







 本文深入探讨了Transformer模型及其演变,包括Transformer的Attention机制、多头注意力、位置编码、缺陷,以及Universal Transformer和Transformer-XL的改进。Transformer抛弃了RNN和CNN,仅使用Attention,而Universal Transformer引入了递归思想和自适应计算,Transformer-XL通过段级循环和相对位置编码解决了上下文碎片和长距离依赖问题。
本文深入探讨了Transformer模型及其演变,包括Transformer的Attention机制、多头注意力、位置编码、缺陷,以及Universal Transformer和Transformer-XL的改进。Transformer抛弃了RNN和CNN,仅使用Attention,而Universal Transformer引入了递归思想和自适应计算,Transformer-XL通过段级循环和相对位置编码解决了上下文碎片和长距离依赖问题。
特别鸣谢刘陆琛@Mayouji在本文写作过程中的帮助
Attention机制在NLP领域的应用最早可以追朔到2014年,Bengio团队将Attention引入NMT(神经机器翻译)任务 [1]。之后更是在深度学习的各个领域得到了广泛应用:如CV中用于捕捉图像上的感受野;NLP中定位关键token/feature.
作为某种程度上可以称为当下NLP领域最强的特征抽取器的transformer [2],同样不是一蹴而就的:
- Transformer
首个完全抛弃RNN的recurrence,CNN的convolution,仅用attention来做特征抽取的模型 - Universal Transformer
重新将recurrence引入transformer,并加入自适应的思想,使得transformer图灵完备,并有着更好的泛化性和计算效率 - Transformer-XL
在transformer的基础上加入Segment-level Recurrence和相对位置编码,从而可以处理超长输入序列,并且更加高效。
在文章开始,首先尝试提出几个问题,来帮助我们理解transformer这一系列模型的思想:
- 为什么要引入attention机制?
Attention机制理论上可以建模任意长度的长距离依赖,并且符合人类直觉- transformer有哪些优点和不足?
完全基于attention,在可以并行的情况下仍然有很强的特征抽取能力,缺点是仍然是自回归的形式、理论上非图灵完备、缺少Recurrent Inductive Bias和条件计算、对超长序列建模能力较差- universal transformer相较于transformer做了哪些改进,有什么不足?
利用Recurrence将transformer的层数由6改为了任意层,并且理论上实现了图灵完备(指的是计算上通用);加入自适应计算的思想,使得模型计算更加高效。- transformer-XL的特点,优势是什么?
引入Segment-level Recurrence,使得transformer可以解决“上下文碎片问题”并捕捉更长距离的依赖,从而可以处理超输入序列
transformer仍然是基于seq2seq,所以介绍attention机制之前,需要先介绍下“前attention”时代,NLP领域中的seq2seq。
seq2seq简介
文中关于seq2seq的介绍均以机器翻译应用为例。
RNN-based seq2seq
seq2seq最早来源于通信,对应过程中的编码和解码。在NLP领域中,seq2seq主要用来解决将一个序列X转化为另一个序列Y这一类问题,通常应用于机器翻译、自动摘要等端到端的生成式应用。seq2seq有一个很重要的特点:输入序列X和输出序列Y可以不等长,不需要一一对应。
传统的seq2seq是条件语言模型,即在已知输入序列X和生成序列Y中已生成词的条件下, 最大化下一目标词的概率,而最终希望得到的是整个输出序列的生成出现的概率最大:
P ( Y ∣ X ) = ∑ t = 1 T log P ( y t ∣ y 1 : t − 1 , X ) P(Y | X)=\sum_{t=1}^{T} \log P\left(y_{t} | y_{1 : t-1}, X\right) P(Y∣X)=t=1∑TlogP(yt∣y1:t−1,X)
其中:
- X为输入序列
- T代表时刻, y 1 : t − 1 y_{1 : t-1} y1:t−1则代表decoder前t-1时间的输出
- 对于seq2seq而言,在训练时 y 1 : t − 1 y_{1 : t-1} y1:t−1是ground truth tokens;而在测试的时候,没有ground truth tokens,此时是采用decoder生成的 y 1 : t − 1 ′ y'_{1 : t-1} y1:t−1′来预测下一个词。训练和预测时这种不一致,也是seq2seq中长期存在的“暴露偏差”的根源,针对这一问题,也有很多的工作,这里就不再展开。
- 上述过程预测输出序列Y的token时,是根据之前时刻的结果 y 1 : t − 1 ′ y'_{1 : t-1} y1:t−1′来预测下一个token,即极大化下一目标token的概率,这是一种典型的贪心策略,得到的是局部最优;而对于一般的端到端生成模型而言,希望得到整个序列的最佳,即最后的生成序列Y的tokens顺序排列的联合概率最大,找到一个全局最优。实际过程中seq2seq在预测时并不使用这种greedy search的策略,而是采用beam search。不过本文主要讲述transformer,seq2seq仅做一个便于问题理解的概述。
下图是一个基本的RNN-based seq2seq(图中的箭头可以描述信息传导过程):
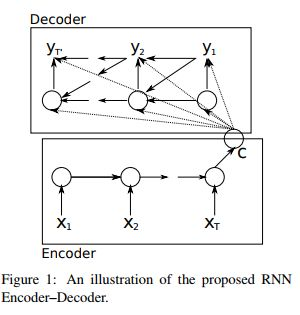
Encoder会将输入序列X编码为一个固定长度的语义向量C:在编码过程中,时刻t的输出仅依赖前一时刻隐层 h t − 1 h_{t-1} ht−1 和当前时刻的输入 x t x_{t} xt
Decoder的输入是encoder得到的语义向量 C C C:解码过程中,时刻t的输出依赖于三个部分,上一个时刻隐层状态 h t − 1 h_{t-1} ht−1和中间语义向量 C C C和上一个时刻的预测输出 y t − 1 y_{t-1} yt−1
Seq2Seq两个部分(Encoder和Decoder)联合训练的目标函数是最大化条件似然函数:
max θ 1 N ∑ n = 1 N log p θ ( y n ∣ x n ) \max _{\boldsymbol{\theta}} \frac{1}{N} \sum_{n=1}^{N} \log p_{\boldsymbol{\theta}}\left(\mathbf{y}_{n} | \mathbf{x}_{n}\right) θmaxN1n=1∑Nlogpθ(yn∣xn)
其中θ为模型的参数,N为训练集的样本个数。
seq2seq中encoder的输入 x i x_i xi和decoder中的输出 y i y_i yi都是词的高维向量表示,向量中蕴涵一定的语义信息,之所以可以用一个高维向量来表示词的语义,其基本假设是上世纪语言学家提出的分布式语义的思想:其认为一个词可以由上下文中的词来表示。
有了分布式语义,我们就可以来理解NLP问题中普遍存在的长距离依赖,考虑语言模型中依据之前的词来预测下一个词:
- 如果我们试图预测“the clouds are in the sky”中的最后一个单词,我们不需要任何更多的上下文信息,从"clonds", “in” 这些近距离的词就可以预测到下一个单词是“sky”
- 而如果尝试预测“I grew up in France… … I speak fluent French.”中的"French",那么需要重点关注远距离的"France"。
上述例子可以表明,当我们做预测时,可能需要重点关注的信息与当前位置的距离非常大,RNN很难保留这种远距离的信息。这就是NLP中普遍存在的长距离依赖。即使有如LSTM,GRU这样加入门控机制和梯度裁剪的RNN变种,其捕捉长距离依赖的能力仍然有所欠缺,Stanford在ACL 2018的一个工作[5]进行了实验,目前可以编码的最长距离在200左右。
RNN-based seq2seq with attention
RNN在将一个不定长输入序列转化为定长的中间语义向量时,会有信息损失,为了避免这样的损失,就引入了Attention机制。Attention机制本身有些类似于人类的直观活动:人在观察一副图画时,直觉会重点关注“更为重要”的信息;人类译者在做翻译时,也会更侧重当前翻译部分所对应的上下文。基于这样的原理,Attention机制在做机器翻译时,会尝试关注源语句中“更为重要”信息,再结合已经翻译的部分,最终得出当前译文。
下面的动图可以很好的描述一个基本的RNN-based seq2seq信息传导过程(图片来源于google seq2seq示例 [4]),在解码得到“Knowledge”时,会将注意力集中在源语句中的“知识”。
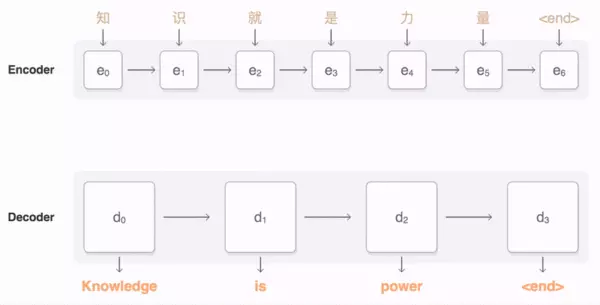
结合了attention的seq2seq,不再局限于定长的语义向量,理论上也不会损失远距离的信息,在实际应用过程中也取得了很好的效果。既然如此,一个朴素的想法就是“既然attention机制已经很有效,那么我们去掉RNN,直接用attention的效果会怎么样?” Google在2017年提出的transformer就是一个完全基于self-attention的seq2seq模型。
Transformer
下面的动图(来自于Google AI Blog[6])演示了transformer在机器翻译中的应用:
- Encoder:读取输入语句并生成其representation。
- Decoder:参考Encoder生成的输入语句的representation,逐词生成输出语句。
transformer首先为每个单词生成初始表示或使用预先定义的wordembedding,动图中用空白的圆表示;然后通过self attention,从所有其他单词中收集信息,生成一个新的representation,每个单词由整个上下文(动图中由填满的圆表示)的信息来表示。然后,对所有单词并行重复此步骤多次,依次生成新的representation。
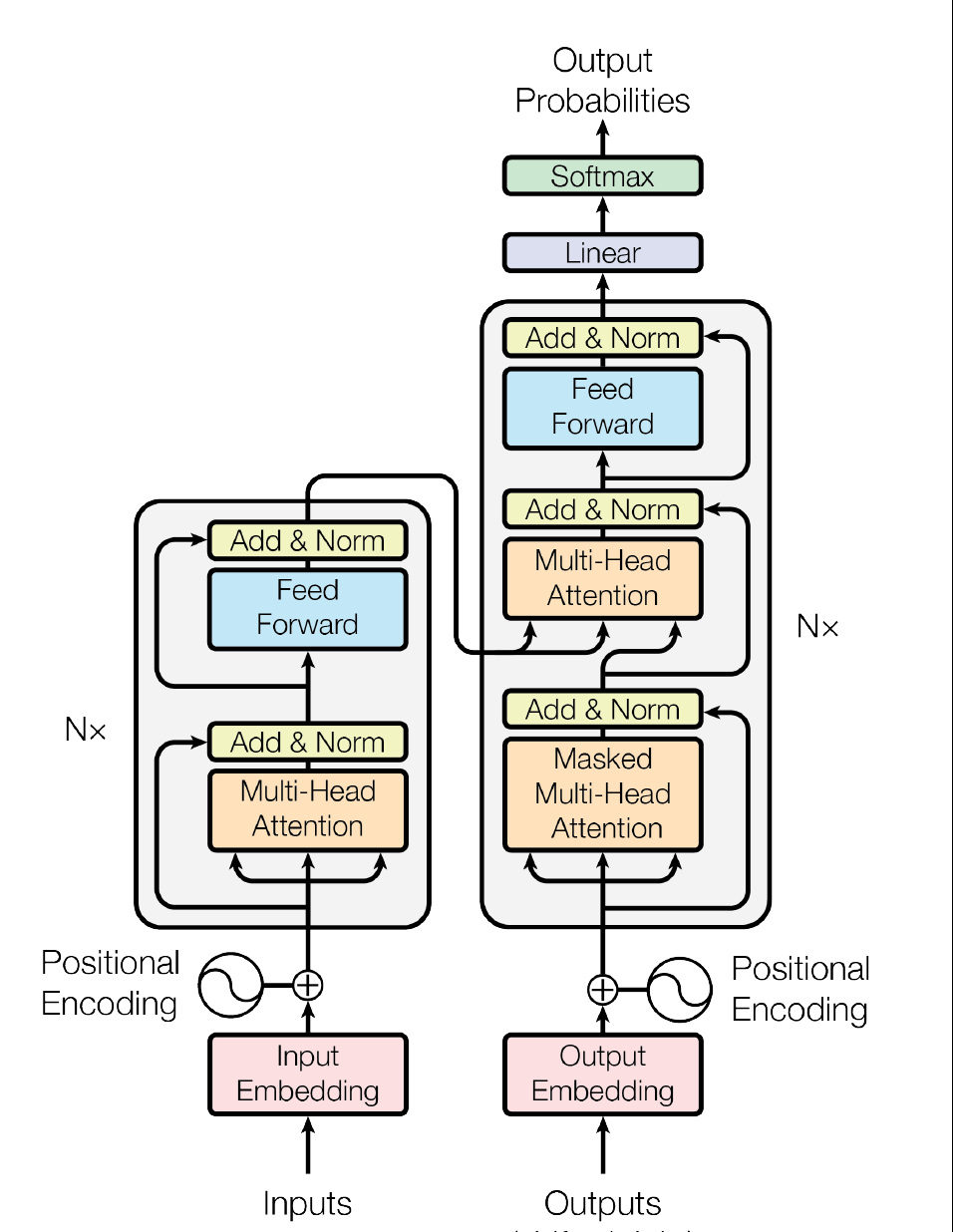
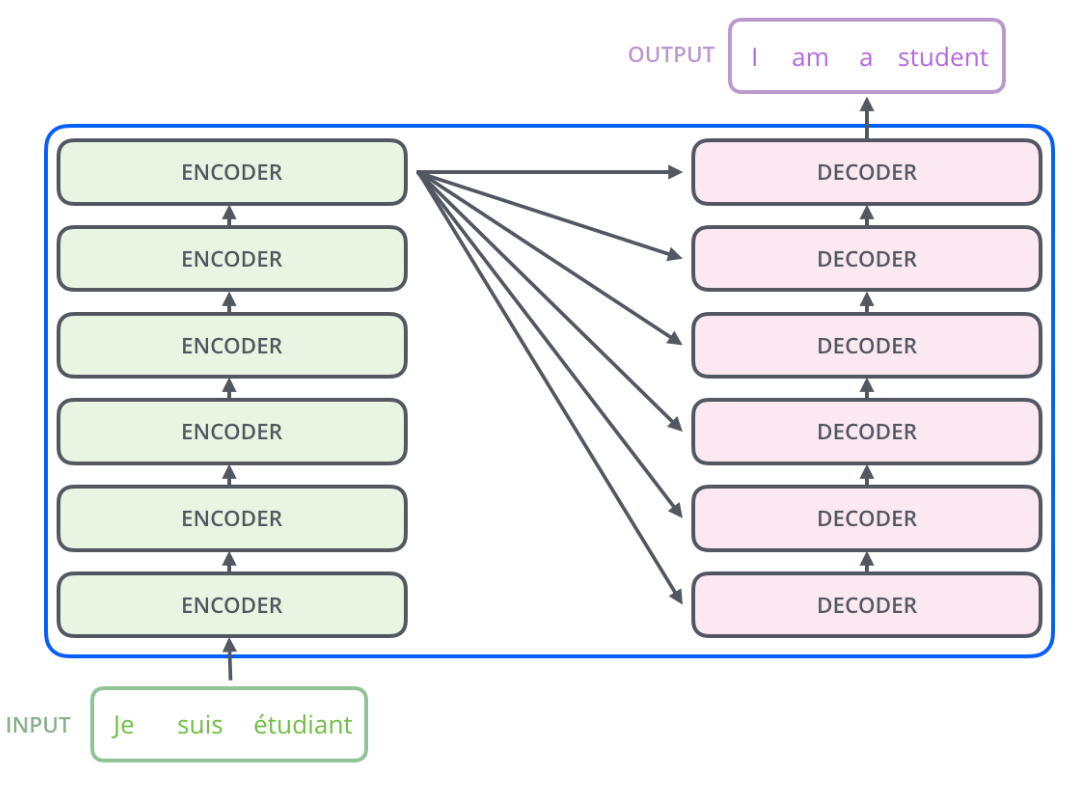
下图(左)是transformer的一个基本架构,左边是编码的部分(transformer的Encoder由6个这样相同的层堆叠而成),右边是解码的部分(transformer的Decoder由6个这样相同的层堆叠而成),下图(右)是展开的示意图
 |
 |
Encoder:由6个相同的层堆叠而成,每层有两个sub layer:multi-head self-attention层和一个全连接前馈神经网络;sub layer之间经layer normalization后,再通过residual connection连接。
Decoder:整体类似于Encoder,多了一层multi-head self-attention,用于在encoder stack的输出上加入multi head attention;在multi-head self-attention层中假加入masking,从而确保了位置i的预测只能依赖于位置i之前的已知输出。(因为解码的时候,位置i之后的输入,并不存在,这样可以保持自回归的特性)
以上是对transformer的一个简要概述,以下将对transformer各个部分进行详解。
Attention
Scaled Dot-Product Attention
Self Attention本质上是将上下文词的representation加权求和作为当前词的representation。需要关注的部分是我们如何得到加权求和的权值。在Transformer中,这一部分用 A t t e n t i o n ( Q , K , V ) Attention(Q,K,V) Attention(Q,K,V)来体现 ,Q是query,K是Key;通过Q和K的点积的结果来体现上下文词对当前词的影响程度,再通过softmax得到归一化权重:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention (Q,K,V)=softmax(dkQKT)V
在transformer中,每个单词会有一个语义向量,乘以权重矩阵 W i Q W^Q_i WiQ, W i K W^K_i WiK, W i V W^V_i WiV,从而得到对应的 Q i Q_i Qi, V i V_i Vi, K i K_i Ki.
d k \sqrt{d_{k}} dk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









