






由于在聚类中那些表示数据类别的分类或分组信息是没有的,即这些数据是没有标签的,所有聚类及时通常被成为无监督学习(UnsupervisedLearning)。
给定一个有N个对象的数据集,构造数据的K个簇,K<=N。满足下列条件:
1.每个簇至少包含一个对象
2.每一个对象属于且仅属于一个簇
3.将满足于上述条件的K个簇称作一个合理划分
对于给定的类别数目K,首先给出初始化分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都较前一次好。
从数据集中随机选择k个数据点作为初始大哥(质心,Centroid)
对集合中每一个小弟,计算与每一个初始大哥的距离,离哪个初始大哥距离近,就跟定哪个大哥。
这时每一个大哥手下都聚集了一群小弟,重新进行选举,每一群选出新的大哥(通过算法选出新的质心)。
如果新大哥和老大哥之间的距离小于某一个设置的阈值或未发生变化(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为我们进行的聚类已经达到期望的结果,算法终止。否则重新迭代。

算法的时间复杂度是O(K*N*T),
k是中心点个数,
N数据集的大小,
T是迭代次数。

"k均值"(k-means)算法就是针对聚类划分最小化平方误差:
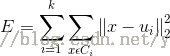
其中是簇Ci的均值向量。从上述公式中可以看出,该公式刻画了簇内样本围绕簇均值向量的紧密程度,E值越小簇内样本的相似度越高。
举例
列举6个点,分成两堆,前三个点一堆,后三个点是另一堆,手动执行K-means
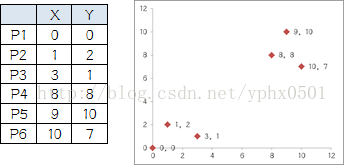



组B有五个人,需要选新大哥,这里要注意选大哥的方法是每个人X坐标的平均值和Y坐标的平均值组成的新的点,为新大哥,也就是说这个大哥是“虚拟的”。
因此,B组选出新大哥的坐标为:P哥((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)。综合两组,新大哥为P1(0,0),P哥(6.2,5.6),而P2-P6重新成为小弟
通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的。
或者按递增的顺序尝试不同的k值,同时画出其对应的误差值,通过寻求拐点来找到一个较好的k值。
中心点的选取(质心)
1、选择彼此距离尽可能远的那些点作为中心点;(具体来说就是先选第一个点,然后选离第一个点最远的当第二个点,然后选第三个点,第三个点到第一、第二两点的距离之和最小,以此类推)
2、先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。
3、多次随机选择中心点训练k-means,选择效果最好的聚类结果。
质心的距离

方案描述:采用keel-dataset的数据集中篮球运动员数据,每分钟助攻数、身高、每分钟得分数。通过该数据集判断一个篮球运动员属于什么位置(后卫、前锋、中锋)或(控卫,分卫,小前锋,大前锋,中锋)
数据集地址:KEEL-dataset- Basketball dataset
数据集特征:assists_per_minute(每分钟助攻数) height(运动员身高)time_played(运动员出场时间)age(运动员年龄)points_per_minute(每分钟得分数)
实验结果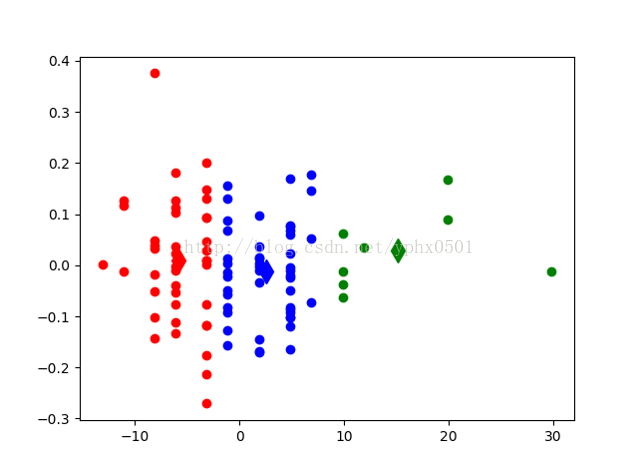
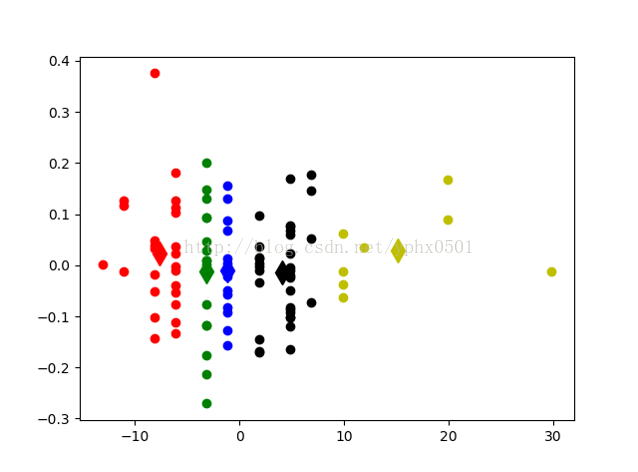
# -*- coding: UTF-8 -*- import numpy import random import codecs import copy import re import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from sklearn.decomposition import PCA import numpy as np def calcuDistance(vec1, vec2): # 计算向量vec1和向量vec2之间的欧氏距离 return numpy.sqrt(numpy.sum(numpy.square(vec1 - vec2))) def loadDataSet(inFile): # 载入数据测试数据集 # 数据由文本保存,为五维坐标 inDate = codecs.open(inFile, 'r', 'utf-8').readlines() dataSet1 = list() dataSet = list() for line in inDate: line = line.strip() strList = re.split('[ ]+', line) # 去除多余的空格 #print (strList[0], strList[1],strList[2], strList[3], strList[4]) numList = list() for item in strList: num = float(item) numList.append(num) #print (numList) dataSet.append(numList) #X = dataSet1 #print(X) #pca = PCA(n_components=2) #a = pca.fit_transform(X) #dataSet=list(a) print(dataSet) return dataSet # dataSet = [[], [], [], ...] def initCentroids(dataSet, k): # 初始化k个质心,随机获取 return random.sample(dataSet, k) # 从dataSet中随机获取k个数据项返回 def minDistance(dataSet, centroidList): # 对每个属于dataSet的item,计算item与centroidList中k个质心的欧式距离,找出距离最小的, # 并将item加入相应的簇类中 clusterDict = dict() # 用dict来保存簇类结果 for item in dataSet: vec1 = numpy.array(item) # 转换成array形式 flag = 0 # 簇分类标记,记录与相应簇距离最近的那个簇 minDis = float("inf") # 初始化为最大值 for i in range(len(centroidList)): vec2 = numpy.array(centroidList[i]) distance = calcuDistance(vec1, vec2) # 计算相应的欧式距离 if distance < minDis: minDis = distance flag = i # 循环结束时,flag保存的是与当前item距离最近的那个簇标记 if flag not in clusterDict.keys(): # 簇标记不存在,进行初始化 clusterDict[flag] = list() # print flag, item clusterDict[flag].append(item) # 加入相应的类别中 return clusterDict # 返回新的聚类结果 def getCentroids(clusterDict): # 得到k个质心 centroidList = list() for key in clusterDict.keys(): centroid = numpy.mean(numpy.array(clusterDict[key]), axis=0) # 计算每列的均值,即找到质心 # print key, centroid centroidList.append(centroid) return numpy.array(centroidList).tolist() def getVar(clusterDict, centroidList): # 计算簇集合间的均方误差 # 将簇类中各个向量与质心的距离进行累加求和 sum = 0.0 for key in clusterDict.keys(): vec1 = numpy.array(centroidList[key]) distance = 0.0 for item in clusterDict[key]: vec2 = numpy.array(item) distance += calcuDistance(vec1, vec2) sum += distance return sum def showCluster(centroidList, clusterDict): # 展示聚类结果 colorMark = ['or', 'ob', 'og', 'ok', 'oy', 'oc','om'] # 不同簇类的标记 'or' --> 'o'代表圆,'r'代表red,'b':blue centroidMark = ['dr', 'db', 'dg', 'dk', 'dy','oc', 'dm'] # 质心标记 同上'd'代表棱形 for key in clusterDict.keys(): plt.plot(centroidList[key][0], centroidList[key][1], centroidMark[key], markersize=12) # 画质心点 for item in clusterDict[key]: plt.plot(item[0], item[1], colorMark[key]) # 画簇类下的点 plt.show() if __name__ == '__main__': inFile = "jingwei.txt" # 数据集文件 dataSet = loadDataSet(inFile) # 载入数据集 print(dataSet) centroidList = initCentroids(dataSet,6) # 初始化质心,设置k=4 clusterDict = minDistance(dataSet, centroidList) # 第一次聚类迭代 newVar = getVar(clusterDict, centroidList) # 获得均方误差值,通过新旧均方误差来获得迭代终止条件 oldVar = -0.0001 # 旧均方误差值初始化为-1 print ('***** 第1次迭代 *****') print ('簇类') for key in clusterDict.keys(): print(key, ' --> ', clusterDict[key]) print ('k个均值向量: ', centroidList) print ('平均均方误差: ', newVar) print (showCluster(centroidList, clusterDict)) # 展示聚类结果 k = 2 while abs(newVar - oldVar) >= 0.0001: # 当连续两次聚类结果小于0.0001时,迭代结束 centroidList = getCentroids(clusterDict) # 获得新的质心 clusterDict = minDistance(dataSet, centroidList) # 新的聚类结果 oldVar = newVar newVar = getVar(clusterDict, centroidList) print ('***** 第%d次迭代 *****' % k) print ('簇类') for key in clusterDict.keys(): print (key, ' --> ', clusterDict[key]) print ('k个均值向量: ', centroidList) print ('平均均方误差: ', newVar) print (showCluster(centroidList, clusterDict) ) # 展示聚类结果 k += 1















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









