







什么是爬虫:通过编写程序,模拟浏览器行为,然后让其去互联网抓取数据的过程。
请求和响应
请求:
请求行:请求方式 请求url地址 请求协议
请求头:放一些服务器要使用的附加信息(user-Agent之类的)
请求体:请求参数(post请求)
响应:
响应行:协议 状态码
响应头:放一些客户端要使用的附加信息(cookie之类的)
响应体:服务器返回内容(json、Html)给客户端
一、爬取百度页面
# urllib包下的request模块
from urllib.request import urlopen
url = 'http://www.baidu.com'
resp = urlopen(url)
# print(resp) # <http.client.HTTPResponse object at 0x00000170B3AADA50>
# print(resp.read().decode("utf-8"))
with open(file="baidu.html", mode='w', encoding='utf-8') as fp:
fp.write(resp.read().decode('utf-8'))
# byte.decode() # 将字节码解码字符串
# str.encode() # 将字符串编码字节码
requests 模块
安装
可以直接在控制台输入 pip install requests
# pip install requests
下载速度过慢的话,可以通过镜像源安装
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
# 利用国内镜像源下载库
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
get 请求
import requests
keyword = input("请输入你想搜索的关键词:")
url = f"https://www.sogou.com/web?query={keyword}"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54 "
}
resp = requests.get(url, headers=header)
print(resp) # <Response [200]>
print(resp.status_code) # 200
print(resp.text)
with open(file=f"{keyword}.html", mode='w', encoding='utf-8') as fp:
fp.write(resp.text) # 页面源代码
resp.close() # 关闭resp
Post 请求
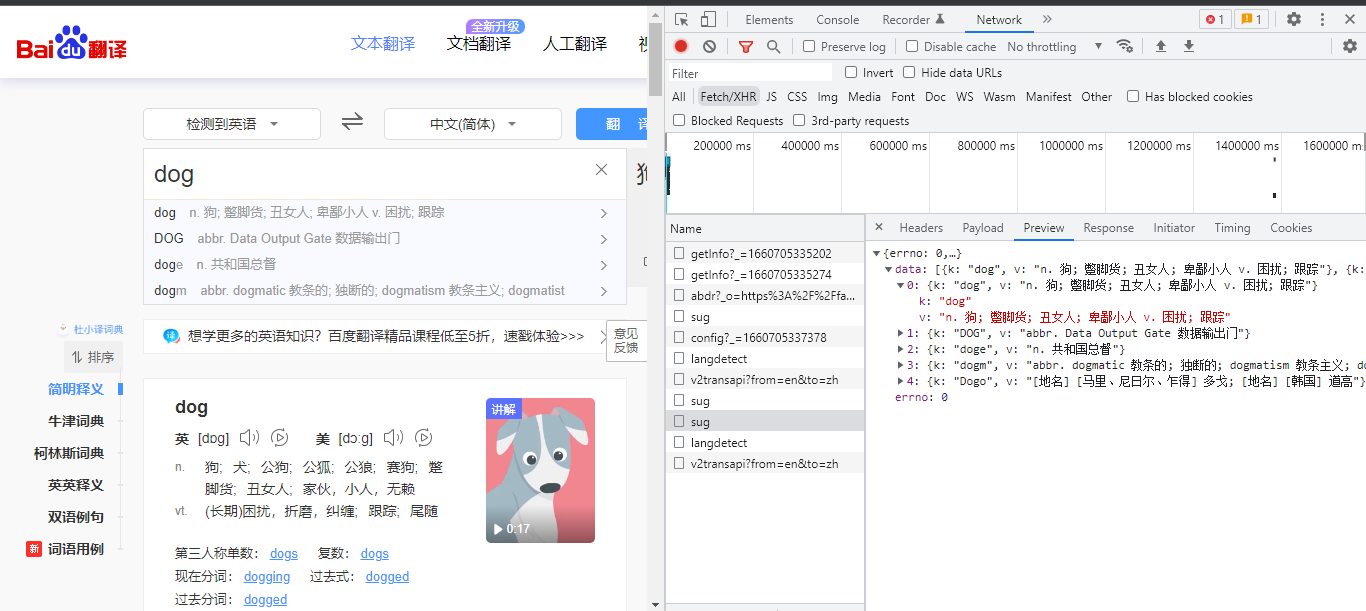
import requests
url = 'https://fanyi.baidu.com/sug'
# 请求体参数
data = {
'kw': 'dog'
}
resp = requests.post(url, data=data)
print(resp.json())
print(resp.json()['data'][0]['v'])
# {'errno': 0, 'data': [{'k': 'dog', 'v': 'n. 狗; 蹩脚货; 丑女人; 卑鄙小人 v. 困扰; 跟踪'}, {'k': 'DOG', 'v': 'abbr. Data Output Gate 数据输出门'}, {'k': 'doge', 'v': 'n. 共和国总督'}, {'k': 'dogm', 'v': 'abbr. dogmatic 教条的; 独断的; dogmatism 教条主义; dogmatist'}, {'k': 'Dogo', 'v': '[地名] [马里、尼日尔、乍得] 多戈; [地名] [韩国] 道高'}]}
# n. 狗; 蹩脚货; 丑女人; 卑鄙小人 v. 困扰; 跟踪
当 get 请求参数过长,可以用另一种方式封装参数。
import requests
url = 'https://movie.douban.com/j/chart/top_list?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 '
'Safari/537.36 '
}
# get 请求参数
params = {
'type': 24,
'interval_id': '100:90',
'action': '',
'start': 0,
'limit': 20
}
resp = requests.get(url, params, headers=headers)
print(resp.request.url)
print(resp.json())
数据解析
我们已经实现了从互联网上爬取网页数据,但是怎么从这诺大的网页中获取到真正想要的数据,这就需要用到正则表达式了。
正则表达式
正则表达式(Regular Expression),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
元字符:具有固定含义的特殊字符
. 匹配除\n以外的任何字符
\w 匹配数字、字母或下划线 相当于[0-9a-zA-Z_]
\s 匹配任意的空白符
\d 匹配单个数字字符 相当于[0-9]
\n 匹配一个换行符
# 表单验证用处大
^ 指定起始字符
$ 指定结束字符
\W 匹配非数字、字母或下划线
\S 匹配非空白符
\D 匹配非数字
| 或者
[] 匹配字符组中的字符 实例:[happy] 匹配 h、a、p、p、y中的任意一个字符
- 连字符 实例:[A-Z] 匹配 A-Z任意一个大写字母
[^...] 匹配除了字符组以外的所有字符
量词:用于指定其前面的字符出现多少次
* 指定字符重复 0 或 多次
+ 指定字符重复 1 或 多次
? 指定字符重复 0 或 1 次
{n} 指定字符重复n次
{n,} 指定字符重复至少n次
{n,m} 指定字符重复 n 到 m 次
贪婪匹配和惰性匹配
贪婪匹配 .*
惰性匹配 .*?
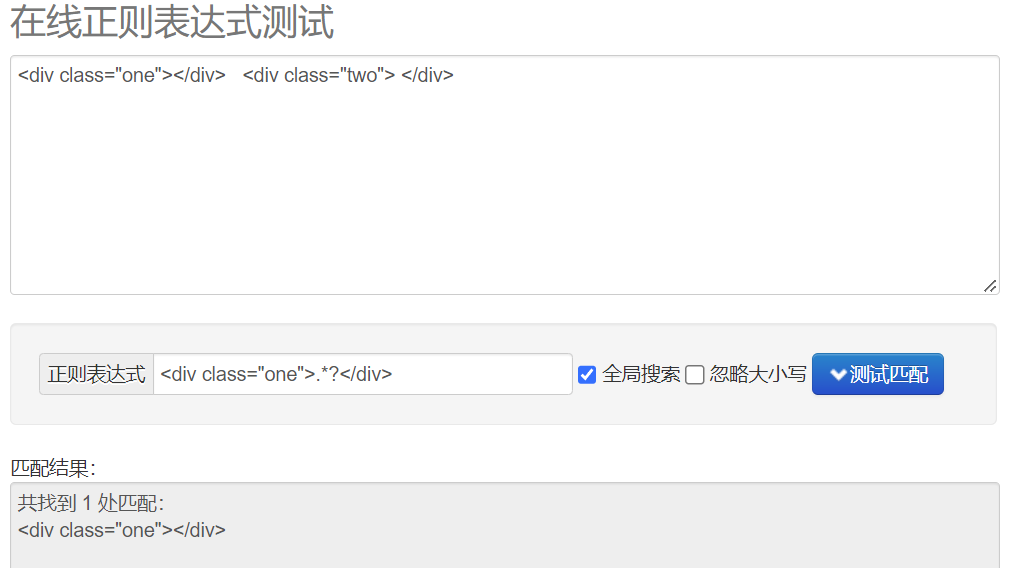
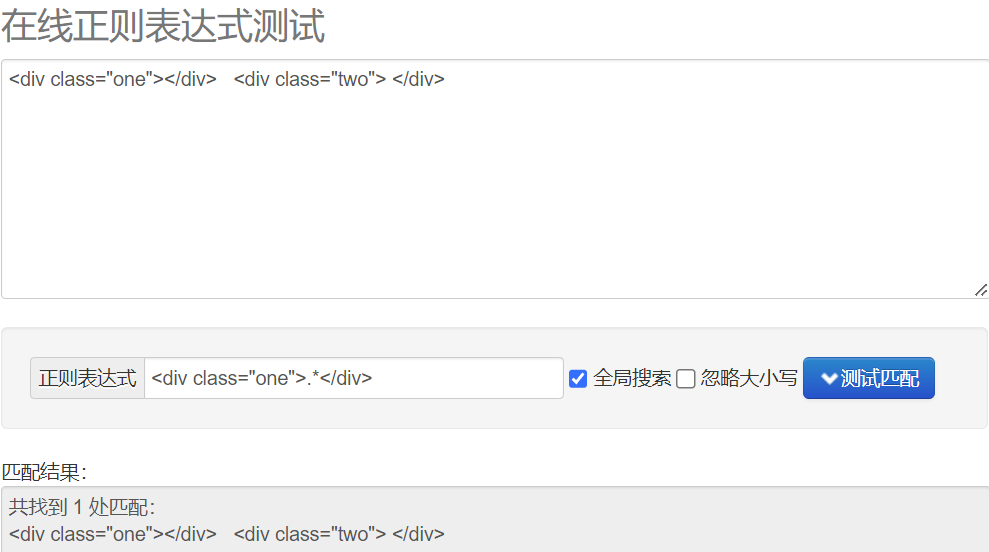
re模块
import re
# 贪婪匹配 .* 惰性匹配 .*?
# def findall(pattern, string, flags=0):
# findall:匹配字符串中所有符合正则的内容,并以列表的方式返回。
match_list = re.findall(pattern=r"\d+", string="123abc456")
print(match_list)
# def finditer(pattern, string, flags=0):
# finditer:返回迭代器
match_iter = re.finditer(pattern=r"\d+", string="123abc456")
print(match_iter)
for iter_one in match_iter:
print(iter_one.group())
# def search(pattern, string, flags=0):
# search:匹配一次,返回match对象
match_search = re.search(pattern=r"\d+", string="123abc456")
print(match_search)
print(match_search.group())
# def match(pattern, string, flags=0):
# match:从头开始匹配,返回 match对象
match_match = re.match(pattern=r"\d+", string="123abc456")
print(match_match.group())
# 预加载正则表达式
obj = re.compile(r"\d+")
res = obj.finditer(string="123abc456")
for iter_two in res:
print(iter_two.group())
输出结果:
['123', '456']
<callable_iterator object at 0x0000022CCE1D7C40>
123
456
<re.Match object; span=(0, 3), match='123'>
123
123
123
456
















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











