










 本文深入讲解Windows命令行工具Findstr的使用方法,包括参数详解、正则表达式应用及实战案例,助您高效搜索文本模式。
本文深入讲解Windows命令行工具Findstr的使用方法,包括参数详解、正则表达式应用及实战案例,助您高效搜索文本模式。
一、引言
Findstr
使用正则表达式搜索文件中的文本模式。
语法
findstr [/b] [/e] [/l] [/r] [/s] [/i] [/x] [/v] [/n] [/m] [/o] [/p] [/offline] [/g:File] [/f:File] [/c:String] [/d:DirList] [/a:ColorAttribute] [Strings] [[Drive:][Path] FileName [...]]
参数
/b
如果位于行的开头则匹配模式。
/e
如果位于行的末尾则匹配模式。
/l
逐字地搜索字符串。
/r
使用搜索串作为正则表达式。Findstr 将所有元字符解释为正则表达式,除非使用了 /l。
/s
在当前目录和所有子目录中搜索匹配的文件。
/i
指定搜索不区分大小写。
/x
打印完全匹配的行。
/v
仅打印不包含匹配的行。
/n
在每个匹配的行之前打印行号。
/m
如果文件包含匹配项,则仅打印该文件名。
/o
在每个匹配行之前打印查找偏移量。
/p
跳过包含非可打印字符的文件。
/offline
利用脱机属性设置处理文件。
/f:File
从指定文件中读取文件列表。
/c:String
使用指定的文本作为文字搜索字符串。
/g:File
从指定文件得到搜索字符串。
/d:DirList
搜索以逗号分隔的目录列表。
/a:ColorAttribute
使用两个十六进制数指定颜色属性。
Strings
指定要在 FileName 中搜索的文本。
[ Drive:][Path] FileName [...]
指定要搜索的文件。
/?
在命令提示符下显示帮助。
注释
? 使用 Strings 和 [Drive:][Path] FileName [...]
在命令字符串中,所有 findstr 命令行选项必须在 Strings 和 [Drive:][Path] FileName [...] 之前。
? 在 findstr 中使用正则表达式
Findstr 可以在任何 ASCII 文件或文件中精确查找所要查找的文本。然而,有时要匹配的信息只有一部分或要查找更宽广的信息范围。在这种情况下,findstr 具有使用正则表达式搜索各种文本的强大功能。
正则表达式是用于指定文本类型的符号,与精确的字符串相反。标记使用文字字符和元字符。每个在常规的表达式语法中没有特殊意义的字符都是文字字符,与出现的该字符匹配。例如,字母和数字是文字符号。元字符是在正则表达式语法中具有特殊意义(操作符或分隔符)的符号。
下表列出 findstr 接受的元字符。
字符 值
通配符:任何字符
*
重复:以前零次或多次出现的字符或数字
^
行中的位置:行首
$
行中的位置:行尾
[class]
字符类:集中的任何一个字符
[^class]
反向类:非集中的任何一个字符
[X-y]
范围:指定范围内的任何字符
X
转义:元字符 X 的文字用途
<xyz
字的位置:字首
xyz>
字的位置:字尾
组合使用正则表达式语法的特殊字符功能十分强大。例如,下面的通配符 (.) 和重复符 (*) 的组合可以匹配任何字符串:
.*
将如下表达式用作匹配以“b”开头并以“ing”结尾的任意字符串的更大表达式的组成部分:
b.*ing
示例
参数详解:
学习findstr需要大量的实践体会,所以需要新建一些txt文本以供测试。
a.txt的内容(a.txt的内容在后面会多次修改,请注意!):
Hello World
Hello Boy
hello ,good man.
goodbye!
1.最简单的应用:在指定文本中查找指定字符串
代码:
findstr "hello" a.txt
结果:
C:\Users\helloworld\Desktop>findstr "hello" a.txt
hello ,good man.
代码:
findstr "Hello" a.txt
结果:
C:\Users\helloworld\Desktop>findstr "Hello" a.txt
Hello World
Hello Boy
这里可以看出,
findstr默认是区分大小写的(跟find命令一样)——找hello就不会出现Hello,反之亦然。
怎么让其不区分大小写呢?
用/i参数!
例如:
C:\Users\helloworld\Desktop>findstr /i "Hello" a.txt
Hello World
Hello Boy
hello ,good man.
2.显示要查找的字符具体在文本哪一行
代码:C:\Users\helloworld\Desktop>findstr /n /i "hello" a.txt
复制代码效果:
1:Hello World
2:Hello Boy
3:hello ,good man.
显示的结果中冒号(:)是英文格式下的,在用for提取的时候需要注意!
这里可以对比一下find命令的/n参数:
代码:
C:\Users\helloworld\Desktop>find /n "hello" a.txt
效果:---------- A.TXT
[3]hello ,good man.
复制代码冒号(:)和中括号([]),这就是差别,编写代码的时候一定要注意。
3.查找包含了指定字符的文本
代码:
复制代码代码如下:
C:\Users\helloworld\Desktop>findstr /m /i "hello" *.txt
效果:
1.txt
a.txt
1.txt中的类容如下:除非参数有 /C 前缀,请使用空格隔开搜索字符串。
例如:
'FINDSTR "hello there" x.y' 在文件 x.y 中寻找 "hello" 或
"there"。'FINDSTR /C:"hello there" x.y' 文件 x.y 寻找
"hello there"。
[code]
由于加上了/m参数,所以只列出包含指定字符的文件名。
4.查找以指定字符开始或结尾的文本行
这个功能和前面介绍的最大不同就在于涉及到了“元字符”,如果你不明白什么是“元字符”,那也不用担心学不好这一节,这就好像不明白“water”是什么,也不会影响喝水。
a.txt内容:
[code]
good hello
你好 hello world
Hello World
Hello Boy
hello ,good man.
goodbye!
如何查找以hello(忽略大小写)开始的行?
两种方法:
①./b参数
代码:
C:\Users\helloworld\Desktop>findstr /b /i "hello" a.txt
效果:
Hello World
Hello Boy
hello ,good man.
good hello 和 你好 hello world,这两行都没有显示出来,因为hello不在行的开始处。
②.^符
这里的^可不是转义符,而是正则表达式中的“匹配行开始的位置”。
代码:
C:\Users\helloworld\Desktop>findstr /i "^hello" a.txt
效果:
复制代码代码如下:
Hello World
Hello Boy
hello ,good man.
学完了以查找指定字符开始的行,下面学习查找以指定字符结尾的行。
如何查找以hello(忽略大小写)结尾的行?
同样有两种方法:
①./e参数
代码:
C:\Users\helloworld\Desktop>findstr /e /i "hello" a.txt
结果:
good hello
只显示了“good hello”,因为其它行虽然有“hello”,但是他们都没有以“hello”结尾。
②.$符
代码:
C:\Users\helloworld\Desktop>findstr /i "hello$" a.txt
结果:good hello
到此,我们已经学习了两个正则表达式的元字符:^和$(分别和他们功能相对应的有/b、/e参数)。
5.查找与指定字符完全匹配的行
首先修改a.txt的内容:
hello
hello hello
good hello
你好 hello world
Hello World
Hello Boy
hello ,good man.
goodbye!
懂得举一反三的的童鞋可能会试着尝试以下代码:
C:\Users\helloworld\Desktop>findstr /n /i "^hello$" a.txt
结果让你倍感欣喜:1:hello
其实除了这一种方法外,findstr命令还提供了/x参数用来查找完全匹配的行。
代码:
C:\Users\helloworld\Desktop>findstr /n /i /x "hello" a.txt
结果:
1:hello
6.关闭正则表达式会怎么样?
我们可以人为地将findstr分为两种模式,“正则表达式模式”和“普通字符串模式”。
findstr默认为“正则表达式模式”,加上/r参数也是“正则表达式模式”(换言之,/r参数有点多余)。
加上/l参数后,findstr转换为“普通字符串模式”(其实find就是这种模式、且只有这种模式)。
“普通字符串模式”下,以同样的代码,看看结果怎样?
代码:
C:\Users\helloworld\Desktop>findstr /li "^hello" a.txt
结果什么都没显示出来。
以hello开头的行明明有以下这些,为什么没显示出来呢?
hello hello
Hello World
Hello Boy
hello ,good man.
因为,当你使用“普通字符串模式”,findstr不会把^当做是正则表达式的元字符,而只是把其当做普通字符^,也就是说它此时已经不具备“表示行首”的功能,变成了和h之类字符一样的普通民众,再也没“特权”。
改变a.txt的内容:^hello
复制代码代码如下:
hello
hello hello
good hello
你好 hello world
Hello World
Hello Boy
hello ,good man.
goodbye!
再次运行代码:
C:\Users\helloworld\Desktop>findstr /nli "^hello" a.txt
结果:
1:^hello
7.查找不包含指定字符的行
如果比较一下find和findstr命令就会发现,他们都具有/v,/n,/i,/off[line]参数,而且功能都是一摸一样的,这里说的就是/v参数。
查找不包含hello的行。
代码:
C:\Users\helloworld\Desktop>findstr /vni "hello" a.txt
结果:
9:goodbye!
8.如何查找当前目录及子目录下文件内容中包含某字符串的文件名?
在写这篇教程的时候,偶然看到有批友问了这个问题,问题地址:http://bbs.bathome.net/viewthread.php?tid=14727
代码:
findstr /ms "专业" *.txt
效果:
找出当前目录及子目录下文件内容中包含“专业”的文本文件,并只显示其文件名。
9.用文本制定要查找的文件 And 用文本制定要查找的字符串
用文本制定要查找的文件
新建一个file.txt,内容如下(这个文本中指定findstr要查找的文本的路径):
C:\Users\helloworld\Desktop\1.txt
C:\Users\helloworld\Desktop\a.txt
C:\Users\helloworld\Desktop\clip.txt
C:\Users\helloworld\Desktop\CrLf 批处理笔记.txt
C:\Users\helloworld\Desktop\file.txt
C:\Users\helloworld\Desktop\MyRarHelp.txt
C:\Users\helloworld\Desktop\test.txt
C:\Users\helloworld\Desktop\红楼.txt
C:\Users\helloworld\Desktop\520\新建文本文档.txt
C:\Users\helloworld\Desktop\520\12\hello_ world.txt
C:\Users\helloworld\Desktop\编程\help.txt
C:\Users\helloworld\Desktop\编程\win7 help比xp help多出来的命令.txt
C:\Users\helloworld\Desktop\编程\wmic.txt
代码:
C:\Users\helloworld\Desktop>findstr /f:file.txt /im "hello"
效果:
C:\Users\helloworld\Desktop\1.txt
C:\Users\helloworld\Desktop\a.txt
C:\Users\helloworld\Desktop\CrLf 批处理笔记.txt
C:\Users\helloworld\Desktop\file.txt
C:\Users\helloworld\Desktop\test.txt
用文本制定要查找的字符串
新建一个string.txt,内容如下(这个文本中指定findstr要查找的字符串):
^hello
world
a.txt
^hello
hello
hello hello
good hello
你好 hello
Hello World
Hello Boy
hello ,good man.
goodbye!
代码:
C:\Users\helloworld\Desktop>findstr /ig:string.txt a.txt
效果:
hello
hello hello
Hello World
Hello Boy
hello ,good man.
被忽略的行
^hello
good hello
你好 hello
goodbye!
从被忽略的“^hello”可以看出,在不加/l参数的前提下,用/g指定的搜索字符串中如果含有“元字符”,则作为正则表达式使用,而不是作为普通表达式。
10.搜索一个完全匹配的句子
其实findstr自带的帮助中就有个很好的例子:
例如: 'FINDSTR "hello there" x.y' 在文件 x.y 中寻找 "hello" 或
"there"。'FINDSTR /C:"hello there" x.y' 文件 x.y 寻找
"hello there"。
可以以这个例子来做个测试。
a.txthello there
hellothere
hello
there
代码:
C:\Users\helloworld\Desktop>findstr /ic:"hello there" a.txt
结果:
hello there
这就是句子的完全匹配了。
11.搜索一个完全匹配的词。
这里也涉及到了两个元字符:\<,\>。
先试看一个例子。
a.txt
far there
farthere
there
far
farm
farmer
代码:
C:\Users\helloworld\Desktop>findstr "far" a.txt
结果:
far there
farthere
far
farm
farmer
我的本意是要查找含有“far”这个单词的行,但是farthere、farm、farmer却显示出来了,这不是我想要的结果。
如果只要求显示含有“far”这个单词的行,该怎么写呢?
代码:
C:\Users\helloworld\Desktop>findstr "\<far\>" a.txt
结果:
far there
far
12.指定要查找的目录
/d参数我一直把它和/f、/g归为一类,但其实二者截然不同,/f、/g是用文本文件制定要查找的文件、字符串,而/d是直接书写目录名到命令中。
代码:
C:\Users\helloworld\Desktop>findstr /imd:520;编程; ".*" "*.txt"
结果:
520:
hello.txt
编程:
help.txt
win7 help比xp help多出来的命令.txt
wmic.txt
查找在520、编程目录中所有包含任意字符的txt文件。
13.统计字符数
/o:在每行前打印字符偏移量,在找到的每行前打印该行首距离文件开头的位置,也就是多少个字符,如test.txt中有如下内容:
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
执行命令:findstr /o .* test.txt
复制代码::上一行中的.*为正则表达式的内容,表示任意行,包含空行
结果如下:
0:aaaaaaaaaa
12:aaaaaaaaaa
24:aaaaaaaaaa
36:aaaaaaaaaa
48:aaaaaaaaaa
注意每行末尾的回车换行符算两个字符。
14.以指定颜色显示文件名
/a:当被搜索文件名中含有通配符*或?时对搜索结果的文件名部分指定颜色属性,具体颜色值参见color帮助:
0 = 黑色 8 = 灰色
1 = 蓝色 9 = 淡蓝色
2 = 绿色 A = 淡绿色
3 = 浅绿色 B = 淡浅绿色
4 = 红色 C = 淡红色
5 = 紫色 D = 淡紫色
6 = 黄色 E = 淡黄色
7 = 白色 F = 亮白色
常用于彩色显示,举个简单的例子,想要彩色显示“批处理之家”怎么办,假如当前的color设置为27(背景绿色,字体白色),用蓝色显示“批处理之家”咋办?::下一行的退格符可以在cmd的编辑模式下按ctrl+p后按退格键获得>"批处理之家" set /p=<nul
>"批处理之家" set /p=<nul
findstr /a:21 .* "批处理之家*"
pause
代码中的退格符是为了让显示的内容仅为"批处理之家",如果有其他内容,在彩色显示的"批处理之家"后还有一个冒号和其他内容,退格符正好将冒号删除。注意代码中的通配符是必须的。
二、应用案例
(1)$GPGGA 语句包括17个字段:语句标识头,世界时间,纬度,纬度半球,经度,经度半球,定位质量指示,使用卫星数量,HDOP-水平精度因子,椭球高,高度单位,大地水准面高度异常差值,高度单位,差分GPS数据期限,差分参考基站标号,校验和结束标记(用回车符<CR>和换行符<LF>),分别用14个逗号进行分隔。
格式示例:$GPGGA,014434.70,3817.13334637,N,12139.72994196,E,4,07,1.5,6.571,M,8.942,M,0.7,0016*79
该数据帧的结构及各字段释义如下:
$GPGGA,<1>,<2>,<3>,<4>,<5>,<6>,<7>,<8>,<9>,M,<10>,M,<11>,<12>*xx<CR><LF>
$GPGGA:起始引导符及语句格式说明(本句为GPS定位数据);
<1> UTC时间,格式为hhmmss.sss;
<2> 纬度,格式为ddmm.mmmm(第一位是零也将传送);
<3> 纬度半球,N或S(北纬或南纬)
<4> 经度,格式为dddmm.mmmm(第一位零也将传送);
<5> 经度半球,E或W(东经或西经)
<6> GPS状态, 0初始化, 1单点定位, 2码差分, 3无效PPS, 4固定解, 5浮点解, 6正在估算 7,人工输入固定值, 8模拟模式, 9WAAS差分
<7> 使用卫星数量,从00到12(第一个零也将传送)
<8> HDOP-水平精度因子,0.5到99.9,一般认为HDOP越小,质量越好。
<9> 海拔高度,-9999.9到9999.9米
M 指单位米
<10> 大地水准面高度异常差值,-9999.9到9999.9米
M 指单位米
<11> 差分GPS数据期限(RTCM SC-104),最后设立RTCM传送的秒数量,如不是差分定位则为空
<12> 差分参考基站标号,从0000到1023(首位0也将传送)。
* 语句结束标志符
xx 从$开始到*之间的所有ASCII码的异或校验
<CR> 回车符,结束标记
<LF> 换行符,结束标记
$GNGGA 与GPGGA类似,见下图

(2)实测数据分析
原始数据片段
ELL WGS-84 6378137.000 298.257223563
PRO TME 111.000000 1.000000 0.000000 0.000000 0.000000 500000.0000 0.0000
DTM 0.00 0.00 0.00 0.00000 0.00000 0.00000 0.00000
GEO "" 0.000
HVU 1.0000000000 1.0000000000
TND 12:29:40 08/09/2020 -480
DEV 0 33269 "GPS NMEA-0183" 57348 C:\HYPACK 2018\devices\gps.dll 17.2.6.0
OFF 0 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
PRD 0 KTD "" "" ""
DDT 0 SYN KTC
USR "FENERBAHCE" "NOT FOR COMMERCIAL USE" 0x1FF 1907
EOH 374E52CD73F92DB2E60B4A94FE482003F68C5D29E7478A0D1496A3E400681FCDA7937359454FF5926C0162AD3554163AF250A1E5D95964704E38C793B142788EB7AC35BF335E20EB945A4BA46560B95F8FB276EAB0101A1A134B303180BE568479319B8D1B2E956DBB4C8F303F94D65B22AAD863A97FD52DE261A9C83308B4BF
POS 0 44979.000 429782.591 3367458.117
QUA 0 44979.000 7 5.000 0.800 16.000 4.000 0.000 0.000 0.000
RAW 0 44979.000 4 302550.22194 1101614.78033 372.27600 42939.00000
GYR 0 44979.530 210.160
SYN 0 44979.525 6 44738920.099 44738920.099 256.000 0.000 0.000 0.000
MSG 0 44979.517 $GNGGA,042939.00,3025.50221938,N,11016.14780327,E,4,16,0.8,395.028,M,-22.752,M,13.0,0002*42
MSG 0 44979.525 $GNZDA,042939.06,09,08,2020,00,00*7A
MSG 0 44979.528 $GNHDT,,*51
MSG 0 44979.530 $GNVTG,210.16,T,213.69,M,0.02,N,0.03,K,D*32
MSG 0 44979.708 UTC 20.08.09 04:29:40 69
POS 0 44980.000 429782.589 3367458.114
QUA 0 44980.000 7 5.000 0.800 16.000 4.000 0.000 0.000 0.000
RAW 0 44980.000 4 302550.22177 1101614.78022 372.27500 42940.00000
GYR 0 44980.525 319.310
SYN 0 44980.520 6 44738920.099 44738920.099 256.000 0.000 0.000 0.000
MSG 0 44980.513 $GNGGA,042940.00,3025.50221774,N,11016.14780215,E,4,16,0.8,395.027,M,-22.752,M,14.0,0002*42
MSG 0 44980.520 $GNZDA,042940.05,09,08,2020,00,00*77
MSG 0 44980.524 $GNHDT,,*51
MSG 0 44980.525 $GNVTG,319.31,T,322.84,M,0.01,N,0.02,K,D*3D
MSG 0 44980.707 UTC 20.08.09 04:29:41 69
FIX 99 44980.750 3 429782.589 3367458.114
POS 0 44981.000 429782.589 3367458.111
QUA 0 44981.000 7 5.000 0.800 16.000 4.000 0.000 0.000 0.000
RAW 0 44981.000 4 302550.22161 1101614.78019 372.27200 42941.00000
MSG 0 44981.510 $GNGGA,042941.00,3025.50221613,N,11016.14780192,E,4,16,0.8,395.024,M,-22.752,M,15.0,0002*4D
GYR 0 44981.523 217.260
SYN 0 44981.518 6 44738920.099 44738920.099 256.000 0.000 0.000 0.000
MSG 0 44981.518 $GNZDA,042941.05,09,08,2020,00,00*76
MSG 0 44981.522 $GNHDT,,*51
MSG 0 44981.523 $GNVTG,217.26,T,220.79,M,0.02,N,0.04,K,D*30
MSG 0 44981.707 UTC 20.08.09 04:29:42 69
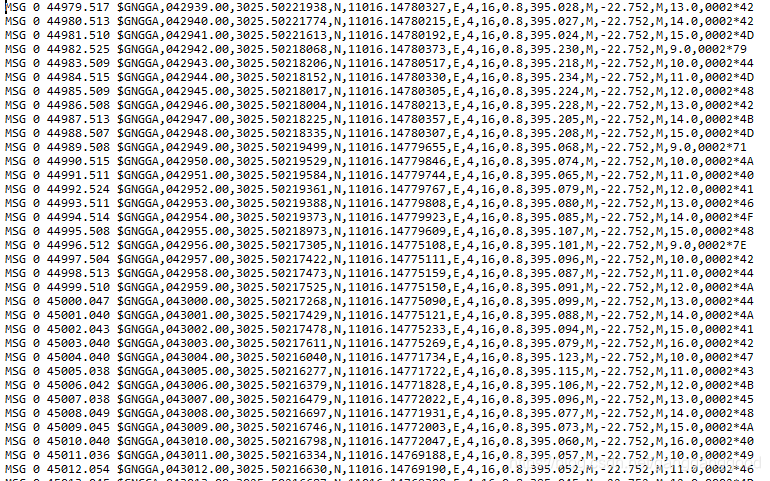
实现功能:从上万条的记录数据中,提取只包含$GNGGA字符串的行
//提取含GNGGA的行
@echo off
findstr /C:"$GNGGA" B.RAW>B1.RAW
上述语句的意思是将B.RAW文件中含有GNGGA的行完全提取出来,生成一个新文件B1.RAW,并保存
结语:希望在以后的日子里能够多思考,多动手,多实践,提高工作效率,解放自己。

















 1495
1495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









