者模式:
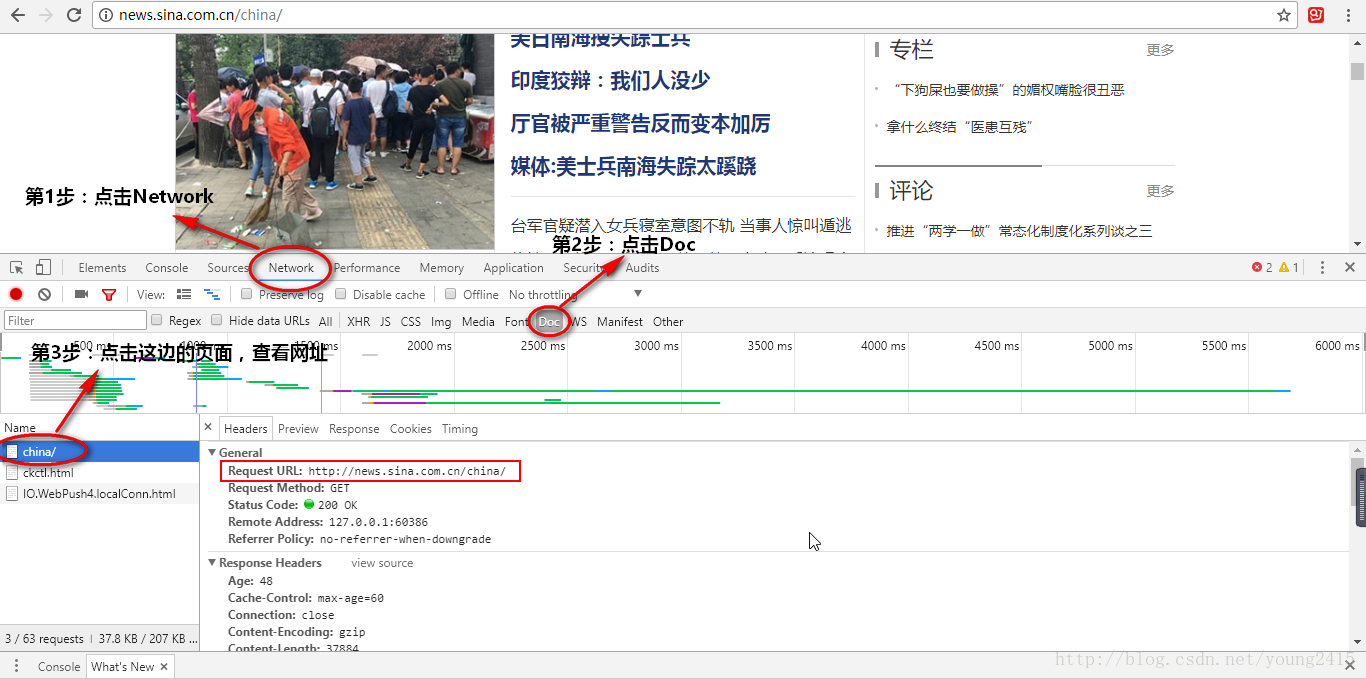
复制网址,来到jupyter编辑页面
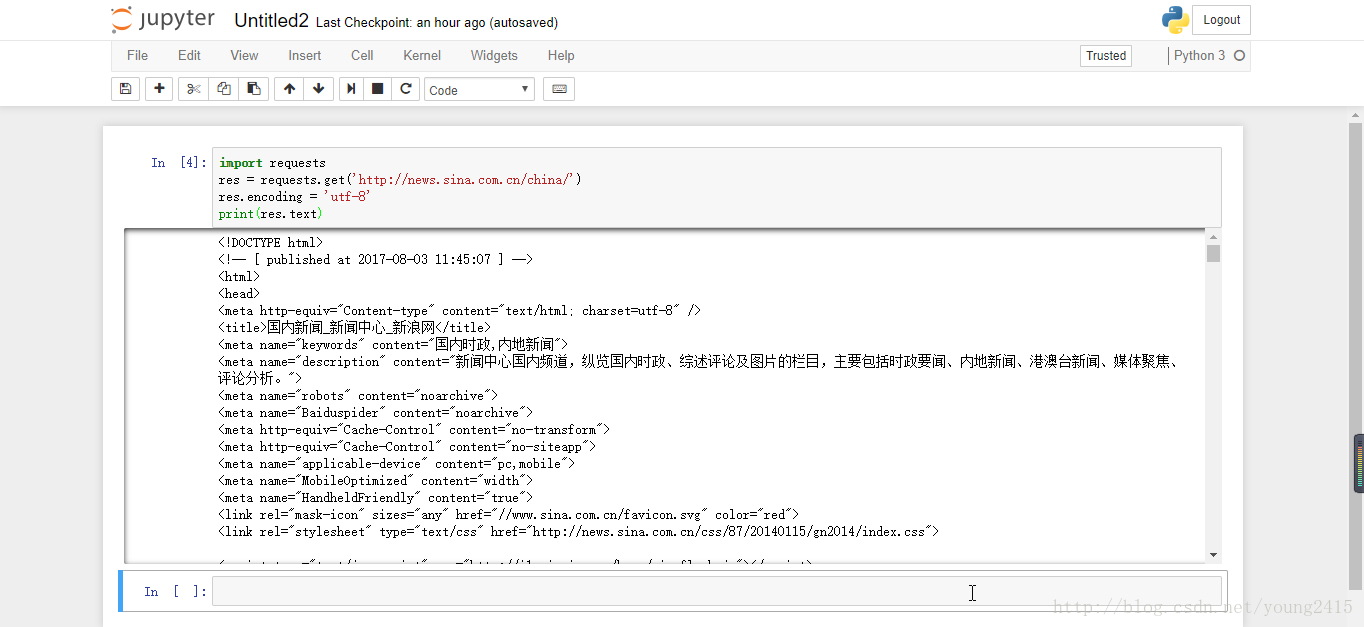
import requests #导入requests工具包
res = requests.get('http://news.sina.com.cn/china/')
res.encoding = 'utf-8' #指定编码类型
print(res.text) #打印网页源代码获取到网页源代码之后,我们面临的一个问题是如何把非结构化的数据转换成结构化的数据,还有如何把我们需要的数据提取出来。这时,BeautifulSoup4就会派上用场了,先来看一下范例 :
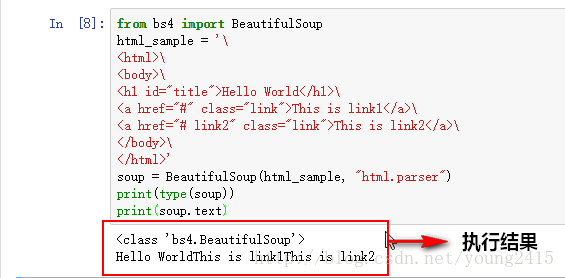
从上图可以看到,经过BeautifulSoup4的转换,网页源代码中的标签被去掉了,得到的是标签中的内容。
但是这样还远远不够,因为有时候我们所需的元素处在一些特殊的标签之中,我们想要获得一个或一组标签(包括内容和属性),这时需要用到的是select方法,看范例:
from bs4 import BeautifulSoup
html_sample = '\
<html>\
<body>\
<h1 id="title">Hello World</h1>\
<a href="#" class="link">This is link1</a>\
<a href="# link2" class="link">This is link2</a>\
</body>\
</html>'
soup = BeautifulSoup(html_sample, "html.parser")
header = soup.select('h1')#获取所有h1标签,返回的是列表
alinks = soup.select('a')#获取所有a标签
tag = soup.select('#title')#获取id为“title”的标签
tag1 = soup.select('.link')#获取class为“link”的标签
#迭代取出每个链接中的地址
for link in alinks:
print(link['href'])#每一个标签中的属性和属性值都被包装成了一个字典,所以我们可以通过key来索引value
print(link['class'])
print(tag1)
print(header)#打印的是整个列表
print(header[0])#打印列表中的第一个元素
print(header[0]['id'])#打印列表中的第一个元素的id
print(type(soup))
print(soup.text)运行结果:

如果存在标签嵌套的情况,可以用空格隔开表示层级关系。比如下面这段HTML代码,span标签里面嵌套着另一个span标签,里面的span标签又存在着嵌套,如果我想获取最里面的a标签,应该怎么办呢?看代码:
html_sample = '\
<span class="time-source" id="navtimeSource">\
2017年08月03日07:24\
<span>\
<span data-sudaclick="media_name">\
<a href="#" target="_blank" >环球网</a>\
</span>\
</span>\
</span>'
soup = BeautifulSoup(html_sample, "html.parser")
link = soup.select('.time-source span span a')
print(link)运行结果:
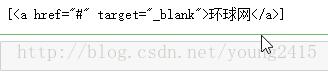
可以看到获得了a标签
完整的爬取新浪网新网资讯的爬虫代码请见:爬取新浪网的新闻资讯并保存 http://download.csdn.net/detail/young2415/9922644















 1923
1923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









