







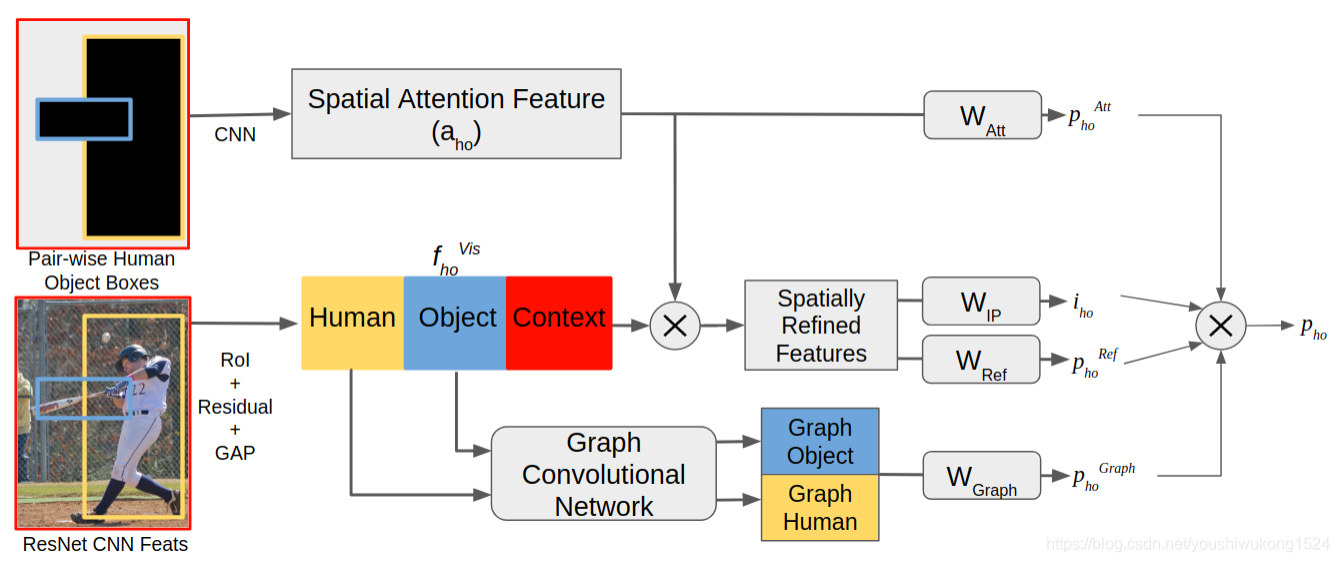
 VSGNet是一种用于检测人-物交互的深度学习模型,提出于2020年的CVPR会议。它包含三个分支:视觉分支、空间注意力分支和图卷积交互分支,通过建模空间关系和结构交互来提高HOI检测的准确性。模型通过整合视觉特征、空间注意力和图卷积来预测交互和动作类别。
VSGNet是一种用于检测人-物交互的深度学习模型,提出于2020年的CVPR会议。它包含三个分支:视觉分支、空间注意力分支和图卷积交互分支,通过建模空间关系和结构交互来提高HOI检测的准确性。模型通过整合视觉特征、空间注意力和图卷积来预测交互和动作类别。
论文题目:VSGNet: Spatial Attention Network for Detecting Human Object Interactions Using Graph Convolutions
会议:2020 CVPR
机构:加州大学 圣巴巴拉分校 电子与计算机工程系
论文:https://arxiv.org/abs/2003.05541
代码:https://github.com/ASMIftekhar/VSGNet (pytorch)
human-object interactions (HOI) 检测任务:
对于每一个image,检测出 human 和 object 的 bounding box,以及他们之间的交互(interactions)标签;
每个human-object对可以有多个交互标签,每个场景可以有多个human和object。
作者思路
起源 - 简单的HOI办法:
1. 分别从 human 和 object 上提取特征并分析:忽略了context信息和 人-物对 的空间信息;
2. 用union boxes建模空间关系:没有对交互显式地建模
因此,作者提出多分支网络:
视觉分支Visual Branch:分别从人、物和周围环境中提取视觉特征;
空间注意分支Spatial Attention Branch:建模人-物对之间的空间关系;
图卷积分支Graph Convolutional Branch:将场景视为一个图,人与对象作为节点,并对结构交互(structural interactions)进行建模。
网络结构
1.Overview
模型输入:图像特征 F 和 人的bbox 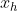 (1到H之间)和 物的bbox
(1到H之间)和 物的bbox 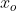 (1到O之间),H和O分别是该场景中人和物的数量
(1到O之间),H和O分别是该场景中人和物的数量
模型目的:
1. 检测人h是否与物体o交互,并给出交互建议值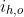
2. 预测动作类别概率向量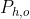 ,其大小为类别数
,其大小为类别数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









