







本文目录
1 客户-服务器体系
这里将一直提供相应服务或者应答请求的主机称为服务端,将发起请求的主机称为客户端。其中,web、邮件传输、域名解析等应用均采用客户-服务的结构,由一个主机运行服务程序并一直保持运行状态,即服务端,而各种端系统,即客户端,通过协议报文向服务端发送请求,完成不同主机应用程序之间的交互。这种结构最大的特点是客户端之间不进行直接通信,服务端具有固定的ip地址。
1.1 HTTP
HTTP (HyperText Transfer Protocol) 是一种面向连接的无状态协议,面向连接表示当HTTP服务端和客户端要想完成交互,完成请求-响应的数据交互,必须先建立连接(这里主要指的是TCP的三次握手);无状态协议指的是无论客户端向服务端发送多少次请求,HTTP的服务端都不会保留客户端的相关信息,并对每一次的请求都作一次响应。
1.1.1 非持续连接与持续连接
前面说过,HTTP是一种面向连接的协议,即当客户端和服务段建立连接之后,才可以进行数据的交互-请求和响应。那么,所有的请求和响应是经过一次建立的连接完成的还是每次都需要重新进行建立连接呢?基于此,将HTTP就分为非持续连接与持续连接两种。
首先对于非持续连接,这里通过一次客户端和服务端的交互来进行描述。假设现在客户端向服务端请求一个包含10个对象的web页面,客户端每次请求一个对象,并且假设这10个对象均位于同一个服务器中,对于请求的第一个对象Obj_1,客户首先发起建立连接的请求,然后等待服务端的应答,收到应答后接着发起对Obj_1的请求,服务端将Obj_1对象的内容封装在响应报文中发送给客户端,之后服务端会通知断开连接,客户端在收到响应报文后断开连接。(这里描述了两次断开连接,其中第一个并没有真正断开来连接,在后续的学习笔记中再描述)。整个过程如下图所示,接着剩下的9个对象均采用这种方式进行传输。从中可以看出,每次建立连接只传输一个对象,需要得到完整的web页面则需要建立10次连接。
而对于持续连接来说,对于一个web页面的请求可以通过建立的一次连接完成。将完成一次请求-响应所用时间称为RTT(Round-Trip Timer),对于一个包含N个对象的web页面,只考虑请求和响应的时间,对于非持续连接,则需要(2NRTT)时间,而持续连接只需要((N+1)*RTT)时间。

1.1.2 HTTP 报文格式
HTTP报文有两种:请求报文和响应报文。
请求报文
GET /photo/0001/2009-10-01/5KHL6EHM0UQ20001.JPG HTTP/1.1
Host: img4.cache.netease.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36
Accept: image/webp,image/apng,image/*,*/*;q=0.8
Accept-Encoding: gzip, deflate\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
……
上面是利用wireshark抓取的HTTP请求报文,这里截取了其中的一部分,首先将第一行称为请求行,它包括了方法字段、url字段和HTTP版本号字段。方法字段除上面提到的GET,还包括POST、HEAD、PUT和DELETE,有兴趣的小伙伴可以去查阅相关资料比较它们的区别,常规的HTTP请求报文都使用GET方法。下面的key-value表示请求头部信息,Host指明了请求对象所在的主机,Connection表明当其使用的是持续连接还是非持续连接,接着是代理,指明代理的原因是HTTP服务器可以根据代理的类型发送相同对象的不同版本,后面就不一一描述了。除请求行和请求头部以外,剩下的就是携带的请求数据。下图表示了一个请求报文的通用格式。

响应报文
HTTP/1.1 200 OK
Date: Sun, 05 Jan 2020 00:43:05 GMT
Content-Type: image/jpeg
Content-Length: 244836
Connection: keep-alive
Server: nginx
Last-Modified: Thu, 01 Oct 2009 03:03:05 GMT
Cache-Control: max-age=5184000
……
上面是捕获的对应的响应报文,与请求报文相对应,响应报文也包括三个部分:状态行、响应头部和响应数据。状态行包括HTTP版本号、状态码和状态描述组成,如“HTTP/1.1 200 OK”。下表显示了日常生活中常见的状态码信息。响应头部包括响应日期,响应的内容、大小,连接方式、服务器类型,响应对象创建或者修改的时间等。

下图表示了一个通用的响应报文信息,从图中可以看出,无论是请求报文还是响应报文,为了区分头部数据和携带的数据,会在二者之间添加一个空行。

1.2.3 HTTP扩展
(1)cookie
前面描述过HTTP是一个无状态的协议,即HTTP服务器不会保存请求的相关信息。但是存在这样的一个现象,比如你登陆一个电商网站,首次登陆需要输入用户名和密码,但是一个礼拜后你没有输入用户名密码却可以点击购物,并且显示你已经登陆了,这就是cookie的作用。
实现cookie需要4个组件协同工作:
- 请求报文携带一个cookie字段;
- 响应报文携带一个cookie字段;
- 客户端存在cookie管理组件,一般由浏览器进行管理;
- web站点存在一个数据库。
下图简单描述了cookie的工作过程,有兴趣可以参考这篇博客。。

(2)web缓存
对于一个存在web缓存的代理服务器,称之为缓存器,假设浏览器正在请求某个对象,将会发生下面的事件:
- 浏览器建立一个到缓存器的连接,然后向缓存器发送一个HTTP请求。
- 缓存器收到该请求后,会在本地查看是否存在该对象的副本,如果存在则向浏览器回复HTTP应答。
- 如果缓存中不存在请求对象的副本,则缓存器会向该对象的初始服务器发送HTTP请求,服务器在收到请求后会向缓存器给出应答。
- 缓存器接收到应答后,会在本地存储一个该对象的副本,并向浏览器发送该副本。
通过使用缓存,可以减小请求响应的时间,因为缓存器一般离客户端更近,因此,从缓存缓请求内容比从初始服务器所用时间更少,呈现速度更快。其次,缓存器中的副本被多次使用,也能降低用户对于网络带宽的要求。但是这里存在一个问题:如何保证缓存器中的副本都是最新的呢?
这里就不得不提到HTTP协议的一种机制,即允许缓存器证实它的副本是最新的,这种机制被称为条件GET,即在请求报文的请求头部字段里面包含一个 “if-midified-Since” 字段,那么这就是一个条件GET。
以上面的例子为例,缓存器现在存在一个对象的副本,过几天后,当浏览器再次访问这个对象的时候,由于初始服务器上的该对象可能已经发生变化,这个时候,缓存器就会向初始服务器发送一个条件GET,if-midified-Since" 字段的值等于上一次响应报文中响应头部 "Last-Modified"字段的值,"Last-Modified"表示请求对象最后一次修改的时间,请求头信息如下:
GET /photo/0001/2009-10-01/5KHL6EHM0UQ20001.JPG HTTP/1.1
Host: img4.cache.netease.com
if-midified-Since: Thu, 01 Oct 2009 03:03:05 GMT
此时如果服务器中该对象没有发生改变,则会向缓存器发送一个状态码为304的响应报文,该报文不包含请求对象的数据,如下:
HTTP/1.1 200 OK
Date: Sun, 05 Jan 2020 01:30:15 GMT
Server: nginx
(empty entity body)
否则会发送一个状态码为200的响应报文,将最新的该对象的版本发送给缓存器。
1.2 STMP
电子邮件早在互联网兴起的时候就已经是最为流行的应用程序之一,其在Internet上发送和接收的原理与现在的快递十分的相似,寄快递的时候,我们首先要找到一家快递站点,在填写完收件人姓名、地址等等之后,包裹就被寄到了收件人所在地的快递站点,收件人取快递的时候就必须去这个站点才能取出。同样的,当我们发送电子邮件时,这封邮件是由邮件发送服务器(任何一个都可以)发出,并根据收信人的地址判断对方的邮件接收服务器而将这封信发送到该服务器上,收信人要收取邮件也只能访问这个服务器才能完成,下面主要介绍简单邮件传输协议-STMP。
1.2.1 STMP 原理简介
前面通过一个例子模拟了电子邮件在网络中的运行过程,下图描述了邮件报文在网络中传播的过程。
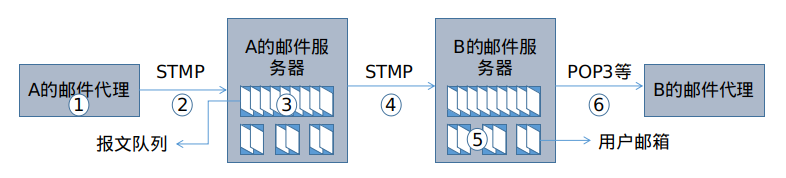
- A调用其端系统上的邮件代理撰写报文,并提供接收方B的邮件地址,然后使用代理发送报文。
- A的邮件代理把报文发给他的邮件服务器,在邮件服务器中该报文被放到报文队列中等待发送。
- 当运行在A的邮件服务器上的STMP客户端发现该报文时,该客户端会创建一个连接,用以连接到运行在B的邮件服务器中的STMP服务器。
- 建立连接以后,STMP客户端会发送该报文。
- 运行在B的邮件服务器中的STMP服务器收到报文后,会将该报文放入B的邮箱中。
- B可以通过使用其端系统上邮件代理阅读该报文。
STMP协议具有两个显著的特点。
- 首先,STMP客户端与相应的服务器建立连接时,一般不使用中间邮件服务器,即STMP客户端与服务端之间直接建立连接,如果此时服务端没有开机,那么该报文会一直保存在STMP客户端所在的邮件服务器中,并且会不断进行新的尝试。由此可见,发送的邮件仅仅会经过接收双方的邮件服务器,不会经过中间邮件服务器。
- 其次,与HTTP协议相同,这两个协议都是从一台主机向另外一台主机发送文件。但不同的是,HTTP是一个拉协议,用户使用HTTP协议从服务器拉取文件,建立连接是由想要接收文件的主机发起。而STMP是一个推协议,发送邮件服务器把文件推送到接收邮件服务器,建立连接是由想要发送的文件发起。
当邮件到达B的邮件服务器时,此时B的邮件代理想要获取其在B的邮件服务器上的邮件时,则需要使用拉协议,因此其并不使用STMP协议,而是使用POP3、IMAP和HTTP等。
1.2.2 STMP 报文
SMTP主要使用一些命令和应答在邮件服务器之间进行之间传输报文。如下图所示,为SMTP主要的命令和应答:

下面是使用QQ邮箱做的一个例子,"C"表示客户端,"S"表示服务端。
C:telnet smtp.qq.com 25
Trying 183.232.95.86...
Connected to smtp.qq.com.
Escape character is '^]'.
S:220 smtp.qq.com Esmtp QQ Mail Server
C:helo xiaoyu
S:250 smtp.qq.com
C:auth login
S:334 VXNlcm5hbWU6
C:账号(BASE64加密)
S:334 UGFzc3dvcmQ6
C:密码(BASE64加密)
S:235 Authentication successful
C:mail from:<198xxx7736@qq.com>
S:250 Ok
C: rcpt to:<128xxx3499@qq.com>
S:250 Ok
C:data
S:354 End data with <CR><LF>.<CR><LF>
Date: 12 Apr 2020 17:22:29
From:198xxx7736@qq.com
To:128xxx3499@qq.com
Subject:test
test
.
250 Ok: queued as
RFC文档的对STMP的报文格式做了下述限制,因此报文的格式大致如下所示。
- 所有报文都是由ASCII码组成
- 报文由报文行组成,各行之间用回车(CR)、换行(LF)符分隔
- 报文的长度不能超过998个字符
- 报文行的长度≤78个字符之内(不包括回车换行符)
- 报文中可包括多个首部字段和首部内容
- 报文可包括一个主体,主体必须用一个空行与其首部分隔
- 除非需要使用回车与换行符,否则报文中不使用回车与换行符

1.3 DNS
在网络中,标识主机的方法主要有两种,一种是根据主机名标识,如www.baidu.com、www.google.com等,另一种是常见的IP地址。域名系统DNS在这中间起着将主机名转换为IP地址的任务。DNS一般由两个部分构成,一个是由分层DNS服务器实现的分布式数据库,另一个是使得主机能够查询该分布式数据库的应用层协议。
1.3.1 DNS工作机制
DNS使用了分布式、层次数据库,其主要包括以下三类服务器,根服务器、顶级域服务器(TLD)、权威服务器,它们的层次结构如下图所示。
- 根DNS服务器:提供TLD服务器的IP地址。
- 顶级域DNS服务器(TLD):com、org和edu都是顶级域,它们提供权威服务器的IP地址。
- 权威DNS服务器:权威名称服务器是域名查询中的最后一站。如果权威名称服务器可以访问所请求的记录,它将返回请求的主机名的IP地址 。
- 本地DNS服务器:每个ISP都有一台本地DNS服务器。

假设网络中一主机 想知道主机www.163.com的IP地址,那么主机上的DNS客户端以及各级域名服务器将会进行如下操作:
- 主机上的DNS客户端先向本地DNS服务器发送DNS查询报文;
- 本地DNS服务器缓存中存在请求主机名对应的IP地址,则相应报文中返回该地址,否则向根服务器发送查询报文;
- 该根服务器发现其.com前缀,就向本地服务器发送负责com的TLD的IP地址列表;
- 本地服务器则再次向这些TLD服务器发送查询报文;
- TLD服务器注意到163.com的前缀,就向地服务器发送负责163.com的权威服务器的IP地址;
- 本地服务器则再次向权威服务器服务器发送查询报文;
- 权威服务器经查询,然后使用www.163.com的IP地址进行相应;
- 本地服务器收到响应后,使用获得的IP进行相应,并写入自己的缓存中。

DNS查询分为递归查询和迭代查询。
递归查询:如果主机所询问的本地域名服务器不知道被查询域名的IP地址,那么本地域名服务器就以DNS客户的身份,向其他根域名服务器继续发出查询请求报文(即替该主机继续查询),而不是让该主机自己进行下一步的查询,如下图中1步骤所示,。因此,递归查询返回的查询结果要么是所要查询的IP地址,要么报错。
迭代查询:本地域名服务器向根域名服务器查询,根域名服务器告诉它下一步到哪里去查询,然后它再去查,每次它都是以客户机的身份去各个服务器查询
1.3.2 DNS记录和报文
资源记录
在DNS服务器存储了资源记录,每个DNS应答都包括了一条或者多条资源记录,每条资源记录包含以下字段(Name, Value, Type, TTL),TTL记录了资源记录应当从缓存中删除的时间,暂不考虑,下面介绍了几种常见的资源类型。
- 如果 Type = A,那么Name就是主机名,Value就是主机的IP 地址。因此,一个A类型的记录提供了一个标准的主机名到IP地址的映射;
- 如果 Type = NS,那么Name是域名(domain,例如foo.com), 值是这个域名的权威DNS服务器。例如(foo.com, dns.foo.com, NS)。
- 如果 Type = CNAME,那么Name是别称,Value是规范名称,用来查询别称的规范主机名,例如(foo.com, relay1.bar.foo.com, CNAME) 是一个 CNAME 记录。
- 如果 Type = MX,那么Name是邮件服务器的别称,Value是邮件服务器的规范名称,例如(foo.com, mail.bar.foo.com, MX)。
报文格式
下图是访问河海大学使用wiresharp捕获的DNS响应报文,图中已经对报文中的字段进行了标记。

DNS只有查询和回答报文,并且两种报文有着相同的格式,如下图所示,
- 首部区域占12个字节,包括6个部分。开始的两个字节标识符被用来匹配发送的请求和接受到的回答。标志占两个字节,分为8个部分,这里不具体描述。数量字段占8个字节,包括问题数、回答RR数、权威RR数和附加RR数,每个两个字节。
- 问题区域包含着正在进行的查询信息,该区域包括名字字段:包含正在被查询的主机名字;类型字段指出有关该名字的正被询问的问题类型,即前面提高的资源类型。
- 回答区域包含了对最初请求的名字的资源记录。
- 权威区域包含了其他权威服务器的资源记录。
- 附加区域包含了其他有帮助的资源记录。

2 P2P体系
前面描述的都是客户-服务器体系结构,这种结构要求必须存在一个打开的服务端,同时不同的客户端向服务端请求对象时,都必须由服务端提供响应的对象,客户端之间不能进行信息的交互,因此客户端发送多少次请求,服务端也必须上载该对象相同的次数。
而使用P2P体系结构的,不要必须存在一个总是打开的服务端,成对间歇连接的主机之间可以直接通信,称之为对等方。
假设要求在客户机/服务器结构和P2P结构间做一个发送文件的能力的对比: 要求是每个客户机都成功下载一个文件,那么,在客户机/服务器结构上,一个服务器要向7台客户机上载这个文件,共上载7次,而P2P结构下,服务器最少只要上载文件一次就够了。
这里通过描述BitTorrent运行的过程来窥探P2P体系结构,下面介绍几个名词,
- 洪流:参与特定文件分发的所有对等方的集合;
- 块:在一个洪流中的对等方下载等长度的文件;
- 追踪器洪流的基础设施节点。
一些简要的规则:
- 对等方首次加入洪流时,没有块,随时间流逝,块越来越多;
- 一个对等方下载块时,也为其他对等方上载多个块;
- 对等方获得整个文件时,可以离开洪流或留在洪流中继续为其他对等方上载块 ;
- 任何对等法可能在只有块的子集时离开,以后重新加入该洪流。
- 对等方加入洪流时,需要向追踪器注册自己并周期性通知追踪器自己仍在洪流中。

上图所示为一个新的对等方A加入洪流时,追踪器随即的从参与对等方的集合中选择一个对等方的子集,并将这个子集中的对等方的IP地址发送给新加入的对等方A。对等方A与获得的所有的对等方建立连接,将成功建立连接的对等方为"邻近对等方",上图中A显示了三个邻近对等方。
在任何时间给定的时间内,每个对等方将具有来自该文件的块的子集,并且不同的对等方具有不同的子集。对等方A周期性的询问它的邻近对等方来获得它们的块列表,然后根据自己所拥有的子块和块列表来作出决定。
- 它应当从它的邻居中请求哪些块?
这里采用的是最稀疏优先的原则,针对自己没有的块,选择在邻近对等方的块列表中副本数量最少的块。 - 应当向哪些向它请求块的邻居发送块?
BitTorrent采用一种兑换算法,对等方A对于能够以最高速率向它提供数据的邻居赋以其优先级。特别的,对等方A对于它的每个邻居都持续的测量接收到比特的速率,并且确定最高速率流入的4个邻居。每10秒对等方A会重新计算速率并修改这4个邻居的集合。
此外,每过30秒,对等方A要随机地选择另外一个邻居并向其发送块,我们称这里邻居为对等方B。因为A正在向B发送数据,所以A有可能成为B的前4上载者之一,这样的话B将向A发送数据,如果BB发送的速率足够的块,则也可能成为A的前4上载者之一。这种效果是对等方能够以趋于找到彼此的协调的速率上载。















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









