







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)

正文
导入公钥到其他datanode节点认证文件
[hadoop@xuegod63 ~]# ssh-copy-id root@192.168.1.62
[hadoop@xuegod63 ~]# ssh-copy-id root@192.168.1.64
配置Hadoop环境,安装Java环境JDK:三台机器上都要配置
63安装jdk
上传jdk-8u161-linux-x64.rpm软件包到63
d63 ~]# rpm -ivh jdk-8u161-linux-x64.rpm
1、安装及配置Java运行环境—jdk。升级了jdk的版本
63 ~]# rpm -ivh jdk-8u161-linux-x64.rpm
63 ~]#rpm -pql /root/jdk-8u161-linux-x64.rpm #通过查看jdk的信息可以知道jdk的安装目录在/usr/java
63 ~]#vim /etc/profile #在文件的最后添加以下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_161
export JAVA_BIN=/usr/java/jdk1.8.0_161/bin
export PATH=${JAVA_HOME}/bin:$PATH
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
63 ~]#source /etc/profile #使配置文件生效
验证java运行环境是否安装成功:
63 ~]# java -version
java version "1.8.0\_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
如果出现安装的对应版本,说明java运行环境已经安装成功。
注:这里只是升级了jdk的版本,因为在我安装的系统中已经安装了jdk。
将jdk部署到其它两台机器上:
63 ~]# scp jdk-8u161-linux-x64.rpm root@192.168.1.62:/root
63 ~]# scp jdk-8u161-linux-x64.rpm root@192.168.1.64:/root
63 ~]# scp /etc/profile 192.168.1.62:/etc/profile
63 ~]# scp /etc/profile 192.168.1.64:/etc/profile
安装:
[root@xuegod64 ~]# rpm -ivh jdk-8u161-linux-x64.rpm
[root@xuegod62 ~]# rpm -ivh jdk-8u161-linux-x64.rpm
重新参加java运行环境:
[root@xuegod64 ~]# source /etc/profile
[root@xuegod62 ~]# source /etc/profile
测试:
[root@xuegod64 ~]# java -version
java version “1.7.0_71”
Java™ SE Runtime Environment (build 1.7.0_71-b14)
Java HotSpot™ 64-Bit Server VM (build 24.71-b01, mixed mode)
[root@xuegod62 ~]# java -version
java version “1.7.0_71”
Java™ SE Runtime Environment (build 1.7.0_71-b14)
Java HotSpot™ 64-Bit Server VM (build 24.71-b01, mixed mode)
三台机器关闭防火墙:
[root@xuegod63 ~]# systemctl stop firewalld.service
[root@xuegod63 ~]# systemctl disable firewalld.service
[root@xuegod62 ~]# systemctl stop firewalld.service
[root@xuegod62 ~]# systemctl disable firewalld.service
[root@xuegod64 ~]# systemctl stop firewalld.service
[root@xuegod64 ~]# systemctl disable firewalld.service
在xuegod63安装Hadoop 并配置成namenode主节点
Hadoop安装目录:/home/hadoop/hadoop-3.0.0
使用root帐号将hadoop-3.0.0.tar.gz 上传到服务器
[root@xuegod63 ~]# mv hadoop-3.0.0.tar.gz /home/hadoop/
注意:以下步骤使用hadoop账号操作。
[root@xuegod63 ~]# su - hadoop
[hadoop@xuegod63 ~]$ tar zxvf hadoop-3.0.0.tar.gz #只要解压文件就可以,不需要编译安装
创建hadoop相关的工作目录
[hadoop@xuegod63 ~]$ mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp
[hadoop@xuegod623 ~]$ ls
dfs hadoop-3.0.0 hadoop-3.0.0.tar.gz tmp
配置Hadoop:需要修改7个配置文件。
文件位置:/home/hadoop/hadoop-3.0.0/etc/hadoop/
文件名称:hadoop-env.sh、yarn-evn.sh、workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
1、配置文件hadoop-env.sh,指定hadoop的java运行环境
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置。
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/hadoop-env.sh
改:54 # export JAVA_HOME=
为:export JAVA_HOME=/usr/java/jdk1.8.0_161
注:指定java运行环境变量
2、配置文件yarn-env.sh,保存yarn框架的运行环境
该文件是yarn框架运行环境的配置,同样需要修改java虚拟机的位置。
yarn :Hadoop 的新 MapReduce 框架Yarn是Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理 。
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/yarn-env.sh 不需要修改。
查看优先规则:
Precedence rules:
yarn-env.sh > hadoop-env.sh > hard-coded defaults
Precedence [ˈpresɪdəns] 优先
4、配置文件core-site.xml,指定访问hadoop web界面访问路径
这个是hadoop的核心配置文件,这里需要配置的就这两个属性,fs.default.name配置了hadoop的HDFS系统的命名,位置为主机的9000端口;
hadoop.tmp.dir配置了hadoop的tmp目录的根位置。这里使用了一个文件系统中没有的位置,所以要先用mkdir命令新建一下。
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/core-site.xml
改:
19
20
注: 在和中间插入以一下红色和蓝色标记内容:
为:
fs.defaultFS hdfs://xuegod63.cn:9000 io.file.buffer.size 13107 hadoop.tmp.dir file:/home/hadoop/tmp Abase for other temporary directories. 注:property 财产 [ˈprɒpəti] io.file.buffer.size 的默认值 4096 。这是读写 sequence file 的 buffer size, 可减少 I/O 次数。在大型的 Hadoop cluster,建议可设定为 65536
5、配置文件hdfs-site.xml
这个是hdfs的配置文件,dfs.http.address配置了hdfs的http的访问位置;
dfs.replication配置了文件块的副本数,一般不大于从机的个数。
[root@xuegod63 ~]# vim /home/hadoop/hadoop-3.0.0/etc/hadoop/hdfs-site.xml
改:19
20
21
注: 在和中间插入以一下红色和蓝色标记内容:
为:
dfs.namenode.secondary.http-address
xuegod63.cn:9001
dfs.namenode.name.dir file:/home/hadoop/dfs/name dfs.datanode.data.dir file:/home/hadoop/dfs/data dfs.replication 2 dfs.webhdfs.enabled true
注:
dfs.namenode.secondary.http-address
xuegod63.cn:9001 # 通过web界面来查看HDFS状态
dfs.replication
2 #每个Block有2个备份。
6、配置文件mapred-site.xml
这个是mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数,
同时指定:Hadoop的历史服务器historyserver
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器
$ /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver
historyserverWARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement “mapred --daemon start” instead.
WARNING: /home/hadoop/hadoop-3.0.0/logs does not exist. Creating.
这样我们就可以在相应机器的19888端口上打开历史服务器的WEB UI界面。可以查看已经运行完的作业情况。
修改mapred-site.xml
[hadoop@xuegod63 hadoop-3.0.0]$ vim
6、配置文件mapred-site.xml
这个是mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数,
同时指定:Hadoop的历史服务器historyserver
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器
$ /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver
historyserverWARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement “mapred --daemon start” instead.
WARNING: /home/hadoop/hadoop-3.0.0/logs does not exist. Creating.
这样我们就可以在相应机器的19888端口上打开历史服务器的WEB UI界面。可以查看已经运行完的作业情况。
修改mapred-site.xml
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/mapred-site.xml
改:19
20
21
注: 在和中间插入以一下红色和蓝色标记内容:
为:
mapreduce.framework.name yarn mapreduce.jobhistory.address 0.0.0.0:10020 mapreduce.jobhistory.webapp.address 0.0.0.0:19888
7、配置节点yarn-site.xml
该文件为yarn框架的配置,主要是一些任务的启动位置
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/yarn-site.xml
修改configuration内容如下:
改:
注: 在和中间插入以一下红色和蓝色标记内容:
为:
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address xuegod63.cn:8032 yarn.resourcemanager.scheduler.address xuegod63.cn:8030 yarn.resourcemanager.resource-tracker.address xuegod63.cn:8031 yarn.resourcemanager.admin.address xuegod63.cn:8033 yarn.resourcemanager.webapp.address xuegod63.cn:8088 yarn.application.classpath /home/hadoop/hadoop-3.0.0/etc/hadoop:/home/hadoop/hadoop-3.0.0/share/hadoop/c ommon/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/common/*:/home/hadoop/hadoop-3.0. 0/share/hadoop/hdfs:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/home/hadoop/h adoop-3.0.0/share/hadoop/hdfs/*:/home/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/*😕 home/hadoop/hadoop-3.0.0/share/hadoop/yarn:/home/hadoop/hadoop-3.0.0/share/hadoop/ya rn/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/*
编辑datanode节点host
[hadoop@xuegod63 hadoop]$ vim workers
xuegod62.cn
xuegod64.cn
复制到其他datanode节点: xuegod64和xuegod62
[hadoop@xuegod63 hadoop-3.0.0]$ scp core-site.xml hadoop-env.sh hdfs-site.xml mapred-site.xml yarn-site.xml workers 192.168.1.62:/home/hadoop/hadoop-3.0.0/etc/hadoop/
[hadoop@xuegod63 hadoop-3.0.0]$ scp core-site.xml hadoop-env.sh hdfs-site.xml mapred-site.xml yarn-site.xml workers 192.168.1.64:/home/hadoop/hadoop-3.0.0/etc/hadoop/
在xuegod63上启动Hadoop
切换到hadoop用户
[root@xuegod63 ~]# su - hadoop
(3)格式化
hadoop namenode的初始化,只需要第一次的时候初始化,之后就不需要了
[hadoop@xuegod63 hadoop-3.0.0]$ /home/hadoop/hadoop-3.0.0/bin/hdfs namenode -format
15/08/03 22:35:21 INFO common.Storage: Storage directory /home/hadoop/dfs/name has been successfully formatted.
。。。
15/08/03 22:35:21 INFO util.ExitUtil: Exiting with status 0
15/08/03 22:35:21 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at xuegod63.cn/192.168.1.63
************************************************************/
[root@xuegod63 hadoop-3.0.0]# echo KaTeX parse error: Expected ‘EOF’, got ‘#’ at position 36: …oot@xuegod63 ~]#̲ rpm -ivh /mnt/… tree /home/hadoop/dfs/
/home/hadoop/dfs/
├── data
└── name
└── current
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
生成基于hadoop用户的不输入密码登录:因为后期使用hadoop用户启动datanode节点使用需要直接登录到对应的服务器上启动datanode相关服务。
[hadoop@xuegod63 hadoop-3.0.0]$ ssh-keygen
[hadoop@xuegod63 hadoop-3.0.0]$ ssh-copy-id 192.168.1.64
[hadoop@xuegod63 hadoop-3.0.0]$ ssh-copy-id 192.168.1.62
[hadoop@xuegod63 hadoop-3.0.0]$ ssh-copy-id 192.168.1.63
(4)启动hdfs: ./sbin/start-dfs.sh,即启动HDFS分布式存储
[root@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/start-dfs.sh
Starting namenodes on [xuegod63.cn]
xuegod63.cn: starting namenode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-namenode-xuegod63.cn.out
xuegod64.cn: starting datanode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-datanode-xuegod64.cn.out
xuegod62.cn: starting datanode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-datanode-xuegod62.cn.out
Starting secondary namenodes [xuegod63.cn]
xuegod63.cn: starting secondarynamenode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-secondarynamenode-xuegod63.cn.out
注:如果报错,如:
xuegod64.cn: Host key verification failed.
解决:
[hadoop@xuegod63 ~]$ ssh 192.168.1.64 #确认可以不输入密码直接连接上xuegod64
关闭后再重启:
[root@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/stop-dfs.sh
[root@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/start-dfs.sh
(5)查看进程,此时master有进程:namenode和 secondarynamenode进程:
[root@xuegod63 ~]# ps -axu | grep namenode --color
Warning: bad syntax, perhaps a bogus ‘-’? See /usr/share/doc/procps-3.2.8/FAQ
root 8214 4.1 9.5 1882176 110804 ? Sl 17:39 0:17 /usr/java/jdk1.8.0_161/bin/java -Dproc_namenode -Xmx1000m
。。。
-Dhadoop.log.dir=/home/hadoop/hadoop-3.0.0/logs -Dhadoop.log.file=hadoop-root-secondarynamenode-xuegod63.cn.log
xuegod64和xuegod62上有进程:DataNode
[root@xuegod64 ~]# ps -axu | grep datanode --color
Warning: bad syntax, perhaps a bogus ‘-’? See /usr/share/doc/procps-3.2.8/FAQ
root 5749 8.8 5.2 1851956 60656 ? Sl 17:55 0:06 /usr/java/jdk1.8.0_161/bin/java -Dproc_datanode -Xmx1000m
。。。
(6)在xuegod63上启动yarn: ./sbin/start-yarn.sh 即,启动分布式计算
[hadoop@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-3.0.0/logs/yarn-root-resourcemanager-xuegod63.cn.out
xuegod62.cn: starting nodemanager, logging to /home/hadoop/hadoop-3.0.0/logs/yarn-root-nodemanager-xuegod62.cn.out
xuegod64.cn: starting nodemanager, logging to /home/hadoop/hadoop-3.0.0/logs/yarn-root-nodemanager-xuegod64.cn.out
(7)查看进程:
查看xuegod63上的ResourceManager进程,xuegod62和xuegod64上的进程:DataNode NodeManager
[root@xuegod63 ~]# ps -axu | grep resourcemanager --color
Warning: bad syntax, perhaps a bogus ‘-’? See /usr/share/doc/procps-3.2.8/FAQ
root 9664 0.2 11.0 2044624 128724 pts/3 Sl 17:58 0:27 /usr/java/jdk1.8.0_161/bin/java -Dproc_resourcemanager -Xmx1000m
[root@xuegod62 ~]# ps -axu | grep nodemanager --color
Warning: bad syntax, perhaps a bogus ‘-’? See /usr/share/doc/procps-3.2.8/FAQ
hadoop 5486 31.8 7.8 1913012 91692 ? Sl 23:01 0:20 /usr/java/jdk1.8.0_161/bin/java -Dproc_nodemanager -Xmx1000m -Dhadoop.log.dir=/home/hadoop/hadoop-3.0.0/logs
[root@xuegod64 ~]# ps -axu | grep nodemanager --color
Warning: bad syntax, perhaps a bogus ‘-’? See /usr/share/doc/procps-3.2.8/FAQ
hadoop 2872 20.8 7.9 1913144 92860 ? Sl 21:42 0:15 /usr/java/jdk1.8.0_161/bin/java -Dproc_nodemanager -Xmx1000m
注:start-dfs.sh 和 start-yarn.sh 这两个脚本可用start-all.sh代替。
[hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/start-all.sh
关闭:
[hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/stop-all.sh
启动: jobhistory服务,查看mapreduce运行状态
[hadoop@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/hadoop/hadoop-3.0.0/logs/mapred-root-historyserver-xuegod63.cn.out
在主节点上启动存储服务和资源管理主服务。使用命令:
[hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/hadoop-daemon.sh start datanode #启动从存储服务
[hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务
登录从结点:启动存储从服务和资源管理从服务
[hadoop@xuegod62 ~]$ /home/hadoop/hadoop-3.0.0/sbin/hadoop-daemon.sh start datanode #启动从存储服务
[hadoop@xuegod62 ~]$ /home/hadoop/hadoop-3.0.0/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务
[hadoop@xuegod64 ~]$ /home/hadoop/hadoop-3.0.0/sbin/hadoop-daemon.sh start datanode #启动从存储服务
[hadoop@xuegod64 ~]$ /home/hadoop/hadoop-3.0.0/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务
(8)查看HDFS分布式文件系统状态: [hadoop@xuegod63 hadoop-3.0.0]$ /home/hadoop/hadoop-3.0.0/bin/hdfs dfsadmin -report 。。。
Datanodes available: 1 (1 total, 0 dead)
Live datanodes:
Name: 192.168.1.62:50010 (xuegod62.cn)
Hostname: xuegod62.cn
Decommission Status : Normal
Configured Capacity: 10320982016 (9.61 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 4737789952 (4.41 GB)
DFS Remaining: 5583167488 (5.20 GB)
DFS Used%: 0.00%
DFS Remaining%: 54.10%
Last contact: Sun May 31 21:58:00 CST 2015
Name: 192.168.1.64:50010 (xuegod64.cn)
Hostname: xuegod64.cn
Decommission Status : Normal
Configured Capacity: 10320982016 (9.61 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 5014945792 (4.67 GB)
DFS Remaining: 5306011648 (4.94 GB)
DFS Used%: 0.00%
DFS Remaining%: 51.41%
Last contact: Mon Aug 03 23:00:03 CST 2015
(9)查看文件块组成部分:
[hadoop@xuegod63 hadoop-3.0.0]$ ./bin/hdfs fsck / -files -blocks
或:
http://192.168.1.63:9870/dfshealth.html#tab-datanode

(10)通过web界面来查看HDFS状态: http://192.168.1.63:9001/status.html
(11)通过Web查看hadoop集群状态: http://192.168.1.63:8088

(12)查看JobHistory的内容:
http://192.168.1.63:19888/jobhistory
(13)设置HADOOP_HOME环境变量,方便后期调用命令。
[root@xuegod63 ~]# vim /etc/profile #添加追加以下内容:
export HADOOP_HOME=/home/hadoop/hadoop-3.0.0
export PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:HADOOP_HOME/bin:
H
A
D
O
O
P
H
O
M
E
/
s
b
i
n
:
HADOOP_HOME/sbin:
HADOOPHOME/sbin:PATH
[root@xuegod63 ~]# source /etc/profile
[root@xuegod63 ~]# start #输入start 按两下tab键,测试命令补齐
测试:
运行Hadoop计算任务,Word Count 字数统计
[hadoop@xuegod63 ~]$ source /etc/profile
(1)/home/hadoop目录下有两个文本文件file01.txt和file02.txt,文件内容分别为:
[hadoop@xuegod63 ~]$ vim file01.txt
man
kong
man
Hello World
mk
[hadoop@xuegod63 ~]$ vim file02.txt
mk
www.xuegod.cn
cd
cat
man
(2)将这两个文件放入hadoop的HDFS中:
[hadoop@xuegod63 ~]$ hadoop fs -ls //查看hdfs目录情况
ls: `.’: No such file or directory
[hadoop@xuegod63 ~]$ hadoop fs -mkdir -p input
[hadoop@xuegod63 ~]$ hadoop fs -put /home/hadoop/file*.txt input
[hadoop@xuegod63 ~]$ hadoop fs -cat input/file01.txt //查看命令
man
kong
man
Hello World
mk
(3)计执行 wordCount单词统计汇总并查看结果:
[hadoop@xuegod63 ~] hadoop jar hadoop-3.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount input output
查看运行之后产生的文件
hadoop fs -ls output
查看运行结果
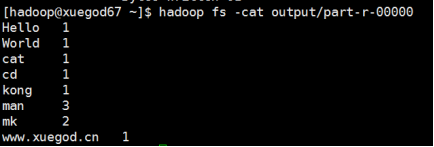
hadoop fs -cat output/part-r-00000
可以看到数据都已经被统计出来了。
实例2:运行排序计算
如下的这个程序,会现在每个节点生成10个G的随机数字,然后排序出结果:
[hadoop@xuegod63 ~]$ hadoop jar hadoop-3.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar randomwriter rand
[hadoop@xuegod63 ~]$ hadoop jar /home/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar sort rand sort-rand
第一个命令会在rand 目录的生成没有排序的数据。第二个命令会读数据,排序,然后写入rand-sort 目录。
排错常见错误
(1)Name node is in safe mode
运行hadoop程序时, 异常终止了,然后再向hdfs加文件或删除文件时,出现Name node is in safe mode错误:
rmr: org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode
解决的命令:
[hadoop@xuegod63 ~]$ hadoop dfsadmin -safemode leave #关闭safe mode
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Safe mode is OFF
(2)DataNode 无法启动
我遇到过两种情况的DataNode无法启动:第一种是/etc/hosts里面机器名字除了和IP对应之外,还和127.0.0.1对应,导致DataNode连接NameNode的9000端口一直连接不上;第二种是多次format namenode 造成namenode 和datanode的clusterID不一致,通过查看NameNode和DataNode的/home/hadoop/dfs/data/current/VERSION,发现确实不一致。
总之,遇到错误不要慌,多看看$HADOOP_HOME/logs下面的日志,就能找到问题。
http://www.aboutyun.com/thread-7088-1-1.html
Hadoop单机版
jdk-7u45-linux-x64.tar.gz 地址https://pan.baidu.com/s/1HlkngnG5H8JAdm0zYezEyg 提取码3z6s
jdk放到/usr/local目录下

解压jdk,
tar -zxvf jdk-7u45-linux-x64.tar.gz
配置环境变量 vim /etc/profile 在文件末尾加上
JAVA_HOME=/usr/local/jdk1.7.0_45
export JAVA_HOME
export PATH=$JAVA_HOME/bin:$PATH
刷新环境变量配置 source /etc/profile
测试jdk安装是否成功,显示如下截图代表成功 java -version
2、安装hadoop2.9.2 下载hadoop2.9.2 地址http://mirrors.hust.edu.cn/apache/hadoop/common/
放到 /usr/local目录下
解压 tar -zxvf hadoop-2.9.2.tar.gz 查看 ll
配置hadoop环境变量 vim /etc/profile 添加如下配置
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$PATH
重新刷新配置 source /etc/profile
查看版本 hadoop version
配置几个配置文件,路径是 cd /usr/local/hadoop-2.9.2/etc/hadoop/
vim core-site.xml 添加如下配置
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
放到 /usr/local目录下
解压 tar -zxvf hadoop-2.9.2.tar.gz 查看 ll
配置hadoop环境变量 vim /etc/profile 添加如下配置
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$PATH
重新刷新配置 source /etc/profile
查看版本 hadoop version
配置几个配置文件,路径是 cd /usr/local/hadoop-2.9.2/etc/hadoop/
vim core-site.xml 添加如下配置
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-sSHkD2sW-1713707427230)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









