







一、算法简介
K-means算法是用来解决著名的聚类问题的最简单的非监督学习算法之一,是很典型的基于距离的聚类算法。该算法采用距离作为相似性的评价指标。即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
k-means算法特点在于:同一聚类的簇内的对象相似度较高;而不同聚类的簇内的对象相似度较小。
二、算法步骤
- 从所有的观测实例中随机取出k个观测点,作为聚类的中心点;然后遍历奇遇的观测点找到各自距离最近的聚类中心点,并将其加入该聚类中。这样,我们便有了一个初始的聚类结果,这是一次迭代过程。
- 每个聚类中心都至少有一个观测实例,这样,我们便可以求出每个聚类的中心点,作为新的聚类中心(该聚类中所有实例的均值),然后再遍历其他所有的观测点,找到距离其最近的中心点,并加入到该聚类中。
- 如此重复步骤2,直到前后两次迭代得到的聚类中心点不再发生变化为止。
该算法旨在最小化一个目标函数——误差平方函数(所有的观测点与其中心点的距离之和)。

经过实验可见如下的迭代过程:
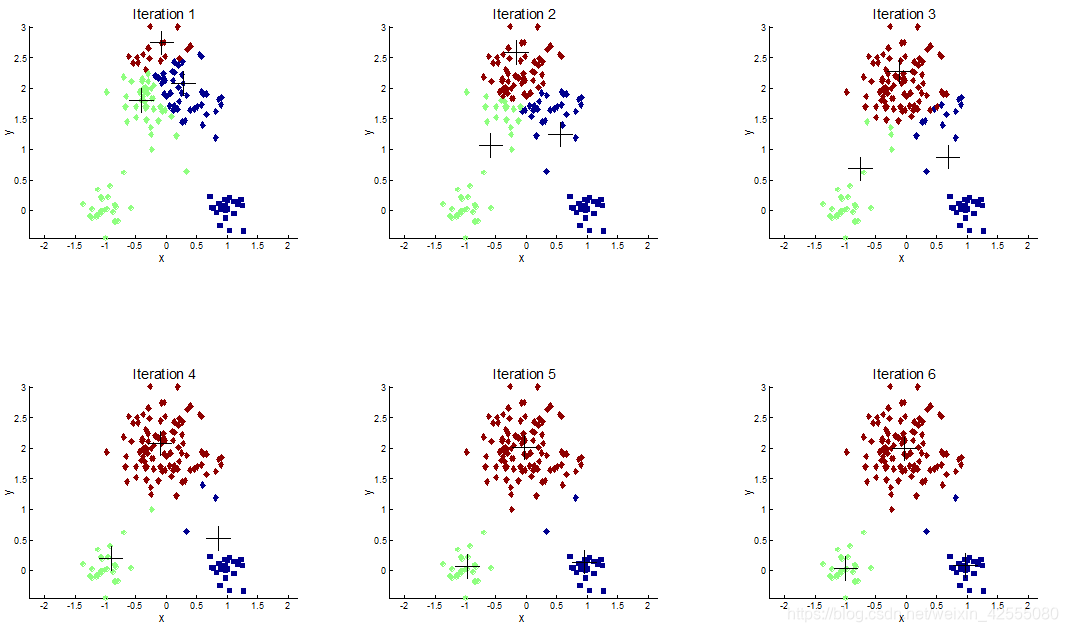
K-means算法的特点是:
- 初始质心点通常是随机选取的
- 不同的初始质心可能产生的聚类不同
- 质心是一个簇中点的平均值
- 度量使用Euclidean欧几里得距离, cosine 相似度量, 相关性度量等.
- 对上述一般的相似性度量,K-means都会收敛
- 大多数经过前几次迭代就能收敛
- 通常终止条件是 簇中的点变化很少时
- 时间复杂度为 O( nKId )
– n = 点的个数, K = 聚类的个数,
– I = 迭代次数, d = 属性个数
三、算法注意点
3.1 初始聚类中心问题解决方法
- 多次运行。多次运行,每次选择不同的初始质心,聚类效果和数据集、k有关,不一定达到好的效果
- 取样并使用层次聚类技术对它聚类,从层次聚类中提取k个簇,并用这些簇的质心作为初始质心(在下列情况下有效:样本相对小、k相对与样本较小)
- 选择分离的质心:即随机选取第一个质心,后面的质心选取应和已经选取的质心距离最远
可能选在非稠密区 - 后处理:对聚类结果进行处理
- 使用二分 K-means,它用于对初始化问题不敏感的情况。
K-means 的变种,可以产生划分或层次聚类
先将所有的点分裂两个簇,再选择一个继续分裂,直到产生k个簇。 - 增量更新质心。可以在点到簇的每次指派之后,增量地更新质心,而不是在所有的点都指派到簇中之后才更新族质心。
3.2 K-means的局限性
- 当聚类的大小、密度、形状不同时,K-means 聚类的结果不理想。
- 数据集包含离群点时,K-means 聚类结果不理想。
- 两个类距离较近时,聚类结果不合理。
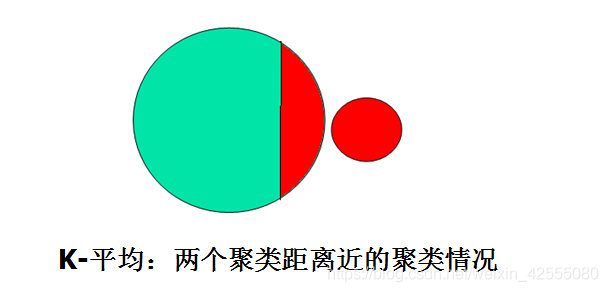
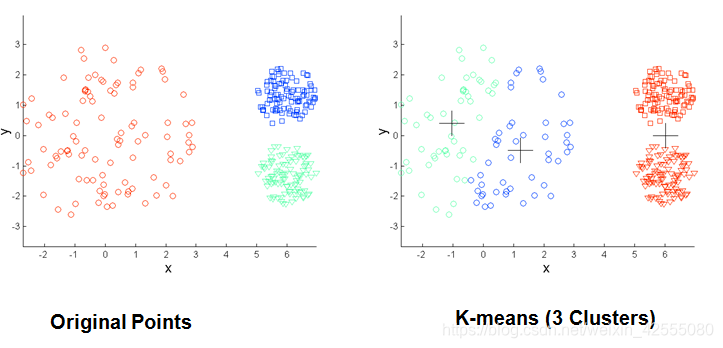
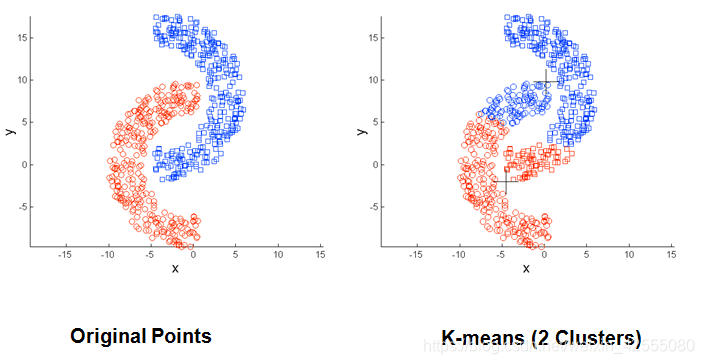
3.2 改进的K-means算法
上面介绍的k-means 算法是一种非常简单并且使用广泛的聚类算法,但是存在如下局限性:
- K 值需要预先给定,很多情况下 K 值的估计很困难。
- K-means 算法对初始选取的聚类中心点很敏感,不同的中心点聚类结果有很大的不同。也就是说,有可能陷入局部最优解。
- 对离群点敏感,聚类结果易产生误差。
- 相似性度量的函数不同也会对聚类结果产生影响。
接下来针对 k-means 的缺陷,总结对k-means的改进。从初始中心点的选取、离群点的检测与去除、相似性度量等几个方面进行概括、比较。
具体改进的方式可以参考博客:机器学习(九)-k-means算法及优化和Python















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









