





 PipeComet是一款基于JettyContinuation的代码框架,旨在解决开放平台的一系列问题。该框架支持四种业务场景,包括普通管道链模式、业务线程池与容器线程池分离模式、并行管道执行模式及纯粹事件驱动模式。
PipeComet是一款基于JettyContinuation的代码框架,旨在解决开放平台的一系列问题。该框架支持四种业务场景,包括普通管道链模式、业务线程池与容器线程池分离模式、并行管道执行模式及纯粹事件驱动模式。
Author:fangweng (文初)
Email:fangweng@taobao.com
Blog: http://blog.csdn.net/cenwenchu79/
Mblog: http://weibo.com/fangweng
概述
PipeComet 是在解决开放平台一系列问题的过程中不断演化的基于Jetty Continuation(Servlet 3容器也适用)的代码框架。先看看下面一张图中四个场景的演变:
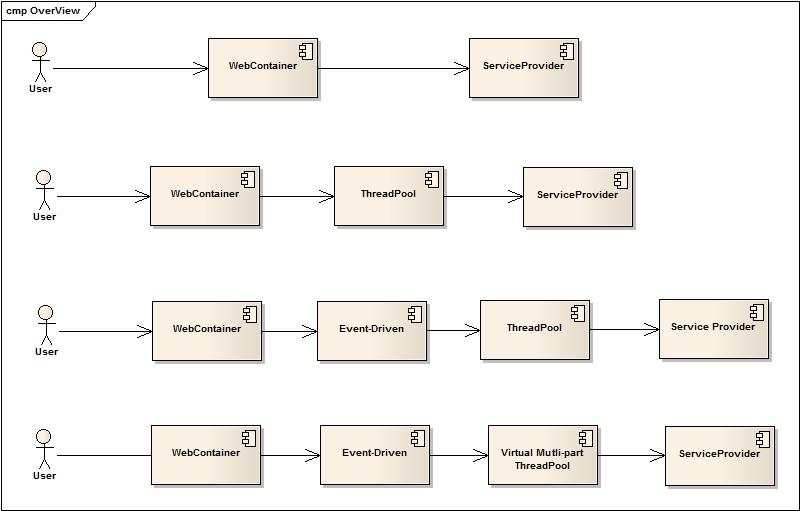
1. Servlet 3以前,一次http请求就由一个容器线程完成全部处理,容器线程的生命周期取决于整个业务处理的时间(如果后端有依赖系统,例如DB,集中式缓存,外部系统service),由此可见,并发处理请求的数量在容器线程池有限的条件下,直接用容器线程数量/rt(响应时间)即可得到。而容器线程是否真的需要有那么久的生命周期?在整个事务处理过程中是否可以被回收,等到需要时在申请?
2. 第一部分描述中,最根本的原因就是一次http请求的资源及它的生命周期完全交由容器管理,并且和容器线程一对一绑定。如果可以将请求资源和其状态与处理线程分开,生命周期不完全由容器管理,那么问题就可以得到解决。因此有了类似于Servlet3和Jetty Continuation的模式(和DB的非Auto commit很类似),期间可以引入外部线程池来接管后端业务处理,而让前端容器线程池生命周期缩短,更专注于处理连接请求和简单的请求预处理。此时可以看到,其实是将业务处理线程池与容器线程池分离,而业务线程池中可以有更灵活和轻量的处理方式。
3. 第二部分中做到的是将业务处理的线程池后移,但并没有从更本上解决本系统如何不受制于后端依赖系统的稳定性及处理能力的高低的约束。因此需要引入事件驱动模型,真正的将多种异步模式引入来解决各种场景的处理,直接或者间接的降低系统资源消耗。事件驱动模型更加彻底的将状态外移,让线程资源生命周期按需申请,大大提高了本系统的资源利用率,降低对外部系统的依赖。带来的负面效应就是逻辑复杂,容错处理要求高,响应时间变慢。
4. 最后引入了虚拟线程池,用于在多种任务执行时共享资源,同时也通过规则设置保证在竞争的情况优先级高并且重要的任务可以优先获得资源。这样也使得业务线程池有更大的业务定制化能力在其中。
下图其实是从四个角度说明了TOP的问题如何被解决,同时也简单了描述了三个组件一个模型的作用:
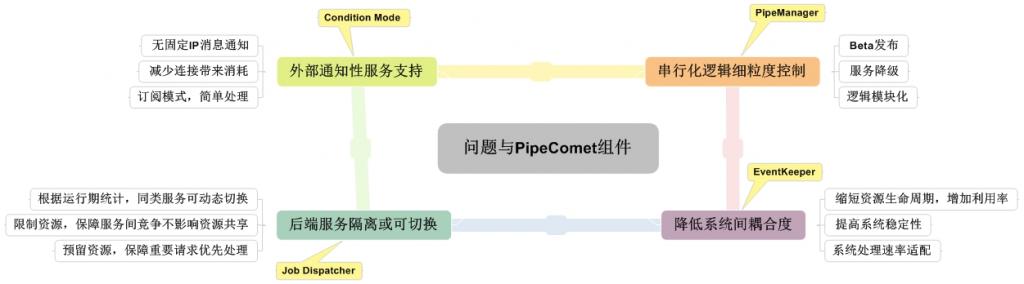
每一个特性上面的黄色小框框除了Condition mode不是组件,其他都是组件,后面具体的会谈到,几个点上都有他们各自的优势,其实也就解决了TOP的基本问题,接下去就仔细的谈谈这些设计点的细节和特性。
设计与实现的细节
首先还是要提前说明一下,参看前面的解决问题的目标,这个框架绝对不是提高并发和降低处理时间的“良药”,解耦带来的负面效果就是系统复杂度增加,响应时间可能会加长,优势在于系统之间的依赖减弱,自身的处理能力决定因素自封闭(瓶颈可以直接根据自身业务处理资源消耗情况估计出来)。
四种场景
整个PipeComet框架主要支持下面四种业务场景:
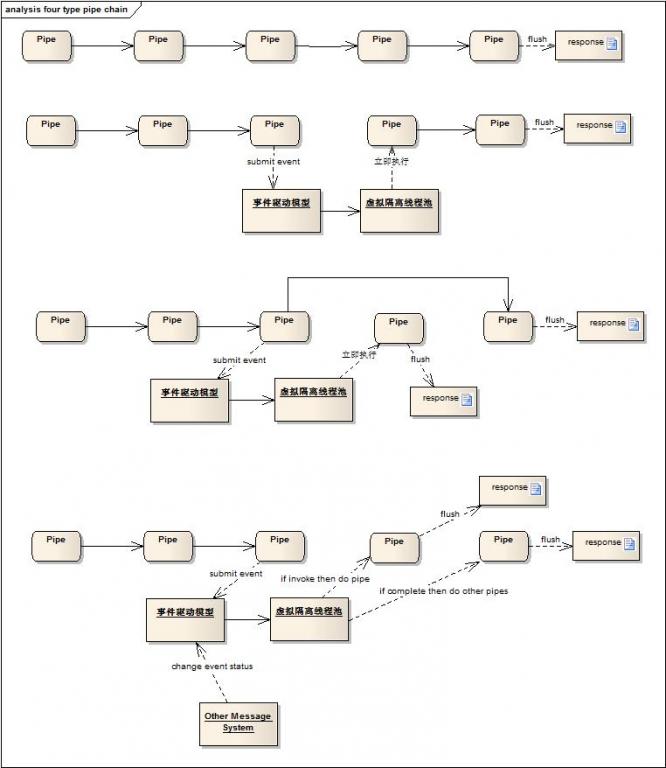
1. 第一种模式就是最普通的Pipe管道链模式,用管道化切割原本串行的业务逻辑,目标就是让开发者能够最小单元模块化业务逻辑,便于逻辑隔离,为服务降级,Beta发布等打好基础。(最挫的就是代码只有一个pipe,一大坨揉在了一起)
2. 第二种模式就是将业务线程池和容器线程池切割开来,但业务线程池的线程将会负责将后续业务阻塞式的处理完。(也许有人会说,为什么不搞成全异步模式呢,后端也通过事件回调模式来完成,这样当前业务线程池线程也可以被释放,其实这种做法在4中会说明,同时2的存在也因为很多时候后端无法做到异步化,那么往往需要采用半异步的模式,效果在于业务线程池可以做更灵活的控制,特别是加入了虚拟隔离线程池)
3. 第三种模式中,容器线程负责将主流程逻辑执行完毕,而并行管道将会被业务线程并行执行,执行过程中支持部分结果回写给客户端,实现并行处理的目的。容器将在最后一个业务线程处理完毕后关闭请求管道。
4. 第四种模式为纯粹事件驱动模式,某一个管道可以设置为条件激发的管道,此管道可以被外部事件激发(一次或者多次),最后交由外部提交结束事件的请求,结束整个请求处理。(事件如果被激发和执行一次,就是用于后端依赖系统也使可以支持异步化的场景,事件如果被激发多次执行,那么就适用于实现类似于Comet长连接Push推送结果的场景,也可以称作类RSS的数据订阅推送的长连模式)
接下来看看提到的四种场景的具体流程交互图:
1. Common Request(Pipe Mode)

补充:PipeManager负责管道的注册管理和执行,pipe之间相互隔离(互不知道对方存在),pipe之间通过context来交互数据,同时也可以根据上一个管道执行的结果判断是否需要跳过执行当前管道的业务逻辑。总的来说,Pipe化的目的就是为了从框架结构上要求开发者细粒度切割串行的业务逻辑,同时做好逻辑隔离,便于维护和控制。
2. Asyn Request
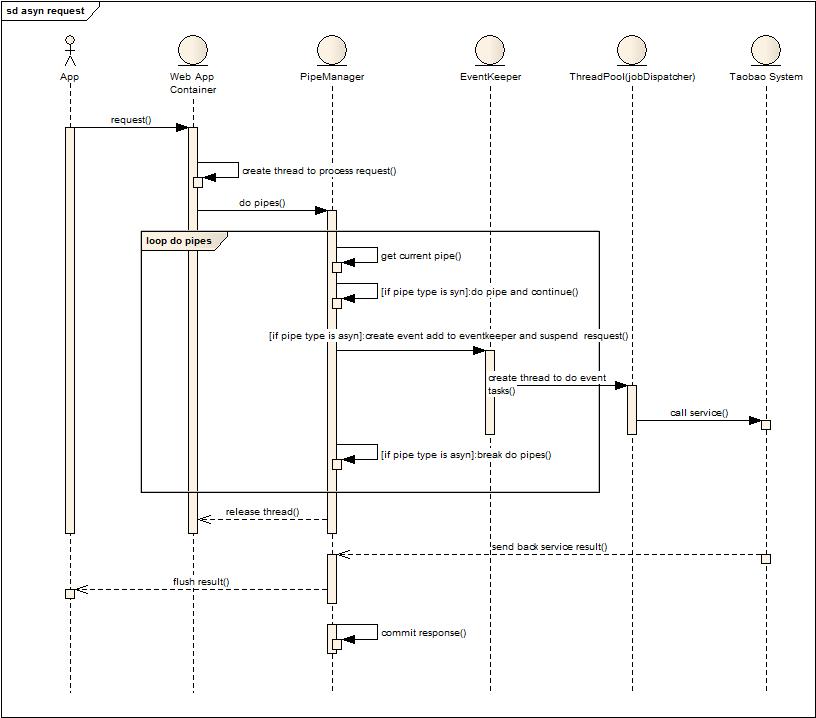
补充说明:这种模式下会发现与前面最大的差异就是当执行到asyn类型的pipe以后,后续的管道将会交由业务线程池去执行,于此同时容器线程就被回收(生命周期缩短),业务线程池执行结束后,主动将结果回刷给客户端,并且提示框架结束请求会话,释放资源。
3. Parallel Request
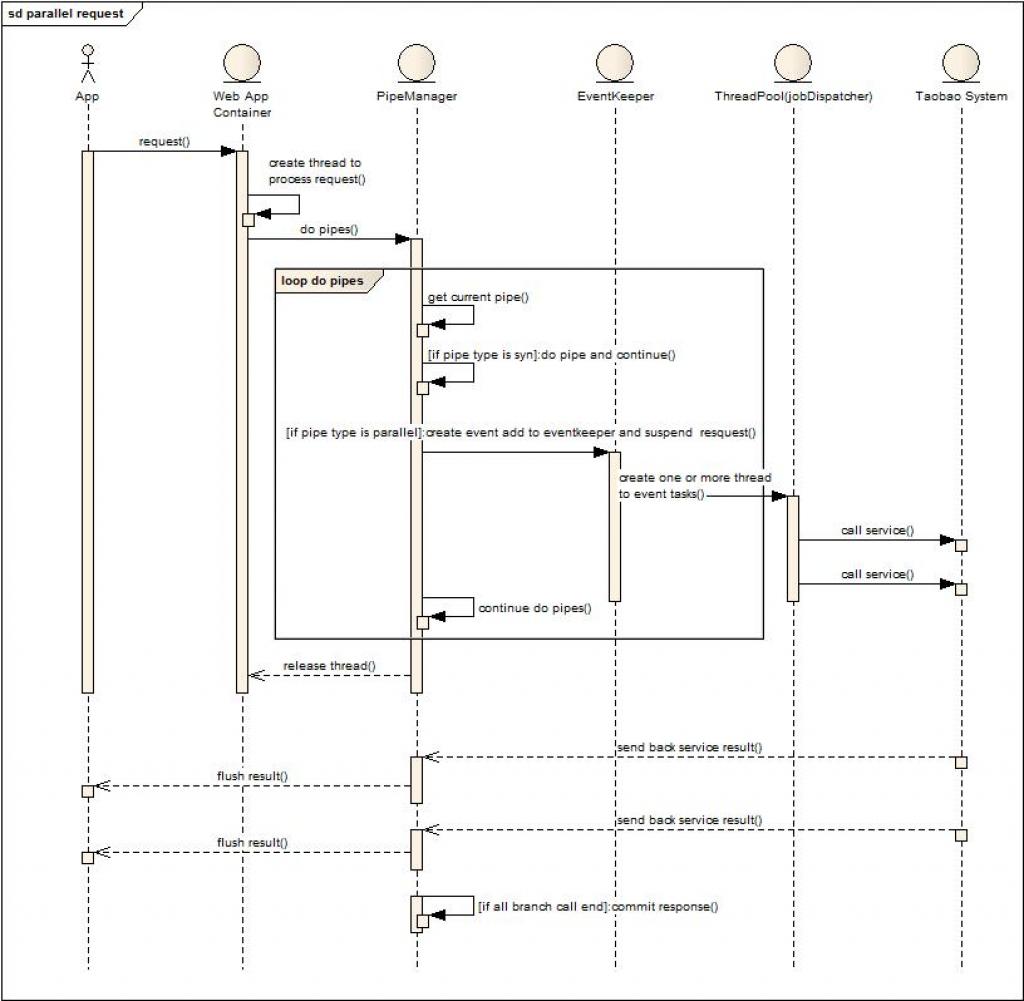
补充说明:第三种模式与第一种差别在于,首先容器线程将会负责主干pipe的执行,而分支pipe将会交给业务线程池并行执行,主干执行结果和分支执行结果都会回写给客户端,当框架发现主干和所有的分支线程任务都执行完毕后,则主动关闭连接,释放资源。
4. Condition Request
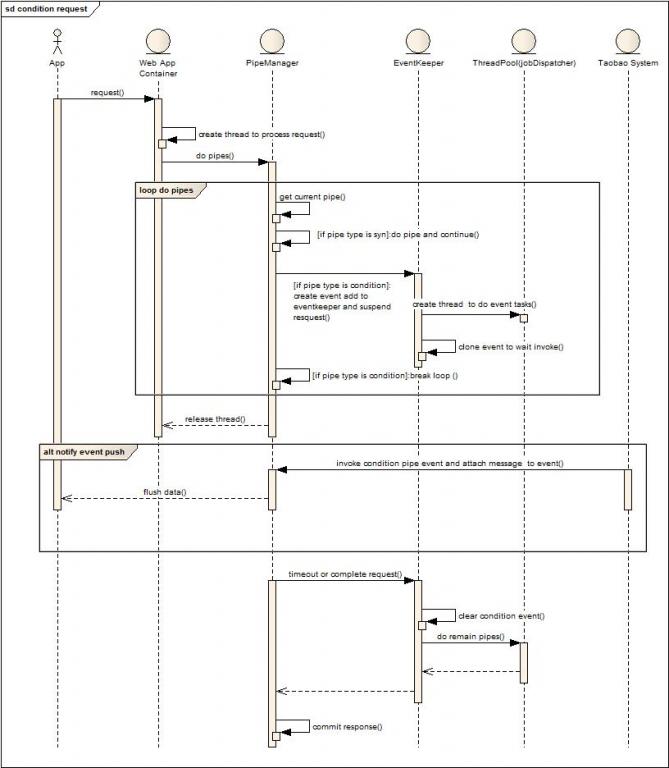
补充说明:Condition类型的管道,最大特点就是完全由外部事件激发管道的重复执行或者继续执行,使得传统意义上的无状态阻塞式Http请求可以转变成为较长时效性,数据可不定时回复的模式,适用于消息订阅和接收的逆向设计。(这里的逆向指的是接收端和发送端角色的设置)。
上面四个场景,如果从Http请求响应上来看,有这么一种转变:即时性要求很高à即时性要求一般à即时性要求很低。从系统对后端服务提供者依赖来看,转变为:强依赖à较强依赖à弱依赖。其实最终在设计角度上来看,还是在系统的可用性和效率上寻找折中和权衡,不同场景的需求不同,是否适用取决于当前系统的瓶颈及风险可承受点的差别上。
四个组件
上面流程中已经反复提到了几个起到关键作用的组件,下面就逐一的介绍这些组件的设计和实现:
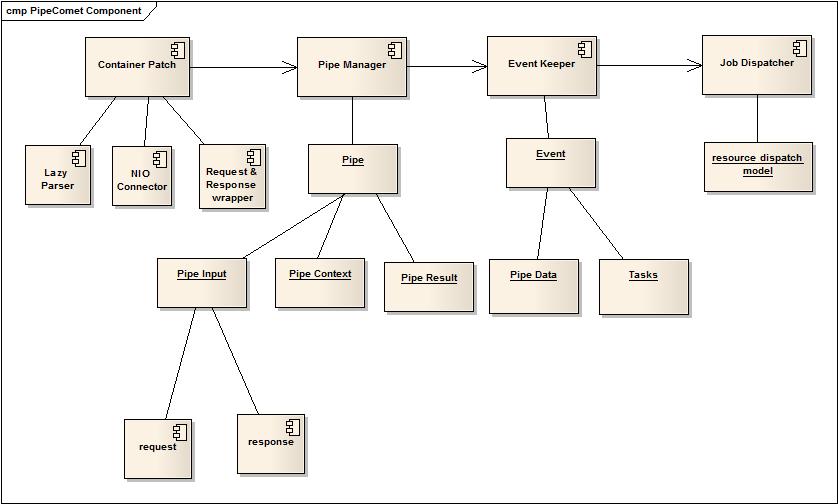
四部分组件有前后关系,同时也会相互串联,实现整体协同。
Container Patch暂时分成3部分:Lazy Parser(通过解析请求字节流来按需解析参数,节省错误请求所带来的无谓资源解析消耗),NIO Connector(当前Jetty是采用模拟阻塞模式使用非阻塞套接字处理的,在性能上还有提升空间),Request&Response Wrapper是为了支持多线程并发操作Request和Response而作的Wrapper。Container Patch是处理流程中最早使用到,且比较底层的组件。(当前Lazy Parser已经正式适用,NIO Connector的优化尚未做,Wrapper做了最简单的处理)
PipeManager是管道框架的核心管理者,它所控制的对象即为Pipe,Pipe是无状态的,每一个请求执行时Pipe会被传入PipeInput(包含了request,response),PipeResult和PipeContext,同时PipeContext通过ThreadLocal可以在管道之间交互信息。从原数据角度讲,Pipe体系框架中最重要的就是Pipe的三个要素:PipeInput,PipeResult,PipeContext。
EventKeeper是事件驱动模型的简单实现,在管道框架之后被使用,承担着管道化体系的多种异步模式事件支持,同时也可以独立成为一个事件驱动模型,内部主要处理event,其中由于和管道框架结合比较紧密,因此event中包含了pipe data和需要外部线程执行的tasks。
JobDispatcher是虚拟的共享线程池,可以通过设置规则来对不同类型请求分配线程资源,最终在资源共享的前提下,也有选择的预留资源,限制资源,差别化分配资源。
LazyParser
目标:通过按需解析Http请求字节流,最小化无效请求资源解析带来的损耗。LazyParser设计实现上并不复杂,但是在解析过程中如何合理利用receive buffer来逐段分析数据成为实现的最重要的细节点。(具体可以参看LazyParser代码)

PipeManager
目标:通过框架约束和管理开发中业务逻辑模块化,串行处理业务隔离耦合度小,最终实现服务降级,Beta发布,异步消息。
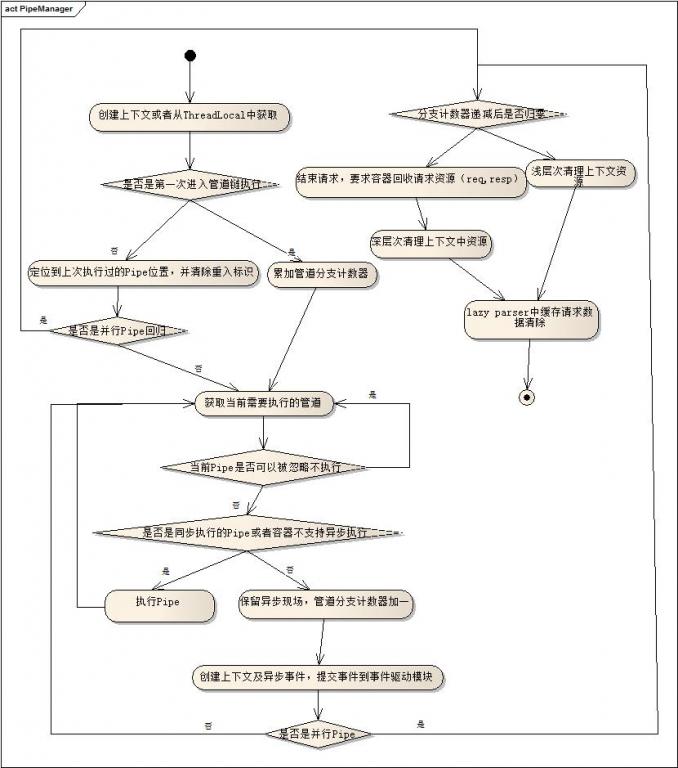
补充说明:不论是简单的同步管道链执行,还是穿插多种类型的异步管道链执行,从结构上来看都是统一的,唯一的差别就是是否会创建事件,交由外部执行,同时分支执行完毕后如何回归,并且最终所有分支执行完后结束会话,释放请求资源。(这里主要用了一个计数器来保证分支和主干在执行顺序不定的情况下依然可以根据情况提交接受请求,期间业务线程之间共享了原来单线程的ThreadLocal变量,因此也存在着部分风险)
Event Keeper
目的:Event Keeper就是一个简化的事件驱动模型,用于支撑管道框架的三种异步请求处理。
Event当前的状态迁移图如下:
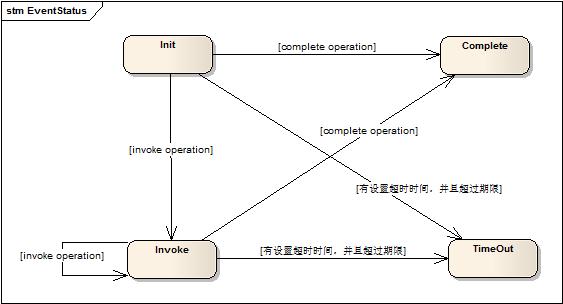
有主动被调用切换的两种状态(complete和invoke),complete表示当前执行一次立刻结束,invoke表示当前执行一次,且保存状态继续等待外部激发。timeout状态属于被动激发,必须通过后台循环检测状态才能够激发(这点在后面系统设计实现分享点滴里面会有说明如何高效的实现被动状态变更检测)
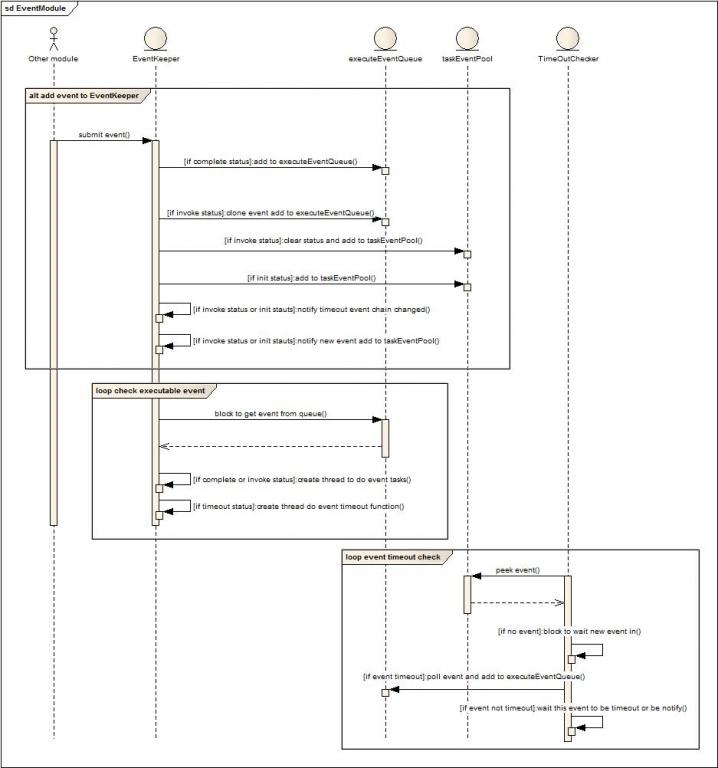
补充说明:对于立即需要执行的事件(complete,invoke)都直接将任务投递到立即执行的队列中,避免在状态队列中扫描带来的消耗。Complete和invoke通过回调系统实现的默认监听器主动实现状态变更操作,而timeout则采用较为高效的处理方式(后续设计分享中会提到)。
Virtual ThraedPool
目的:虚拟共享线程池为了线程资源统一管理,在共享的前提下也能够通过设置分配规则在资源竞争时有差别的限制,保留及分配资源。
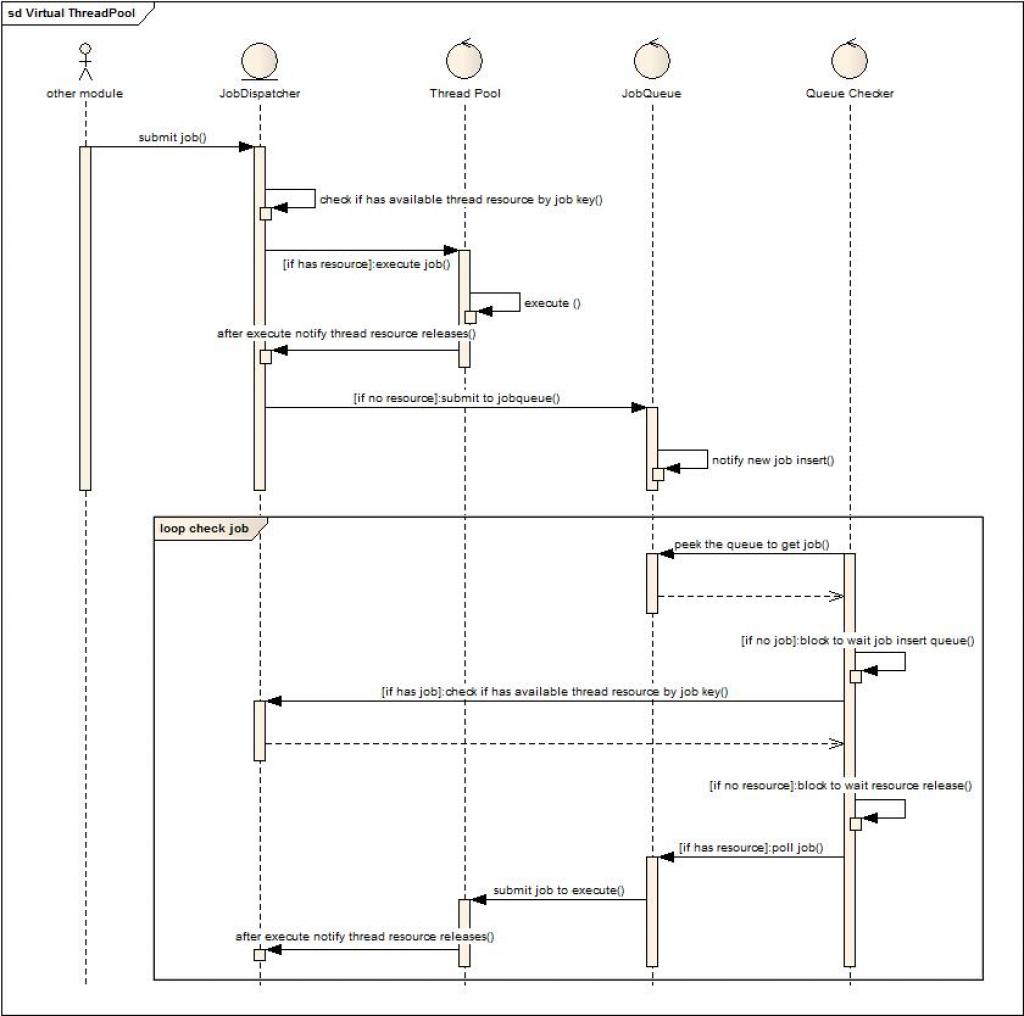
其中,Check resource avaliable在后面这张图中会表现的很清楚。当前支持的规则模型为:leave和limit两种,leave表示为某一类请求预留多少线程资源独享,limit表示在整个线程池中,此类请求最大所占的资源数量。当资源不足是被压入队列等待资源释放时,当前设计同样考虑了最小代价最快的得到资源可分配通知,避免反复循环检查和出入队列。
下图是check resource时的逻辑控制图:
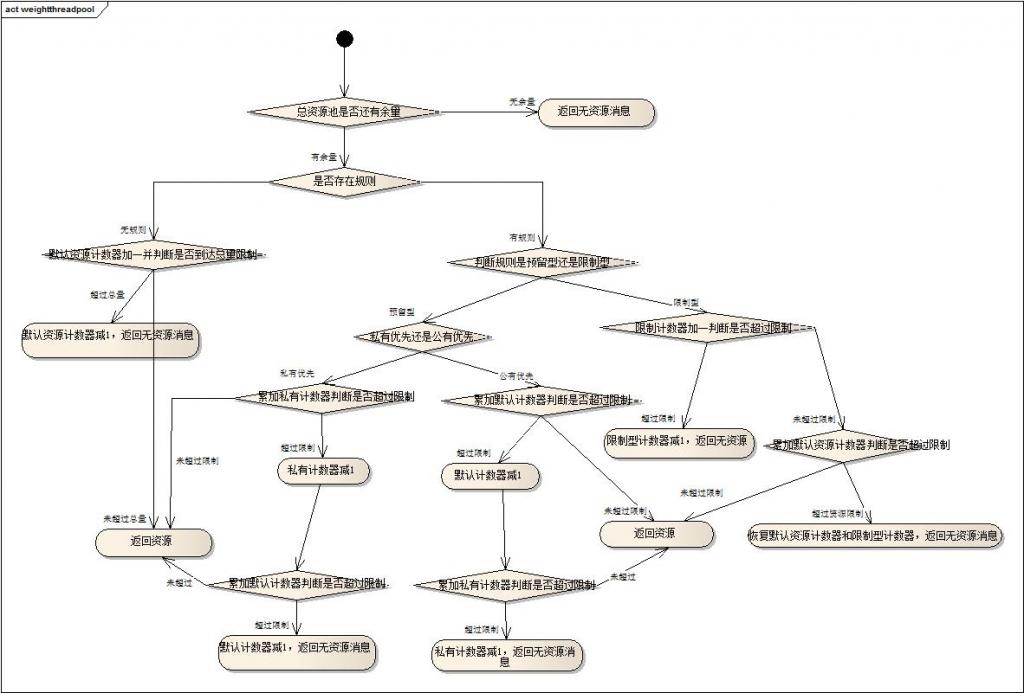
设计分享
EventKeeper
线程轮询或空转是 CPU 最大的敌人
Event一共有四个状态:init,complete,invoke,timeout。迁移如下图:

接着来看看怎么一步一步的改变一些想法:
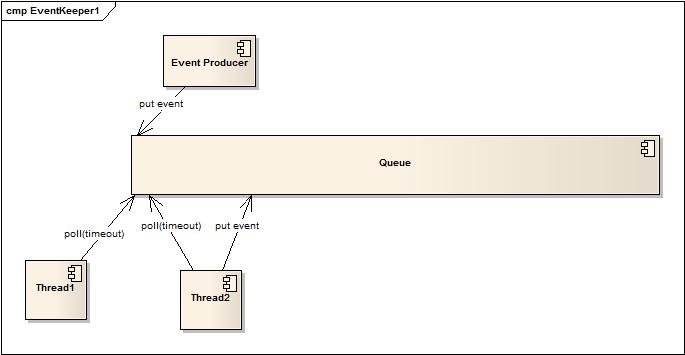
开始的时候用最简单和常规的思路:Event Producer将事件丢入队列,一个或者多个Thread采用block的方式去争夺Queue中的事件,判断事件状态,来决定是否丢入线程池执行。
问题:
1. 需要立即执行的任务(入队列时已经是complete,invoke,timeout状态)混在等待状态变更的队列中,执行效率较慢。
2. Event状态如果长久不变更,会被反复读取并塞回去。
优化后结构:

改变:将立即执行的任务与等待外部状态变更的队列分割开来,事件在入队列前就被区分对待,在Executable Queue中的事件就会被简单执行,不做任何判断,而Queue中的事件如果发生变化,线程就将事件迁移到Executable Queue。这样解决了上面提到的第一个问题,对于很多立即执行的事件消耗很小。同时状态变更队列中只剩下两种状态的事件(init,invoke)但第二个问题依旧存在。
接着在继续优化后的结果如下:

改变:
如何减少队列由于要检查状态不断地读取和插入操作?(下面描述是递进的)
A. 单线程能够在大队列下依旧能够高效处理。(poll就可以被peek替换或者用Iterator直接轮询)
B. Invoke事件的变迁往往是外部主动激发,因此可以通过对event附加上listener来让外部激发时主动做出对应的action(在两个队列中迁移event)。
C. 此时对于Thread1来说需要做的就是检查队列里面所有的event是否超时。最高效的策略:入队列时即按照超时时间排序,每次检测从头开始,发现当前事件已经不在超时,就无需继续检查后续链,同时用condition来await到最近一个timeout的时候,防止无用循环检查。(如果有较小的timeout event入队列将会唤醒等待)
具体可以参看源码。
总结来说:
1. 能够做出判断的操作,不要用复杂的轮询状态方式来做,直接激发事件处理机制。
2. 将事件状态迁移分成主动迁移和被动迁移两部分,主动迁移通过在创建事件时增加listener,在主动迁移时调用listener去做后台的一些操作(框架负责调用,业务方无需了解后续状态迁移和Action)。
3. 被动迁移部分根据其特性有效地做排序(在少量数据时可能反而有损耗),检查时根据顺序检测,用规则减少各种无效的校验。
虽然是事件驱动的一些简单的设计,但是可以适用于松散模式下的状态检查设计。
LazyParser
节省资源是海量处理最基本的要求
问题:每一次Http请求是否都需要将所有的字节流收取完毕后才执行业务?
处理方式:如果能够边解析边执行,效率更高。加入串行化逻辑被切割为(A,B,C,D四个管道顺序执行),其中A管道执行时只需要a参数,如果通过解析字节流发现a已经解析到,那么此时可以停止解析后续的字节流。
优点:
1. 如果发现a参数已经在A处理中被认为无效请求,那么后续字节流将不在接受,同时可以节省解析字节流的时间和内存消耗。
2. 外部网络状况通常会产生慢连接,此时数据包接收速度较慢,如果可以变解析边处理可能可以减少响应时间。
开放平台每天十几亿的调用量,每减少一些无效请求的消耗,每提高一点慢连接带来的损耗都能够节省不少资源。
LazyParser结构在上面组件介绍部分有说,而具体实现也主要是在字节流上的一些处理,参看代码。
注意点:
Continuation开发过程中,很重要的就是要了解整个Continuation的生命周期,以及Request和Response的生命周期,当Continuation结束后如果还依旧使用request或者response就会出现各种问题,同时在多线程并发+事件驱动模式下,更要注意回收自身ThreadLocal中的内容。整个框架中就是帮开发人员屏蔽各种异步请求事件驱动处理细节和资源管理细节。
硬件:
1, Os:Linux version 2.6.18-164.el5xen
2, Cpu:2core Intel(R) Xeon(R) CPU E5620 @ 2.40GHz
3, Memory:2G
Jvm:
-Xms1548m -Xmx1548m -XX:PermSize=96m -XX:MaxPermSize=256m -Xmn1024m -XX:+PrintCompilation -XX:+UseConcMarkSweepGC -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:+DisableExplicitGC -XX:+UseCompressedOops -XX:+DoEscapeAnalysis
容器:
采用jetty容器(容器线程池默认minThread=50,maxThreads=200)
单次压力测试时间:15分钟
压测场景
本次压测的目的,有四个
1, jetty普通模式(同步模式)与异步模式(引入业务线程池)的性能差别。
2, 有业务线程池(异步模式)前提下,引入事件驱动模型后的性能差别。(用于类似于外部Notify场景)
3, 引入业务线程池,有权重(没有达到权重设置的上限)和无权重的性能差别
4, 在1,3步的前提下服务隔离真正的起到了预期的效果。
针对上述四个目的分别做了如下的场景测试
目的:jetty普通模式(同步模式)与异步模式(引入业务线程池)的性能差别
参数设置:
业务线程池:coreThread=100,maxThreads=200,
Jetty线程池:minThread=100,maxThread=200,
使用taobao.user.get压,响应时间100ms,并发100
测试结果:
| 场景 | tps | 响应时间 | load |
| 异步模式(引入业务线程池) | 623 | 0.159 | 2.594 |
| 同步模式(使用容器线程池) | 618 | 0.157 | 2.572 |
结论:
说明在两种模式下,性能上没有影响!
目的2对应的测试场景以及结论
目的:有业务线程池(异步模式)前提下,引入事件驱动模型后的性能差别。(用于类似于外部Notify场景)
参数设置:
业务线程池:coreThreads=50,maxThreads=200,queueLength=1000
Jetty线程池:minThreads=50,maxThreads=200
使用taobao.user.get压,响应时间为100ms,并发100
测试结果:
| 场景 | tps | 响应时间 | load |
| 使用非事件驱动模型 | 464 | 0.209 | 1.6 |
| 使用事件驱动模型 | 465 | 0.208 | 0.58 |
结论:
在异步模式下(引入了业务线程池),引入事件驱动模型,对性能没有影响!
目的3对应的测试场景以及结论
目的:引入业务线程池,有权重(没有达到权重设置的上限)和无权重的性能差别
参数设置:
业务线程池:coreThreads=50,maxThreads=200,queueLength=1000
Jetty线程池:minThreads=50,maxThreads=200
权重设置,taobao.user.get允许使用的最大资源线程数200(压测时不会达到这个上限),使用taobao.user.get压,响应时间100ms,并发用户100
测试结果:
| 场景 | tps | 响应时间 | load |
| 不设置权重模型 | 467 | 0.211 | 1.664 |
| 设置权重模型(没有达到允许使用资源的最大值) | 468 | 0.21 | 1.67 |
结论:
说明在没有达到权重设置的最大值时,是否设置权重对性能没有影响。
在上述的基础上又进行了如下的测试对比,由于coreThreads是50,而并发用户是100,所以在这个场景下会有很多任务在线程池的队列中等待执行,从而影响tps和响应时间。
目的:在相同的并发请求下,对于不同的coreTheads的设置,对性能的影响。
没有设置权重模型下的对比
| 场景 | tps | 响应时间 | load |
| coreThead=150 | 610 | 0.157 | 1.828 |
| coreThread=50 | 467 | 0.211 | 1.664 |
在有权重模型下的对比:
| 场景 | tps | 响应时间 | load |
| coreThread=150 | 622 | 0.158 | 1.879 |
| coreThread=50 | 468 | 0.21 | 1.67 |
结论
在相同并发请求下,如果业务线程池(coreThread)设置的小的话部分任务会放到线程池队列中,从而影响整体服务能力和响应时间。所以coreThread不能设置的过小也不能设置的过大,过小会影响请求的响应时间,过大有空闲线程也会消耗资源。
目的:在引入异步和权重的前提下服务隔离真正的起到了预期的效果。
参数设置:
业务线程池:coreThreads=50,maxThreads=200,queueLength=500
Jetty线程池:minThreads=50,maxThreads=200
taobao.item.get模拟后端服务质量不好,并发用户50,taobao.user.get模拟后端服务质量好,并发用户50
测试结果(1):
| 场景 | tps | 响应时间 | load | 队列长度 |
| 权重模型 taobao.user.get允许使用最大资源数为10个线程 | 2 | 21.352 | 0.165 | 43 |
| 没有权重模型 | 9.5 | 5.136 | 0.165 |
|
结论:
设置了权重模型,并且资源的使用受到了限制后会影响服务的tps和响应时间(队列中的任务表示权重规则生效,虽然还有资源,但已经无法使用资源)
测试结果(2):
Taobao.item.get和taobao.user.get压测并发各50
| 场景 | api | tps | 响应时间 | load | 队列长度 |
| taobao.item.get(响应时间5s)允许使用最大资源数为10个线程;taobao.user.get(响应时间100ms)给其预留10个资源线程。 | taobao.item.get | 2.0 | 24.662 | 1.0 | 40 |
| taobao.user.get | 321 | 0.151 | 1.0 | 0 | |
| 没有资源使用限制(响应时间100ms) | taobao.user.get | 331 | 0.147 | 0.9 | 0 |
结论:
说明服务隔离已经起效,对于质量差的服务在达到其使用的上限后将会等待自己的资源可用,不会影响质量好的服务。(taobao.item.get模拟服务较差或者服务出问题的isp,taobao.user.get表示普通的isp)
测试结果(3):
规则模型:taobao.item.get:limit:10,表示taobao.item.get最多允许其使用10个线程(响应时间为5s)
taobao.user.get:leave:10,表示taobao.user.get预留10个资源,当公用资源被占用完后还有10个自己的资源可以使用(响应时间100ms),两类请求并发各为50
| 场景 | api | tps | 响应时间 | load | 队列长度 |
| taobao.item.get限制使用10个资源 | taobao.item.get | 2.0 | 24.662 | 1.0 | 40 |
| taobao.user.get预留10个资源 | taobao.user.get | 321 | 0.151 | 1.0 | 0 |
| 无限制 | taobao.item.get | 8.8 | 5.599 | 0.14 |
|
| 无限制 | taobao.user.get | 52 | 0.948 | 0.14 |
|
结论:
说明如果不做服务隔离,质量差的服务会影响质量好的服务(taobao.item.get模拟服务较差或者服务出问题的isp,taobao.user.get表示普通的isp)
最终结论:
1, 异步模式和同步模式,对性能上没有损耗。
2, 引入事件驱动模型后,对性能上也没有损耗。
3, 事件驱动模型也满足了多种业务场景的需要(并行的管道执行,串行管道执行,异步管道执行,以及notify的需要)。
4, 业务线程池的引入真正的可以做到服务的隔离,质量好的isp不会受到质量差的isp的影响。
后续工作
1. Jetty自身NIO Connector的优化
2. PipeComet的Condition模式下来实现对外Http Notify,并得到单机connection和active connection的测试最大值。
压力测试报告
压测环境















 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









