







一、概述
进来在学go的端口检测部分,但是自己写遇到很多问题,又不知道从何入手,故找来网上佬们写的现成工具,学习一波怎么实现的。分析过程杂乱,没啥思路,勿喷。
项目来源:https://github.com/XinRoom/go-portScan/blob/main/util/file.go
二、目录结构分析
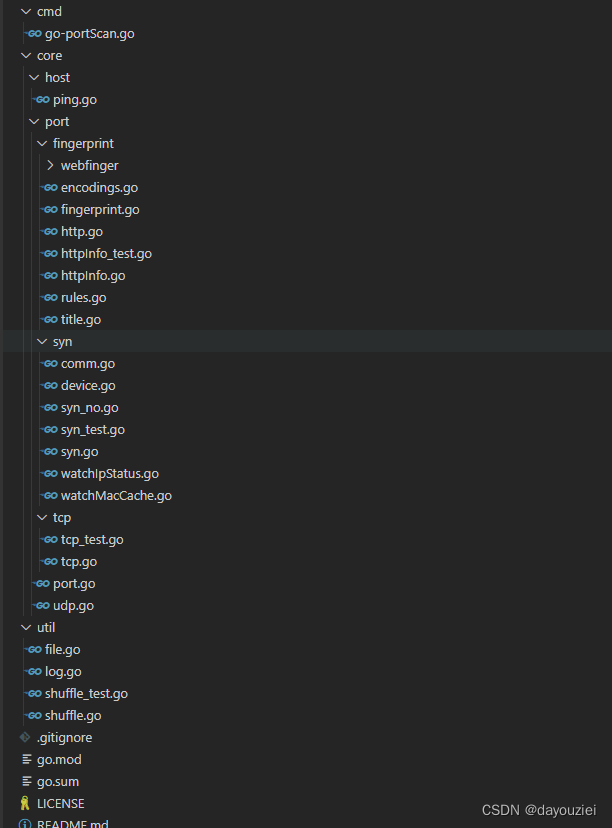
总体来说,这个工具主要三部分,cmd(主程序)、core(核心框架部分)、util(工具部分),后续的分析也从这三个部分开始讲解
三、util目录
此目录下主要有三个文件,分别为file.go、log.go、shuffle.go,以下逐一分析
1、file.go(逐行读取文件内容)
-
func GetLines(filename string) (out []string, err error)
主要内容为一个GetLines方法,其接收一个文件名作为参数,并返回文件中非空行的内容组成字符串切片和可能的错误,主要作用是逐行读取文件,并将非空行的内容添加到“out"切片中。
func GetLines(filename string) (out []string, err error) {
if filename == "" {//先判断文件名是否为空,为空则提示错误
return out, errors.New("no filename")
}
file, err := os.Open(filename)//打开文件
if err != nil {
return out, err
}
defer file.Close()//读取完记得关闭
scanner := bufio.NewScanner(file)//读取文件的内容
scanner.Split(bufio.ScanLines)//一行一行读取分隔
for scanner.Scan() {//逐行读取并将文本内容追加到out切片中
line := strings.TrimSpace(scanner.Text())
if line != "" {
out = append(out, line)
}
}
return
}2、log.go(日志记录)
-
func NewLogger(filename string, std bool) *log.Logger
主要内容为一个 NewLogger方法,它根据提供的参数创建一个新的日志记录器对象。该函数接受一个文件名和一个布尔值参数。
filename参数用于指定日志输出的文件名,如果为空字符串则表示日志将输出到标准输出(stdout)。std参数是一个布尔值,如果设置为true,则日志会同时输出到文件和标准输出;如果设置为false,则只输出到文件。
这个函数的目的是根据参数创建一个日志记录器,可以指定输出到文件还是标准输出,并可以选择是否同时输出到文件和标准输出。
func NewLogger(filename string, std bool) *log.Logger {
var out io.Writer
if filename == "" {
out = os.Stdout //如果传入的filename为空,将out设置为标准输出
} else {//如果不为空,则打开这个文件,
outFile, _ := os.OpenFile(filename, os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if std {//如果 std为true,则将输出同时定向到标准输出和文件中,通过 io.MultiWriter 将os.Stdout 和打开的文件合并成一个多写入器
out = io.MultiWriter(os.Stdout, outFile)
} else {//如果 std 参数为 false,则直接将输出定向到打开的文件中
out = outFile
}
}
logger := log.New(out, "", 0)//使用 log.New 方法创建一个新的日志记录器对象 logger,将输出对象 out 作为日志记录器的输出,设置空的前缀,并且不添加任何额外的选项(flag)
return logger
}3、shuffle.go
主要包含3个方法:NewShuffle、Get、IsUint16InList,以及一个结构体Shuffle
-
type Shuffle struct
type Shuffle struct {
rl []uint16 // 乱序序列,存储的是一般轮次的乱序序列
rl2 []uint16 // 最后一轮乱序序列(无法整除时使用)
n uint16 // 乱序精度,用来限制乱序序列的长度
size uint64 //乱序序列的大小
}-
func NewShuffle(size uint64) *Shuffle
函数接收一个 size 参数作为生成乱序序列的大小。
// NewShuffle 局部乱序
func NewShuffle(size uint64) *Shuffle {
if size == 0 { //如果size为0, 返回nil
return nil
}
sf := &Shuffle{size: size}// 创建一个新的 Shuffle 结构体,设置其 size 字段为传入的值
if size > 100 {
sf.n = 100 //如果size>100,设置乱序精度为100
} else {
sf.n = uint16(size)//否则设置乱序精度为size 的 uint16 类型。
}
//通过循环填充 rl 切片,创建一般轮次的乱序序列。
//使用 rand 包生成随机数种子,对 rl 进行乱序化操作。
//如果 size 无法整除 n,则设置 rl2 切片,并生成最后一轮乱序序列
// 通用轮次
sf.rl = make([]uint16, sf.n)
for i := uint16(0); i < sf.n; i++ {
sf.rl[i] = i
}
// 洗牌方法
r := rand.New(rand.NewSource(int64(size)))
r.Shuffle(int(sf.n), func(i, j int) {
sf.rl[i], sf.rl[j] = sf.rl[j], sf.rl[i]
})
// 最后一轮无法整除时新建对应长度的rl2
t := uint16(size % uint64(sf.n))
if t != 0 {
sf.rl2 = make([]uint16, t)
for i := uint16(0); i < t; i++ {
sf.rl2[i] = i
}
r.Shuffle(int(t), func(i, j int) {
sf.rl2[i], sf.rl2[j] = sf.rl2[j], sf.rl2[i]
})
}
return sf
}-
func (sf *Shuffle) Get(index uint64) uint6
Get 方法接收一个索引 index,用于获取转换后的索引值。首先计算 t 为 index 对 sf.n 取模得到的结果。然后根据索引 index 与 n 的关系,决定使用哪个乱序序列。如果无法整除,则使用 rl2,否则使用 rl
// Get 根据索引获取转换后的索引值
func (sf *Shuffle) Get(index uint64) uint64 {
t := index % uint64(sf.n)
// 最后一轮无法整除时用rl2
if index-t+uint64(sf.n) > sf.size {
return index - t + uint64(sf.rl2[uint16(t)])
}
return index - t + uint64(sf.rl[uint16(t)])
}-
func IsUint16InList(code uint16, list []uint16) bool
IsUint16InList 函数接收一个 code 和一个 list,用于判断 list 中是否存在 code。
它遍历 list 切片,如果发现存在与 code 相等的元素,则返回 true;如果遍历完 list 后都没有找到,则返回 false。
func IsUint16InList(code uint16, list []uint16) bool {
for _, e := range list {
if e == code {
return true
}
}
return false
}














 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









