






文章在第五节结束之后,算法的大致流程就阐述完备了。第六节说明了集群成员变更的处理,第七节之后呢文章的意义对我来说就不大了,故最后就对第六节进行精度。
更改集群配置是十分不安全的,一次以原子方式切换所有服务器是不可能的,因此集群可能在转换期间分裂为两个独立的主体。
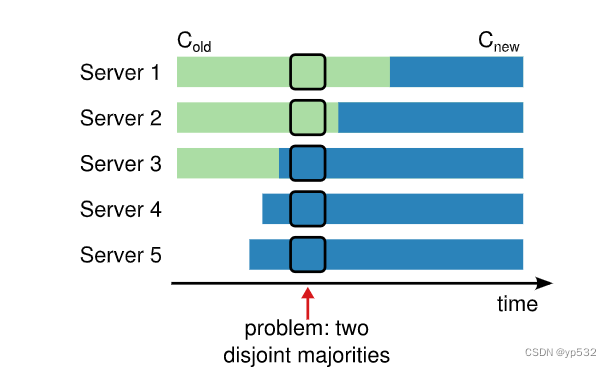
图十说明在集群从3台服务器增长到5台服务器时在某个时间点上,可以选出两个不同的领导人担任同一任期,一个拥有多数旧配置(old),另一个拥有多数新配置(new)。
为了解决这个问题,raft提出了联合共识(joint consensus),联合共识保证:
1.日志条目复制到所有配置的服务器中。
2.来自任一配置的任何服务器都可以作为leader。
3.选举和承诺请求要求在新旧配置中分别获得大多数的投票。
联合共识允许各个服务器在不同的时间在配置之间转换,而不影响安全性。此外,联合共识允许集群在整个配置更改过程中继续为客户机请求提供服务。
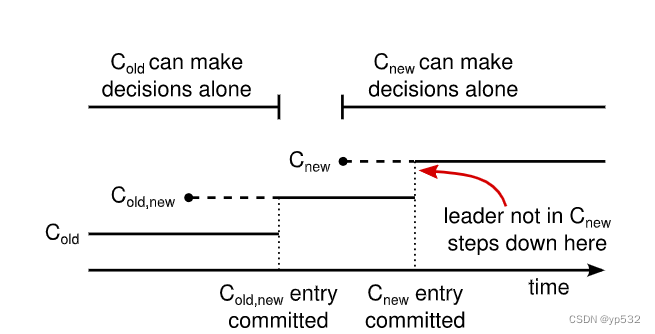
如图11所描述:虚线表示已创建但未提交的配置项,实线表示最新提交的配置项。leader首先在其日志中创建联合共识(old,new)配置条目,并将其提交给联合共识节点(大部分老节点的leader和大部分新节点的leader)。然后它创建新条目并将其提交给大部分新配置节点。在任何时间点上,老节点和新节点都不可能同时独立做出决定。
对于重新配置,还有三个问题需要解决。
问题一:新服务器最初可能不存储任何日志条目。如果在此状态下将它们添加到集群中,则可能需要相当长的时间才能赶上进度,在此期间可能无法提交新的日志条目。
问题二:集群领导者可能不是新配置的一部分。在这种情况下,leader一旦提交了新日志条目,就会退出(返回到follower状态)。这意味着当leader在管理一个不包括它自己的集群时会有一段时间(当它提交新日志条目时);它复制日志条目,但不以大多数计算自己是否通过。
问题三:被删除的服务器可能会破坏集群。这些服务器将不会接收心跳,因此它们将超时并开始新的选举。然后他们将发送带有新term数的RequestVote rpc,这将导致当前的leader恢复到follower状态。最终将选出新的领导者,但被删除的服务器将再次超时,这个过程将重复,导致可用性较差。
raft给出的解决方案:
解决一:Raft在配置更改之前引入了一个额外的阶段,在这个阶段中,新服务器作为非投票成员加入集群(leader将日志条目复制给它们,但不考虑大多数)。一旦新服务器跟上了集群的其余部分,就可以按照上面描述的那样进行重新配置。
解决二:leader转换发生在新条目提交时,因为这是新配置可以独立操作的第一个点(从新节点中始终可以选择leader)。在此之前,可能只有来自旧节点的服务器才能被选为领导者。
解决三:当服务器认为当前leader存在时,会忽略RequestVote rpc。具体来说,如果服务器在从当前领导人那里听到的最小选举超时内收到RequestVote RPC,它就不会更新它的term或投票。这不会影响正常的选举,在这种情况下,每个服务器在开始选举之前至少要等待一个最小的选举超时。
In Search of an Understandable Consensus Algorithm的精度就到这里,如果在上完老师的课后有什么更改和补充会发在后续的课程报告。















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









