







图像分类:
目标:
已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。(图像分类问题是计算机视觉的核心问题)
困难&挑战:
- 视角变化(Viewpoint variation)
- 同一个物体,摄像机可以从多个角度来展现。
- 大小变化(Scale variation)
- 物体可视的大小通常是会变化的(不仅是在图片中,在真实世界中大小也是变化的)。
- 形变(Deformation)
- 很多东西的形状并非一成不变,会有很大变化。
- 遮挡(Occlusion)
- 目标物体可能被挡住。有时候只有物体的一小部分(可以小到几个像素)是可见的。
- 光照条件(Illumination conditions)
- 在像素层面上,光照的影响非常大。
- 背景干扰(Background clutter)
- 物体可能混入背景之中,使之难以被辨认。
- 类内差异(Intra-class variation)
- 一类物体的个体之间的外形差异很大,比如椅子。这一类物体有许多不同的对象,每个都有自己的外形。

数据驱动方法:
如何写一个图像分类的算法呢?这和写个排序算法可是大不一样。怎么写一个从图像中认出猫的算法?搞不清楚。因此,与其在代码中直接写明各类物体到底看起来是什么样的,倒不如说我们采取的方法和教小孩儿看图识物类似:给计算机很多数据,然后实现学习算法,让计算机学习到每个类的外形。这种方法,就是数据驱动方法。
图像分类流程:
图像分类就是输入一个元素为像素值的数组,然后给它分配一个分类标签。完整流程如下:
- 输入:
- 输入是包含N个图像的集合,每个图像的标签是K种分类标签中的一种。这个集合称为训练集。
- 学习:
- 这一步的任务是使用训练集来学习每个类到底长什么样。一般该步骤叫做训练分类器或者学习一个模型。
- 评价:
- 让分类器来预测它未曾见过的图像的分类标签,并以此来评价分类器的质量。我们会把分类器预测的标签和图像真正的分类标签对比。毫无疑问,分类器预测的分类标签和图像真正的分类标签如果一致,那就是好事,这样的情况越多越好。
图像分类数据集:
CIFAR-10
10个类(50000张图片的训练集+10000张图片的测试集,每张图片的大小是32*32,RGB颜色)
距离度量:
L1距离(曼哈顿距离)
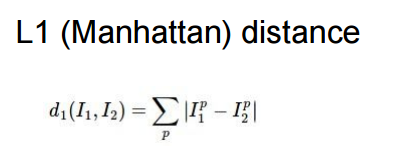
L2距离(欧几里得距离)
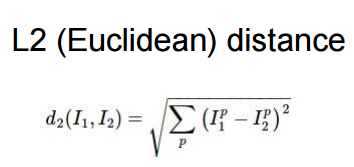
L1与L2的比较:在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。L1和L2都是在p-norm常用的特殊形式。
k-Nearest Neighbor分类器(实际中很少用):
它的思想很简单:与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。所以当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。从直观感受上就可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。
Nearest Neighbor分类器易于理解,实现简单。其次,算法的训练不需要花时间,因为其训练过程只是将训练集数据存储起来。然而测试要花费大量时间计算,因为每个测试图像需要和所有存储的训练图像进行比较,这显然是一个缺点。在实际应用中,我们关注测试效率远远高于训练效率。其实,我们后续要学习的卷积神经网络在这个权衡上走到了另一个极端:虽然训练花费很多时间,但是一旦训练完成,对新的测试数据进行分类非常快。这样的模式就符合实际使用需求。
Nearest Neighbor分类器的计算复杂度研究是一个活跃的研究领域,若干Approximate Nearest Neighbor (ANN)算法和库的使用可以提升Nearest Neighbor分类器在数据上的计算速度(比如:FLANN)。这些算法可以在准确率和时空复杂度之间进行权衡,并通常依赖一个预处理/索引过程,这个过程中一般包含kd树的创建和k-means算法的运用。
Nearest Neighbor分类器在某些特定情况(比如数据维度较低)下,可能是不错的选择。但是在实际的图像分类工作中,很少使用。因为图像都是高维度数据(他们通常包含很多像素),而高维度向量之间的距离通常是反直觉的。
KNN实际应用过程:
如果你希望将k-NN分类器用到实处(最好别用到图像上,若是仅仅作为练手还可以接受),那么可以按照以下流程:
- 预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。在后面的小节我们会讨论这些细节。本小节不讨论,是因为图像中的像素都是同质的,不会表现出较大的差异分布,也就不需要标准化处理了。
- 如果数据是高维数据,考虑使用降维方法,比如PCA或随机投影。
- 将数据随机分入训练集和验证集。按照一般规律,70%-90% 数据作为训练集。这个比例根据算法中有多少超参数,以及这些超参数对于算法的预期影响来决定。如果需要预测的超参数很多,那么就应该使用更大的验证集来有效地估计它们。如果担心验证集数量不够,那么就尝试交叉验证方法。如果计算资源足够,使用交叉验证总是更加安全的(份数越多,效果越好,也更耗费计算资源)。
- 在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
- 如果分类器跑得太慢,尝试使用Approximate Nearest Neighbor库(比如FLANN)来加速这个过程,其代价是降低一些准确率。
- 对最优的超参数做记录。记录最优参数后,是否应该让使用最优参数的算法在完整的训练集上运行并再次训练呢?因为如果把验证集重新放回到训练集中(自然训练集的数据量就又变大了),有可能最优参数又会有所变化。在实践中,不要这样做。千万不要在最终的分类器中使用验证集数据,这样做会破坏对于最优参数的估计。直接使用测试集来测试用最优参数设置好的最优模型,得到测试集数据的分类准确率,并以此作为你的kNN分类器在该数据上的性能表现。
用于超参数调优的验证集:
k-NN分类器需要设定k值,那么选择哪个k值最合适的呢?我们可以选择不同的距离函数,比如L1范数和L2范数等,那么选哪个好?还有不少选择我们甚至连考虑都没有考虑到(比如:点积)。所有这些选择,被称为超参数(hyperparameter)。在基于数据进行学习的机器学习算法设计中,超参数是很常见的。一般说来,这些超参数具体怎么设置或取值并不是显而易见的。
你可能会建议尝试不同的值,看哪个值表现最好就选哪个。好主意!我们就是这么做的,但这样做的时候要非常细心。特别注意:决不能使用测试集来进行调优。当你在设计机器学习算法的时候,应该把测试集看做非常珍贵的资源,不到最后一步,绝不使用它。如果你使用测试集来调优,而且算法看起来效果不错,那么真正的危险在于:算法实际部署后,性能可能会远低于预期。这种情况,称之为算法对测试集过拟合。从另一个角度来说,如果使用测试集来调优,实际上就是把测试集当做训练集,由测试集训练出来的算法再跑测试集,自然性能看起来会很好。这其实是过于乐观了,实际部署起来效果就会差很多。所以,最终测试的时候再使用测试集,可以很好地近似度量你所设计的分类器的泛化性能(在接下来的课程中会有很多关于泛化性能的讨论)。
把训练集分成训练集和验证集。使用验证集来对所有超参数调优。最后只在测试集上跑一次并报告结果。测试数据集只使用一次,即在训练完成后评价最终的模型时使用。
好在我们有不用测试集调优的方法。其思路是:从训练集中取出一部分数据用来调优,我们称之为验证集(validation set)。以CIFAR-10为例,我们可以用49000个图像作为训练集,用1000个图像作为验证集。验证集其实就是作为假的测试集来调优。
交叉验证:
有时候,训练集数量较小(因此验证集的数量更小),人们会使用一种被称为交叉验证的方法,这种方法更加复杂些。还是用刚才的例子,如果是交叉验证集,我们就不是取1000个图像,而是将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。
在实际情况下,人们不是很喜欢用交叉验证,主要是因为它会耗费较多的计算资源。一般直接把训练集按照50%-90%的比例分成训练集和验证集。但这也是根据具体情况来定的:如果超参数数量多,你可能就想用更大的验证集,而验证集的数量不够,那么最好还是用交叉验证吧。至于分成几份比较好,一般都是分成3、5和10份。
扩展阅读:
强烈推荐两篇文章~~~















 1978
1978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









