







哔站视频简介:
好文章:
产生背景
对于传统的机器学习来说,训练数据越多,训练出来的模型越好。你有数据,我也有数据,那将大家的数据放在一起来训练,就能得到更好的模型。然而,数据是属于用户的,他们可能并不愿意把数据交出来,如何才能实现安全、高效的 “数据” 协作呢?
补充说明:对于病人数据、电子数据这些东西都是特别敏感的,因此隐私保护是一件很重要的事情。对于医院来说,他们可能并不愿把数据共享给其它医院。
问题:
-
隐私数据泄露,如何保护
-
数据孤岛导致无法安全共享
2016 年,Google AI 团队提出让用户在自己的设备上训练模型,以上传模型参数,取代上传模型数据,一定程度上解决了数据隐私问题,这就是联邦学习的雏形。
基本定义
联邦学习(Federated Learning)是一种分布式机器学习技术(数据不集中) ,其核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练,在不需要交换本地个体或样本数据的前提下,仅通过交换模型参数或中间结果的方式,构建基于虚拟融合数据下的全局模型,从而实现数据隐私保护和数据共享计算的平衡,即“数据可用不可见”、“数据不动模型动”的应用新范式 。
目标:解决数据协作和隐私问题,在不暴露数据的情况下利用多个用户的数据
非单机训练,有多个用户节点
多个客户端在中央服务器的协调下共同训练
保持数据去中心化和分散性
简介
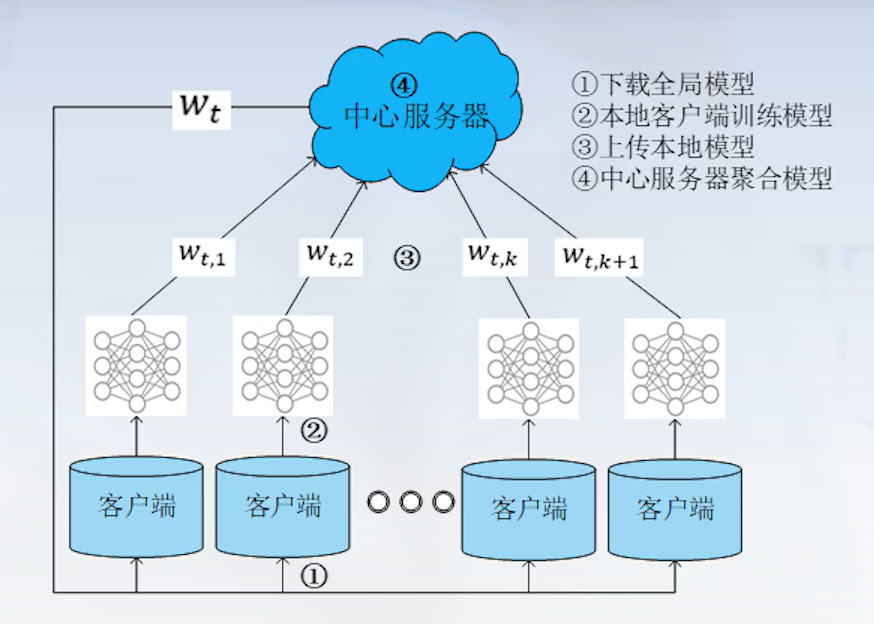
训练流程
- 下载全局模型
- 在本地客户端训练模型
- 上传本地模型
- 中心服务器聚合模型
特点
- 参与联邦学习的原始数据都保留在本地用户端,与中心服务器交换的只是本地模型
- 联合训练的全局模型被各方共享
- 最终的全局模型精读与集中式机器学习相似
面临的挑战
数据不均衡和Non-IID(非独立同分布)- 大量设备不可靠
- 通信带宽有限
分类
横向联邦学习
又称特征对齐的联邦学习,即特征重叠多,样本重叠少。
纵向联邦学习
又称样本对齐的联邦学习,即样本重叠多,特征重叠少。
关于横向联邦和纵向联邦,有一篇通俗易懂的文章:横向联邦学习 vs 纵向联邦学习
联邦迁移学习
样本和特征重合都不多,希望利用数据提高模型能力,就需要将参与者的模型和数据迁移到同一空间中运算。
经典机器学习技术试图从零开始学习每一个任务,而迁移学习技术则是在目标任务的高质量训练数据较少的情况下,将前一个任务的知识转移到目标任务上。
框架集合
- FATE
- Pysyft
- PaddleFL
- Fedlearner
- TFF
- ……
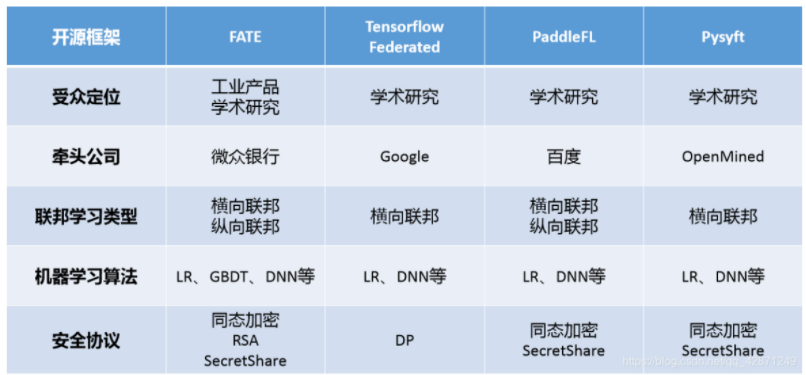
参考:联邦学习开源框架
开山之作
论文解读:
https://zhuanlan.zhihu.com/p/515756280
https://zhuanlan.zhihu.com/p/429370255
https://www.jianshu.com/p/8ced840f07fe


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









