






 文章讨论了n-gram模型在处理语言建模时的局限性,如one-hot向量的维度灾难、无法泛化和理解词间关系。为了解决这些问题,提出了NNLM(神经网络语言模型),利用词向量将离散表示转换为连续表示,改善了数据稀疏性和语义表达,能预测相似上下文中的目标词。
文章讨论了n-gram模型在处理语言建模时的局限性,如one-hot向量的维度灾难、无法泛化和理解词间关系。为了解决这些问题,提出了NNLM(神经网络语言模型),利用词向量将离散表示转换为连续表示,改善了数据稀疏性和语义表达,能预测相似上下文中的目标词。
论文发表:NIPS
一:解决了什么问题?
传统的n-gram存在的问题:
对于n-gram模型,求第t个词出现的概率,不需要考虑前面所有的词,而是只考虑前n个词,计算的时间复杂度固定为100000的n次方,上式变为:
p(w(t-n+1),w(t-n+2),…,wt) = p(w(t-n+1)) p(w(t-n+2)w(t-n+1)) …p(wn|w(t-n+1)…wt-1)
n-gram模型被证明是成功可行的,但是对于n-gram模型,存在一些问题:
- 词的表示是one-hot向量,维度灾难。
- 变量为离散随机变量,一个变量的变化可能会对全局产生极大的影响,不够平滑。
- 语料库是有限的,无法识别新的相似词语/句法,比如已经学习过“猫在房间里跑”,没有学习过“狗在房间里跑”就无法识别该句,没办法实现泛化。
- 无法理解词与词之间的内在联系,无法建模出多个相似词的关系。
二:怎么解决问题,通过什么模型?
提出NNLM 模型,通过神经网络来解决语言模型问题:
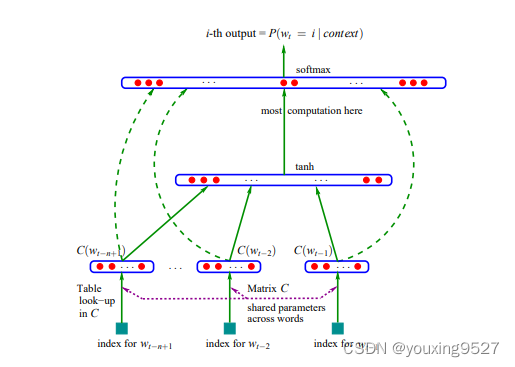
解决方案:
- 通过引入词向量,从离散表示到连续表示。
- 稠密向量各维度值是实数,不限于0和1,可以表示连续空间,可以通过计算距离度量词与词之间的相似度。类似的思想还有IR中的向量空间模型(VSM)。
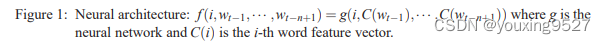 通过前面n-1个词,可以预测下方第n个词
通过前面n-1个词,可以预测下方第n个词

总结:
- 由于NNLM模型使用了低维紧凑的词向量对上文进行表示,这解决了词袋模型带来的数据稀疏、语义鸿沟等问题。显然nnlm是一种更好的n元语言模型;另一方面在相似的上下文语境中,nnlm模型可以预测出相似的目标词,而传统模型无法做到这一点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









