






面试题
Nginx
1.nginx日志访问量前十的ip怎么统计?
awk '{array[$1]++}END{for (ip in array)print ip,array[ip]}' access.log |sort -k2 -rn|head
2、现在给你三百台服务器,你怎么对他们进行管理?
管理3百台服务器的方式:
1)设定跳板机,使用统一账号登录,便于安全与登录的考量。
2)使用salt、ansible、puppet进行系统的统一调度与配置的统一管理。
3)建立简单的服务器的系统、配置、应用的cmdb信息管理。便于查阅每台服务器上的各种信 息记录。 ‘’
2.nginx 和apache 的区别有哪一些,各有什么区别?
1. nginx 相对 apache 的优点:
轻量级,同样起web 服务,比apache 占用更少的内存及资源
抗并发,nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能
高度模块化的设计,编写模块相对简单
社区活跃,各种高性能模块出品迅速啊
2.apache 相对nginx 的优点:
rewrite ,比nginx 的rewrite 强大
模块超多,基本想到的都可以找到
少bug ,nginx 的bug 相对较多
超稳定
3.LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
LVS:是基于四层的转发
HAproxy:是基于四层和七层的转发,是专业的代理服务器
Nginx:是WEB服务器,缓存服务器,又是反向代理服务器,可以做七层的转发
区别:LVS由于是基于四层的转发所以只能做端口的转发、而基于URL的、基于目录的这种转发LVS就做不了
工作选择:HAproxy和Nginx由于可以做七层的转发,所以URL和目录的转发都可以做,在很大并发量的时候我们就要选择LVS,像中小型公司的话并发量没那么大,选择HAproxy或者Nginx足已,由于HAproxy由是专业的代理服务器,配置简单,所以中小型企业推荐使用HAproxy
4.写一个脚本,实现批量添加20个用户,用户名为user1-20,密码为user后面跟5个随机字符
#!/bin/bash
#description: useradd
for i in `seq -f"%02g" 1 20`;do
useradd user$i
echo "user$i-`echo $RANDOM|md5sum|cut -c 1-5`"|passwd –stdinuser$i >/dev/null 2>&1
done
5.使用“反向代理服务器”的优点是什么?
反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器
间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时。
6.请解释Nginx如何处理HTTP请求。Nginx 是一个高性能的 Web 服务器,能够同时处理大量的并发请求。它结合多进程机制和异步机制 ,异步机制使用的是异步非阻塞方式 ,接下来就给大家介绍一下 Nginx 的多线程机制和异步非阻塞机制 。
(1) 多进程机制
服务器每当收到一个客户端时,就有 服务器主进程 ( master process )生成一个 子进程( worker process )出来和客户端建立连接进行交互,直到连接断开,该子进程就结束了。
使用进程的好处是各个进程之间相互独立,不需要加锁,减少了使用锁对性能造成影响,同时降低编程的复杂度,降低开发成本。其次,采用独立的进程,可以让进程互相之间不会影响 ,如果一个进程发生异常退出时,其它进程正常工作, master 进程则很快启动新的 worker 进程,确保服务不会中断,从而将风险降到最低。
缺点是操作系统生成一个子进程需要进行 内存复制等操作,在资源和时间上会产生一定的开销。当有大量请求时,会导致系统性能下降 。
(2) 异步非阻塞机制
每个工作进程 使用 异步非阻塞方式 ,可以处理 多个客户端请求 。
当某个 工作进程 接收到客户端的请求以后,调用 IO进行处理,如果不能立即得到结果,就去处理其他请求 (即为非阻塞 );而 客户端 在此期间也 无需等待响应 ,可以去处理其他事情(即为异步 )。
当 IO 返回时,就会通知此 工作进程 ;该进程得到通知,暂时 挂起 当前处理的事务去 响应客户端请求 。
7.什么是中间件?什么是jdk?
中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源
中间件位于客户机/ 服务器的操作系统之上,管理计算机资源和网络通讯是连接两个独立应用程序或独立系统的软件。相连接的系统,即使它们具有不同的接口
但通过中间件相互之间仍能交换信息。执行中间件的一个关键途径是信息传递通过中间件,应用程序可以工作于多平台或OS环境。
jdk:jdk是Java的开发工具包,它是一种用于构建在 Java 平台上发布的应用程序、applet 和组件的开发环
8.简述DNS进行域名解析的过程?
用户要访问http://www.baidu.com,会先找本机的host文件,再找本地设置的DNS服务器,如果也没有的话,就去网络中找根服务器,根服务器反馈结果,说只能提供一级域名服务器.cn,就去找一级域名服务器,一级域名服务器说只能提供二级域名服务器.com.cn,就去找二级域名服务器,二级域服务器只能提供三级域名服务器.http://baidu.com.cn,就去找三级域名服务器,三级域名服务器正好有这个网站http://www.baidu.com,然后发给请求的服务器,保存一份之后,再发给客户端
9.我给你一台服务器,你应该做什么?
1、提高用户密码的复杂度,给普通用户合理设置sudo权限,禁止root用户远程登录
禁止root远程登录:vim /etc/ssh/sshd_config,
找到PermitRootLogin改为PermitRootLogin no,
重启 service sshd restart
2、优化shhd服务,修改服务监听的端口号,禁用反向解析,提高连接效率
优化sshd服务:关闭UseDNS,vi /etc/ssh/sshd_config,找到UseDNS这一行,删掉注释“#”把后面的yes改为no;关闭SERVER上的GSS认证,还是上面那个文件,找到GSSAPIAuthentication这一行,把后面的yes改为no,两个关闭之后重新启动sshd服务,systemctl restart sshd
3、防火墙,有两种防火墙,分别是firewalld,iptable;开始只允许22端口放行
centos6用是是iptable,centos7两种防火墙firewallld和iptable都有;
让iptable生效:iptables -P INPUT DROP
关闭iptable:iptables -P INPUT ACCEPT
查看防火墙放行列表:firewall-cmd --list-all
放行22号端口:firewall-cmd --zone=public --add-port=22/tcp --permanent
刷新生效:firewall-cmd --reload
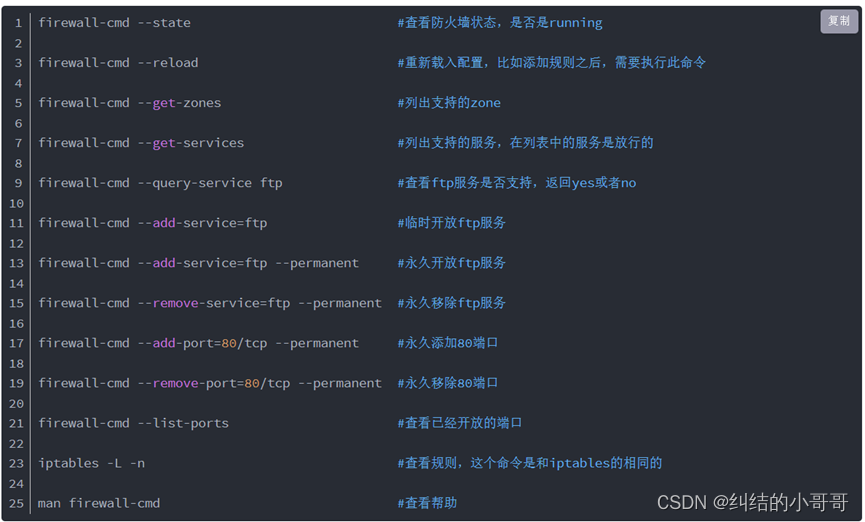
4、配置网络yum源
访问阿里云网址:mirros.aliyun.com
找到centos,里面找到centos7的网络yum源,复制粘贴到linux(公司里很少用本地yum源,一般都是用网络yum源)
5、装系统的时候,合理分配硬盘容量,将数据盘与系统盘分开
将一个硬盘sda来装系统,另一个sdb来装数据,这样即使系统崩了,数据还在。
6、优化系统
解决系统中出现大量Time Wait的问题
vi /etc/sysctl.conf 内核文件
可以在末尾添加以下内容:
net.ipv4.tcp_syncookies = 1 #表示开启SYN Cookies,当出现SYN等待队列溢 出时,启用Cookies来处理,可防范少量SYN攻击,默认为0,表示关闭。
net.ipv4.tcp.tw_reuse = 1 #表示开启重用,允许将TIME-WAIT sockets重新用 于新的TCP连接,默认为0,表示关闭,加快访问客户端的速度。
net.ipv4.tcp_tw_recycle = 1 #表示开启TCP连接中TIME-WAIT sockets的快速 回收,默认为0,表示关闭,不用等待2MSL,直接到CLOSED状态。
net.ipv4.tcp_fin_timeout = 10 #修改系统默认的TIMEOUT时间,等待重置 时间,默认30秒,改成10秒
7、设置用户打开的文件数和进程数
vi /etc/security/limits.conf
Too many open files
文件数:* soft nofile 65535
* hard nofile 65535
程序数:* soft nproc 65535
* hard nproc 65535
10.为什么要用Nginx?
跨平台、配置简单、反向代理、高并发连接:处理2-3万并发连接数,官方监测能支持5万并发,内存消耗小:开启10个nginx才占150M内存 ,nginx处理静态文件好,耗费内存少
而且Nginx内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
使用Nginx的话还能:
1、节省宽带:支持GZIP压缩,可以添加浏览器本地缓存
2、稳定性高:宕机的概率非常小
3、接收用户请求是异步的
11.什么是正向代理和反向代理?
正向代理就是一个人发送一个请求直接就到达了目标的服务器
正向代理服务器代理的是客户端,而反向代理服务器代理的是服务端
12.Nginx的优缺点?
优点:
1)占内存小,可实现高并发连接,处理响应快
2)可实现http服务器、虚拟主机、方向代理、负载均衡
3)Nginx配置简单
4)可以不暴露正式的服务器IP地址
缺点:
动态处理差:nginx处理静态文件好,耗费内存少,但是处理动态页面则很鸡肋,现在一般前端用nginx作为反向代理抗住压力
13.nginx为什么要做动静分离?
Nginx是当下最热的Web容器,网站优化的重要点在于静态化网站,网站静态化的关键点则是是动静分离,动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们则根据静态资源的特点将其做缓存操作。
让静态的资源只走静态资源服务器,动态的走动态的服务器
Nginx的静态处理能力很强,但是动态处理能力不足,因此,在企业中常用动静分离技术。
对于静态资源比如图片,js,css等文件,我们则在反向代理服务器nginx中进行缓存。这样浏览器在请求一个静态资源时,代理服务器nginx就可以直接处理,无需将请求转发给后端服务器tomcat。
若用户请求的动态文件,比如servlet,jsp则转发给Tomcat服务器处理,从而实现动静分离。这也是反向代理服务器的一个重要的作用。
14.Nginx负载均衡的算法怎么实现的?策略有哪些?
为了避免服务器崩溃,大家会通过负载均衡的方式来分担服务器压力。将对台服务器组成一个集群,当用户访问时,先访问到一个转发服务器,再由转发服务器将访问分发到压力更小的服务器。
15.Nginx负载均衡实现的策略有以下五种:
(1)轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某个服务器宕机,能自动剔除故障系统。
(2)权重 weight
weight的值越大分配到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下。其次是为在主从的情况下设置不同的权值,达到合理有效的地利用主机资源。
(3)ip_hash( IP绑定)
每个请求按访问IP的哈希结果分配,使来自同一个IP的访客固定访问一台后端服务器,并且可以有效解决动态网页存在的session共享问题
(4)fair(第三方插件)
必须安装upstream_fair模块。
对比 weight、ip_hash更加智能的负载均衡算法,fair算法可以根据页面大小和加载时间长短智能地进行负载均衡,响应时间短的优先分配。
(5)url_hash(第三方插件)
必须安装Nginx的hash软件包
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。
16.Nginx配置高可用性怎么配置?
当上游服务器(真实访问服务器),一旦出现故障或者是没有及时相应的话,应该直接轮询到下一台服务器,保证服务器的高可用
17.nginx是如何实现高并发的?
简单来讲,就是: 异步,非阻塞,使用了epoll和大量的底层代码优化
nginx采用一个master进程,多个woker进程的模式。
1. master进程主要负责收集、分发请求。当一个请求过来时,master拉起一个worker进程负责处理这个请求。
2. master进程也要负责监控woker的状态,保证高可靠性
3. woker进程一般设置为跟cpu核心数一致。nginx的woker进程跟apache不一样。apche的进程在同一时间只能处理一个请求,所以它会开很多个进程,几百甚至几千个。而nginx的woker进程在同一时间可以处理额请求数只受内存限制,因此可以处理多个请求。
18.nginx的四大功能是什么?
正向代理,反向代理,负载均衡,动静分离
19.http服务器是干什么的。Nginx是一个http服务可以独立提供http服务。可以做网页静态服务器。
20:虚拟主机。可以实现在一台服务器虚拟出多个网站。例如个人网站使用的虚拟主机。
基于端口的,不同的端口
基于域名的,不同域名
21.反向代理,负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理。并且多台服务器可以平均分担负载,不会因为某台服务器负载高宕机而某台服务器闲置的情况
正向代理和反向代理的区别?
22.正向
地址,所以只能通过代理代理代理的对象是客户端。也就是用户知道要访问目标服务器的地址,然后让代理服务器去代理客户端请求目标服务器。比如翻墙。
23.反向代理代理的对象是服务器。也就是用户不知道目标服务器的地址,只知道代理服务器服务器去请求目标服务器。
24.负载均衡
单个服务器解决不了,我们增加服务器的数量,然后将请求分发到各个服务器上,将原先请求集中到单个服务器上的情况改为将请求分发
到多个服务器上,将负载分发到不同的服务器,也就是我们所说的负载均衡。
25.动静分离
为了加快网站的解析速度,可以把动态页面和静态页面由不同的服务器来解析,加快解析速度。降低原来单个服务器的压力。
26.nginx和apache的区别?
轻量级,同样起web 服务,比apache 占用更少的内存及资源;抗并发,nginx处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能;高度模块化的设计,编写模块相对简单;最核心的区别在于apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接(万级别)可以对应一个进程。
27.Nginx虚拟主机怎么配置?
1、基于域名的虚拟主机,通过域名来区分虚拟主机——应用:外部网站
2、基于端口的虚拟主机,通过端口来区分虚拟主机——应用:公司内部网站,外部网站的管理后台
3、基于ip的虚拟主机。
28.Nginx如何处理HTTP请求?
Nginx使用反应器模式。主事件循环等待操作系统发出准备事件的信号,这样数据就可以从套接字读取,在该实例中读取到缓冲区并进行处理。单个线程可以提供数万个并发连接。
29.为什么要用Nginx?
跨平台、配置简单
非阻塞、高并发连接:
处理2-3万并发连接数,官方监测能支持5万并发
内存消耗小:
开启10个nginx才占150M内存,Nginx采取了分阶段资源分配技术
nginx处理静态文件好,耗费内存少
内置的健康检查功能:
如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
节省宽带:
支持GZIP压缩,可以添加浏览器本地缓存
稳定性高:
宕机的概率非常小
master/worker结构:
一个master进程,生成一个或者多个worker进程
接收用户请求是异步的:
浏览器将请求发送到nginx服务器,它先将用户请求全部接收下来,再一次性发送给后端web服务器,极大减轻了web服务器的压力,一边接收web服务器的返回数据,一边发送给浏览器客户端
网络依赖性比较低,只要ping通就可以负载均衡
可以有多台nginx服务器
30.为什么Nginx性能这么高?
得益于它的事件处理机制:
异步非阻塞事件处理机制:运用了epoll模型,提供了一个队列,排队解决
31.基于虚拟主机配置域名
需要建立/data/www /data/bbs目录,windows本地hosts添加虚拟机ip地址对应的域名解析;对应域名网站目录下新增index.html文件
32.为什么不使用多线程?
Nginx:采用单线程来异步非阻塞处理请求(管理员可以配置Nginx主进程的工作进程的数量),不会为每个请求分配cpu和内存资源,节省了大量资源,同时也减少了大量的CPU的上下文切换,所以才使得Nginx支持更高的并发。
33.请陈述stub_status和sub_filter指令的作用是什么?
Stub_status指令:该指令用于了解Nginx当前状态的当前状态,如当前的活动连接,接受和处理当前读/写/等待连接的总数 ;
Sub_filter指令:它用于搜索和替换响应中的内容,并快速修复陈旧的数据
34.用 Nginx服务器解释-s的目的是什么?
用于运行Nginx -s参数的可执行文件。
35.列举Nginx服务器的最佳用途。
Nginx服务器的最佳用法是在网络上部署动态HTTP内容,使用SCGI、WSGI应用程序服务器、用于脚本的FastCGI处理程序。它还可以作为负载均衡器。
36.Nginx服务器上的Master和Worker进程分别是什么?
Master进程:读取及评估配置和维持 ;
Worker进程:处理请求。
37.限流怎么做的?
Nginx限流就是限制用户请求速度,防止服务器受不了
限流有3种
正常限制访问频率(正常流量)
突发限制访问频率(突发流量)
限制并发连接数
38.请描述nginx-fastcgi工作原理
Nginx不支持对外部程序的直接调用或解析,所有的外部程序(包括PHP)必须通过FastCGI接口来调用。FastCGI接口在linux下是socket(这个socket可以是文件socket,也可以是ip socket)。为了调用CGI程序,还需要一个FastCGI的wrapper(wrapper可以理解为用于启动另一个程序的程序),这个wrapper绑定在某个固定socket上,如端口或者文件socket。当Nginx将CGI请求发送给这个socket的时候,通过FastCGI接口,wrapper接收道请求,然后派生出一个新的线程,这个线程调用解释器或者外部程序处理脚本并读取返回数据;接着,wrapper再将返回的数据通过FastCGI接口,沿着固定的socket传递给Nginx;最后,Nginx将返回的数据发送给客户端。这就是Nginx+FastCGI的整个运作过程
39.Nginx在前端如何把真实IP传给后端真实服务器?
可以通过修改nginx.conf来实现
proxy_set_header HOST $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Client-IP $remote_addr;
proxy_set_header X-For $proxy_add_x_forwarded_for;
40.你们如何实现web图片防盗链,请简述布置步骤
首先我们编写我们的web配置,加入一个类来处理图片过来的请求,获取来源的域名,判断域名中是否包含自己的域名。我自己的域名是aspnetjia,如何在。就返回正确的图片,如何不包含自己的域名那就证明是外链调用,就返回一张默认的图片。
Mysql常用引擎有哪些区别和特点?工作中如何选择?
InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比较低,也可以使用。
如果读写比较多就选择InooDB,如果写少读多就选择MyISAM
请设计一个高大上的mysal备份方案
41.提升用户体验的网站解决方案?
分析:高并发、大数据量写入数据,会把数据先写到内存,积累一定的量之后,
然后在定时或定量的写到磁盘(减少磁盘的IO (Input/ Output)) ,最终还是会把数据加载到内存中再对外提供访问。
优点:写数据到内存,性能高、速度快(微博、微信、SNS、秒杀产品)
缺点:可能会丢失一部在内存中还没有来得及存入磁盘的数据
解决数据不丢失的方法:
1)服务器主板上安装蓄电池,在断电的瞬间把内存数据会写到磁盘里
2) UPS (一组蓄电池)不间断供电(程序10分钟,IDC数据UPS 1小时)
3)选双路电的机房,使用双电源、分别接不同路的电,服务器要放到不同的机
柜、地区
42.DNS 基本原理
1.浏览器先检查自身缓存中有没有被解析过的这个域名对应的ip地址,如果有,解析结束。同时域名被缓存的时间也可通过TTL属性来设置。
⒉.如果浏览器缓存中没命中,浏览器会检查操作系统缓存中有没有对应的已解析过的结果。而操作系统也有一个域名解析的过程。在windows中可通过c盘里hosts文件来设置,如果你在这里指定了一个域名对应的in地址,那浏览器会首先使用这个in地址。但是这种操作系统级别的域名解析规程也被很多黑客利用,通过修改你的hosts文件里的内容把特定的域名解析到他指定的in地址上,造成所谓的域名劫持。所以在windows7中将hosts文件设置成了readonlx,防止被恶意篡改。
3.如果至此还没有命中域名,才会真正的请求本地域名服务器(LDNS)来解析这个域名,这台服务器一般在你的城市的某个角落,距离你不会很远,并且这台服务器的性能都很好,一般都会缓存域名解析结果,大约80%的域名解析到这里就完成了。
4.如果LDNS仍然没有命中,就直接跳到根(.)域名服务器请求解析。
5.根域名服务器返回给LDNS一个所查询域的主域名服务器(GTLD Server,国际顶尖域名服务器,如(.com .cn .org等)地址。
6.此时LDNS再发送请求给上一步返回的GTLD(类似于.com).。
7.接受请求的GTLD查找并返回这个域名对应的Name Server 的地址,这个NameServer就是网站注册的域名服务器(Crushlinux.com)。
8. Name Server根据映射关系表找到目标ip,返回给LDNS。
9.LDNS缓存这个域名和对应的ip。
10.LDNS把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程完毕。
43.URL由什么组成?所谓请求是什么东东?Uri又是什么?
答:URL=uri+域名,请求就是URL,uri是资源位置
44.http协议里GET和POST请求的区别?
答:get是读,post是写。
45.伪静态网页的本质是什么?
答:伪静态网页的本质是将动态网页转换成静态网页,将数据提取出来,放到前端缓存。
46.前端语言的种类,后端语言的种类
答:html、Css、安卓、后端java、Python
47.报头是什么?主体是什么?
答:报头是参数,主体是想要看的信息
48.什么是IP,PV,UV?
答:ip是独立ip每个链接web服务器的ip地址。Pv是用户点击一次网页就是记录一个pv。Uv是每个用户访问网页的时候都会发一个cookie,一个cookie是一个uv,有的就不记录,没有的就新发一个并记录一个uv
49.Nginx服务三大功能?
答:可以当缓存服务器,可以当反向代理(负载均衡),可以当web服务器
50.Apache和nginx的网络模型是什么?
答:apache是select同步阻塞模型,nginx是epoll异步模型
51.同步阻塞I/O和异步非阻塞I/O的含义?
答:同步阻塞就是必须等上一个io完成以后才能进行下一个io。异步非阻塞就是当上一个io进行等待的时候可以先完成下一个的一部分当上一个等待结束继续完成上一个。
52.什么叫连接保持,它的作用是什么?
答:保持连接就是一个用户在三次握手以后不进行任何操作的时候还在连接状态的时间,超过时间就会直接断开连接、降低并发,节省资源
53.如果用户是通过IP地址访问网站的,如何让它只能看指定的server网站?
在域名的后面加上default_server的字段
54.nginx的location五种优先级过滤规则
精确>特殊正则>正则>字符串>默认 “=”> “^~” > “~.*” > “//” > “/”
55.nginx的403访问报错有可能是什么原因?
可能是主页文件的权限出错,放置文件的目录权限出错,还有特殊的403,是找不到主页文件,会触发安全机制,报错403
56.nginx的404访问报错可能是什么原因?
找不到文件,路径出错
57.LNMP服务器运行原理?
在LNMP组合工作时,首先是用户通过浏览器输入域名请求nginx Web服务,如果请求是静态资源,则由nginx解析返回给用户;如果动态请求(php结尾),那么nginx就会把它通过FastCGI接口(生产常用方法)发送给PHP引擎服务(FastCGI进程php-fpm)进行解析,如果这个动态请求要读取数据库,那么PHP就会继续向后请求MySQL数据库,以读取需要的数据,并最终通过nginx服务把它获取的数据返回给用户,这就是LNMP环境的基本请求顺序流程。这个请求流程是企业使用LNMP环境的常用流程。
58.fastcgi是什么?它的客户端和服务端名字叫啥?
Fastcgi是以个高速的可伸缩的,在http服务器和动态语言间的通信接口。客户端叫fastcgi_pass 服务端叫php_fpm;
59.fastcgi服务端监听什么端口?
9000
60.在nginx配置文件里,哪行代码体现了fastcgi客户端和服务器的数据传输过程?
Fastcgi_pass 127.0.0.1:9000
61.什么叫做高可用?什么叫做单点故障?
就是没有单点问题的集群,单点就是坏任何一台服务器,集群就不能使用
62.手写一个简单的负载均衡配置文件(必须包含server模块和upsteam模块内容)
- 服务器池的名字www.pooks
(2)RS节点两个,IP地址为:192.168.200.100, 192.168.200.200
woerker_processes 1:
Events{
Worker_connections 1024;
}
http {
Lnclude mime.types;
Default_application/octet-stream;
Sendfile on;
Keepalive_timeout 65;
Upstream www_pools {
Server 192.168.200.100 weight=1;
Server 192.168.200.200 weight=1;
}
Server {
Listen80;
Server_name www.yunjiesuan.com;
Location /{
Proxy_pass http://www_pools;
}
}
}
63.新搭建的nginx反向代理,但后方节点RS的访问日志里没有用户的真实来源IP
请问这是为什么?以及如何让后方Web访问日志记录用户的真实来源IP地址。
因为反向代理是nginx发起一个全新的请求,所有web服务器记录的都是反向代理的ip想要记录真实的ip就要在反向代理的配置文件里的location里添加一下代码
Proxy_set_header x-forwarded-for $remote_addr.
64.新搭建的nginx反向代理,后面RS虚拟了两个网站,bbs和www。但是,我们发现无论用哪个bbs还是www域名访问反向代理时,只能看到RS的第一个bbs网站请问这是为什么?以及要如何避免这个问题?
用户请求过来的域名在反向代理重新发起请求的时候,到web服务器里是ip访问的,ip访问默认的从上往下排序,所以只会访问bbs,想要多虚拟域名方法需要在反向代理的配置文件里的location里添加以下代码
Proxy_set_header host $host;
65.什么叫做会话保持?Nginx反向代理服务器实现会话保持的三种方法?
就是验证的时候,是一个节点发的验证,回来的时候负载均衡可能会发给别的节点,链接不上就是回话保证不了,回来的时候能验证了就是回话保持。Ip_hash cookie共享 session共享。
66.简单描述网站图片盗链本质是什么?
本质就是将别人的资源服务器的url写到自己的主页里,浏览器读图片的时候回去别人的资源服务器找资源
67.nginx Web服务器图片访问基本流程原理?
浏览器先读取到图片的链接,然后重新发起个请求,在去取图片。
68.Linux常见系统发行版本有哪些?
答:RedHat、CentOS 、suse 、ubuntu 、fedora等
69.apache有几种工作模式,分别简述两种工作模式及其优缺点?
答:apache主要有两种工作模式:prefork(apache的默认安装模式) worker(可以在编译的时候添加—with-mpm=worker选项)
Prefork的特点是:
prefork MPM 使用多个子进程,每个子进程只有一个线程。每个进程在某个确定的时间只能维持一个连接。
预派生,这种模式可以不必在请求到来时再产生新的进程,从而减小了系统开销。
可以防止意外的内存泄露。
在服务器负载下降的时候会自动减少子进程数。
Worker的特点是:
worker MPM 使用多个子进程。每子进程有多个线程。每个线程在某个确定的时间只能维持一个连接。
某个确定的时间只能维持一个连接。
支持混合的多线程多进程的多路处理模块。
如果对于一个高流量的HTTP服务器,worker MPM是一个比较好的选择,因为worker MPM占用的内存要比prefork要小。
70. 简述/etc/fstab里面各个字段的含义?
答:因为mount挂载在重启服务器后会失效,所以需要将分区信球写到/etc/fstab文件中让它永久挂载:
磁盘分区 挂载目录 文件格式 设定的状态 备份标志位 开机是否检查
/dev/sdb1 /mnt/david ext4 defaults 0 0
- 。
71. FTP主被动模式原理
PORT(主动)方式的连接过程是:
客户端向服务器的FTP端口(默认是21)发送连接请求,服务器接受连接,建立一条命令链路当需要传送数据时,客户端在命令链路上用PORT命令高速服务器:我打开了XXXX端口,你过来连接我,于是服务器从20端口向客户端的XXXX端口发送连接请求,建立一条数据链路来传送数据。
72.主动模式和被动模式的不同简单概述为:
主动模式传送数据时是"服务器"连接到"客户端"的端口;被动模式传送数据是“客户端"连接到"服务器"的端口。
主动模式需要客户端必须开放端口给服务器,很多客户端都是在防火墙内,开放端口给FTP服务器访问比较困难。
被动模式只需要服务器端开放端口给客户端连接就行了。
73.Nginx优化30条
- 安全优化,隐藏Nginx版本号
答 sever_tokens off;在陪值文件里http段内添加
2) 安全优化:更改默认的Nginx服务用户
答 两种方法
第一种:直接编译的时候指定用户和组
./configure --user=nginx --group=nginx --prefix=/usr/local/nginx –with-http_stop_status_module –with-http_ssl_module
- 性能优化:根据硬件配置调整Nginx worker进程数企业面试题:输入top命令查看系统资源占用信息,在top命令界面如何查看多颗cpu的信息
答: worker_processes 1;几核就修改成几,查看cpu的方法top 按1。或者看/proc目录下的cpuinfo文件看processor
4)性能优化:绑定不同的讲程到不同的cpu上,资源平均分配企业面试题:命令如何通过命令调整到不同的进程或服务到不同的cpu上,让资源平均使用cpu?
答 在第二行插入代码worker_cpu_affinity 0001 0010 0100 1000
5)性能优化:nginx事件处理模型优化俄日epoll企业面试题: Nginx epoll和Apache select的区别?
答:在events模块里添加代码use epoll;
6)性能优化:调整每个Nginx worker进程的最大连接数。企业面试题:并发的概念,你的公司网站开友定多大, ip. pv多大?
答:worker_connections 20480;
7)性能优化:配置Nginx worker进程最大打开文件数特别提醒:配置参不是越大越好,最好设直到服务器承受的极限点
答:worker_rlimit_nofile 65535;
8)性能优化:开启Nginx高效的传输模式
答:sendfile on;
9)性能优化:调整各个超时参数,设置连接超时时间
答:keepalive_timeout 60;
client_header_timeout 15;
client_body_timeout 15;
send _timeout 25;
10)安全优化:上传文件大小限制(动态服务器web应用
答: client_max_body_size 8m;
11)Nginx FastCGl参数优化(根据http原理给面试官讲解)
答:fastcgiconnect_timeout 240; #Nginx允许fcgi连接超时时间
fastcgisend timeout 240, #Nginx允许fcgi返回数据的超时时间
fastcgiread_timeout 240; #Nginx读取fcgi响应信息的超时时间
fastcgibuffer_size 64k; #Nginx读取响应信息的缓冲区大小
fastegi buffers 4 64k; #指定Nginx缓冲区的数量和大小
fastcgi_busy_buffers_size 128k; #当系统繁忙时buffer的大小
fastcgi_temp_file_write_size 128k; #Nginx临时文件的大小
fastcgi_temp_path /data/ngx_fcgi_tmp: #指定Nginx临时文件放置路径
12)Nginx expires缓存优化
答:在location里添加expires 3650d; d是天,表示缓存3650天
13)性能优化: Nginx gzip压优化
答:gzip on;
#开启gzip压缩功能
gzipminlength 1k;容许压缩页面的最小字节
gzip_buffers 4 16K;缓冲4块,单位16k
gzip_http_version 1.1:压缩版本
gzip_comp level 2;压缩等级
gzip_types text/plain application/x-javascript text/css
application/xml压缩类型
gzip_vary on;
#vary header支持。该选项可以让前端的缓存服务器缓存经过gzip压缩的页面,例如用Squid缓存经过Nginx压缩的数据。
14)安全优化:更改源码隐藏软件名,及版本号
答:依次修改3个Nginx源码文件
1)/usr/src/nginx-1.6.2/src/core/ nginx.h
2) nginx-1.6.3/src/httpd/gnx_http_header_filter_module.c
3)nginx-1.6.3/src/http/nginx_http_special_response.c
第二步是修改后编辑软件,使其生效
15) 性能优化:Nginx日志相关优化
日志切割,不记录指定元素日志,最小化日志目录权限
16)安全优化:限制指定目录或指定扩展名的文件被访问
限制上传到资源目录的程序被访问,防止木马入侵
17)安全优化:限制来源ip客户端访问指定网站或目录
适合内部使用的网址,例如:phpmyadmin
18)用户体验优化:针对错误页面进行优雅显示优化
19)安全加性能优化:防爬虫优化
robot协议,根据HTTP_USER_AGENT进行控制
20)性能优化: 防盗链优化
21)安全优化: 严格设置集群中读写分离后的web站点目录权限
22) 安全优化:防止使用ip访问Nginx网站(防止非法域名恶意解析)
23)安全优化: 防DDOS攻击
单ip并发连接的控制,与连接效率控制
利用webbench压力测试一个网站,
24) 安全优化:防DDOS攻击策略
详见云计算阅读资科21:企业cdn网站加速相关技术精讲之附录1
25)安全优化: 限制客户端请求的HTTP方法
26)安全优化: 为web服务增加用户验证
适合内部机密网址
27)安全优化: Nginx加密传输优化(Nginx SSL)
28)安全优化: 上Nginx运行与(A Chroot jail (Containers))监牢模式
29)安全优化: 移除所有不需要的Nginx modules
- 安全优化: web服务器磁盘挂载及网络问卷系统优化
74.全部磁盘块由四个部发组成,分别为引导块、专用块、i节点表块和数据存储块
Linux系统中的每个文件都被赋予一个唯一的数值,这个数值称做索引节点。索引节点存储在一个称作索引节点表<inode table>中,该表在磁盘格式化时被分配。每个实际的磁盘或分区都有其自己的索引节点表。一个索引节点包含文件的所有信息,包括磁盘上数据的地址和文件类型。文件类型包括如普通文件、目录和特殊文件这样的信息。
Linux硬盘组织方式为:引导区、超级块(superblock)、索引节点(inode)、数据块(datablock)、目录块(diredtory block)。其中超级块中包含了关于该硬盘或分区上的文件系统的整体信息,如文件系统的大小等;超级块后面的数据结构是索引结点,它包含了针对某一个具体文件的几乎全部信息,如文件的存取权限、所有者、大小、建立时间以及对应的目录块和数据块等;数据块是真正存储文件内容的位置。但是索引结点中部包括文件的名字,文件名是放在目录块里包含有文件的名字以此文件的索引结点编号。
75.将/home/stud1/wang目录做归档压缩,压缩后生成wang.tar.gz文件,并将此文件保存到/home目录下,实现此任务的tar命令格式tar zcvf
/home/wang.tar.gz/home/syud1/wang
- 你是一个小型web系统的运维负责人,你们的网站经常收到cc和ddos攻击,请分别阐述下,您有什么思路防御这两种攻击
CC攻击防御策略
(1).取消域名绑定
具体操作步骤是:打开“IIS管理器“
定位到具体站点右键“属性”打开该站点的属性面板,点击IP地址右侧的定位到具体站点右侧的“高级“按钮,选择该域名项该域名项进行编辑,将“主机头值”删除或者改为其它的值(域名)。经过测试,取消域名绑定后W eb服务器的CPU 马上恢复正常状态,通过IP进行访问连接一切正常。但是不足之处也很明显,取消或者更改域名对于别人的访问带来了不便,另外,对于针对IP的CC攻击它是无效的,就算更换域名攻击者发现之后,他也会对新域名实施攻击。
(2).域名欺骗解析
如果发现针对域名的CC攻击,我们可以把被攻击的域名解析到127.0.0.1这个地址上。实现攻击者自己攻击自己的目的.
另外,当我们的Web 服务器遭受CC 攻击时把被攻击的域名解析到国家有权威的政府网站或者是网警的网站,让其网警来收拾他们。
(3).更改Web端口
一般情况下Web 服务器通过80 端口对外提供服务,因此攻击者实施攻击就以默认的80端口进行攻击,所以,我们可以修改W eb 端口达到防CC攻击的目的。
(4).屏蔽IP
通过命令或在查看日志发现了CC攻击的源IP,就可以在 IIS 中设置屏蔽该IP对W eb站点的访问,从而达到防范攻击的目的。
76. DDOS防御策略
仅仅依靠某种系统或产品放逐DDOS是不现实的,可以肯定的是,完全杜绝DDOS目前的不可能的,但通过适当的措施抵制90%的DDOS攻击是可以做到的,基于攻击和防御都有成本开销的缘故,若通过适当的办法增强了抵御DDOS的能力,也就意味着加大了攻击者的攻击成本,那么绝大多数攻击者将无法继续下去而放弃,也就相当于成功的抵御了
77.尽量避免NAT的使用
无论是路由器还是硬件防护墙设备要尽量避免采用地址转换NAT的使用,因为采用此技术会较大降低网络通信能力,其实原因很简单,因为NAT需要对地址来回转换,转换过程中需要对网络包的校验和进行计算,因此浪费了很多CPU的时间,但有些时候必须使用NAT,那就没有好办法了。
2)把网站做成静态页面
门户网站主要都是静态页面,若非需要动态脚本调用,那就把它弄到另外一台单独主机去,免的遭受攻击时连累主服务器,当然,适当放一些不做数据库调用脚本还是可以的,此外,最好在需要调用数据库的脚本中拒绝使用代理的访问
3)充足的网络带宽保证
网络带宽直接决定了能抗受攻击的能力,假若仅仅有10M带宽的话,无论采取什么措施都很难对抗现在的 SYNFlood攻击。
- 你平常遇到一个比较难的问题,一般是怎么处理的,请简述一次您调试|分析|处理问题的一个过程,要求写清楚问题是什么,排查的思路过程,遇到的障碍是怎么排除的,事后的改进措施,例如:
1.故障起因:
服务器遭受到黑客攻击,服务器被当成肉鸡一直DDOS外部网站,事情不大,但影响甚大,因为此主机不光负载过高,并且跑了1G的带宽,影响可想而知。刚开始接收到反馈出口带宽异常,同时接收到服务器带宽占用报警,我们所有主机都是加有基础监控模板的(Zabbix监控系统)。所以很快定位到了某主机异常,马上上监控看了流量图,从监控可以看出,带宽跑了1G且都是往外发包。
2.故障处理:
第一件事,立马对此机器进行断网处理,这个要看业务重要性来决定了。因为这样立马能够解决这个问题,而来给排查留下时间。
上了机器之后,第一件事就是top -c一下,既然往外发包就必然会产生进程。但是比较麻烦的是,不管是top -c还是ps aux都是只能看见进程,而看不见进程执行的绝对路径。这个时候查找php. php这个文件。经过分析大概意思就是一直对一个IP的80端口进行发包,建立套接字连接导致服务器负载过高的同时,往外大量发包。
3.线索排查:
问题解决了,接下来就是分析为什么会被挂马,首先查看这几种主要日志(一般都会被人清除的):登录日志(包括失败和成功)、历史操作命令、还有消息日志和安全日志都可以看一看。最重要的是看看有没有潜藏有用户,其实一般这种机器都会下架处理。
我们这边由于不是那么规范,每个机器都有大量用户登录,所以这个不太好排查。也没有审计工具之类的,只能把最近登录用户拉出来看看有没有离职用户还遗留有账号。
4.如何防护
设置iptables规则,只允许已经建立网络连接的用户从OUTPUT出去,针对所有的主机和协议。
78.说一件你通宵处理问题的事迹,是如何抗住压力与疲倦
我在上家公司刚转正后公司业务扩展需要加两台服务器,对数据库搭建高可用,因为老师傅不在,公司运维就我一个人在值班,以前一直没自主搭建过,但是既然任务下来了,我就得把任务拿下来,那次我一个人通过查资料和网上论坛询问,通宵搞定了。
没感觉到什么压力与疲倦。主要我很喜欢Linux的东西,越做越兴奋。
79.简述Linux文件系统通过i节点把文件的逻辑结构和物理结构转换的工作过程。
参考答案:
Linux通过i节点表将文件的逻辑结构和物理结构进行转换。
i节点是一个64字节长的表,表中包含了文件的相关信息,具甲有文件的大小、文件所有者、文件的存取许可方式以及文件的类型等重要信恳。在i节点表中最重要的内容是磁盘地址表。在磁盘地址表中有13个块号,文件将以块号在磁盘地址表中出现的顺序依次读取相应的块。Linux文件系统迪过把i节点和文件名进行连接,当需要读取该文件时,文件系统在当前目录表中食找该文件名对应的项,由此得到该文件相对应的i节点号,通过该i节点的磁盘地址表把分散存放的文件物理块连接成文件的逻辑结构。
7.简述进程的启动、终止的方式以及如何进行进程的查看。
参考答案:
80.在Linux中启动一个进程有手工启动和调度启动两种方式:
(1)手工启动
用户在输入端发出命令,直接启动一个进程的启动方式。可以分为:
1)前台启动:直接在SHELL中输入命令进行启动。
2)后台启动:启动一个目前并不紧急的进程,如打印进程。
(2)调度启动
系统管理员根据系统资源和进程占用资源的情况,事先进行调度安排,指定任务运行的时间和场合,到时候系统回自动完成该任务。
经常使用的进程调度命令为:at、batch、crontab
8.简述安装Slackware
参考答案
(1)对硬盘重新分区。
(2)启动Lmux系统(用光盘、软盘等)
(3)建立 Linux:主分区和交换分区。
(4)用 setup命令安装 Linux系统。
(5)格式化 Linux主分区和交换分区
(6)安装 Linux软件包
(7)安装完毕,建立从硬盘启动 Linux系统的L10启动程序,或者制作一张启动 Linux系统的软盘。重新启动 Linux系统。
81什么是静态路由,其特点是什么?什么是动态路由,其特点是什么?
参考答案:
静态路由是由系统管理员设计与构建的路由表规定的路由。适用于网关数量有限的场合,且网络拓朴结构不经常变化的网络。其缺点是不能动态地适用网络状况的变化,当网络状况变化后必须由网络管理员修改路由表。
动态路由是由路由选择协议而动态构建的,路由协议之间通过交换各自所拥有的路由信息实时更新路由表的内容。动态路由可以自动学习网络的拓朴结构,并更新路由表。其缺点是路由广播更新信息将占据大量的网络带宽。
198 进程的查看和调度分别使用什么命令?
参考答案:
进程查看的命令是ps和top
进程调度的命令有at, crontab, batch,kil
82.当文件系统受到破坏时,如何检查和修复系统?
参考答案:
成功修复文件系统的前提是要有两个以上的主文件系统,并保证在修复之前首先卸载将被修复的文件系统。使用命令fsck对受到破坏的文件系统进行修复。fsck检查文件系统分为5步,每步检查系统不同部分的连接特性并对上一步进行验证和修改。在执行fsck命令时,检查首先从超级块开始,然后是分配的磁盘块、路径名、目录的连接性、链接数目以及空闲块链表、i-node。
83解释i点在文件系统中的作用。
参考答案:
在inux文件系统中,是以块为单位存储信息的,为了找到某一个文件在存储空间中存放的位置,用节点对一个文件进行索引。I节点包含了描述一个文件所必须的全部信息。所以i节点是文件系统管理的一个数据结构。
84.什么是符号链接,什么是硬链接?符号链接与硬链接的区别是什么?
参考答案:
链接分硬链接和符号链接。
符号链接可以建立对于文件和目录的链接。符号链接可以跨文件系统,即可以链接分硬链接和符号链接。跨磁盘分区。符号链接的文件类型位是1,链接文件具有新的i节点。
硬链接不可以跨文件系统。它只能建立对文件的链接,硬链接的文件类型位是一,且硬链接文件的节点同被链接文件的i节点同被链接文件的i节点相同。
85.在对linux系统分区进行格式化时需要对磁盘簇(或i节点密度)的大小选行选择,请说明选择的原则。
参考答案:
磁盘簇(或i节点密度)是文件系统调度文件的基本单元。磁盘簇的大小,直接影响系统调度磁盘空间效率。当磁盘分区较大时,磁盘簇也应选得大些;当分区较小时,磁盘簇应选得小些。通常使用经验值。
86.简述网络文件系统NFS,并说明其作用
参考答案:
网络文件系统是应用层的一种应用服务,它主要应用于 Linux和 Linux系统、Linux和Unx系统之间的文件或目录的共享。对于用户而言可以通过NFS方便的访问远地的文件系统,使之成为本地文件系统的一部分。采用NFS之后省去了登录的过程,方便了用户访问系统资源。
87.Apache服务器的配置文件httpd.conf中有很多内容,请解释如
下配置项:
(1) MaxKeepAliveRequests 200
(2)UserDir public_html
(3)DefaultType text/plain
(4)AddLanguare en.en
(5)documentRoot"/usr/local/httpd/htdocs”
(6)addtypeapplication/x-httpd-php.php.php.php4
参考答案
(1)允许每次连接的最大请求数目,此为200;
(2)设定用户放置网页的目录;
(3)设置服务器对于不认识的文件类型的预设格式;
(4)设置可传送语言的文件给浏览器;
(5)该目录为 Apache放置网页的地方;
(6)服务器选择使用php4。
88.某Linxu主机的/etc/rc.d/rc.inetl文件中有如下语句,请修正错误,并解释其内容。
/etc/rc.d/rc.inetl:
……
ROUTE add –net default gw 192.168.0.101 netmask 255.255.0.0 metric 1
ROUTE add –net 192,168.1.0 gw 192,168.0.250 netmask 255.255.0.0
metric 1
参考答案:
修正错误:
- ROUTE应该为小写:route
- network 255.255.0.0应该为:netmask 255.255.255.0
- 缺省路由的子网掩码应改为 netmask0.0.0.0
- 缺省路由必须在最后设定,否则其后的路由将无效。
解释内容:
解释内容
(1) route:建立静态路由表的命令;
(2)add:增加一条新路由;
(3)net192.168.1.0:到达一个目标网络的网络地址;
(4) default:建立一条缺省路由;
(5)gw192.168.0.101:网关地址;
(6) metric 1:到达目标网络经过的路由器数(跳数)。
18.简述使用ftp进行文件传输时的两种登录方式?它们的区别是什么?常用的ftp文件传输命令是什么?
参考答案:
- ftp有两种登录方式:匿名登录和授权登录。使用匿名登录时,用户名为: anonymous,密码为:任何合法emai地址;使用授权登录时,用户名为用户在远程系统中的用户帐号,密码为用户在远程系统中的用户密码。
区别:使用匿名登录只能访问ftp月录下的资源,默认配置下只能下
载;而授权登录访问的权限大于匿名登录,且上载、下载均可。
(2)ftp文件传输有两种文件传输模式:ACI模式和 binary模式。sc模式用来传输文本文件,其他文件的传输使用 binary模式。
(3)常用的ftp文件传输命令为:bin. asc, put,get、mput、get、 prompt、bye
89.计算机中的端口总共有多少个
TCP0-65535、UDP0-65535也就是总共有65536*2=131072个端口
90.全局变量和局部变量有什么区别?是怎么实现的?操作系统和编译器是怎么知道的?
全局变量是整个程序都可访问的变量,谁都可以访问,生存期在整个程序从运行到结束(在程序结束时所占内存释放)而局部变量存在于模块(子程序,函数)中,只有所在模块可以访问,其他模块不可直接访问,模块结束(函数调用完毕).局部变量消失,所占据的内存释放。
操作系统和编译器,可能是通过内存分配的位置来知道的,全局变量分配在全局数据段并且在程序开始运行的时候被加载局部变量则分配在堆栈里面。
91.全局变量和局部变量有什么区别?实怎么实现的?操作系统和编译器是怎么知道的?
全局变量是整个程序都可访问的变量,谁都可以访问,生存期在整个程序从运行到结束(在程序结束时所占内存释放)而局部变量存在于模块(子程序,函数)中,只有所在模块可以访问,其他模块不可直接访问,模块结束(函数调用完毕),局部变量消失,所占据的内存释放。
操作系统和编译器,可能是通过内存分配的位置来知道的,全局变量分配在全局数据段并且在程序开始运行的时候被加载局部变量则分配在堆栈里面。
92.什么是静态网页,什么是动态网页?
答:静态网页是只能看,不能交换数据的网页,动态网页就是能交换数据,有数据库支持的网页。
93.分布式存储的最大的两个瓶颈在哪?
一个是网络宽带的问题,包括但不限于,本地的网路宽带,公网的网络宽带,还有一个是对于小文件的出来
94.linux的开机启动过程,
(1)主机加电自检,加载 BIOS 硬件信息。
(2)读取 MBR 的引导文件(GRUB、LILO)。
(3)引导 Linux 内核。
(4)运行第一个进程 init (进程号永远为 1 )。
(5)进入相应的运行级别。
(6)运行终端,输入用户名和密码。
95.linux系统里,你知道buffer和cache如何区分吗?
buffer和cache都是内存中的一块区域,当CPU需要写数据到磁盘时,由于磁盘速度比较慢,所以CPU先把数据存进buffer,然后CPU去执行其他任务,buffer中的数据会定期写入磁盘;当CPU需要从磁盘读入数据时,由于磁盘速度比较慢,可以把即将用到的数据提前存入cache,CPU直接从cache中拿数据要快的多。
96.查看当前谁在使用该主机用什么命令? 查找自己所在的终端信息用什么命令?
查找自己所在的终端信息:who am i
查看当前谁在使用该主机:who
97.在Linux系统下如何按照下面要求抓包:只过滤出访问http服务的,目标ip为192.168.0.111,一共抓1000个包,并且保存到1.cap文件中?
tcpdump -nn -s0 host 192.168.0.111 and port 80 -c 1000 -w 1.cap
98.我们可以使用哪个命令查看系统的历史负载(比如说两天前的)?
sar -q -f /var/log/sa/sa22 #查看22号的系统负载
99.说说TCP/IP的七层模型
应用层 (Application):网络服务与最终用户的一个接口。
协议有:HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
表示层(Presentation Layer):数据的表示、安全、压缩。(在五层模型里面已经合并到了应用层),格式有,JPEG、ASCll、DECOIC、加密格式等。
会话层(Session Layer):建立、管理、终止会话。(在五层模型里面已经合并到了应用层),对应主机进程,指本地主机与远程主机正在进行的会话。
传输层 (Transport):定义传输数据的协议端口号,以及流控和差错校验。协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层。
网络层 (Network):进行逻辑地址寻址,实现不同网络之间的路径选择。协议有:ICMP IGMP IP(IPV4 IPV6) ARP RARP
数据链路层 (Link):建立逻辑连接、进行硬件地址寻址、差错校验等功能。(由底层网络定义协议),将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正。
物理层(Physical Layer):是计算机网络OSI模型中最低的一层。物理层规定:为传输数据所需要的物理链路创建、维持、拆除,而提供具有机械的,电子的,功能的和规范的特性。简单的说,物理层确保原始的数据可在各种物理媒体上传输。局域网与广域网皆属第1、2层物理层是OSI的第一层,它虽然处于最底层,却是整个开放系统的基础。物理层为设备之间的数据通信提供传输媒体及互连设备,为数据传输提供可靠的环境,如果您想要用尽量少的词来记住这个第一层,那就是“信号和介质”。
NFS
1.NFS挂载原理?
当我们在NFS 服务器设置好一个共享目录/home/public后,其他的有权访问NFS
服务器的NFS客户端就可以将这个目录挂在到自己文件系统的某个挂载点,
这个挂载点可以自己定义,如上图客户端A与客户端B挂载的目录就不相同。并且
挂载好后我们在本地能够看到服务端/home/public的所有数据。如果服务器端配置的客户端只读,那么客户端就只能够只读。如果配置读写,客户端就能够进行读写。挂载后,NFS客户端查看磁盘信息命令:#df -h.
既然NFS是通过网络来进行服务器端和客户端之间的数据传输,那么两者之间要传输数据就要有相对应的网络端口,NFS服务器到底使用哪个端口来进行数据传输呢?基本上NFS这个服务器端口开在2049,但由于文件系统非常复杂。因此NFS还有其他的程序去启动额外的端口;这些额外的用来传输数据的端口是随机选择的,是小于1024的端口;既然是随机的那么客户端又是如何知道NFS服务器端到底使用的是哪个端口呢?这时就需要通过远程过程调用(Remote Procedure Call,RPC)协议来实现了!
2.NFS 服务的监听端口号?
NFS服务不监听任何端口,RPC服务监听端口
111
3.NFS在/etc/fstab里配置开机自动挂载失败了。为什么?
netfs服务需要开启否则失败
netfs服务让操作系统启动后载读取/etc/fstab 文件一遍
Lvs
1.说下LVS中NAT和DR模式的区别?
NAT模式:类似于防火墙的私有网络结构,负载调度器作为所有服务器节点的网关,作为客户机的访问入口,也是回应客户机的出口,由于私有IP和负载调度器都在同一物理网络,安全性很高
DR模式:采用半开放式网络结构,与TUN模式类似,但各节点并不是分散各地,与负载调度器在同一物理网络,负载调度器与各节点服务器通过本地网络连接,不需要建立专用IP隧道。但是安全可靠性不高。
2.详细说一下负载均衡群集的工作模式?
①TUN模式(IP隧道):
开放式的网络结构,负责调度仅作为客户机的访问入口,各节点通过各自的Internet连接直接回应客户机。而不再经过负载调度器,安全可靠性适中
②NAT模式(地址转换模式):
类似于防火墙的私有网络结构,负载调度器作为所有服务器节点的网关,作为客户机的访问入口,也是回应客户机的出口,由于私有IP和负载调度器都在同一物理网络,安全性很高。
③DR模式(直接路由):
采用半开放式网络结构,与TUN模式类似,但各节点并不是分散各地,与负载调度器在同一物理网络,负载调度器与各节点服务器通过本地网络连接,不需要建立专用IP隧道。但是安全可靠性不高。
3.扩展回答:你上家公司都负责多少台机器,它们都是干什么的?
1)请简述常见的群集开源软件有哪些?并说出他们的区别。
LVS特点是:
①首先它是基于4层的网络协议的,抗负载能力强,对于服务器的硬件要求除了网卡外,其他没有太多要求;
②配置性比较低,这是一个缺点也是一个优点,因为没有可太多配置的东西,大大减少了人为出错的几率;
③应用范围比较关,不仅仅对web服务器做负载均衡,还可以对其他应用(mysql)做负载均衡;
④LVS架构中存在一个虚拟IP的概念,需要向IDC多申请一个IP来做虚拟IP。
Nginx负载均衡器的特点是:
①工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构;
②Nginx安装和配置比较简单,测试起来比较方便;
③也可以承担高的负载压力且稳定,一般能力支撑超过上万次的并发;
④Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点,不过其中缺点就是不支持url来检测;
⑤Nginx对请求的异步处理可以帮助节点服务器减轻负载;
⑥Nginx能支持http和Email,这样就在适用范围上面小很多;
⑦默认有三种调度算法:轮询、weight以及ip_hash(可以解决会话保持的问题),还可以支持第三方的fair和url_hash等调度算法;
HAProxy的特点是:
①HAProxy是工作在网络7层之上(也可支持4层);
②支持Session的保持,Cookie的引导等;
③支持url检测后端的服务器出问题的检测会有很好的帮助;
④支持的负载均衡算法:动态加权轮询(Dynamic Round Robin),加权源地址哈希(Weighted Source Hash),加权URL哈希和加权参数哈希(Weighted Parameter Hash);
⑤单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度;
⑥HAProxy可以对Mysql进行负载均衡,对后端的DB节点进行检测和负载均衡。
DNS轮询:是做负载均衡最简单有效的实现方法,各方面代价都极低。
缺点是:由于没有检测机制,不够均衡,容错反应时间长。
F5:是一家叫F5 Networks的公司开发的四~七层交换机,软硬件捆绑。F5上负载均衡大多是基于NAT/SNAT,也可以实现Proxy,但用的较少,无论配置管理方便性、灵活性,性能和稳定性上都比较好;
4.简述LVS群集中DR模式的工作原理
Client向目标VIP发送请求,Director负载均衡器接受。
Director根据负载均衡算法选择真实服务器,不修改也不封装IP报文,将目标MAC地址修改为真实服务器MAC,由局域网发送。
真实服务器收到请求包,发现与本机VIP一致便开始处理,随后重新封装发给局域网。
Client收到回复包,服务完成。(Client不会知道具体哪台服务器提供了服务)
5.群集负载调度器技术有哪几种分发方式?
基于IP、基于端口、基于内容
6.基于IP负责调度技术有哪三种工作模式?
①Virtual server via NAT (VS-NAT) (地址转换)
②Virtual server via IP tunneling (VS-TUN) (IP隧道)
③Virtual Server via Direct Routing (VS-DR) (直接路由)
7.请简述LVS的八种算法都是什么?
①轮询调度 (Round Robin) (简称rr)
②加权轮询 (Weighted Round Robin) (简称wrr)
③最少链接 (Least Connections) (LC)
④加权最少链接 (Weighted Least Connections) (WLC)
⑤基于局部性的最少链接 (Locality-Based Least Connections) (LBLC)
⑥带复制的基于局部性最少链接 (Locality-Based Least Connections with Replication) (LBLCR)
⑦目标地址散列 (Destination Hashing) (DH)
⑧源地址散列 (Source Hashing) (SH)
8.lvs四层负载均衡和nginx七层反向代理的本质区别?
Lvs是转发,nginx是代理,代替,发起全新的请求
9.lvs有几种俱式,模式之间的本质区别在哪里
答:有4中模式,DR模式是利用mac地址转换的。tunnel模式是通过ip隧道技术的, nat模式是做一个dnat转换的fullnat是snat和dnat—起来
10. lvs负载均衡器上有几块网卡,他后边的web节点,在什么模式下也需要双网卡
答:两块,内外网且换,加上虚拟ip,在dr模式下
11.lvs的rd模式的原理
cip用户的请求先到网关,输入域名dns解析,出公网的ip. aip,网关做了dnat目标地址转换,转成vip, vip进行负载均衡从网关讲来以后就相同网段传输,依靠mac地址传输,网关牛要进行arn协议获取lvs的mac地址
12.描述一下LVS三种模式的工作过程?
LVS 有三种负载均衡的模式,分别是VS/NAT(nat 模式) VS/DR(路由模式) VS/TUN(隧道模式)
一、NAT模式(VS-NAT)
原理:就是把客户端发来的数据包的IP头的目的地址,在负载均衡器上换成其中一台RS的IP地址,并发至此RS来处理,RS处理完后把数据交给负载均衡器,负载均衡器再把数据包原IP地址改为自己的IP,将目的地址改为客户端IP地址即可期间,无论是进来的流量,还是出去的流量,都必须经过负载均衡器
优点:集群中的物理服务器可以使用任何支持TCP/IP操作系统,只有负载均衡器需要一个合法的IP地址
缺点:扩展性有限。当服务器节点(普通PC服务器)增长过多时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包的流向都经过负载均衡器。当服务器节点过多时,大量的数据包都交汇在负载均衡器那,速度就会变慢!
二、IP隧道模式(VS-TUN)
原理:首先要知道,互联网上的大多Internet服务的请求包很短小,而应答包通常很大,那么隧道模式就是,把客户端发来的数据包,封装一个新的IP头标记(仅目的IP)发给RS,RS收到后,先把数据包的头解开,还原数据包,处理后,直接返回给客户端,不需要再经过负载均衡器。注意,由于RS需要对负载均衡器发过来的数据包进行还原,所以说必须支持IPTUNNEL协议,所以,在RS的内核中,必须编译支持IPTUNNEL这个选项
优点:负载均衡器只负责将请求包分发给后端节点服务器,而RS将应答包直接发给用户,所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,就能处理很巨大的请求量,这种方式,一台负载均衡器能够为很多RS进行分发。而且跑在公网上就能进行不同地域的分发。
缺点:隧道模式的RS节点需要合法IP,这种方式需要所有的服务器支持”IP Tunneling”(IP Encapsulation)协议,服务器可能只局限在部分Linux系统上
三、直接路由模式(VS-DR)
原理:负载均衡器和RS都使用同一个IP对外服务但只有DR对ARP请求进行响应,所有RS对本身这个IP的ARP请求保持静默也就是说,网关会把对这个服务IP的请求全部定向给DR,而DR收到数据包后根据调度算法,找出对应的RS,把目的MAC地址改为RS的MAC(因为IP一致),并将请求分发给这台RS这时RS收到这个数据包,处理完成之后,由于IP一致,可以直接将数据返给客户,则等于直接从客户端收到这个数据包无异,处理后直接返回给客户端,由于负载均衡器要对二层包头进行改换,所以负载均衡器和RS之间必须在一个广播域,也可以简单的理解为在同一台交换机上
优点:和TUN(隧道模式)一样,负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端,与VS-TUN相比,VS-DR这种实现方式不需要隧道结构,因此可以使用大多数操作系统做为物理服务器。
缺点:(不能说缺点,只能说是不足)要求负载均衡器的网卡必须与物理网卡在一个物理段上。
MySQL
1.说一下mysql主从的原理
Mysql主从的原理呢;是这个样的 首先呢,master服务器将sql数据库改写的记录,放入bin-log日志当中,slave通过IO线程获取master上边的这个改变记录,同时呢IO线程启动dump线程,发送二进制日志,保存到salve上边的中继日志上。然后sql线程读取二进制日志,从而达到主从一致的目的。
2.全备,增备,热备,冷备分别阐述下你的理解
全备:数据库所有数据的一次完整备份,也就是备份当前数据库的所有数据
增备:就在上次备份的基础上备份到现在所有新增的数据
冷备:停止服务的基础上进行备份操作
热备:实行在线进行备份操作,不影响数据库的正常运行
全备在企业中基本上是每周或天一次,其它时间是进行增量备份
热备使用的情况是有两台数据库在同时提供服务的情况,针对归档模式的数据库
冷备使用情况有企业初期,数据量不大且服务器数量不多,可能会执行某些库、表结构等重大操作时
3.MySQL主要的索引类型
普通索引:是最基本的索引,它没有任何限制;
唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一;
主键索引:是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值;
组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合;
全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较,mysql中MyISAM支持全文索引而InnoDB不支持;
4.网站打开慢,给出排查方法,如果是数据库慢导致,如何排查并解决,分析举例
检查操作系统负载是否过高
登录mysql查看有哪些sql与占用时间过长,show processlist;
用explain查看消耗时间过长的SQL语句是否走了索引
对SQL语句优化,建立索引
5.MySQL有哪些日志
错误日志:记录出错信息,也记录一些警告信息或者正确的信息。
查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
慢查询日志:设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
二进制日志:记录对数据库执行更改的所有操作。
中继日志。
事务日志。
6.简述MyISAM和InnoDB的区别
MyISAM:不支持事务;支持表锁;支持全文索引;count()有变量存储,无需查全表;非聚簇索引
InnoDB:支持事务;支持行级锁;聚簇索引;
7.数据并发产生的问题
脏写:A事务修改了未提交的B事务修改过的数据
脏读:A事务读取到了未提交的B事务修改过的数据
不可重复读:A事务读取数据,B事务更新数据,A事务再次读的时候读取到了B事务更新过的数据
幻读:A事务从表中读取了一些行数据,B事务在该表中插入了一些新的行,A事务再次读取同一个表,发现多出几行。
8.事务的ACID特性
原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。
一致性(Consistency):一致性是指事务执行前后,数据从一个合法性状态变换到另一个合法性状态。
隔离性(Isolation):一个事务内部的操作及使用的数据对并发的其他事务是隔离的。
持久性(Durability):一个事务一旦被提交,此事务对数据库中数据的改变就是永久性的。
1:什么是mysql
mysql身为数据库是属于关系型还是非关系型。如果属于关系型或非关系型,请解释一下关系型数据库或者非关系型数据库的概念。优势又在哪。
答:1,MySQL属于关系型数据库。2关系型数据库的数据拥有固定的存储结构,通过库--表--行--列的方式存储,存储时会有表的结构化关系,过程如下:解析sql语句--连接层--磁盘存取--结构化成表。3,优势:容易理解,(二维表的结构非常贴近现实世界,二维表格,容易理解);使用方便,(通用的sql语句使得操作关系型数据库非常方便 );易于维护,(数据库的ACID属性,大大降低了数据冗余和数据不一致的概率)
9:sql语句的分类有三种,分别是DDL,DML,DCL。请简单概述一下这三种语句。
DDL:数据定义语言,用来建立数据库,数据对象和定义其列,如create、alter、drop;
DML:数据操纵语言,用来查询、插入、删除、修改数据库中的数据,如select、insert、update、delete;
DCL:数据控制语言,用来控制数据库组件的存取许可,存取权限等,如commit、rollback、grant、revoke;
10:什么是SQL,请简单概述一下。
答:结构化查询语言。
Sql是执行在客户端(windows在命令行下执行,linux在终端执行)下或者通过java代码执行在JDBC。
11:SQL语句规范,请简单概括一下。
1,以;(分号)结尾
2,关键字之间有空格,通常一个空格,但是有多个也没问题
3,sql语句中可以添加换行
4,SQL不区分大小写
12:什么是表。
表是数据库中的数据组成单位 类似于Java中的对象 表中的字段 对应对象中的属性。
1、查看所有数据库命令:
show databases;
2、创建数据库 通常一个项目只对应1个数据库 格式:create database 数据库名称;
create database db1;
3、查看数据库详情 -格式:show create database 数据库名称;
show create database db1;
4、删除数据库 -格式:drop database 数据库名称;
drop database db2;
5、选中数据库
use db2;
13.创建表
格式: create table 表名 (字段1名 字段类型,字段2名 字段类型);
create table person (name varchar(10),age int);
14.查看所有表
show tables;
15查看表结构
-格式:show create table 表名;
show create table person;
1、修改表名称 -格式: rename table 原名 to 新名;
rename table student to t_student;
2.查看表内详情
select * from person;
3.删除表
-格式: drop table 表名
drop table student;
5.修改hero表名为heros
rename table hero to heros;
16.什么是触发器
简单的说,就是一张表发生了某件事(插入、删除、更新操作),然后自动触发了预先编写好的若干条SQL语句的执行;
17.触发器的作用
监视某种情况,并触发某种操作(保证数据的完整性,起到约束的作用;)
18.MySQL-MMM优缺点 优点:高可用性,扩展性好,出现故障自动切换,对于主主同步,在同一时间只提供一台数据库写操作,保证的数据的一致性。 缺点:Monitor节点是单点,可以结合Keepalived实现高可用。
19.主键、外键
主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
外键:在一个表中存在的另一个表的主键称此表的外键。
20.为什么用自增列作为主键
如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引、
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、
如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
3.触发器的作用?
触发器是一种特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
21.什么是存储过程?用什么来调用?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。
调用:
1)可以用一个命令对象来调用存储过程。
2)可以供外部程序调用,比如:java程序。
22.存储过程的优缺点?
优点:
1)存储过程是预编译过的,执行效率高。
2)存储过程的代码直接存放于数据库中,通过存储过程名直接调用,减少网络通讯。
3)安全性高,执行存储过程需要有一定权限的用户。
4)存储过程可以重复使用,可减少数据库开发人员的工作量。
缺点:移植性差
23.什么叫视图?游标是什么?
视图:
是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改会影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:
是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
24.视图的优缺点
优点:
1对数据库的访问,因为视图可以有选择性的选取数据库里的一部分。
2)用户通过简单的查询可以从复杂查询中得到结果。
3)维护数据的独立性,试图可从多个表检索数据。
4)对于相同的数据可产生不同的视图。
缺点:
性能:查询视图时,必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,那么就无法更改数据
25.drop、truncate、 delete区别
最基本:
drop直接删掉表。
truncate删除表中数据,再插入时自增长id又从1开始。
delete删除表中数据,可以加where字句。
(1) DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2) 表和索引所占空间。当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
(3) 一般而言,drop > truncate > delete
(4) 应用范围。TRUNCATE 只能对TABLE;DELETE可以是table和view
(5) TRUNCATE 和DELETE只删除数据,而DROP则删除整个表(结构和数据)。
(6) truncate与不带where的delete :只删除数据,而不删除表的结构(定义)drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
(7) delete语句为DML(data maintain Language),这个操作会被放到 rollback segment中,事务提交后才生效。如果有相应的 tigger,执行的时候将被触发。
(8) truncate、drop是DLL(data define language),操作立即生效,原数据不放到 rollback segment中,不能回滚。
(9) 在没有备份情况下,谨慎使用 drop 与 truncate。要删除部分数据行采用delete且注意结合where来约束影响范围。回滚段要足够大。要删除表用drop;若想保留表而将表中数据删除,如果于事务无关,用truncate即可实现。如果和事务有关,或老师想触发trigger,还是用delete。
(10) Truncate table 表名 速度快,而且效率高,因为:?truncate table 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
(11) TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
(12) 对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
26.什么是临时表,临时表什么时候删除?
临时表可以手动删除:
DROP TEMPORARY TABLE IF EXISTS temp_tb;
临时表只在当前连接可见,当关闭连接时,MySQL会自动删除表并释放所有空间。因此在不同的连接中可以创建同名的临时表,并且操作属于本连接的临时表。
创建临时表的语法与创建表语法类似,不同之处是增加关键字TEMPORARY,
如:
CREATE TEMPORARY TABLE tmp_table (
NAME VARCHAR (10) NOT NULL,)
time date NOT NULL
select * from tmp_table;
27.非关系型数据库和关系型数据库区别,优势比较?
非关系型数据库的优势:
性能:NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
可扩展性:同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
关系型数据库的优势:
复杂查询:可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
事务支持:使得对于安全性能很高的数据访问要求得以实现。
28.什么是事务?
事务是对数据库中一系列操作进行统一的回滚或者提交的操作,主要用来保证数据的完整性和一致性。
29.事务四大特性(ACID)原子性、一致性、隔离性、持久性?
原子性(Atomicity):
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
一致性(Consistency):
事务开始前和结束后,数据库的完整性约束没有被破坏。比如A向B转账,不可能A扣了钱,B却没收到。
隔离性(Isolation):
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
持久性(Durability):
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
30.事务的并发?事务隔离级别,每个级别会引发什么问题,MySQL默认是哪个级别?
从理论上来说, 事务应该彼此完全隔离, 以避免并发事务所导致的问题,然而, 那样会对性能产生极大的影响, 因为事务必须按顺序运行, 在实际开发中, 为了提升性能, 事务会以较低的隔离级别运行, 事务的隔离级别可以通过隔离事务属性指定。
事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果因此本事务先后两次读到的数据结果会不一致。
3、幻读:幻读解决了不重复读,保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。
例如:事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作 这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。 而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有跟没有修改一样,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
事务的隔离级别
读未提交:另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据脏读
不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果因此本事务先后两次读到的数据结果会不一致。
可重复读:在同一个事务里,SELECT的结果是事务开始时时间点的状态,因此,同样的SELECT操作读到的结果会是一致的。但是,会有幻读现象
串行化:最高的隔离级别,在这个隔离级别下,不会产生任何异常。并发的事务,就像事务是在一个个按照顺序执行一样
31 .varchar和char的使用场景?
1.char的长度是不可变的,而varchar的长度是可变的。
定义一个char[10]和varchar[10]。
如果存进去的是‘csdn’,那么char所占的长度依然为10,除了字符‘csdn’外,后面跟六个空格,varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的。
2.char的存取数度还是要比varchar要快得多,因为其长度固定,方便程序的存储与查找。
char也为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率。
varchar是以空间效率为首位。
3.char的存储方式是:对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节。
varchar的存储方式是:对每个英文字符占用2个字节,汉字也占用2个字节。
4.两者的存储数据都非unicode的字符数据
32.请简述什么是冷备,温备,热备
冷备:数据库关闭状态下进行备份
热备:数据库运行状态下进行备份
温备:锁定数据库,只读不可写,再进行备份
33.进程状态除了S和R还有什么?
R(TASK_RUNNING),可执行状态
S(TASK_INTERRUPTIBLE),可中断的睡眠状态
D(TASK_UNINTERRUPTIBLE),不可中断的睡眠zhuangt
T(TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态
Z(TASK_DEAD – EXIT_ZOMBIE),退出状态或跟踪状态
X(TASK_DEAD -EXIT_DEAD),退出状态,进程即将被销毁
34.什么是进程什么是线程,并发和并行?
进程是资源分配的基本单位,有独立的空间
线程是CPU独立运行和独立调度的基本单位
并发是指可以处理多个同时发生的事情
并行是指可以同时处理多个事情
35.数据库起不来可能是什么原因,怎么解决?
主配置文件出错,非正常关闭导致mysql的snock号无法正常使用
解决方法:当snock出错时将原有的snock删除或改名即可
其他原因首先在主配置文件设置log-error错误日志,然后查看错误日志分析错误
36.经分析,确定你们公司的服务器遭受攻击,你该怎么处理?
首先上报领导,然后进行业务暂停或者转移,查看攻击位置和产生原因,然后重做系统
37.请说出下列端口号对应的服务,20,21,22,23,25,53,67,80,110,137,138,143,443,3306,8080?
20:ftp数据端口
21:ftp文件传输协议端口
22:安全shell(ssh)使用
23:(tcp)telnet服务
25:smtp简单邮件传输协议
53:dns域名解析服务
67:引导协议服务
80:http超文本传输协议
110:pop3邮局协议版本3
137:红帽企业samba使用的netbios名称服务
138:红帽企业samba使用的netbios数据服务
139:红帽企业samba使用的netbios会话服务
143:imap互联网消息存取协议
443:https安全超文本传输协议
3306:mysql的默认端口
8080:被用于www代理服务的
38.请说出防火墙的四表五链?
四表:
Raw:确定是否对数据包进行状态跟踪
Mangle:为数据包设置标记
Nat:修改数据包中的源目标IP地址或端口
Filter:确定是否被放行该数据包
五链:
Input:处理入站数据包
Output:处理出战数据包
Forward:处理转发数据包
Postrouting:在进行路由选择后处理数据包
Prerouting:在进行路由选择前处理数据包
39.工作遇到过的那些运维故障,怎么解决?请描述两个并解决?
(1)linux系统故障的一般处理思路
报错信息—>查阅日志文件-->分析定位问题-->解决问题
(2)linux系统无法启动原因及解决
系统无法启动的原因很多,常见的几种情况有:
①文件系统被破坏,常常因断电和非法关机引起文件系统结构不一致。
修复方法:用fsck命名强制修复,进入单用户模式或交互界面,按提示进入修改模式中,卸载对应的问题磁盘,然后用fsck命令修复,无法恢复的数据会存放在lost+found下。umount /dev/sda3 fsck.ext4 -y /dev/sda3
②系统配置/etc/fstab错误或丢失而无法启动。当启动时出现starting system logger后停止了,就要想办法恢复/etc/fstab文件,
利用linux rescue修复模式登录系统,从而获取挂载点和分区信息,重构/etc/fstab文件
③系统内核文件丢失,内核升级错误,引导程序出错,硬件故障等都会引起无法启动。
(3)linux网络故障处理思路流程
①检查权限是否打开,iptables,selinux
②服务是否正常,用telnet或netstat检查服务是否正常开启
③检查本机网络是否正常,ping自身IP、同网段主机、网关
④检查DNS解析是否正常,/etc/hosts和/etc/resolv.conf
⑤检测网卡ip设置,route检查路由是否正确
⑥检查网络硬件,网卡、路由器、集线器、网线、交换机(lsmod、ifconfig、ip)
故障举例:
inode耗尽故障:
当inode耗尽后,磁盘虽然有剩余空间,但也会出现no space left的报错
用df -i命令可以查看所有分区对应inode的使用情况
用ls -I nginx.log 能查看对应文件的inode编号。详细信息用stat nginx.log查看
针对inode耗尽的情况,清理删除那些无用的文件就可以了,尤其是那些碎小的文件
删除文件后空间不释放问题:
文件系统的数据分为两个部分:数据部分和指针部分,当有进程正在使用某个文件时,执行删除命令,空间是不会释放的,删除的是数据文件部分,指针部分并未删除,所以空间并不释放。
用 lsof | grep delete 查看已删除的文件,找到对应文件执行清空命令 echo “ ” > /tmp/nginx.log 空间就会得到释放。
40.磁盘报错“No space left on device”但是df -h查看磁盘空间并未满,原因?
No space left on device意思是磁盘空间不足,上述错误原因是inode韩进导致磁盘故障。
解决方法:①删除不使用的文件
②将文件备份重新格式化此系统文件,指定较多的inode个数
。
41.请详细描述mysql主从工作原理
主数据库(mysql)更新的数据写入二进制文件中,从数据库开启(读写)I/O线程,向主数据库请求数据同步,主数据库开启读写线程回应从数据库,从数据库收到主的二进制日志将写入有中继日志中,从数据库开启SQL线程将中继日志内容读写并执行,实现数据同步.
42.当mysql数据误删除后如何恢复?
当mysql数据误删除可以进行完全备份恢复和增量备份恢复
完全备份恢复:①每天都对mysql数据库的数据进行完全备份
②当出现事故时,首先恢复离事故最近的时间的完全备份
③其次在恢复完整备份时间点之后的事故发生时这一时间的binlog文件中记载的内容
增量备份:①每天都在完全备份或者增量备份后被修改的文件才会备份
②当事故发生时,首先恢复离事故最近的时间的完全备份,然后逐一恢复增量备份,直到事故发生最近的备份
43.客户打开网站变慢,请说出原因
网站页面显现的速度取决于许多的要素,包含服务器功能、网络传输质量、网站的带宽、DNS解析、页面内容包含涉及到的JS代码、图像和视频的巨细等等各种要素。
(1)网络最小宽带
这是最主要的要素,在慢的网站放在号的带宽下拜访速度相同快,网络的带宽包含对网站地点服务器带宽和用户端两个方位,对接点指的是出口端与进口端(如电信对网通的对接点)。
(2)DNS解析时刻
DNS解析包含往复解析的次数及每次解析所花费的时刻,它们两者的积即是DNS解析所耗费的时刻,因而,许多人无视了DNS的疑问,其实,DNS对网站解析速度也是十分重要的。
(3)机器的装备
包含服务器与客户机端的硬件装备程度,相同的网络环境下,双核的服务器的运算才干必定要强一些,毫无疑问的,相同的网络环境下,你用一台赛扬的机器和奔四双核处置器的电脑,翻开相同的页面,速度,也必定不相同。
(4)服务器软件
软件多少、安稳和软件的正确装备,都会影响到服务器环境,致使影响到网络速度。服务器装置软件防火墙,会献身一些网络速度,所以VPS、或独立服务器用户装一个防火墙足矣。
(5)页面内容的巨细(重要)
页面文件的巨细是网站是否能疾速翻开最重要一个要素,若是说服务器等硬件方面咱们决议不了,我强烈主张从这儿下手,不管是表格仍是DIV+CSS,恰当的优化代码,都能削减页面巨细。
尽量优化代码,用最少的代码,冗余代码也是拖慢网站速度之一。
(6)许多数据库操作
小网站在履行许多数据库操作时,也会影响网站翻开速度,这儿使asp+access布局的网站尤为显著,尤其是一起有许多用户提交谈论时,就操作数据库锁死,致使网站打不开。
(7)用许多javascript
网站上运用许多JS是大忌,不只搜索引擎无法录入,一起会不断提交恳求添加服务器担负,例如鼠标特效、节目的特效、状态栏的特效等等。这些特效的原理是先由服务器下载到你本地机器,然后在你本地机器上运转发生,然后你从看到的。特效做的多了,在你本地机器上就要运转大半天才干悉数完结,而若是你的主机装备通常的话,那就更慢了。所以成都网站建造主张一定要少用javascript特效
(8)页面上用大图像和FLASH
咱们晓得图像是拖慢网速最重要一个要素,图像通过处置,可以使图像空间变小,不然许多的图像一开始都会占用许多空间又使用网站翻开速度变得很慢,相同FLASH也是一个道理。
(9)过多引证了其他网站的内容
包含你引证其他网站的图像、视频文件等,若是直接在页面引证另外网站的东西,而那个网站的速度又慢,或许那个网站的该页面现已不存在了,那么你翻开的速度就会十分慢。
44请描述上家公司的架构
1)请简述什么是脑裂?脑裂如何发生及如何解决?
当两(多)个节点同时认为自己是唯一处于活动状态的服务器从而出现争用资源的情况,这种争用资源的场景即是所谓的”脑裂”(split-brain)或“区间集群”(partitioned cluster)。“
如何发生:网线断了或者防火墙没有关闭,导致接受不到返回的信息,所以主从均给自己配了VIP
如何解决:关闭主从的防火墙;查看网线是否断裂,如断裂更换便可以解决
2)MHA怎么实现高可用?
在MySQL故障切换过程中,MHA能最大程度上保证数据库的一致性,当MySQL
的主服务器出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所以其他的slave重新指向新的master,整个故障转移过程对应程序是完全透明的。
从宕机崩溃的master保存二进制日志文件(binlog events)
识别含有新的slave
应用从master保存的二进制日志文件
提升一个slave为新的master
使其他的slave链接新的master进行复制
3)360Atlas都有什么功能?
读写分离、从库负载均衡、IP过滤、自动分表、DNA可平滑上下线DB、自动摘除宕机的DB
45.你会写什么脚本?
实现日志切割:
#!/bin/bash
#cut_nginx_logs.sh
datetime=$(date -d “-1 day” “+%Y%m%d”) ---获取昨天的年月日
log_path=”/usr/local/nginx/logs”
pid_path=”/usr/local/nginx/logs/nginx.pid”
[ -d $log_path/backup ] || mkdir -p $log_path/backup
if [ -f $pid_path ] ---pid文件有就证明进程活着
then
mv $log_path/access.log $log_path/backup/access.log-$datetime
kill -USR1 $(cat $pid_path)
find $log_path/backup -mtime +30 |xargs rm -f ---30前改动的都删掉
Else
echo “Error,Nginx is not working!” | tee -a /var/log/messages ---不存在就报错
fi
146.Mysql数据库如何调优?都调哪些内容?
a)先对Mysql的优化技巧进行分析,然后进一步结合具体案例nat123服务器改了SQL端口分机连接不上的解决办法来进行分析
b)当写入时,使用innodb_flush_method=O_DIRECT来避免双缓冲;
c)避免使用 O_DIRECT 和 EXT3文件系统 -你将序列化所以要写入的
d)分配足够的 innodb_buffer_pool_size来加载整个InnoDB文件到内存中- 少从磁盘中读取;
e)不要将innodb_log_file_size参数设置太大,这样可以更快同时更多的磁盘空间 – 丢掉多的日志通常是好的,在数据库崩溃后可以降低恢复数据库的时间;
f)不要混用innodb_thread_concurrency和thread_concurrency参数 – 这2个值是不兼容的;
g)分配一个极小的数量给max_connections参数 – 太多的连接会用尽RAM并锁定MySQL服务;
h)保持thread_cache在一个相对较高的数字,大约16 – 防止打开连接时缓慢;
i)使用skip-name-resolve参数 – 去掉DNS查找;
j)如果你的查询都是重复的,并且数据不常常发生变化,那么使用查询缓存会让你感到失望;
k)接下来以史记案例服务器改了SQL端口分机连接不上的解决方法来进行分析:
l)问题分析:如果外网访问连接内网管家婆,一般的NAT映射是会改变访问端口的,导致应用不可连接,使用nat123全端口映射好可简单解决这问题
解决方法:使用nat123全端口映射,实现外网访问内网多端口、固定端口
应用方法:在内网安装nat123软件。
47.你是如何做系统优化的?都优化了哪些?
~不用root,添加普通用户,通过sudo授权管理。
~更改默认的远程连接SSH服务端口及禁止root用户远程连接
~定时自动更新服务器时间
~配置yum更新源,从国内更新源下载安装rpm包
~关闭selinux及iptable(IPtable工作场景如果有wan ip一般要打开,高并发除外)
~调整文件描述的数量。进程及文件的打开都会消耗文件描述符
~定时自动清理/var/spool/clientmquene/目录垃圾文件,防止inodes节点被占满
~精简开机自启动服务(crond,sshd,network,rsyslog)
~linux内核参数优化/etc/sysctl.conf,执行sysctl -p 生效
~更改字符集,支持中文,但建议还是使用英文字符集,防止乱码问题,不要使用中文
~锁定关键系统文件
chattr +I /etc/passwd /etc/shadow /etc/group /etc/gshadow /etc/inittab
~处理以上内容后包chattr.lsattr改名oldboy,这样就安全多了。
~清空/etc/issue,去除系统及内核版本登录前的屏幕显示
~清除无用的默认系统账户或组
48.shell编程熟练么?编写一个自动化备份mysql数据库的脚本?
#!/bin/bash
#mysql备份脚本
MY_USER=”admin”
MY_PASS=”123123”
MY_HOST=”192.168.1.108”
MY_CONN=”-u$MY_USER -P$MY_PASS-H $MY_HOST”
MY_DB1=”auth”
MY_DB2=”client”
BF_DIR=”/backup”
BF_CMD=”/use/local/mysqldump”
BF_TIME=$(date +%Y%m%d-%h%m)
NAME_1=”$MY_DB1-$BF_TIME”
NAME_2=”$MY_DB2-$BF_TIME”
[ -D $BF_DIR ] || mkdir -p $BF_DIR
cd $BF_DIR
$BF_CMD $MY_CONN – datebases $MY_DB1 > $NAME_1.sql
$BF_CMD $MY_CONN – datebases $MY_DB1 > $NAME_2.sql
/bin/tar zcf $NAME_1.tar.gz $NAME_1.sql – remove &> /dev/null
/bin/tar/zcf $NAME_2.tar.gz $NAME_2.sql – remove &> /dev/null
49.mysql如果主从不同不同步报错了怎么恢复?
首先检查NTP时间服务器是否正常工作(安装,配置,运行)
检查server-id是否配置有误
逐项排查配置文件,看是否录入错误
50.你在维护网络的过程中,曾经遇到过什么重大问题?怎么解决的?
服务器资源共享故障,无法将访问权限指定给用户
【故障现象】
整个网络使用的是Windows域,客户端是Windows7.服务器的IP设置为192.168.0.1,DNS是127.0.0.1,路由器的内部IP地址是192.168.0.1.客户端全部采用自动获取IP地址方式,并且同属于DomainUser组。在服务器设置共享文件的时候,虽然可以指定权限,但是无法访问。
【故障分析】
在Windows域中,都是使用NTFS权限和共享权限来设置共享文件夹的访问权限。不过NTFS权限是高于共享文件夹权限的,也就是说必须先为欲设置为共享的文件夹设置NTFS权限,然后再为其设置共享文件夹权限。如果两者发生冲突,那么将以NTFS权限为准。
【故障解决】
先为用户指定NTFS权限,然后再指定共享文件夹权限。例如需要给用户A创建一个共享文件夹TESTA,使该共享文件夹能够被用户A完全控制,而被其他任何用户访问,就要先设置TESTA的访问权限,为用户A指定“完全控制“权限,而为Everyone设置”只读“权限。同样,在设置共享文件夹权限的时候也要这样设置。
51.用命令查看http的并发请求数与其TCP链接状态?
netstat -n | awk ‘/^tcp/{++S[$NF]} END {for(a in S) print a,S[a]}
52.在SQL中对表进行增、删、改、查的命令都是什么?
创建表:create table 表名
删除表:drop table 表名
更改表中数据:update 表名 set 字段名=值 where 条件
查看表:show tables
53.现有14块100G的硬盘,分别用RAID0、RAID1、RAID5、RAID10组装后的大小分别为?
RAID0:1400G
RAID1:700G
RAID5:1300G
RAID10:700G
54.请简述linuxroot口令丢失后的解决过程?
Root密码丢失后解决GRUB:在引导装载程序菜单上,键入[e]来进入编辑模式。你会面对一个引导项目列表。查找其中类似以下输出的句行:kernel /vminux-2.4.18-0.4 ro root=/dev/hda2按箭头键直到这一行被突出显示,然后按[e]。你现在可在文本结尾处空一格再添加single来告诉GRUB引导单用户Linux模式。按[Enter]键来使编辑结果生效。你会被带回编辑模式屏幕,从这里,按[b],GRUB就会引导单用户Linux模式。结束载入后,你会面对一个与以下相似的shell提示:sh-2.05#现在,你便可以改变根命令,键入:bash#passwd root你会被要求重新键入口令来校验。结束后,口令就会被改变,你便可以在提示下键入reboot来重新引导;然后,像平常一样登录为根用户。LILO:当系统启动到出现LILO引导画面时,对于图形引导方式按TAB键进入对方文本方式,然后在LILO处输入linux single回车即可进入免密码的控制台,进入以后使用passwd命令修改root密码即可。
55.在一个IT系统中我们为了避免单点故障怎么办?
第一步:应该把页面里的权限设置好
第二步:写上标准的GetPermission()函数,在这个函数里,调用this.Authorization ()函数,将当前用户的相关权限获得,为接着按这些权限的处理工作做好准备
第三步:在页面的FormOnLoad事件中,调用获取权限的函数,这样这个页面在加载时,就可以调用这个函数了。
第四步:在后台配置好,我系统到底有哪些权限项目,进行授权,你可以做比较细的权限配置项目,也可以做一个比较粗的权限配置,可以将页面上进行了很细的控制进行对对一的映射,这样客户需要比较粗的权限控制,你就可以做个粗放的,客户需要细腻的权限控制,你就做个很细腻的权限控制,可以根据客户的需要灵活进行定义。
56请简述编写故障报告的要点内容为?
一、背景概述 二、事件概述 三、故障处理情况 四、应对措施 五、事件分析
六、经验总结 七、改进措施
或者or
一、故障概况 二、影响范围 三、故障详细描述 四、故障诊断 五、故障恢复 六、总结
57.如果某一天你误执行rm -rf*,会有哪些情况发生?
电脑中的没有权限的文件都会删掉,系统命令被删除无法使用,grub.conf被删除,系统开机无法引导,整个系统难以正常运转。
58.MySQL改了IP,会出现什么情况怎么解决?
不会影响现有数据,因为MySQL保存的数据不依赖IP
更换IP需要检查MySQL监听是否正常,有必要重启MySQL进程
netstat -ntlp
应用如果绑定了旧的IP会导致无法读写数据库
59.CDN的原理是什么?
cdn就是静态缓存 +只能解析。
A分布:在全国分布cdn节点,就是服务器群组,比如华东节点 广东网通广东电
信,华北节点北京网通电信,华中武汉教育网节点。
B镜像:然后把你网站静态的内容,比如图片、下载等资源镜像到各地的服务器上
C智能分析:用户访问的时候,根据ip判断是网通还是电信,是海南的还是东北的,然后连接到最近的服务器节点上去。
CDN适合静态的,动态的实际上还是要回到源服务器调用,中间多了一个环节反而更慢。建议用cdn加速网站静态部分
CDN的全称是Content Delivery Network,即内容分发网络。其目的是通过在现有的Internet中
增加一层新的网络架构,将网站的内容发布到最近用户的网络“边缘”,使用户可以就近取得所需内容,
解决Internet网络拥挤的状况,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小,
用户访问量大、网点分布不均等原因所造成的的用户访问网站响应速度慢的问题。
60.如何备份大数据库MySQL数据文件?MySQL优化有哪些步骤?
Xtrabackup可以做什么
- 在线(热)备份整个库的InnoDB、XtraDB表
- 在xtrabackup的上一次整库备份基础上做增量备份 (innodb only)
- 以流的形式产生备份,可以直接保存到远程机械上(本机硬盘空间不足时很有用)
MySQL数据库本身提供的工具并不支持真正的增量备份,二进制日志恢复是
point-in-time(时间点)的恢复而不是增量备份。Xtrabackup工具支持对InnoDB存储
引擎的增量备份,工作原理如下:
- 首先完成一个完全备份,并记录下此时检查点的LSN(Log Sequence Number)。
- 在进程增量备份时,比较表空间中每个页的LSN是否大于上次备份的的LSN,如果是,则备份该页,同时记录当前检查点的LSN。首先,在logfile中找到并记录最后一个checkpoint("last checkpoint LSN").然后开始从LSN的位置开始拷贝InnoDB的logfile到xtrabackup logfile;接着,开始拷贝全部的数据文件.ibd;在拷贝全部数据文件结束之后,才停止拷贝logfile。因为logfile里面记录全部的数据修改情况、所以,即时在备份过程中数据文件被修改过了、恢复时仍然能够通过解析xtrabackup_logfile保持数据的一致。
61.Linux服务器CPU负载很高、IO高网卡流量大怎么处理?
内存使用过高处理方法:
查询手段
使用top查看.
处理方法
- 将没有用的进程杀掉
- 查看占用进程高的应用的日志,对其相应用的优化
- 增加内存或者通过pstack这些工具去查对进程的pid对系统调用的情况来
定位故障原因。
3、_Linux服务器CPU负载很高、IO高网卡流量大怎么处理?
内存使用过高处理方法:查询手段
使用top查看.处理方法
1、将没有用的进程傻吊
2、查看占用进程高的应用的日志,对其相应用的优化
3、增加内存或者通过pstack这些工具去查对进程的pid对系统调用的情况来
定位故障原因。
CPU负载过高处理方法:
查询手段:
CPU资源负载过高,可以通过使用top命令查出对应cpu资源使用率高的进程。
分析原因:
根据进程判断是什么应用,再去查对应应用的访问量大小,以及日志定位是因为访问量过大导致,还是因为性能的原因导致。
处理方法:
如果是访问量导致的,那就要考虑服务器扩容,通过lvs做服务的负载均衡来分担了。
如果是性能的问题,通常通过日志可以查到慢查询的代码的。将查询的日志整理给到开发,让开发去做优化就可以了负载。
IO负载过高处理方法
查询手段
IO过高,可通过iOSat与iotop去检查,iotop可以查到哪个及|昵称的IO比较高的,
也用同样的方法去查原因。
分析原因:
IO比较高通常出现在数据库或写的日志量非常大,或应用访问量非常大而产生大量的日志写磁盘的原因导致的。
处理方法:
因为读写数据库导致IO过高,通常是慢查询的导致的,可以查mysql的慢查询的命令,让开发去做优化。
如果是web访问量过大而导致大量写日志的,可以考虑暂时将日志关闭,或优化日志,将部分对查障没有帮助的日志采用屏蔽的方法减低日志写入磁盘的量的方法减小IO。
比如有些开发可能会对php或Tomcat或resin开debug的,这种日志可以关掉的。
Nginx的日志格式也可以调用,可以屏蔽掉部分关键字的日志输出的。
62.负载均衡与反向代理区别?
反向代理代理的是服务器。是从客户端连接的角度来看。对于客户端来说,它看不到后面的真正的应用服务器
而负载均衡是前段进行资源负载分配调度,让多台相同功能的服务器实现尽可能类似的负载。从而最大化效率
两者目的不一样,但是最终实现有点相同
63.你们公司的网络出口带宽是多少?每天网站的PV、UV不同IP,最高并发是多少?
可以用#ethtool eth0 命令来查看网络出口带宽,
Pv(访问量):即Page View,即页面浏览量或点击量,在一定统计周期内用户每次刷新网页一次即被算一次。
UV(独立访客)︰即Unique ViSitor,访问您网站的一台电脑客户端为一个访客。00.00-24:00内相同的客户端只被计算一次。
IP(独立IP)︰即Internet Protocal,指独立IP数。00:00-24:00内相同IP地址只被计算一次。
64.关于Linux内核优化的几个方向:
(1)ulimit open文件数限制,
(2)系统最大poot数
(3) Time wait快速回收
(4) TCP三次握手
(5)应用程序优化等
65.你用过的服务器型号有哪些?配置如何?
生产企业:戴尔(中国)有限公司
刀片式服务器结构: 2U
品牌: Dell/戴尔
型号:R730 E52603v3 8G 2*1TB
接口类型: SAS
最大支持CPU个数: 2个
标配内存:8GB
硬盘容量:自定义
处理器主频: 1.7GHz
售后服务:全国联保
服务器类型:机架式
处理器类型:其他/other
依据不同配置(参考电脑高中低配置,价格在1W到2W之间)
(图自己查去)
66.你们公司使用的服务器版本是什么?
CentOS6.5
67.简述Dell R7x0硬RAID的配置步骤?
当dell界面过去后按下ctrl +r进入raid 配置界面
然后按F2选择第一项(Create New VD)创建新的RAID
进入到下面的界面,蓝色体的为选中状态,此时光标移动到RAID level那一栏,继续回车
此时出现RAID选项,仅有硬盘满足的条件下才会出现相应的选项,不能满足的选项不会出现。
选择需要做的选项比如RAID-0,然后在三块硬盘中选择需要做的硬盘,tab 键移动到该位置选择用空格键就可以,最后选择ok。
最后按esc准备保存退出,弹出下图窗口选择ok。
出现* Press Control+Alt +Delete to reboot **后,根据提示操作就可以了
create database yunjisuan;
68.删除一个叫做yunjisuan的库?
drop database yunjisuan;
69.查看mysql.user表里的user,host,password字段的所有数据
select user,host,passwor from mysql.user;
70.MySQL插入一条数据(写语句的架构即可)
lnsert into<表名> values('值1','值2。。。);
Insert into<表名>(字段名1,字段名2) values('值1∵'值2')
71.MySQL更新一条数据(写语句的架构即可)
update<表名>set字段名='值";
update<表名>set字段名='值' where字段名=‘值";
72.MySQL删除一条数据(写语句的架构即可)
delete from /where字段名='值';
73.授权账号yunjisuan拥有192.168.200.0/24网段的所有登陆和修改权限,密码333333 :grant all on *.* to 'yunjisuan'@'%’ identified by '333333";
74.让mysql的设置立刻生效(刷新)
flush privileges;
75.查看当前用户的·权限记录show grants;
76.查看yunjisuan@"192.168.200.%"账号的权限记录答:
show grants for 'yunjisuan'@'192.168.200.%'
77.修改账户yunjisuan@'192.168.200.%'的密码为:666666
答: update mysql.user set password=password('666666') where user=yunjisuan;
78.什么叫慢查询日志,它用来做什么的?如何打开慢查询日志(配置文件命
令)
答:就是以条语句执行的时间过长,会被记录答慢查询日志。
Long_query_time=5
Log-solw-queries=mysql_slow.log
79.索引的分类(五种)
答:普通,唯一,主键,单列及多列,全文。
80.事务的四个属性
答:一致性,原子性.隔离性,持久性
81.查看系统内置变量autocommit的信息
答: show variables like '%autocommit%;
82.mvsal数据库的全备命令(备份所有的库所有的表)
答: mysgldump -u账号-p密码--opt --all-databases >文件路径
83.msyal数据库备份指定库(benet,yunjisuan)的命令
答: mysqldump -u账号-p密码--databases benet,yunjIsuan >文件路径
84.MySOL数据库开启二进制日志的配置文件的参数是什么?
答:log-bin=mysql-bin
85.控制MySOL二进制日志大小的参数是什么?
答: max_binlog_size=102400
86.MySOL数据库强制刷新binlog日志的配置文件参数
答:flush logs;
87.MylSAM引擎的特点(三条)
答:不支持事物。表级锁定,读写阻塞
88.InnoDB引擎的特点(三条)
答:支持事物,行级锁定,具有非常高的缓存性能。
89.MySQL 临时锁表只读命
令flush table with read lock;
90.MySQL解除临时锁表只
读命令unlock tables;
91.开启MySQL中继日志的配置文件参数
relay-log=relay-bin
92.输入命令临时跳过一条 sql线程的解析的命令
set global sql_slave_skip_counter=1
93.MySQL主从复制延迟时间,在哪里查看?(写出参数)
show slave
statuslG;
Last_SQL_Errn
o:0
94.MySQL 主从复制延迟时间大,都有哪些可能的原因及你建议的解决办法?
主从复制有延迟,是正常的,但是绝对不能超过3秒,一旦超过3秒,就必须紧急处理,你要找出延迟的问题可能在哪?
- 设备问题,我们知道一般来说主库的硬件性能通常会比从库好,所以提高从库的硬件性能
- 可能会有慢SQL更新语句,一条SQL语句执行时间过长,假如有一条10秒的SQL,那么主库和从库之间数据延迟就至少是10秒了。因此,开启慢查询日志。记录SQL执行时间过长的语句、然后通知开发人员对SQL语句进行优化
- 根据数据库,SQL线程为单线程解析relaylog,5.6x版本SQL线程为一个小库一个SQL线程,5.7x版本数据库为SQL线程的解析和提交都变成了以组为单位进行,换句话,批量解析relaylog,批量执行在本地。
- 也许是从库数量太多,从库越多,主库就需要复制越多份的binlog日志,对主库的压力过大,或者主库承受的并发量过大,导致binlog日志复制给从库出现延迟
- 是不是网络延迟问题,测试主库到从库之间的网络延迟。Ping一下就知道了
95.假如MySQL的binlog日志把系统盘空间占满了,你如何在不影响数据安全的情况下解决这个问题?
为了保证恢复的完整性,我们得开启binary log功能,同时binlog给恢复工作也带来了很大的灵活性,可以基于时间点或是位置进行恢复。考虑到数据库性能,我们可以将binlog文件保存到其他安全的硬盘中。
96.MySQL5.6x版和MySQL5.7x版本的数据库有什么新特性?
5.6x版本SQL线程为一个小库一个SQL线程,5.7x版本数据库为SQL线程的解析和提交都变成了以组为单位进行,换句话,批量解析relaylog,批量执行在本地。
97.新安装的mysql 设置root密码的命令
mysqladmin -uroot password '123123';
98.创建一个叫做yunjisuan的库?
99.MHA故障切换转移原理
MHA由两部分组成:MHA Manager(管理节点)和MHA Node (数据节点)
MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群、
也可以部署在一台Slave上。把主库master的binlog日志复制
当Master出现故障时,系统会找出relay-log日志最全的从库slave
然后将其relay-log同步到其他从库,提升此从库slave为新的主宰
并让所有其余的从库重新只想新的主库,同时把复制出来的binlog日志放到新的主库中。
100.MySQL的从库的relay-log日志如果太大了怎么办?
全备之后直接删掉、或者在配置文件限制了一个日志的大小,自动切割,或者做一个自动切割的脚本。
101.MHA的MySQL高可用架构,如何解决MHA管理端的单点问题?
在每一个mysql服务器上加一个mha管理端
102mysql数据库的备份还原是怎么做的?
答:平时采用两种方法来做:
- 利用mysql自带的使用工具mysqldump和mysql来备份还原数据库。
- 利用第三方的mysql管理工具比如:mysqladmin。
停止mysql服务拷贝数据文件
103.现在给你三百台服务器,你怎么对他们进行管理?
管理3百台服务器的方式:
1)设定跳板机,使用统一账号登录,便于安全与登录的考量。
2)使用salt、ansiable、puppet进行系统的统一调度与配置的统一管理。
3)建立简单的服务器的系统、配置、应用的cmdb信息管理。便于查阅每台服务器上的各种信息记录。
104.简述raid0 raid1 raid5 三种工作模式的工作原理及特点
RAID,可以把硬盘整合成一个大磁盘,还可以在大磁盘上再分区,放数据
还有一个大功能,多块盘放在一起可以有冗余(备份)
RAID整合方式有很多,常用的:0 1 5 10
RAID 0,可以是一块盘和N个盘组合
其优点读写快,是RAID中最好的
缺点:没有冗余,一块坏了数据就全没有了
RAID 1,只能2块盘,盘的大小可以不一样,以小的为准
10G+10G只有10G,另一个做备份。它有100%的冗余,缺点:浪费资源,成本高
RAID 5 ,3块盘,容量计算10*(n-1),损失一块盘
特点,读写性能一般,读还好一点,写不好
冗余从好到坏:RAID1 RAID10 RAID 5 RAID0
性能从好到坏:RAID0 RAID10 RAID5 RAID1
成本从低到高:RAID0 RAID5 RAID1 RAID10
单台服务器:很重要盘不多,系统盘,RAID1
数据库服务器:主库:RAID10 从库 RAID5RAID0(为了维护成本,RAID10)
WEB服务器,如果没有太多的数据的话,RAID5,RAID0(单盘)
有多台,监控、应用服务器,RAID0 RAID5
我们会根据数据的存储和访问的需求,去匹配对应的RAID级别
Tomcat
1.tomcat 如何优化?
改Tomcat最大线程连接数
需要修改conf/server.xml文件,修改里面的配置文件:
maxThreads=”150”//Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可 创建的最大的线程数。默认值200。可以根据机器的时期性能和内存大小调整,一般 可以在400-500。最大可以在800左右。
Tomcat内存优化,启动时告诉JVM我要多大内存
调优方式的话,修改:
Windows 下的catalina.bat
Linux 下的catalina.sh
修改方式如:
JAVA_OPTS=’-Xms256m -Xmx512m’-Xms JVM初始化堆的大小-Xmx JVM堆的最大值 实际参数大
2.Tomcat工作模式?
Tomcat作为servlet容器,有三种工作模式:
1、独立的servlet容器,servlet容器是web服务器的一部分;
2、进程内的servlet容器,servlet容器是作为web服务器的插件和java容器的实现,web服务器插件在内部地址空间打开一个jvm使得java容器在内部得以运行。反应速度快但伸缩性不足;
3、进程外的servlet容器,servlet容器运行于web服务器之外的地址空间,并作为web服务器的插件和java容器实现的结合。反应时间不如进程内但伸缩性和稳定性比进程内优;
进入Tomcat的请求可以根据Tomcat的工作模式分为如下两类:
Tomcat作为应用程序服务器:请求来自于前端的web服务器,这可能是Apache, IIS, Nginx等;
Tomcat作为独立服务器:请求来自于web浏览器;
3.Tomcat是什么?
Tomcat 服务器Apache软件基金会项目中的一个核心项目,是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用。
比方说,我有个web项目是想让他运行,就可以在运行在tomcat平台上,如果开启就可以运行访问,如果停掉tomcat服务,那么无法访问了
4.Tomcat的缺省端口是多少,怎么修改
默认8080
修改端口号方式
找到Tomcat目录下的conf文件夹
进入conf文件夹里面找到server.xml文件
打开server.xml文件
在server.xml文件里面找到下列信息
把Connector标签的8080端口改成你想要的端口
5.怎么在Linux上安装Tomcat
先去下载Tomcat的安装包,gz结尾的(代表Linux上的Tomcat)
上传到Linux上,解压
修改端口号,也可以不修改把。如果要修改在server.xml内改
修改好了之后,你就进入你这个tomcat下的bin目录,输入:./startup.sh
这样就启动成功了。
6.怎么在Linux部署项目
先使用eclipse或IDEA把项目打成.war包,然后上传到Linux服务器,然后把项目放在Tomcat的bin目录下的webapps,在重启Tomcat就行了。
7.Tomcat的目录结构
/bin:存放用于启动和暂停Tomcat的脚本
/conf:存放Tomcat的配置文件
/lib:存放Tomcat服务器需要的各种jar包
/logs:存放Tomcat的日志文件
/temp:Tomcat运行时用于存放临时文件
/webapps:web应用的发布目录
/work:Tomcat把有jsp生成Servlet防御此目录下
类似Tomcat,发布jsp运行的web服务器还有那些:
8.Resin
Resin提供了最快的jsp/servlets运行平台。在java和javascript的支持下,Resin可以为任务灵活选用合适的开发语言。Resin的一种先进的语言XSL(XML stylesheet language)可以使得形式和内容相分离。
9.Jetty
Jetty是一个开源的servlet容器,它为基于Java的web内容,例如JSP和servlet提供运行环境。Jetty是使用Java语言编写的,它的API以一组JAR包的形式发布。开发人员可以将Jetty容器实例化成一个对象,可以迅速为一些独立运行(stand-alone)的Java应用提供网络和web连接。
10.WebLogic
BEA WebLogic是用于开发、集成、部署和管理大型分布式Web应用、网络应用和数据库应用的Java应用服务器。将Java的动态功能和Java Enterprise标准的安全性引入大型网络应用的开发、集成、部署和管理之中。
11.jboss
Jboss是一个基于J2EE的开放源代码的应用服务器。 JBoss代码遵循LGPL许可,可以在任何商业应用中免费使用,而不用支付费用。JBoss是一个管理EJB的容器和服务器,支持EJB 1.1、EJB 2.0和EJB3的规范。但JBoss核心服务不包括支持servlet/JSP的WEB容器,一般与Tomcat或Jetty绑定使用。
12.tomcat 如何优化?
改Tomcat最大线程连接数
需要修改conf/server.xml文件,修改里面的配置文件:
maxThreads=”150”//Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可 创建的最大的线程数。默认值200。可以根据机器的时期性能和内存大小调整,一般 可以在400-500。最大可以在800左右。
Tomcat内存优化,启动时告诉JVM我要多大内存
调优方式的话,修改:
Windows 下的catalina.bat
Linux 下的catalina.sh
修改方式如:
JAVA_OPTS=’-Xms256m -Xmx512m’-Xms JVM初始化堆的大小-Xmx JVM堆的最大值 实际参数大
13.tomcat 有哪几种Connector 运行模式(优化)?
下面,我们先大致了解Tomcat Connector的三种运行模式。
BIO:同步并阻塞 一个线程处理一个请求。缺点:并发量高时,线程数较多,浪费资源。Tomcat7或以下,在Linux系统中默认使用这种方式。
配制项:protocol=”HTTP/1.1”
NIO:同步非阻塞IO
利用Java的异步IO处理,可以通过少量的线程处理大量的请求,可以复用同一个线程处理多个connection(多路复用)。
14.Tomcat8在Linux系统中默认使用这种方式。
Tomcat7必须修改Connector配置来启动。
配制项:protocol=”org.apache.coyote.http11.Http11NioProtocol”
备注:我们常用的Jetty,Mina,ZooKeeper等都是基于java nio实现.
APR:即Apache Portable Runtime,从操作系统层面解决io阻塞问题。
AIO方式,异步非阻塞IO(Java NIO2又叫AIO) 主要与NIO的区别主要是操作系统的底层区别.可以做个比喻:比作快递,NIO就是网购后要自己到官网查下快递是否已经到了(可能是多次),然后自己去取快递;AIO就是快递员送货上门了(不用关注快递进度)。
配制项:protocol=”org.apache.coyote.http11.Http11AprProtocol”
备注:需在本地服务器安装APR库。Tomcat7或Tomcat8在Win7或以上的系统中启动默认使用这种方式。Linux如果安装了apr和native,Tomcat直接启动就支持apr。
15.Tomcat有几种部署方式?
在Tomcat中部署Web应用的方式主要有如下几种:
利用Tomcat的自动部署。
把web应用拷贝到webapps目录。Tomcat在启动时会加载目录下的应用,并将编译后的结果放入work目录下。
使用Manager App控制台部署。
在tomcat主页点击“Manager App” 进入应用管理控制台,可以指定一个web应用的路径或war文件。
修改conf/server.xml文件部署。
修改conf/server.xml文件,增加Context节点可以部署应用。
增加自定义的Web部署文件。
在conf/Catalina/localhost/ 路径下增加 xyz.xml文件,内容是Context节点,可以部署应用。
16.tomcat容器是如何创建servlet类实例?用到了什么原理?
当容器启动时,会读取在webapps目录下所有的web应用中的web.xml文件,然后对 xml文件进行解析,并读取servlet注册信息。然后,将每个应用中注册的servlet类都进行加载,并通过 反射的方式实例化。(有时候也是在第一次请求时实例化)
在servlet注册时加上1如果为正数,则在一开始就实例化,如果不写或为负数,则第一次请求实例化。
17.Tomcat工作模式
Tomcat作为servlet容器,有三种工作模式:
1、独立的servlet容器,servlet容器是web服务器的一部分;
2、进程内的servlet容器,servlet容器是作为web服务器的插件和java容器的实现,web服务器插件在内部地址空间打开一个jvm使得java容器在内部得以运行。反应速度快但伸缩性不足;
3、进程外的servlet容器,servlet容器运行于web服务器之外的地址空间,并作为web服务器的插件和java容器实现的结合。反应时间不如进程内但伸缩性和稳定性比进程内优;
进入Tomcat的请求可以根据Tomcat的工作模式分为如下两类:
18.tomcat四中基础的安全优化一种基础性能优化?
基础安全优化降权启动Telent管理端口保护,ajp连接端口管理,禁用管理端,性能调优屏蔽dns查询。
19.生产环境下某台tomcat7服务器,在刚发布的时候一切都很正常,在运行一段时间后就穿线cpu占用很高的问题,基本上是负载一天比一天高。诸如此类问题,请排查!
- 程序属于cpu密集型,和开发沟通,排除此类情况,用top或者ps
解决方法:top-h(按cpu占用率排名)是trace-p进程的pid,print“%\n”线程的pid(将pid转换成16进制),jstack进程的pid|grep线程的pid(16进制的)-A 30 (-A 往下看30行 -B 往上看30行 -C前后都看30行)
- 程序代码有问题,出现死循环,可能性很大,用上面的办法找出来杀掉
20.讲述一下Tomcat8005、8009、8080三个端口的含义?
8005==》 关闭时使用
8009==》 为AJP端口,即容器使用,如Apache能通过AJP协议访问Tomcat的8009端口
8080==》 一般应用使用
21.什么叫CDN?
即内容分发网络,其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络边缘,使用户可就近取得所需的内容,提高用户访问网站的速度。
22.什么叫网站灰度发布?
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式
AB test就是一种灰度发布方式,让一部用户继续用A,一部分用户开始用B
如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面 来
灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度
Zabbix
1.zabbix监控mysql的四大性能指标:
查询吞吐量
查询执行性能
连接情况
缓冲池使用情况
2.配置zabbix自定义监控流程
①被监控端修改 Agent 配置文件 ( 修改是否允许自定义 key, 加载配置文件目录 )
②被监控端创建存放自定义 key 文件 ( 在 zabbix_agentd.conf 文件中定义 ), 书写自定义 key
③重起客户端 agentd
④测试自定义 key 是否生效
⑤在 zabbix 页面创建监控模板 , 创建应用 , 创建监控项 , 关联主机
3.zabbix的主动监控与被动监控
主动监控和被动监控都是相对于被监控端主机而言的
默认 zabbix 采用被动监控
当监控主机达到一定量级后 ,zabbix 服务器会越来越慢 , 此时可以考虑使用主动监控 , 释放服务器的压力 zabbix 也支持分布式监控
被动监控 :server 向 Agent 发起连接 , 发送监控 key,Agent 接受请求 , 响应监控数据
主动监控 :Agent 向 server 发起连接 ,Agent 请求需要检测监控项目列表 ,server 相应 Agent 发送一个 items 列表 ,Agent 确认收到监控列表 ,TCP 连接完成 , 会话关闭 ,Agent 开始周期性收集数据
区别 :
server 不用每次需要数据都连接 Agent,Agent 会自己收集数据并处理数据 ,Server 仅需要保存数据 即可
4.zabbix 是怎么微信报警的
首先,需要有一个微信企业号。(一个实名认证的[微信号]一个可以使用的[手机号]一个可以登录的[邮箱号]
下载并配置微信公众平台私有接口。
配置Zabbix告警,(增加示警媒介类型,添加用户报警媒介,添加报警动作)
5.zabbix官方的一句话描述zabbix:
监视任何事情适用于任何IT基础架构,服务,应用程序和资源的解决方案
Monitor anythingSolutions for any kind of IT infrastructure, services, applications, resources
监控基础概论
zabbix并非监控,而是实现监控的工具
Zabbix-server是一个c/s和b/s结构
安装zabbbix的服务器安装时和php7.1有冲突:若此机器上已经安装php7.1就安装不上zabbix
监控知识体系
6.为什么要使用监控
1.对系统不间断实时监控
2.实时反馈系统当前状态
3.保证服务可靠性安全性
4.保证业务持续稳定运行
7.如果去到一家新的公司,如何入手?
1.硬件监控——路由器、交换机、防火墙
2.系统监控——cpu、内存、磁盘、网络、进程、tcp
3.服务监控——nginx、php、tomcat、redis、memcache、mysql
4.web监控——响应时间、加载时间、渲染时间
5.日志监控——ELK、(收集、存储、分析、展示)日志
6.安全监控——firewalld、WAF(nginx+lua)、安全宝、牛盾云、安全狗
单机监控 单机进程cpu查看负载和使用率
单机内存查看 单机磁盘查看 单机查看网络 引入zabbix分布式监控系统
使用shell脚本来监控服务器 安装zabbix (单机)--> LAMP (架构)--> LAP + MYSQL
服务端端口:10051 客户端端口:10050
基础模板 自定义监控阈值实战 自定义监控项
单位 值类型 值映射 阈值的定义
单条件 多条件
自定义触发器(动作) 自定义报警(邮件|微信)邮件发送的信息内容可以使用系统自带的宏变量来对应修改(官方站点有宏变量的介绍)
自定义图形、聚合图形、幻灯片、网络拓扑图、Graphtree
自定义模板(给主机添加) 系统默认自带的监控项设置阈值要根据生产中的需求来进修修改(阈值的高低) 服务监控(监控的服务要求有状态页面查询)
Nginx PHP-fpm mysql tomcat redis web监控 请求时间 响应时间
页面不是200-->触发报警 自动化监控: 自动发现(server端轮询网段扫描发现agent)
** 自动发现:server-->轮询扫描-->ip地址段--> **
自动发现:ip、ftp、ssh、web、pop3、imap、tcp
ip范文自动发现(两个阶段:发现-->动作)
szabbix-web自动发现定义自动监控的网段中的zabixx-agent(配置文件中server已经定义zabbix-server地址) 自动发现所执行的动作 发送消息 添加/删除主机 启用/禁用主机
添加主机到组 从组中删除主机 将主机链接到模板/从模板中取消链接 执行远程脚本命令 主动注册(agent端主动告诉server端请求加入)
zabbix-server必须开启自动注册-->操作-->(通知|加入监控|套用模板)
Agent(ServerActive=10.0.0.61)-->启动-->自动加入zabbix-server
zabbix-proxy分布式
Zabbix-proxy使用场景:
监控远程位置,解决跨机房
监控主机多,性能跟不上,延迟大
解决网络不稳定
8.zabbix 是怎么实施监控的
一个监控系统运行的大概的流程是这样的:
agentd需要安装到被监控的主机上,它负责定期收集各项数据,并发送到zabbix server端,zabbix server将数据存储到数据库中,zabbix web根据数据在前端进行展现和绘图。这里agentd收集数据分为主动和被动两种模式:
主动:agent请求server获取主动的监控项列表,并主动将监控项内需要检测的数据提交给server/proxy
被动:server向agent请求获取监控项的数据,agent返回数据。
主动模式被动模式:默认为zabbix-agent被动模式
主动模式与被动模式主要是站在zabbix-agent身份来说
1.被动模式(zabbix-server轮询检测zabbix-agent)
2.主动模式(zabbix-agent主动上报给zabbix-server)优
zabbix主动模式与被动模式选择
1.当(Queue)队列中有大量的延迟监控项
2.当监控主机超过300+ ,建议使用主动模式
【主动监测】通信过程如下:
zabbix首先向ServerActive配置的IP请求获取active items,获取并提交active tiems数据值server或者proxy。很多人会提出疑问:zabbix多久获取一次active items?它会根据配置文件中的RefreshActiveChecks的频率进行,如果获取失败,那么将会在60秒之后重试。分两个部分:
获取ACTIVE ITEMS列表
Agent打开TCP连接(主动检测变成Agent打开)
Agent请求items检测列表
Server返回items列表
Agent 处理响应
关闭TCP连接
Agent开始收集数据
主动检测提交数据过程如下:
Agent建立TCP连接
Agent提交items列表收集的数据
Server处理数据,并返回响应状态
关闭TCP连接
【被动监测】通信过程如下:
Server打开一个TCP连接
Server发送请求agent.ping\n
Agent接收到请求并且响应
Server处理接收到的数据
关闭TCP连接
1、新建监控项目时,选择的是zabbix代理还是zabbix端点代理程式(主动式),前者是被动模式,后者是主动模式。
2、agentd配置文件中StartAgents参数的设置,如果为0,表示禁止被动模式,否则开启。一般建议不要设置为0,因为监控项目很多时,可以部分使用主动,部分使用被动模式
9.zabbix 自定义发现是怎么做的
1、首先需要在模板当中创建一个自动发现的规则,这个地方只需要一个名称和一个键值。
2、过滤器中间要添加你需要的用到的值宏。
3、然后要创建一个监控项原型,也是一个名称和一个键值。
4、然后需要去写一个这样的键值的收集。
自动发现实际上就是需要首先去获得需要监控的值,然后将这个值作为一个新的参数传递到另外一个收集数据的item里面去。
10.zabbix 是怎么微信报警的 ----企业现在用的比较的多
1、首先,需要有一个微信企业号。(一个实名认证的[微信号]一个可以使用的[手机号]一个可以登录的[邮箱号]
2、下载并配置微信公众平台私有接口。
3、配置Zabbix告警,(增加示警媒介类型,添加用户报警媒介,添加报警动作)。
zabbix 怎么开启自定义监控
1、写一个脚本用于获取待监控服务的一些状态信息。
2、在zabbix客户端的配置文件zabbix_agentd.conf中添加上自定义的“UserParameter”,目的是方便zabbix调用我们上面写的那个脚本去获取待监控服务的信息。
3、在zabbix服务端使用zabbix_get测试是否能够通过第二步定义的参数去获取zabbix客户端收集的数据。
4、在zabbix服务端的web界面中新建模板,同时第一步的脚本能够获取什么信息就添加上什么监控项,“键值”设置成前面配置的“UserParameter”的值。
5、数据显示图表,直接新建图形并选择上一步的监控项来生成动态图表即可。
11.zabbix 监控了多少客户端 客户端是怎么进行批量安装的
根据实际公司台数回答。
1、使用命令生成密钥。
2、将公钥发送到所有安装zabbix客户端的主机。
3、安装 ansible 软件,(修改配置文件,将zabbix 客户机添加进组)。
4、创建一个安装zabbix客户端的剧本。
5、执行该剧本。
6、验证。
实战经验总结:
1.先查看文档中有没有对应的脚本和xml模板
2.在服务端导入模板,查看对应的监控项名称
3.测试脚本是否能取值,并存放置于/etc/zabbix/scripts目录下,一定要增加执行权限
4.编写xx.conf文件,里面主要存放的是如何定义监控项
5.最后重启zabbix-agent
6.使用服务端zabbix-get 获取 zabbix-agent对应的监控项的数据
范例:
公司未启用swap(swap也是公司中服务器不建议启用的,因为swap是将磁盘模拟内存使用,消耗cpu的性能,建议关闭swap。加大内存),随着客户的流量日益增大,导致将zabbix服务进程强制OOM, Zabbix服务进程被kill,有两种解决的方法,如果公司为了性能着想加大内存,如果公司资有限添加swap,如果是为了服务的效率建议使用添加内存的
12.Zbbbix监控过吗?平时你们都监控什么?
平时我们自己都监控我们主要的程序是否在正常运行,监控网站服务的流量,服务器CUP使用情况,服务器是否正常运行等。
13.请问你们的监控排班是什么样的?监控报告都写什么?
我们公司监控方面是三人8小时轮班的,保证24小时都有人在。
监控报告一般都是日期,人员,监控事项,监控事故处理检查及结果
14.zabbix-server端的pollers进程和trappers进程的作用
Pollers的作用是主动的找agent端去要数据,trappers是出来agent端发来的数据
15.zabbix-agent主动模式和被动模式的区别?及在哪修改agent主动模式
主动模式是,agent端主动发送数据给server端,被动模式是agent端收到server端的命令才被动发送数据。在etc/zabbix/zabbix_agent.conf里第136行修改主动模式
16.zabbix-server的监控模式有四种,那四种?作用分别是什么?
Anget模式是用来监控操作系统和软件服务的有主被动模式
Snmp模式是用来监控网络物理设备列如路由器·交换机
Jmx模式专门监控jvm的
Ipmi模式用来监控物理服务器硬件的,列如cpu , mem , radio
17.企业中zabbix-server的监控频率是如何设定的?
一般都是90到300秒,忙的时候90,不忙的时候300
18.企业中zabbix-server的报警频率是如何设定的?
在报警媒介里,一般设到1到3次,报警的时间设到60秒
19.zabbixserver如何开启java支持?
在编译的时候添加模块 --enable-java,在编译之前要安装jdk,列如:./configure --prefix=/usr/local/zabbix --with-mysql --with-net-snmp --with-libcurl --enable-server enable-agent --enable-agent --enable-proxy --enable-java --with-libxml2
20.zabbixserver的java gateway干啥的?监听端口多少?
Javagateway是接受jmx数据的,监听端口10050
21.zabbixserver默认监听端口?Zabbixagent默认监听端口?
Server默认的是10051,agent默认的是10050
22.zabbixserver的java pollers进程的作用?
主动的发起向客户端要jmx数据的进程
gitlab+jenkins
1.jenkins是什么
Jenkins是一个开源的、可扩展的持续集成、交付、部署(软件/代码的编译、打包、部署)的基于web界面的平台。允许持续集成和持续交付项目,无论用的是什么平台,可以处理任何类型的构建或持续集成。
2.SVN版本控制系统工作流程?
1.将服务器已经有的内容下载到本地
⒉初始化项目
3.查看文件的状态svn status
4.将新的文件添加到代码仓库中
5.将文件添加到服务器
6.个人的基本操作
3.SVN与Git的区别是什么
Git是分布式的,而Svn不是分布的
Git把内容按元数据方式存储,而SVN是按文件
GIT分支和SVN的分支不同
GIT没有一个全局的版本号,而SVN有
GIT的内容完整性要优于SVN
4.什么叫做DevOps
Devops就是开发和运维无缝交接工作
5.什么叫做CI/CD流水线
Ci就是持续集成流水线,cd就是持续交付流水线
6.请描述devops自动化ci/cd自动化测试的基本流程(jenkins+svn+ansible实现)
开发在svn上更新版本代码,返回用jenkins持续下发服务器,在20台的时候就可以不需要ansible,如果多台的话需要ansible写剧本多台管理
7.生产环境服务器自动化代码上线需要ansible吗?
看时间生产情况,如果就是简单的几台就可有可无,效果差不多,如果是多带读物就必须要ansible来管理了,要不会消耗大量的时间
8.jenkins+svn和jenkins+svn+absible的区别在哪里?
如果就是简单的几台就可有可无,效果差不多,如果是多带读物就必须要ansible来管理了,要不会消耗大量的时间
9.svn的监听端口
3690
10.Git分布式版本控制系统和svn中央版本控制系统的区别?
合: sVn定中央集中版本,所有的人都下载同一个版本去更新,git是分布式的,可以现在自己想要的分支。svn集中式版本控制系统不但速度慢,而且必须联网才能使用
git系统的安全性高。git及其强大的分支管理
git不仅仅是个版本系统,他也是个内容管理系统、工作管理系统等
git是分布式的svn不是,这是git和其他非分布式的版本控制系统.列如svncvs最核心的区别
git把内容按元数据方式存储,而svn是按文件,所有的资源控制系统都是吧文件的源信息隐藏在一个类似svn.cvs等文件夹里
git和svn的分支:分支再svn中一点不特别,就是版本库中的另外的一个目录git没有一个全局的版本号,而svn有目前为止svn相比git缺少的最大的特征git内容完整性要优于svn: git的内容储存使用的是sha-1
哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障时和网络问题是降低对版本库的破环/IIl
11.工作区,暂存区,本地仓库,远程仓库代表的含义?
工作区是开发人员在工作的目录,暂存区,可以理解为内存,本地仓库是将内存的代码写到磁盘上,远程仓库代表是将磁盘的同步到网上
12.git fetcn,git merge,git pull的区别?
答:git fetch是只将内容拉取下来,在用qit merae 将版本内容合并到本址git pull 是一步到位直接拉取和合并
13.git如何回滚代码到任意版本,请写出大概命令步骤?
提示: git reflog与git log --pretty=oneline答:用git reflog查看所有的历史id编码在用git reset --hard 加id编码直接回滚
14.Git分支合并的代码出现冲突如何解决?
答:冲突了以后,git会给出提示,我们打开冲突的文件,将冲突的2选一删除一个
15.GitLab私有仓库一共有几种权限设置,他们之间的差别在哪?
答:有5种guest访客,只能发表评论,不能读写reporter报告者
只能克隆,不能提交代码,产品测试用的developer开发人员
可以进行代码的读写,普通程序员用的master主程序员
可以添加项目成员,添加标签,创建和保护分支产品经理用的owner所有者
有所有的权限,一般不用
16.GitLab的备份和恢复命令分别是什么?
答:备份命令: gitlab-rake gitlab:backup:create
恢复命令: gitlab-rake gitlab:backup:restore BACKUP=备份文件编号
17.Git将本地仓库用作远程仓库时的初始化命令?(只初始化本地仓库,不能提交代码)
答: git --bare init
18.jenkins的pipeline流水线发布php项目基本构建流程?
现在jenkinsweb上建立一个流水线,流水线里需要配置的有参数化构建,在流水线选项里选择是自己写配置脚本还是从服务器里取配置脚本从服务器拉取的话,需要现在服务器上写配置脚本,然后上传到git仓库,在告诉流水线配置,脚本在那里放置,同时还有配置jenkins到gie的免秘钥,和登录节点服务器的密码
19.什么使用Jenkins?
jenkins是一种使用Java编程语言编写的开源持续集成软件工具,用于实时测试和报告较大代码库中的孤立更改。 Jenkins软件使开发人员能够快速找到并解决代码库中的缺陷,并自动进行构建测试。
20.Jenkins Pipeline是什么?
Jenkins Pipeline插件是Jenkins用户的游戏规则改变者。 Pipeline插件基于Groovy中的领域特定语言(DSL),使管道可编写脚本,并且是开发复杂的多步DevOps管道的强大方法。
21.如何在Jenkins中创建备份和复制文件?
创建备份,需要做的就是定期备份JENKINS_HOME目录。 这包含所有构建作业配置,从属节点配置以及构建历史记录。 要创建Jenkins设置的备份,只需复制此目录。
22.如何在Jenkins中配置自动构建?
在Jenkins中的构建可以定期触发(按计划,在配置中指定),或者在检测到项目中的源更改时触发,或者可以通过请求URL自动触发: http://YOURHOST/jenkins/job/PROJECTNAME/build
23.Jenkins的作业(Job)是什么?
Jenkins可用于执行典型的构建服务器工作,例如进行连续/正式/每晚构建,运行测试或执行一些重复的批处理任务。 这在詹金斯(Jenkins)中被称为“自由式软件项目”。
24.如何在Jenkins中创建多分支管道?
Multibranch Pipeline项目类型使您可以为同一项目的不同分支实现不同的Jenkinsfile。 在Multibranch Pipeline项目中,Jenkins自动发现,管理和执行针对在源代码管理中包含Jenkinsfile的分支的管道。
25.Jenkinsfile是什么?
Jenkinsfile是一个文本文件,其中包含Jenkins Pipeline的定义,并已签入源代码管理。 创建Jenkinsfile(已检入源代码管理)可带来许多直接好处: 管道上的代码审查/迭代;管道的审计跟踪;管道的唯一事实来源,可以由项目的多个成员查看和编辑。
26.Maven,Ant和Jenkins有什么区别?
Maven和ANT是构建工具,但主要区别在于Maven还提供了依赖项管理,标准项目布局和项目管理。 关于Maven,ANT和Jenkins之间的区别,后来的是一个持续集成工具,其作用远不止构建工具。
27.在Jenkins中持续集成是什么?
持续集成是一个将所有开发工作尽早集成的过程。 生成的工件会自动创建和测试。 此过程允许尽早发现错误。 Jenkins是一种流行的开源工具,可以执行持续集成和构建自动化。
28.新增文件的命令: git add file或者git add .
29.提交文件的命令: git commit –m或者git commit –a
30.查看工作区状况: git status –s
31.提交时发生冲突,你能解释冲突是如何产生的吗?你是如何解决的?
开发过程中,我们都有自己的特性分支,所以冲突发生的并不多,但也碰到过。诸
类的公共方法,我和别人同时修改同一个文件,他提交后我再提交就会报冲突的错误。
发生冲突,在IDE里面一般都是对比本地文件和远程分支的文件,然后把远程分支上文件的内容手工修改到本地文件,然后再提交冲突的文件使其保证与远程分支的文件一致,这样才会消除冲突,然后再提交自己修改的部分。特别要注意下,修改本地冲突文件使其与远程仓库的文件保持一致后,需要提交后才能消除冲突,否则无法继续提交。必要时可与同事交流,消除冲突。
发生冲突,也可以使用命令。
通过git stash命令,把工作区的修改提交到栈区,目的是保存工作区的修改;
通过git pull命令,拉取远程分支上的代码并合并到本地分支,目的是消除冲突;
通过git stash pop命令,把保存在栈区的修改部分合并到最新的工作空间中;15:你使用过git stash命令吗?你一般什么情况下会使用它
解决冲突文件时,会先执行git stash,然后解决冲突;
遇到紧急开发任务但目前任务不能提交时,会先执行git stash,然后进行紧急任务的开发,然后通过git stash pop取出栈区的内容继续开发;
切换分支时,当前工作空间内容不能提交时,会先执行git stash再进行分支切换
31.能不能说一下git fetch和git pull命令之间的区别?
简单来说:git fetch branch是把名为branch的远程分支拉取到本地;而git pull branch是在fetch的基础上,把branch分支与当前分支进行merge;因此pull = fetch + merge。
32.jenjins回滚的两种方式 Git回滚和版本号回滚
33.jenkins和gitlab的区别
Gitlab轻量级安装后cicd自带
Gitlab更好的给代码集成,gitlab比Jenkins性能好
Jenkins插件多
34.发布和回滚是用什么做的 Jenkins中gogs插件做的,回滚根据commit_id回滚
35.什么是gitlab 托管代码的,相当于git的二次开发
Prometheus
1. Prometheus 介绍
Prometheus是一套开源的系统监控报警框,相比Nagios或者Zabbix拥有如下优点
2.易管理性
Prometheus: Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
3.业务数据相关性
Prometheus:监控服务的运行状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
4.高效:
单一Prometheus可以处理数以百万的监控指标;每秒处理数十万的数据点。
5.易于伸缩:
通过使用功能分区(sharing)+联邦集群(federation)可以对Prometheus进行扩展,形成一个逻辑集群;Prometheus提供多种语言的客户端SDK,这些SDK可以快速让应用程序纳入到Prometheus的监控当中。
6.良好的可视化:
Prometheus除了自带有Prometheus UI,Grafana可视化工具也提供了完整的Proetheus支持
7.你对普罗米修斯有什么了解吗?
普罗米修斯(Prometheus)是开源的监控系统,是用来对巨量服务的监控处理,Prometheus 也是一款时序(time series)数据库,也可以
配置微信报警和邮件报警
8.Why, 为什么需要Prometheus?
Prometheus和Kubernetes有很多相通之处,Kubernetes其中一个功能是提供了弹性动态的部署能力,而Prometheus则提供了
动态的监控能力。Kubernetes已经成为实事标准,与之相辅相成的Prometheus自然也成为了云原生监控告警的首选项。
9.什么是序列数据,能更详细的解释一下吗?
时序数据库全称为时间序列数据库。时间序列数据库指主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。10.
10.同样是监控,为什么不使用zabbix?
综合来看,Zabbix 的成熟度更高,上手更快,但更好的集成导致灵活性较差,监控数据的复杂度增加后,Zabbix 做进一步定制难度很高
Prometheus 基本上是正相反,上手难度大一些,但由于定制灵活度高,数据也有更多的聚合可能,起步后的使用难度远小于 Zabbix
11.Prometheus的图形化还有其他方式吗?
Prometheus可以搭配Grafana,展示出精美的图形化页面,Grafana也可以搭配Zabbix进行图形化
Shell
1.什么是shell脚本?shell脚本是包含包含一个或多个命令的文本文件的命令。
2.为什么要使用shell脚本?系统管理员使用它来发出许多命令来完成任务。 所有命令都在文本文件(shell脚本)中一起添加,以完成日常例行任务。
3. shell脚本有什么优点(好处)?这些是shell脚本的两个主要优点:它可以帮助您开发自己的操作系统,包含最适合相关功能。以根据自己的平台设计软件应用程序。用于管理和维护系统。
4. shell脚本有哪些缺点?以下是shell脚本的主要缺点:弱设计可能会破坏整个过程,并可能导致代价高昂的错误。如果在创建期间发生键入错误,则它可以删除整个数据以及分区数据。它的初始过程缓慢并逐渐改善。不同操作系统之间的可移植性很差。
5. shell脚本中使用的变量有哪些类型?shell脚本中使用了两种类型的变量:系统定义的变量:这些变量由操作系统本身定义或创建。
6.用户定义的变量:这些变量由系统用户定义
7.什么是僵尸进程?僵尸进程是死亡的进程,但父进程未选择退出状态
8.Linux中的3个标准流有哪些?Linux中的3个标准流是:Linux中的3个标准流有哪些?
9.Linux中的3个标准流是:0 - 标准输入 1 - 标准输出 2 - 标准错误 0 - 标准输入
1 - 标准输出 2 - 标准错误 & 和&& 有什么区别。 & - 希望脚本在后台运行的时候使用它 && - 当前一个脚本成功完成才执行后面的命令/脚本的时候使用它
10.Linux/Unix进程的经历的几个阶段是什么? Linux/Unix进程通常经历四个阶段:
等待:在这个阶段,Linux进程等待资源。 运行:在此阶段,Linux进程当前正在执行。
停止:在此阶段,Linux进程在成功执行后停止。 僵尸:这个阶段称为僵尸,因为该进程已停止但仍在进程表中处于活动状态。
怎样来清除僵尸进程
11.改写父进程,在子进程结束后为它收尸。具体做法是接管SIGCHLD信号。子进程死后,会发送SIGCHLD信号给父进程,父进程收到此信号后,执 行waitpid()函数为子进程收尸。
把父进程杀掉。父进程死后,僵尸进程成为“孤儿进程”,过继给 1 号进程 init,init 始终会负责清理僵尸进程,它产生的所有僵尸进程也跟着消失
如何在脚本中使用参数?第一个参数:$1,第二个参数:$2
示例:脚本将文件 (arg1) 复制到目标 (arg2)
./copy.sh file1.txt /tmp/
cat copy.sh
#!/bin/bash
cp $1 $2
12.如何计算传递参数的数量?$#
13.如何在脚本中获取脚本名称?$0
14.如何检查之前的命令是否运行成功?$?
15.如何从文件中获取最后一行?tail -1
16.如何从文件中获取第一行?head -1
17.如何从文件的每一行中获取第三个元素?awk '{print $3}'
18.如果第一个等于 FIND,如何从文件的每一行中获取第二个元素awk '{ if ($1 == "FIND")
print $2}'
19.如何调试 bash 脚本 将 -xv 添加到 #!/bin/bash
例子 #!/bin/bash –xv
20.举个例子如何编写函数? function example { echo "Hello world!"}
21.如何将字符串添加到字符串?V1="Hello" V2="World" V3=$V1+$V2
echo $V3 输出 Hello+World
22.如何将两个整数相加?
V1=1
V2=2
let V3=$V1+$V2
echo $V3
输出
3
Remember you need to add "let" to line V3=$V1+$V2
then echo $V3 will give 3
if without let , then it will be
echo $V3 will give 1+2
23.如何检查文件系统上是否存在文件?
if [ -f /var/log/messages ]
then
echo "File exists"
fi
24.写下 shell 脚本中所有循环的语法?
循环:
for i in $( ls ); do
echo item: $i
done
while 循环:
#!/bin/bash
COUNTER=0
while [ $COUNTER -lt 10 ]; do
echo The counter is $COUNTER
let COUNTER=COUNTER+1
done
直到循环:
#!/bin/bash
COUNTER=20
until [ $COUNTER -lt 10 ]; do
echo COUNTER $COUNTER
let COUNTER-=1
done
25.每个脚本开头的#!/bin/sh 或#!/bin/bash 是什么意思?
该行告诉使用哪个 shell。#!/bin/bash 使用 /bin/bash 执行的脚本。如果是 python 脚本,会有 #!/usr/bin/python
26.如何从文本文件中获取第 10 行?
head -10 file|tail -1
27.bash 脚本文件中的第一个符号是什么 #
28.命令的输出是什么: [ -z "" ] && echo 0 || 回声 1 0
29.什么命令“export”? 在子shell中公开变量
30.如何在后台运行脚本? 在脚本末尾添加“&”
31.“chmod 500 脚本”是做什么的? 使脚本所有者可以执行脚本
32.“>”做什么? 将输出流重定向到文件或另一个流。
33.& 和 && 有什么区别 & - 当我们想要将脚本放到后台时使用它 && - 当我们想要执行命令/脚本时,如果第一个脚本成功完成
34.当我们在 [条件] 之前需要 "if" 时? 如果条件满足,我们需要运行多个命令。
35.命令的输出是什么:name=John && echo 'My name is $name' My name is $name
36.bash shell 脚本中用于注释的符号是什么? #
37.命令的输出是什么: echo ${new:-variable} variable
38. ' 和 " 引号之间有什么区别?
' - 我们在不想将变量评估为值时使用它
" - 将评估所有变量并分配其值。
39.如何将 stdout 和 stderr 流从脚本内部重定向到 log.txt 文件?
添加“exec >log.txt 2>&1”作为脚本中的第一个命令
分享70个经典的 Shell 脚本面试题与答案
pdf 0星 超过10%的资源 89KB
下载
40.如何仅使用 echo 命令获取部分字符串变量?
echo ${variable:x:y}
x - 起始位置
y - 长度
示例:
variable="我的名字是 Petras,我是开发人员。"
echo ${variable:11:6} # 将显示 Petras
41.仅当字符串变量=“User:123:321:/home/dir”给出时,如何使用echo 命令获取home_dir?
echo ${variable#*:*:*:} 或 echo ${variable##*:}
42.如何从上面的字符串中获取“用户”? echo ${variable%:*:*:*} 或 echo ${variable%%:*}
43.如何列出 UID 小于 100 (awk) 的用户? awk -F: '$3<100' /etc/passwd
44.编写程序,为用户计算唯一的主要组并仅显示计数和组名
cat /etc/passwd|cut -d: -f4|sort|uniq -c|while read c g do
{ echo $c; grep :$g: /etc/group|cut -d: -f1;}|xargs -n 2 done
45.如何在 bash shell 中将标准字段分隔符更改为“:”? IFS=“:”
46.如何获得可变长度? ${#variable}
47.如何打印变量的最后 5 个字符? echo ${variable: -5}
48.${variable:-10} 和 ${variable:-10} 有什么区别?
${variable:-10} - 如果在 ${variable: -10} 之前没有分配变量,则给出 10 - 给出
变量的最后 10 个符号
49.如何仅用 echo 命令替换部分字符串? echo ${变量//模式/替换}
50.哪个命令将字符串替换为大写? tr '[:lower:]' '[:upper:]'
51.如何计算本地账户? wc -l /etc/passwd|cut -d" " -f1 或 cat /etc/passwd|wc -l
52.如何在没有 wc 命令的情况下计算字符串中的单词? set ${string} echo $#
53.哪个是正确的“export $variable”或“export variable”? export variable
54.如何列出第二个字母为 a 或 b 的文件? ls -d ?[ab]*
55.如何将整数 a 添加到 b 并分配给 c ? c=$((a+b)) 或 c=`expr $a + $b` 或 c=`echo "$a+$b"|bc`
56.如何从字符串中删除所有空格? echo $string|tr -d " "
57.重写命令打印句子并将变量转换为复数:item="car";回声“我喜欢$item”?
item="car"; echo "I like ${item}s"
58.编写将打印从 0 到 100 的数字并每隔三分之一显示一次 (0 3 6 9 ...) 的命令?
for i in {0..100..3}; do echo $i; done or for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
59.如何打印提供给脚本的所有参数?echo $* or echo $@
60.[ $a == $b ] 和 [ $a -eq $b ] 有什么区别
[ $a == $b ] - 应该用于字符串比较
[ $a -eq $b ] - 应该用于数字测试
61.= 和 == 之间有什么区别 详解shell中脚本参数传递的两种方式 pdf 0星 超过10%的资源 48KB
下载
= - 我们用来给变量赋值
== - 我们用来比较字符串
62.编写命令来测试 $a 是否大于 12 ? [$a-gt 12]
63.编写命令来测试 $b 是否等于 12 ? [ $b -le 12 ]
64.如何检查字符串是否以“abc”字母开头? [[ $string == abc* ]]
65. [[ $string == abc* ]] 和 [[ $string == "abc*" ]] 有什么区别
[[ $string == abc* ]] - 将检查字符串是否以 abc 字母开头
[[ $string == "abc*" ]] - 将检查字符串是否完全等于 abc*
66.如何列出以 ab 或 xy 开头的用户名?
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
67.什么$!意味着在 bash 中 最近的后台命令 PID
68.什么$?? 最近的前台退出状态。
69.如何打印当前shell的PID? echo $$
70.如何获取传递给脚本的参数数量? echo $#
71.$* 和 $@ 有什么区
$* - 将所有传递给脚本的参数作为单个字符串
提供 $@ - 将所有传递给脚本的参数作为分隔列表提供.分隔符 $IFS
72.如何在 bash 中定义数组? array=("Hi" "my" "name" "is")
73.如何打印第一个数组元素? echo ${array[0]}
74.如何打印所有数组元素? echo ${array[@]}
75.如何打印所有数组索引? echo ${!array[@]}
76.如何删除 id 为 2 的数组元素? unset array[2]
77.如何添加 id 为 333 的新数组元素? array[333]="New_element"
78.shell 脚本如何获取输入值? a) 通过参数 ./script param1 param2
b) 通过读命令 read -p "Destination backup Server : " desthost
79.我们如何在脚本中使用“expect”命令?
/usr/bin/expect << EOD
spawn rsync -ar ${line} ${desthost}:${destpath}
expect "*?assword:*"
send "${password}\r"
expect eof
EOD
80.如何只用 echo 命令获取字符串变量的一部分 ?
echo ${variable:x:y}
x - 起始位置
y - 长度
81.例子:
variable="My name is Petras, and I amdeveloper."
echo ${variable:11:6} # 会显示 Petras
82.如何使用 awk 列出 UID 小于 100 的用户 ?
awk -F: '$3<100' /etc/passwd
83.请说出shell中awk、sed、grep各自的特点
sed:根据指定的条件进行处理,可实现增、删、改、查的功能,已完成自动化处理任务
awk:在无交互的情况下实现相当复杂的文本操作。是文本分析工具,可对文件进行分析处理,尤其适合对文本文件进行数据提取,数据统计,数据对比等分析处理操作
grep:在文件中查找并显示包含指定字符串的行。是字符串查找工具
84.请解释一下自定义变量含义:$* $# $? $0 $$ $! $(1-9)
$#是传给脚本的参数个数
$O是脚本本身的名字
$1是传递给该shell的第一个参数
$2是传递给该shell脚本的第二个参数
$@是传给脚本的所有参数的列表
$+是以一个单字符显示所有向脚本传递的参数,与位置变量不同,参数可超过9个
$$是脚本运行的当前进程ID号
$?是显示最后命令的退出状态,0表示没有错误,其他表示有错误
显示指定文件详情信息
stat 显示指定文件的详细信息,比ls更详细
who 显示在线登陆用户
whoami 显示当前操作用户
hostname 显示主机名
uname 显示系统信息
top 动态显示当前耗费资源最多进程信息
ps 显示瞬间进程状态 ps -aux
du 查看目录大小 du -h /home带有单位显示目录信息
df 查看磁盘大小 df -h 带有单位显示磁盘信息
ifconfig 查看网络情况
ping 测试网络连通
netstat 显示网络状态信息
man 命令不会用了,找男人 如:man ls
clear 清屏
alias 对命令重命名 如:alias showmeit="ps -aux" ,另外解除使用unaliax showmeit
kill 杀死进程,可以先用ps 或 top命令查看进程的id,然后再用kill命令杀死进程。
显示日期与时间的命令:date
显示日历的命令:cal
简单好用的计算器:bc
gzip:
bzip2:
tar: 打包压缩
-c 归档文件
-x 压缩文件
-z gzip压缩文件
-j bzip2压缩文件
-v 显示压缩或解压缩过程 v(view)
-f 使用档名
例:
tar -cvf /home/abc.tar /home/abc 只打包,不压缩
tar -zcvf /home/abc.tar.gz /home/abc 打包,并用gzip压缩
tar -jcvf /home/abc.tar.bz2 /home/abc 打包,并用bzip2压缩
当然,如果想解压缩,就直接替换上面的命令 tar -cvf / tar -zcvf / tar -jcvf 中的“c” 换成“x” 就可以了。
shutdown
-r 关机重启
-h 关机不重启
now 立刻关机
halt 关机
reboot 重启
将一个命令的标准输出作为另一个命令的标准输入。也就是把几个命令组合起来使用,后一个命令除以前一个命令的结果。
例:grep -r "close" /home/* | more 在home目录下所有文件中查找,包括close的文件,并分页输出。
vim三种模式:命令模式、插入模式、编辑模式。使用ESC或i或:来切换模式。
命令模式下:
:q 退出
:q! 强制退出
:wq 保存并退出
:set number 显示行号
:set nonumber 隐藏行号
/apache 在文档中查找apache 按n跳到下一个,shift+n上一个
yyp 复制光标所在行,并粘贴
h(左移一个字符←)、j(下一行↓)、k(上一行↑)、l(右移一个字符→)
查看文件大小 du -sh 文件名 ls -lh 文件名
查看系统版本 cat /etc/redhat-release
查看系统内核 uname -r
cat /proc/version
拆分文件 split -l 拆分的行 文件名 spilt -b 拆分的大小 文件名
查看后端任务 Jobs -l
查找linux系统下以txt结尾,30天没有修改的文件大小大于20K同时具有执行权限的文件并备份到/data/backup/目录下
find / -name *txt -mtime +30 -type f -size +20k -perm a=x -exec cp {} /data/backup/ \;
./var/www/html/是网站的发布目录,如何每天凌晨0点30对其进行自动备份,写出操作步骤?
(1)、crontab -e 进入编辑模式
(2)、添加以下内容 30 0 * * * /bin/tar -czf /backup/web_bak_$(date +\%Y\%m\%d).tar.gz /var/www/html > /dev/null 2>&1
(3)、启动服务 service crontab start;chkconfig crontab on
查看文件内容有哪些
vi 文件名 #编辑方式查看,可修改
cat 文件名 #显示全部文件内容
more 文件名 #分页显示文件内容
less 文件名 #与 more 相似,更好的是可以往前翻页
tail 文件名 #仅查看尾部,还可以指定行数
head 文件名 #仅查看头部,还可以指定行数
描述几种linux文件系统(三种以上)并列出他们的特点
xfs Centos 7默认文件系统 被业界称为最先进、最具有可升级性的文件系统技术
swap是liux中用户交换分区的文件系统(类似于windows中的虚拟内存),当内存不够用是,使用交换分区暂时替代内存。一般大小为内存的 2 倍,但是不要超过 2GB。它是 Linux 的必需分区
ext linux中最早的文件系统
ext2 ext的升级版本,,于1993发布,支持最大16TB的分区和最大2TB文件。红帽linux7.2版本以前默认就是ext2文件系统
ext3 ext2的升级版本,相对于ext2来区别在于日志功能,以便在系统突然停止时提高文件系统的可靠性
ext4 ext3的升级版本,Ext4 在性能、伸缩性和可靠性方面进行了大量改进。Ext4 的变化可以说是翻天覆地的,比如向下兼容 Ext3、最大 1EB 文件系统和 16TB 文件、无限数量子目录、Extents 连续数据块 概念、多块分配、延迟分配、持久预分配、快速 FSCK、日志校验、无日志模式、在线碎片整理、inode 增强、默认启用 barrier 等。它是 CentOS 6.3 的默认文件系统
proc linux中基于内存的虚拟文件系统,用来管理内存存储目录/proc
查看文件内容有哪些命令可以使用?
vi 文件名 #编辑方式查看,可修改
cat 文件名 #显示全部文件内容
more 文件名 #分页显示文件内容
less 文件名 #与 more 相似,更好的是可以往前翻页
tail 文件名 #仅查看尾部,还可以指定行数
head 文件名 #仅查看头部,还可以指定行数
7.终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
终端 /dev/tty
黑洞文件 /dev/null
Linux基础命令
1.什么是Linux
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和Unix的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统
二、给你一台linux服务器,如果保障它的安全?
1.从基本做起,及时安装系统补丁
2 安装和设置防火墙
3.安装网络杀毒软件
4.关闭不需要的服务和端口
5. 定期对服务器进行备份
6. 设置账号和密码保护
7. 监测系统日志
三、查看你的公司当前的系统版本和查看服务器的cpu
Cat /proc/cpuinfo
Lscpu
4.针对网页访问慢,该如何排查和解决
先查看以下因素
1、服务器出口带宽不够用
本身服务器购买的出口带宽比较小。一旦并发量大的话,就会造成分给每个用户的出口带宽就小,访问速度自然就会慢。
跨运营商网络导致带宽缩减。例如,公司网站放在电信的网络上,那么客户这边对接是长城宽带或联通,这也可能导致带宽的缩减。
2、服务器负载过大,导致响应不过来
可以从两个方面入手分析:
分析系统负载,使用 w 命令或者 uptime 命令查看系统负载。如果负载很高,则使用 top 命令查看 CPU ,MEM 等占用情况,要么是 CPU 繁忙,要么是内存不够。
如果这二者都正常,再去使用 sar 命令分析网卡流量,分析是不是遭到了攻击。一旦分析出问题的原因,采取对应的措施解决,如决定要不要杀死一些进程,或者禁止一些访问等。
3、数据库瓶颈
如果慢查询比较多。那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等。然后,也可以搭建 MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。
4、网站开发代码没有优化好
例如 SQL 语句没有优化,导致数据库读写相当耗时。
排查
1、首先要确定是用户端还是服务端的问题。当接到用户反馈访问慢,那边自己立即访问网站看看,如果自己这边访问快,基本断定是用户端问题,就需要耐心跟客户解释,协助客户解决问题。
2. 如果访问也慢,那么可以利用浏览器的调试功能,看看加载那一项数据消耗时间过多,是图片加载慢,还是某些数据加载慢。
3. 针对服务器负载情况。查看服务器硬件(网络、CPU、内存)的消耗情况。如果是购买的云主机,比如阿里云,可以登录阿里云平台提供各方面的监控,比如 CPU、内存、带宽的使用情况。如果是真机,查看cpu 内存、带宽的使用情况
4.如果发现硬件资源消耗都不高,那么就需要通过查日志,比如看看 MySQL慢查询的日志,看看是不是某条 SQL 语句查询慢,导致网站访问慢。
解决
1、如果是出口带宽问题,那么久申请加大出口带宽。
2、如果慢查询比较多,那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
3、如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等等。然后也可以搭建MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。
4、申请购买 CDN 服务,加载用户的访问。
5、如果访问还比较慢,那就需要从整体架构上进行优化咯。做到专角色专用,多台服务器提供同一个服务。
CDN:CDN的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。作用:解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
5.你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
使用 linux 命令 ’disown -r ’可以将所有正在运行的进程移除。
6.Linux 中进程有哪几种状态?在 ps 显示出来的信息中,分别用什么符号表示的?
答案:
(1)、不可中断状态:进程处于睡眠状态,但是此刻进程是不可中断的。不可中断, 指进程不响应异步信号。
(2)、暂停状态/跟踪状态:向进程发送一个 SIGSTOP 信号,它就会因响应该信号 而进入 TASK_STOPPED 状态;当进程正在被跟踪时,它处于 TASK_TRACED 这个特殊的状态。
“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。
(3)、就绪状态:在 run_queue 队列里的状态
(4)、运行状态:在 run_queue 队列里的状态
(5)、可中断睡眠状态:处于这个状态的进程因为等待某某事件的发生(比如等待 socket 连接、等待信号量),而被挂起
(6)、zombie 状态(僵尸):父亲没有通过 wait 系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉
(7)、退出状态
D 不可中断 Uninterruptible(usually IO)
R 正在运行,或在队列中的进程
S 处于休眠状态
T 停止或被追踪
Z 僵尸进程
W 进入内存交换(从内核 2.6 开始无效)
X 死掉的进程
7查看各类环境变量用什么命令?
答案:
查看所有 env
查看某个,如 home:env $HOME
十一 绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令?
答案:
绝对路径:如/etc/init.d
当前目录和上层目录:./ ../
主目录:~/
切换目录:cd
8.linux后台运行方法
Nobup、screen、daemonize
9.如果一个 linux 新手想要知道当前系统支持的所有命令的列表,他需要怎么做?
答案:
使用命令 compgen -c,可以打印出所有支持的命令列表。
10.使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
答案:
使用命令 repquota 能够显示出一个文件系统的配额信息
12.查看当前谁在使用该主机用什么命令? 查找自己所在的终端信息用什么命令?
查找自己所在的终端信息:who am i
查看当前谁在使用该主机:who
查看负载 top
13.限制用户的进程 ulimit -u
如何查看cpu ls cpu
cat /proc/cpuinfo
setuid 让普通用户执行二进制命令时有属主的权限 chmod 4777 GID 2 (属组的权限) sticky.bit :粘滞位,只有目录的创造者才能删除
14.Linux系统中病毒怎么解决
1)最简单有效的方法就是重装系统
2)要查的话就是找到病毒文件然后删除,中毒之后一般机器cpu、内存使用率会比较高,机器向外发包等异常情况,排查方法简单介绍下
top 命令找到cpu使用率最高的进程
一般病毒文件命名都比较乱,可以用 ps aux 找到病毒文件位置
rm -f 命令删除病毒文件
检查计划任务、开机启动项和病毒文件目录有无其他可以文件等
3)由于即使删除病毒文件不排除有潜伏病毒,所以最好是把机器备份数据之后重装一下
15.发现一个病毒文件你删了他又自动创建怎么解决
公司的内网某台linux服务器流量莫名其妙的剧增,用iftop查看有连接外网的情况,针对这种情况一般重点查看netstat连接的外网ip和端口。
用lsof -p pid可以查看到具体是那些进程,哪些文件经查勘发现/root下有相关的配置conf.n hhe两个可疑文件,rm -rf后不到一分钟就自动生成了,由此推断是某个母进程产生的这些文件。所以找到母进程就是找到罪魁祸首
查杀病毒最好断掉外网访问,还好是内网服务器,可以通过内网访问,断了内网,病毒就失去外联的能力,杀掉它就容易的多,怎么找到呢,找了半天也没有看到蛛丝马迹,没办法只有ps axu一个个排查,方法是查看可以的用户和和系统相似而又不是的冒牌货,果然,看到了如下进程可疑
看不到图片就是/usr/bin/.sshd,于是我杀掉所有.sshd相关的进程,然后直接删掉.sshd这个可执行文件,然后才删掉了文章开头提到的自动复活的文件
总结一下,遇到这种问题,如果不是太严重,尽量不要重装系统
一般就是先断外网,然后利用iftop,ps,netstat,chattr,lsof,pstree这些工具顺藤摸瓜
一般都能找到元凶。但是如果遇到诸如此类的问题
/boot/efi/EFI/redhat/grub.efi: Heuristics.Broken.Executable FOUND,个人觉得就要重装系统了
16.请写出下面 linux SecureCRT 命令行快捷键命令的功能?
Ctrl + a:光标移动到行首
Ctrl + c:终止当前程序
Ctrl + d:如果光标前有字符则删除,没有则退出当前中断
Ctrl + e:光标移动到行尾
Ctrl + l:清屏
Ctrl + u:剪切光标以前的字符
Ctrl + k:剪切光标以后的字符
Ctrl + y:复制u/k的内容
Ctrl + r:查找最近用过的命令
tab:命令或路径补全
Ctrl+shift+c:复制
Ctrl+shift+v:粘贴
17.服务器开不了机怎么解决一步步的排查
A、造成服务器故障的原因可能有以下几点:

B、如何排查服务器故障的处理步骤如下:

18.简单说下CentOS系统的开机启动顺序?
开机—加载BIOS—加载MBR(主引导扇区)--GRUB2启动引导阶段—内核引导阶段—系统初始化阶段
19.安装linux系统的两个最基本的分区
/ 根分区和swap交换分区
20.绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令?
绝对路径:如/etc/init.d
当前目录和上层目录:./ ../
主目录:~/
切换目录:cd
21.怎么查看当前进程?怎么执行退出?怎么查看当前路径?
查看当前进程:ps
执行退出:exit
查看当前路径:pwd
8.Linux 中进程有哪几种状态?在 ps 显示出来的信息中,分别用什么符号表示的?
(1)、不可中断状态:进程处于睡眠状态,但是此刻进程是不可中断的。不可中断, 指进程不响应异步信号。
(2)、暂停状态/跟踪状态:向进程发送一个 SIGSTOP 信号,它就会因响应该信号 而进入 TASK_STOPPED 状态;当进程正在被跟踪时,它处于 TASK_TRACED 这个特殊的状态。
“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。
(3)、就绪状态:在 run_queue 队列里的状态
(4)、运行状态:在 run_queue 队列里的状态
(5)、可中断睡眠状态:处于这个状态的进程因为等待某某事件的发生(比如等待 socket 连接、等待信号量),而被挂起
(6)、zombie 状态(僵尸):父亲没有通过 wait 系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉
(7)、退出状态
D 不可中断 Uninterruptible(usually IO)
R 正在运行,或在队列中的进程
S 处于休眠状态
T 停止或被追踪
Z 僵尸进程
W 进入内存交换(从内核 2.6 开始无效)
X 死掉的进程
22.怎么使一个命令在后台运行?
一般都是使用 & 在命令结尾来让程序自动运行。(命令后可以不追加空格)
23.利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息?
ps -ef (system v 输出)
ps -aux bsd 格式输出
ps -ef | grep pid
24.把后台任务调到前台执行使用什么命令?把停下的后台任务在后台执行起来用什么命令?
把后台任务调到前台执行 fg
把停下的后台任务在后台执行起来 bg
25.查看当前谁在使用该主机用什么命令? 查找自己所在的终端信息用什么命令?
查找自己所在的终端信息:who am i
查看当前谁在使用该主机:who
26.当你需要给命令绑定一个宏或者按键的时候,应该怎么做呢?
可以使用bind命令,bind可以很方便地在shell中实现宏或按键的绑定。
在进行按键绑定的时候,我们需要先获取到绑定按键对应的字符序列。
比如获取F12的字符序列获取方法如下:先按下Ctrl+V,然后按下F12 .我们就可以得到F12的字符序列 ^[[24~。
接着使用bind进行绑定。
[root@localhost ~]# bind ‘”\e[24~":"date"'
注意:相同的按键在不同的终端或终端模拟器下可能会产生不同的字符序列。
【附】也可以使用showkey -a命令查看按键对应的字符序列。
27..如果一个linux新手想要知道当前系统支持的所有命令的列表,他需要怎么做?
使用命令compgen -c,可以打印出所有支持的命令列表。
28.bash shell 中的hash 命令有什么作用?
linux命令’hash’管理着一个内置的哈希表,记录了已执行过的命令的完整路径, 用该命令可以打印出你所使用过的命令以及执行的次数。
29.使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
络使用命令repquota 能够显示出一个文件系统的配额信息
只有root用户才能够查看其它用户的配额。
30..TCP与UDP的区别
1、基于连接与无连接;
2、对系统资源的要求(TCP较多,UDP少);
3、UDP程序结构较简单;
4、流模式与数据报模式 ;
5、TCP保证数据正确性,UDP可能丢包;
6、TCP保证数据顺序,UDP不保证。
Linux系统和windows系统区别
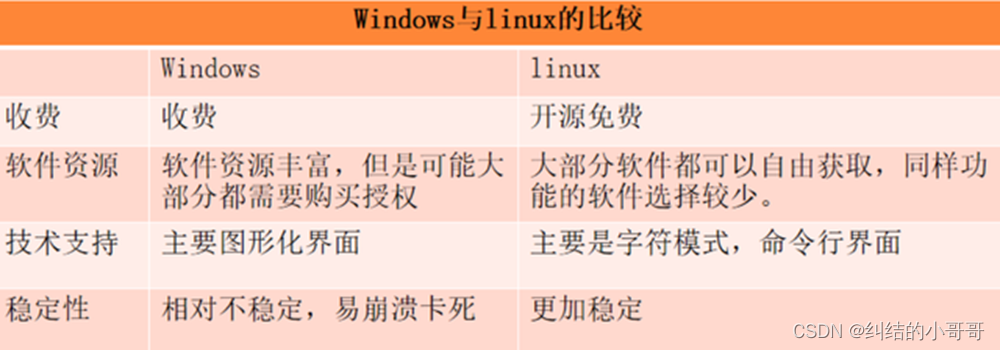
Linux常用的命令 uname:可显示电脑以及操作系统的相关信息 uname -a :显示主机名、内核等系统信息

hostname:显示系统主机名 hostname -i :显示系统 IP 地址

cal:显示本月的日历
date:显示当前时间 uptime:显示运行时间

whereis xxx :显示 xxx 程序可能的位置 which xxx:显示 xxx 命令对应执行的程序
查看文件命令
cat file1 > file2 : 将 file1 的文件内容输入到 file2 中
more file1:按页查看 file1 文件内容,从前向后翻看文件 (空格-一行行, 空白键-一页页)
less file1:按页查看 file1 文件内容,可往前往后翻看文件 (上下键)-q 退出
head -n 5 file1:显示 file1 文件的前 5 行 == 默认前 10 行
tail -n 5 file1:显示 file1 文件的后 5 行 === 默认后 10 行
tail -f file1:实时显示 file1 文件的最新增加内容 === 查看动态更新的日志 , ctrl + C 退出
wc /path/file: 输出 file 文件的行数,单词书和字节数
Linux目录结构

bin (binaries)存放二进制可执行文件
sbin (super user binaries)存放二进制可执行文件,只有root才能访问
etc (etcetera)存放系统配置文件
usr (unix shared resources)用于存放共享的系统资源
home 存放用户文件的根目录
root 超级用户目录
dev (devices)用于存放设备文件
lib (library)存放跟文件系统中的程序运行所需要的共享库及内核模块
mnt (mount)系统管理员安装临时文件系统的安装点
boot 存放用于系统引导时使用的各种文件
tmp (temporary)用于存放各种临时文件
var (variable)用于存放运行时需要改变数据的文件
1、cd
切换工作目录(英文全拼:change directory)
(1)语法 cd 文件目录
(2)常用操作命令 cd ~ 跳转到home目录 cd ../.. 跳转到目录的上两层
2、ls 显示指定目录下所有子目录和文件(英文全拼:list files)
(1)语法 ls 参数 目录名
(2)常用参数 -a 显示所有文件及目录 (. 开头的隐藏文件也会列出)
-l 除文件名称外,亦将文件型态、权限、拥有者、文件大小等信息详细列出
(3)常用操作命令 ls -l 可以缩写为ll,先洗展示当前目录下所有目录和文件
ls -R /Tools 递归列出/Tools下的子目录
3、pwd 显示当前工作目录绝对路径
(1)语法 pwd 参数
(2)常用参数 -- help 在线帮助 -- version 显示版本信息
(3)常用操作命令 无
4、cat
连接文件或标准输入并打印。这个命令常用来显示文件内容,或者将几个文件连接起来显示,或者从标准输入读取内容并显示,它常与重定向符号配合使用。
(1)语法 cat 参数 文件
(2)常用参数 -n, --number 对输出的所有行编号,由1开始对所有输出的行数编号
(3)常用操作命令
cat test.txt 展示文件test.txt的所有内容 cat > test01.txt 新建test01.txt文件
cat -n test01.txt > test02.txt 将test01.txt文件加上行号后放入test03.txt
cat test01.txt test02.txt > test03.txt 将test01.txt test02.txt文件连接后放入test03.txt
5、less 浏览文件,支持翻页和搜索,支持向上翻页和向下翻页
(1)语法less 参数 文件
(2)常用参数 -f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件 -N 显示每行的行号 -i 忽略大小写
(3)常用操作命令 ?字符串:向上搜索"字符串"的功能 /字符串:向下搜索"字符串"的功能 b 向上翻一页 d 向后翻半页 空格键 滚动一页(向下翻一页) G 移动到最后一行
g 移动到第一行 q 退出less命令
6、more 逐页阅读文件
(1)语法 more 参数 文件
(2)常用参数 -N 显示每行的行号 -num 一次显示的行数 +num 从第 num 行开始显示
(3)常用操作命令 Ctrl+B 返回上一屏 Ctrl+F 向下滚动一屏 空格键 向下滚动一屏
q 退出more命令
7、cp (英文全拼:copy file)命令主要用于复制文件或目录。
(1)语法 cp 参数 源 目的 cp 参数 源 目录
(2)常用参数
-a 此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。
-R, -r, --recursive 复制目录及目录内的所有项目
(3)常用操作命令
cp test01.txt test02.txt 把test01.txt内的所有内容都复制到test02.txt中
cp -R test01 test02 把test01里面的所有文件内容都复制到test02目录下
8、mv
(英文全拼:move file)命令用来为文件或目录改名、或将文件或目录移入其它位置。
(1)语法 mv 参数 源 目的mv 参数 源 目录
(2)常用参数 -f 如果指定移动的源目录或文件与目标的目录或文件同名,不会询问,直接覆盖旧文件。
(3)常用操作命令
mv test1.txt test2.txt 将文件 test1.txt 改名为 文件test2.txt
mv test1.txt test3/ 移动文件,将文件test1.txt移动到test3目录
mv test1 test2 移动目录,如果目录test2不存在,将目录test1改名为test2;否则,将test1移动到test2中
9、rm (英文全拼:remove)命令用于删除一个文件或者目录。
(1)语法rm 参数 文件/目录
(2)常用参数
-f 即使原档案属性设为唯读,亦直接删除,无需逐一确认。
-r, -R, --recursive 指示rm将参数中列出的全部目录和子目录均递归地删除。
(3)常用操作命令
rm -f test.txt 不询问是否删除,直接删除test.txt文件
rm -rf homework 递归删除homework目录
10、ps 英文全拼:process status)命令用于显示当前进程的状态
(1)语法 ps 参数
(2)常用参数 -aux 显示所有包含其他使用者的行程 -e 显示所有程序 -f 显示UID,PPIP,C与STIME栏位
(3)常用操作命令 ps -ef | grep java 显示所有的java进程 Linux常见报错及解决方法(持续更新)
一. 报错 /lib64/libc.so.6: version `GLIBC_2.14’ not found 原因 查看GLIBC版本 ldd --version

GLIBC版本太低,Linux机器上不存在2.14版本
解决方法
wget http://ftp.gnu.org/gnu/glibc/glibc-2.17.tar.gz
tar -xf glibc-2.17.tar.gz
cd glibc-2.17
mkdir build
cd build
../configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin
make -j 8
make install
strings /lib64/libc.so.6 | grep GLIBC
二. 报错
加载插件[***]失败,[libssl.so.6: cannot open shared object file: No such file or directory]

原因
该插件程序依赖于libssl.so.6,但丢失库文件对应的软链接
解决方法:建立软链接,如下
for 32bit
ln -sf /usr/lib/libssl.so.10 /usr/lib/libssl.so.6
ln -sf /usr/lib/libcrypto.so.10 /usr/lib/libcrypto.so.6
for 64bit
ln -sf /usr/lib64/libssl.so.10 /usr/lib64/libssl.so.6
ln -sf /usr/lib64/libcrypto.so.10 /usr/lib64/libcrypto.so.6
列出目录内容
ls -a:显示所有文件(包括隐藏文件);
ls -l:显示详细信息;
ls -R:递归显示子目录结构;
ls -ld:显示目录和链接信息;
ctrl+r:历史记录中所搜命令(输入命令中的任意一个字符);
Linux中以.开头的文件是隐藏文件;
pwd:显示当前目录
查看文件的类型
file:查看文件的类型
复制文件目录
1、cp:复制文件和目录 cp源文件(文件夹)目标文件(文件夹)
常用参数:-r:递归复制整个目录树;-v:显示详细信息;
复制文件夹时要在cp命令后面加一个-r参数:
如:cp -r 源文件夹 目标文件夹
2、touch+文件名:当文件不存在的时候,创建相应的文件;当文件存在的时候,修改文件的创建时间。
功能:生成一个空文件或修改文件的存取/修改的时间记录值。
touch * :将当前下的文件时间修改为系统的当前时间
touch –d 20040210 test:将test文件的日期改为20040210
touch abc :若abc文件存在,则修改为系统的当前时间;若不存在,则生成一个为当前时间的空文件
3、mv 文件 目标目录:移动或重命名文件或目录(如果指定文件名,则可以重命名文件)。可以将文件及目录移到另一目录下,或更改文件及目录的名称。
格式为:mv [参数]<源文件或目录> <目标文件或目录>
mva.txt ../:将a.txt文件移动上层目录
mv a.txt b.txt:将a.txt改名为b.txt
mvdir2 ../:将dir2目录上移一层
4、rm:删除文件;
常用参数:-i:交互式 -r:递归的删除包括目录中的所有内容
5、mkdir +文件夹名称:创建文件夹;
6、rm -r +文件夹名称:删除文件夹(空文件夹和非空文件夹都可删除)
rmdir 文件夹名称:删除文件夹(只能删除空文件夹)
7、mkdir -p dir1/dir2 :在当前目录下创建dir1目录,并在dir1目录下创建dir2目录, 也就是连续创建两个目录(dir1/和dir1/dir2)
8、rmdir –p dir1/dir2:删除dir1下的dir2目录,若dir1目录为空也删除它
9、rm * :删除当前目录下的所有文件
10、-f参数:强迫删除文件 rm –f *.txt:强迫删除所有以后缀名为txt文件
11、-i参数:删除文件时询问
rm –i * :删除当前目录下的所有文件会有如下提示:
rm:backup:is a directory 遇到目录会略过
rm: remove ‘myfiles.txt’ ? Y
删除文件时会询问,可按Y或N键表示允许或拒绝删除文件
12、-r参数:递归删除(连子目录一同删除,这是一个相当常用的参数)
rm -r test :删除test目录(含test目录下所有文件和子目录)
rm -r *:删除所有文件(含当前目录所有文件、所有子目录和子目录下的文件) 一般在删除目录时r和f一起用,避免麻烦
rm -rf test :强行删除、不加询问
13、grep:功能:在文件中搜索匹配的字符并进行输出
格式:grep[参数] <要找的字串> <要寻找字 串的源文件>
greplinux test.txt:搜索test.txt文件中字符串linux并输出
14、ln命令
功能:在文件和目录之间建立链接
格式:ln [参数] <源文件或目录> <目标文件或目录>
链接分“软链接”和“硬链接”
1.软链接:
ln–s /usr/share/do doc :创建一个链接文件doc,并指向目录/usr/share/do
2.硬链接:
ln /usr/share/test hard:创建一个硬链接文件hard,这时对于test文件对应 的存储区域来说,又多了一个文件指向它
系统常用命令
输出查看命令
echo:显示输入的内容 追加文件echo "liuyazhuang" >> liuyazhuang.txt
cat:显示文件内容,也可以将数个文件合并成一个文件。
格式:格式:cat[参数]<文件名>
cat test.txt:显示test.txt文件内容
cat test.txt | more :逐页显示test.txt文件中的内容
cat test.txt >> test1.txt :将test.txt的内容附加到test1.txt文件之后
cat test.txt test2.txt >readme.txt : 将test.txt和test2.txt文件合并成readme.txt 文件
head:显示文件的头几行(默认10行) -n:指定显示的行数格式:head -n 文件名
tail:显示文件的末尾几行(默认10行)-n:指定显示的行数 -f:追踪显示文件更新 (一般用于查看日志,命令不会退出,而是持续显示新加入的内容)
格式:格式:tail[参数]<文件名>
tail-10 /etc/passwd :显示/etc/passwd/文件的倒数10行内容
tail+10 /etc/passwd :显示/etc/passwd/文件从第10行开始到末尾的内容
more:用于翻页显示文件内容(只能向下翻页)
more命令是一般用于要显示的内容会超过一个画面长度的情况。为了避免画 面显示时瞬间就闪过去,用户可以使用more命令,让画面在显示满一页时暂停,此时可按空格健继续显示下一个画面,或按Q键停止显示。
ls -al |more:以长格形式显示etc目录下的文件列表,显示满一个画面便暂停,可 按空格键继续显示下一画面,或按Q键跳离
less:翻页显示文件内容(带上下翻页)按下上键分页,按q退出、‘
less命令的用法与more命令类似,也可以用来浏览超过一页的文件。所不同 的是less 命令除了可以按空格键向下显示文件外,还可以利用上下键来卷动文件。当要结束浏览时,只要在less命令的提示符“:”下按Q键即可。
ls -al | less:以长格形式列出/etc目录中所有的内容。用户可按上下键浏览或按Q键跳离
查看硬件信息
Ispci:查看PCI设备 -v:查看详细信息
Isusb:查看USB设备 -v:查看详细信息
Ismod:查看加载的模块(驱动)
关机、重启
shutdown关闭、重启计算机
shutdown[关机、重启]时间 -h关闭计算机 -r:重启计算机
如:立即关机: shutdown -h now
10分钟后关机:shutdown -h +10
23:30分关机:shutdown -h 23:30
立即重启: shutdown -r now
poweroff:立即关闭计算机
reboot:立即重启计算机
5、归档、压缩
zip:压缩文件 zip liuyazhuang.zip myfile 格式为:“zip 压缩后的zip文件文件名”
unzip:解压文件 unzip liuyazhuang.zip
gzip:压缩文件 gzip 文件名
tar:归档文件
tar -cvf out.tar liuyazhuang 打包一个归档(将文件"liuyazhuang"打包成一个归档)
tar -xvf liuyazhuang.tar 释放一个归档(释放liuyazhuang.tar归档)
tar -cvzf backup.tar.gz/etc
-z参数将归档后的归档文件进行gzip压缩以减少大小。
-c:创建一个新tar文件
-v:显示运行过程的信息
-f:指定文件名
-z:调用gzip压缩命令进行压缩
-t:查看压缩文件的内容
-x:解开tar文件
tar -cvf test.tar *:将所有文件打包成test.tar,扩展名.tar需自行加上
tar -zcvf test.tar.gz *:将所有文件打包成test.tar,再用gzip命令压缩
tar -tf test.tar :查看test.tar文件中包括了哪些文件
tar -xvf test.tar 将test.tar解开
tar -zxvf foo.tar.gz 解压缩
gzip各gunzip命令
gziptest.txt :压缩文件时,不需要任何参数
gizp–l test.txt.gz:显示压缩率
查找
locate:快速查找文件、文件夹: locate keyword
此命令需要预先建立数据库,数据库默认每天更新一次,可用updatedb命令手工建立、更新数据库。
find查找位置查找参数
如:
find . -name liuyazhuang 查找当前目录下名称中含有"liuyazhuang"的文件
find / -name .conf 查找根目录下(整个硬盘)下后缀为.conf的文件find / -perm 777 查找所有权限是777的文件find / -type d 返回根目录下所有的目录find . -name "a"-exec ls -l {} ;
find功能:用来寻找文件或目录。
格式:find [<路径>] [匹配条件]
find / -name httpd.conf 搜索系统根目录下名为httpd.conf的文件
7、ctrl+c :终止当前的命令
8、who或w命令
功能:查看当前系统中有哪些用户登录
格式:who/w[参数]
9、dmesg命令 功能:显示系统诊断信息、操作系统版本号、物理内存的大小以及其它信息
10、df命令 功能:用于查看文件系统的各个分区的占用情况
11、du命令
功能:查看某个目录中各级子目录所使用的硬盘空间数
格式:du [参数] <目录名>
12、free命令
功能:用于查看系统内存,虚拟内存(交换空间)的大小占用情况
VIM是一款功能强大的命令行文本编辑器,在Linux中通过vim命令可以启动vim编辑器。
一般使用vim + 目标文件路径 的形式使用vim
如果目标文件存在,则vim打开目标文件,如果目标文件不存在,则vim新建并打开该文件
:q:退出vim编辑器
VIM模式
vim拥有三种模式
(1)命令模式(常规模式)
vim启动后,默认进入命令模式,任何模式都可以通过esc键回到命令模式(可以多按几次),命令模式下可以键入不同的命令完成选择、复制、粘贴、撤销等操作。
命名模式常用命令如下:
i : 在光标前插入文本;
o:在当前行的下面插入新行;
dd:删除整行;
yy:将当前行的内容放入缓冲区(复制当前行)
n+yy :将n行的内容放入缓冲区(复制n行)
p:将缓冲区中的文本放入光标后(粘贴)
u:撤销上一个操作
r:替换当前字符
/ 查找关键字
(2)插入模式
在命令模式下按 " i "键,即可进入插入模式,在插入模式可以输入编辑文本内容,使用esc键可以返回命令模式。
(3)ex模式
在命令模式中按" : "键可以进入ex模式,光标会移动到底部,在这里可以保存修改或退出vim.
ext模式常用命令如下:
:w :保存当前的修改
:q :退出
:q! :强制退出,保存修改
:x :保存并退出,相当于:wq
:set number 显示行号
:! 系统命令 执行一个系统命令并显示结果
:sh :切换到命令行,使用ctrl+d切换回vim
软件包管理命令(RPM)
1、软件包的安装
使用RPM命令的安装模式可以将软件包内所有的组件放到系统中的正确路径,安装软件包的命令是:rpm –ivh wu-ftpd-2.6.2-8.i386.rpm
i:作用rpm的安装模式 v: 校验文件信息h: 以#号显示安装进度
2、软件包的删除
删除模式会将指定软件包的内容全部删除,但并不包括已更改过的配置文件,删除RPM软件包的命令如下:rpm –e wu-ftpd
注意:这里必须使用软件名“wu-ftpd”或”wu-ftpd-2.6.2-8而不是使用当初安装时的软件包名.wu-ftpd-2.6.2-8.i386.rpm
3、软件包升级
升级模式会安装用户所指定的更新版本,并删除已安装在系统中的相同软件包,升级软件包命令如下:rpm –Uvh wu-ftpd-2.6.2-8.i386.rpm –Uvh:升级参数
4、软件包更新
更新模式下,rpm命令会检查在命令行中所指定的软件包是否比系统中原有的软件 包更新。如果情况属实,rpm命令会自动更新指定的软件包;反之,若系统中并没有指定软件包的较旧版本,rpm命令并不会安装此软件包。而在升级模式下,不管系统中是否有较旧的版本,rpm命令都会安装指定的软件包。
rpm –Fvhwu-ftpd-2.6.2-8.i386.rpm -Fvh:更新参数
5、软件包查询
若要获取RPM软件包的相关信息,可以使用查询模式。使用-q参数可查询一个已 安装的软件包的内容
rpm –q wu-ftpd
查询软件包所安装的位置:rpm –ql package-name
rpm –ql xv (l参数:显示文件列表)
rsync
1.Rsync有几种模式?
(1)本地间数据同步
(2)异地间数据同步
(3)socket进程模式的数据同步
2.Rsync的socket模式的监听端口号?
873端口
3.Rsync的限速参数?
- -bwlimit
4.Rsync+inotify每秒支持的并发传输文件数?
每秒200文件并发,数据同步几乎无延迟(小于1秒)
5.企业自定义yum源的命令叫什么?请手写一个简单的自定义yum源文件(包路径:
/root/rpm/)
keepalived
1.keepalived三大功能?
实现无力高可用lvs管理对lvs进行健康检查
2.keepalived是基于什么协议实现的故障转移?此协议的作用是什么?
是基于vrrp虚拟路由冗余协议,这个协议是实现持续高可用的,保证keepalived持续工作
3.keepalived故障切换转移原理完整描述?
主的keepalived会持续发出一个广播包,这个广播包的优先级会高于备的keepalived,备的keepalived收到的优先级高于自己的广播包会保存静默不动,如果收不到广播包,会所有的备的keepalived都发一个广播包,优先级最高的那个,会激活ip转移功能,将ip转移到自己的keepalived上
4.keepalived高可用对上是有脚本的。分别都是什么脚本?描述一下脚本的作用和设计思路?
主的是防止软件宕了,keepalived还在运行,会造成业务不能正常用作,设计思路用Telnet每5秒扫描自己的nginx的反向代理端口,如果能扫到就没事,扫不到就停止keepalived服务,实现vrrp协议,写一个无限循环,睡5秒,如果扫不到就会执行停止keepalived命令
备的是要判断是否是脑裂,还是正常的切换,正常的切换就通知运维是主的keepalived出事,如果是脑裂就会通知是脑裂,脚本思路,ping下主的连接交换机的ip是否活着,扫下80端口、正常活着就是脑裂、或者判断ping下心跳线的网卡还是否活着、如果不通,ping主的连接交换机的,要是交换机的或者就是脑裂,心跳线出了问题,如果心跳线的ip活着扫端口,活着基本就是脑裂
5.为何keepalived高可用对之间要用专门的心跳线进行连接?
在正常的环境中,会出现两个keepalived对之间的互相影响,发的是广播包,会都收到,会影响别的keepalived对之间的正常工作,为了防止这个,我们用心跳线连接两个网卡,之间连接来解决。
6.讲一下Keepalived的工作原理?
在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP通告信息,
BACKUP不会抢占MASTER,除非它的优先级更高。当MASTER不可用时(BACKUP收不到通告信息)
多台BACKUP中优先级最高的这台会被抢占为MASTER。这种抢占是非常快速的(<1s),以保证服务的连续性
由于安全性考虑,VRRP包使用了加密协议进行加密。BACKUP不会发送通告信息,只会接收通告信息
7.keepalive的工作原理和如何做到健康检查
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内,其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样就可以保证路由器的高可用了
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式,vrrp模块是来实现VRRP协议的
Keepalived健康检查方式配置
HTTP_GET|SSL_GET
HTTP_GET | SSL_GET
{
url {
path /# HTTP/SSL 检查的url可以是多个
digest <STRING> # HTTP/SSL 检查后的摘要信息用工具genhash生成
status_code 200# HTTP/SSL 检查返回的状态码
}
connect_port 80 # 连接端口
bindto<IPADD>
connect_timeout 3 # 连接超时时间
nb_get_retry 3 # 重连次数
delay_before_retry 2 #连接间隔时间
}
docker命令
建立镜像
Docker build -t su/centos7:1(注意需要在有dockerfile的目录里输入命令)
启动容器
Docker run -dit su/centos7:1 /bin/bash(可以加/bin/bash,也可以不加)
Docker run --name sunan su/centos7:1 (启动的时候给容器起个名字叫sunan)
-d:放在后天运行
-i:可以交互输入命令
-t:启动一个伪终端
-c:指定几个cpu来运行内存
-m:指定几个内容
隐形参数--name给容器起名
看容器的日志
Docker logs sunnan (可以是名字,也可以是iD)
看启动的容器
Docker ps -a(加a是看所有)
开始运行容器
Docker start xxx (可以是容器的名字,也可以是容器的id)
重启一个容器
Docker restart xxx(可以是容器的名字也可以是id)
停止运行容器
时时的输出容器的资源使用状况
Docker stats xxx --no-stream (容器的名字或者id,类似top命令)
加参数 --no-stream是只输出一次就可
Docker stop xxx(可以是容器的名字,也可以是id)
切进容器的命令
Docker attach xxx
Exit是退出容器
杀容器
Docker kill xxx(容器的名字或者容器的id,直接删除容器的进程使其处于停止)
删除容器
Docker rm xxx(容器的名字或者容器的id,必须先停止容器以后才能删)
-f强删
将一个更改过的容器封装成一次性的镜像(先进去一个容器,搭建一个项目,退出从封装)
Docker commit xxx (原来的容器,更改过的) xxx/xxx(新的镜像叫什么名字)
不进容器,直接发布命令
Docker exec (-dit) xxx (容器的名字,或者id) ls/(想要执行的命令)
参数
-dit直接可以切进去
容器和属主机直接的复制文件命令
Docker cp /tmp/dockerfile (文件的路径) xxx:/tmp(容器的明智或者ip,冒号后面是地址)(也是把什么复制到哪里的格式)
创建一个新的容器
Docker create -it xxx(镜像的名字或者id)(用法跟run一样,只是create不启动容器,想要启动还需要用start命令启动下)
查看容器进程鱼源镜像做对比看哪里不一样
Docker diff xxx(容器的名字或者id)
返回的结果c是多了什么
A是少了什么
监控容器的变化
Docker events
导出容器
Docker export xxx(容器的名字或id)>yyyy.tar(导出来的容器叫什么名字)
将到处的容器创建为一个镜像
Docker import yyy.tar(导出来的容器的名字)zzz(导入要创建的镜像叫什么名字)
查看镜像的历史记录
Docker history xxx(镜像的名字或者id)
查看镜像的详细信息
Docker inspect xxx(镜像的民族或者id)
导出镜像
Docker save xxx(要导出的镜像的名字或者id)>yyy.tar(导出来叫什么名字)
导入镜像
Docker load <yyy.tar(需要导入的镜像的名字,有相同的镜像是不让导入的)
暂停容器的命令(unpause是回复暂停的容器)
Docker pause xxx(容器的名字或者id)
查看容器的端口映射协议
Docker port xxx(容器的名字或者id)
想要在启动的时候添加容器的映射端口
Docker run -dit --name xx -p 80:80 yy(xx容器起名叫,80:80将属主机的80端口映射到容器里的80端口,yy要启动的镜像的名字)
给容器改名
Docker rename xxx yyy(xxx 原来的名字,yyy想要叫的名字)
用于克隆镜像的
Docker tag xxx xxx1 (将什么,克隆成什么,可以当场软连接,要删一起删)
调整启动以后的容器的cpu和内存
Docker update -c 2 xxx(需要调整的)
-c调整cpu
-m调整内存,需要多少直接在后面写就可以了
监控容器的退出状态
Docker wait xxx(容器的名字或者id)
创建一个自定义网络
Docker network creat lnmp(创建一个自定义网络叫lnmp)
查看docker网络
Docker network ls产看所有网桥网路
Brctl show 同上
Login用于登录docker hub官方公有的仓库
Logout用于登出官方共有的仓库
Push将本地的镜像提交到docker hub
kvm和docker的本质区别,至少说3点(虚拟化类型,资源占用,程序安全)
Kvm是硬件虚拟化,docker是软件虚拟化,kvm的资源占用高,docker资源占用少,kvm的安全级别较高,有防火墙防护,docker是程序级别的,容器与容器之间没有防火墙
如何减小dockerfile生成镜像体积?
尽量选取满足需求但较小的基础系统镜像,例如大部分时候可以选择debian:wheezy或debian:jessie镜像,仅有不足百兆大小;
清理编译生成文件、安装包的缓存等临时文件;
安装各个软件时候要指定准确的版本号,并避免引入不需要的依赖;
从安全角度考虑,应用要尽量使用系统的库和依赖;
如果安装应用时候需要配置一些特殊的环境变量,在安装后要还原不需要保持的变量值;
dockerfile中CMD与ENTRYPOINT区别是什么?
CMD 和 ENTRYPOINT 指令都是用来指定容器启动时运行的命令。
指定 ENTRYPOINT 指令为 exec 模式时,CMD指定的参数会作为参数添加到 ENTRYPOINT 指定命令的参数列表中。
dockerfile中COPY和ADD区别是什么?
COPY指令和ADD指令都可以将主机上的资源复制或加入到容器镜像中
区别是ADD可以从 远程URL中的资源不会被解压缩。
如果是本地的压缩包ADD进去会被解压缩
docker网络类型有哪些? host模式 container模式 none模式 bridge模式
如何配置docker远程访问?
vim /lib/systemd/system/docker.service
在ExecStart=后添加配置,注意,需要先空格后,再输入 -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
docker核心namespace CGroups 联合文件系统功能是什么?
namespace:资源隔离 cgroup:资源控制
联合文件系统:支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下
命令相关:导入导出镜像,进入容器,设置重启容器策略,查看镜像环境变量,查看容器占用资源
导入镜像 docker load -i xx.tar
导出镜像docker save -o xx.tar image_name
进入容器docker exec -it 容器命令 /bin/bash
设置容器重启策略启动时 --restart选项
查看容器环境变量 docker exec {containerID} env
查看容器资源占用docker stats test2
构建镜像有哪些方式?
dockerfile
容器提交为镜像
Glusterfs
1.Glusterfs的存储卷的动态(在线)扩容命令?
Gluster volume add-brick 卷名 种类 几个节点组成 具体的节点位置1 具体的节点位置2
列如: gluster volume add-brick gs2 replica 2 glusterfs03:/gluster/brick2 glusterfs04/gluster/brick2(添加到卷名为gs2 卷的分布式复制卷,用2个节点的glusterfs03和04的百日草k的块,来进行扩容)
2.glusterfs的磁盘平衡功能的用处是什么?以及命令是什么?
新扩容的磁盘服务器是不会往里面写数据的,因为在原来的盘里有旧的数据,需要磁盘平衡一下,将数据平衡了,数据才会写到新的磁盘 gluster volume rebalance
Gs2 start (对数据卷gs2进行磁盘平衡)
3.glusterfs默认连接端口的范围
49152-49162.默认端口是49152
4.写出五条glusterfs的优化参数中文版?
条带大小,剩余磁盘空间阈值,ip访问授权,请求等待时间,读缓存大小,缓存校验周期,io线程数,客户等待时间
5.glusterfs服务器我们通常需要监控那些选项?
需要监控cpu.内存.主机存活.磁盘空间.并发数.系统load.主机运行时间
6.请说出,一台glusterfs节点服务器爆炸以后,你是如何处理的(恢复数据的步骤)?
先配置一台鱼爆炸服务器硬件配置一模一样的服务器,包括但不限于磁盘数,磁盘大小,等,然后安装系统,配置和故障服务器一样的ip,安装上glusterfs,修改配置文件,跟之前的一样,在其他的健康节点上执行命令gluster peer status,查看故障服务器的uuid,或复制这个uuid给新的服务器,修改的文件在/var/lib/glusterd/glusterd.info,然后在新的服务器上执行gluster volume heal gs2 full 开始执行同步,就可以恢复数据了
Redis
1.redis的默认监听端口是多少?
答:6379
2.redis的部署必须做的4种初始调优
答:启动文件个数,tcp连接数,和ocm开启,巨大化页面缓存关闭
3.redis的两种数据持久化模式
答: rdb和aof数据流
4.Redis中必须被屏蔽掉的危险命令都有什么:至少写出3个
答: keys * , flushdb flushall
5.redis手动关闭主从复制命令(只能在从上进行。)
答: redis-cli slaveof no one
6.我们平时如何分析redis的key和可以的大小,我们为什么要分析。
用到一个pip安装的工具rdbtools,先将文件到处rdb -c memory /data/redis/dump.rdb > /root/memory.csv. 然后用命令抓取数据进行分析 cat /root/memory.csv | tr`,` |sort -k4rn|head
7.请简述redis主从同步工作的过程
Redis的复制功能是基于内存快照的持久化策略基础上的,也就定说无论你的持久化策略选择的是什么,只要用到了Redis的复制功能,就一会有内存快照发生。
当Slave启动并连接到Master之后,它将主动发送一个SYNC命令(首先Master会启动一个后台进程,将数据快照保存到文件中Lrdb文件」 Master会给Slave 发送一个
Ping命令来判断Slave的存活状态当存活时Master会将数据文件发送给Slave并将所有写命令发送到Slave )。
Slave首先会将数据文件保存到本地之后再将数据加载到内存中。
当第一次链接或者是故障后重新连接都会先判断Slave的存活状态在做全部数据的同步,之后只会同步Master的写操作(将命令发送给Slave)
网站被上传木马到附件目录,有文件插入了恶意代码,请问如何解决?如何预防?
1.挂木马可能是一种代码,让别人打开你的网站的同时,就会超链接他事先设置好的木马上了。
2.也可能是后门,也就是别人在你的网页漏洞中添加了可以进出的一个门,这个门你自己可能都不知道。
3.是在你的网站下必要文件下安装木马,挂住你的网站,使得别人启动网站,或自己启动时中毒。
解决办法:
1.进行杀毒,看是否有实体木马存在,存在的话,杀掉它。
2.代码查看,看是否有可疑代码,有就删除它,这个比较麻烦,但专业制作网站的,也不是很难。
3.最简单的办法,用可以扫描到网站木马的软件,自己弄好网站后,打开,带扫描网页的杀毒软件可以直接扫描到你的代码存在的问题,可以根据提示删除。
8.请简述redis与memcached的区别
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等;
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list, set, hash等数据结构的存储;
3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value交换到磁盘;
4、过期策略--memcache在set时就指定,例如set key10 0 8,即永不过期。
Redis可以通过例如expire设定,例如expire name 10;
5、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从;
6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);
7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
8、Redis支持数据的备份,即master-slave模式的数据备份;
9、应用场景不一样: Redis出来作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;Memcached适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和session等。
9.请简述session共享都有哪些方法?为什么要做?
方法:
1.基于数据库的Session共享
2.基于NFS共享文件系统
3.基于memcached 的session,如何保证memcached本身的高可用性?
4.基于resin/tomcat web容器本身的session复制机制
5.基于TT/Redis或jbosscache进行session共享。
6.基于cookie进行session共享
原因:
客户端向服务器发送一个请求request,然后服务器返回一个相应response,之后
这个连接就会被关闭,两者也没有任何关系了,也就是服务器中不会存储此次请求的有关信息,再次请求时服务器就无法知道这次请求和上次请求是否是一个客户了。当需要进行统计时,我们就需要采用会话session来记录这次连接的信息了。
一个客户端访问服务器时,可能会在这个服务器的多个页面之间不断刷新、反复
连接同一个页面或者向一个页面提交信息,有了session的记录,服务器就可以知道这就是同一个客户端在完成动作罢了。
你在填写表单登录时,比如A表单中有name值,那么在提交A表单时就会提交
name值,跳转到B页面时,在B页面通过getAttribute(String name)方法来获取A表单提交的name的值,然后在用方法SetAttribute(key,value)将获取到的参数存储到session中,注销的时候用方法removeAttribute(String name)清空session即可。
10.什么是redis
redis是一个使用C语言写成的,开源。高性能key-value非关系缓存数据库
11.redis 为何这么快
1)基于内存 redis将数据全部存放在内存当中
2)单线程减少上下文切换,同时保证原子性
3)lO多路复用
4)高级数据结构(如SDS,Hash以及调表等)
12.redis为何使用单线程
官方回答
因为redis是基于内存的操作,CUP不会成为redis的瓶颈,而最有可能的是机器内存的大小或者网络带宽。
既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章采用单线程
详细原因
1)不需要各种锁的性能消耗
Redis 的数据结构并不全是简单的 Key-Value,还有 List,Hash 等复杂的结构,
这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。
2)单线程多进程集群方案
单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,
但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
所以单线程、多进程的集群不失为一个时髦的解决方案。
13.如何保证 Redis 的高并发?
Redis 通过主从加集群架构,实现读写分离,主节点负责写,
并将数据同步给其他从节点,从节点负责读,从而实现高并发。
5.redis常用命令
终端链接
redis-cli -h 192.168.1.1 -p 6379
key
keys * # 获取所有的key
select 0 # 选择第一个库
move myString 1 # 将当前的数据库key移动到某个数据库,目标库有,则不能移动
flush db # 清除指定库
randomkey # 随机key
type key # 类型
set key1 value1 # 设置key
get key1 # 获取key
mset key1 value1 key2 value2 key3 value3
mget key1 key2 key3
del key1 # 删除key
exists key # 判断是否存在key
expire key 10 # 10s 过期
pexpire key # 1000 毫秒
persist key # 删除过期时间
subscribe chat1 # 订阅频道
publish chat1 "hell0 ni hao" # 发布消息
pubsub channels # 查看频道
pubsub numsub chat1 # 查看某个频道的订阅者数量
unsubscrible chat1 # 退订指定频道 或 punsubscribe java.*
psubscribe java.* # 订阅一组频道
14.是否使用过 Redis 集群,集群的原理是什么?
1.Redis Sentinal 着眼于高可用, 在 master 宕机时会自动将 slave 提升为master, 继续提供服务。
2.Redis Cluster 着眼于扩展性, 在单个 redis 内存不足时, 使用 Cluster 进行分片存储。
15.Redis 集群会有写操作丢失吗?为什么?
答:Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作
16.Redis 集群之间是如何复制的?Redis 集群最大节点个数是多少?Redis 集群如何选择数据库? 异步复制 16384 个。 Redis 集群目前无法做数据库选择, 默认在 0 数据库。
17.怎么理解 Redis 事务?
1) 事务是一个单独的隔离操作: 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中。
不会被其他客户端发送来的命令请求所打断。
2) 事务是一个原子操作: 事务中的命令要么全部被执行, 要么全部都不执行。
10.Redis 的内存用完了会发生什么?
如果达到设置的上限,Redis 的写命令会返回错误信息(但是读命令还可以正常返回。)
或者你可以将 Redis 当缓存来使用配置淘汰机制,当 Redis 达到内存上限时会冲刷掉旧的内容
ELK
1.elk工作原理
Logstash 主要是用来日志的搜集,分析,过滤日志的工具,支持大量的数据获取方式,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤,修改等操作在一并发往elasticsearch上去。
Kibana也是一个开源和免费的工具,kibana可以为logstash和elasticsearch提供的日志分析友好的web界面,可以帮助汇总,分析和搜索重要的数据日志。
Redis特性,对小文件支持极高,效率极快,对大文件支持极低,所以我们要关闭内核的大文件缓存,redis是典型的单线程异步模型。
Elasticsearch如何限制别人对数据的访问
Kibana,如何闲置访问的来源
Localstart如何特种正则处理
2.ELK能做什么
ELK组件在海量日志系统的运维中,可用于解决:
分布式日志数据集中式查询和管理,故障排查
系统监控,包含系统硬件和应用各个组件的监控
安全信息和事件管理
友好web页面展示
3.kibana是什么
数据可视化平台工具
特点:
灵活的分析和可视化平台
实时总结和流数据的图表
为不同的用户显示直观的界面
即时分享和嵌入的仪表板
4.logstash是什么
logstash是一个数据采集、加工处理以及传输的工具
特点
所有类型的数据集中处理
不同模式和格式数据的正常化
自定义日志格式的迅速扩展
为自定义数据源轻松添加插件
5.ES与关系型数据库的特点
ES 与关系型数据库的对比
在 ES 中,文档归属于一种 类型 (type) ,而这些类型存在于索引 (index) 中,类比传统关系型数据库
DB -> Databases -> Tables -> Rows -> Columns
关系型 数据库 表 行 列
ES -> Indices -> Types -> Documents -> Fields
ES 索引 类型
Ansible
1.ansible是基于什么语言开发的软件? python
2.anisble哪个模块可以将其他主机的文件拷贝到本地?fetch模块
3.ansible哪个模块可以自动配置yum源?yum_repository模块
4.哪些功能是command模块所不支持的?管道 重定向 &后台进程
5.在YAML文件中使用什么符号支持跨行文本?> 或者 |
6.在Ansible的playbook剧本中使用什么关键词定义任务?tasks
7.YA ML文件中用什么代表数组,什么代表kv数据? . 代表数组 : 代表kv数据
8.简单描述ansiblefacts的作用?
ansible_facts用于采集被管理设备的系统信息所有收集的信息都被保存在安量中
每次执行playbook默认第一个任务就是Gathering Facts使用setup模块可以查看收集到的tacs信息
9.Ansible使用什么语句实现循环功能? loop语句
10.Ansible使用什么关键词可以定义任务块? block
11.Ansible剧本中使用when进行条件判断时,变量是否使用(0]引用? 否(不适用{{}})
12.哪些是ansiblerole的标准目录 tasks Defauits vars files handiers
13.ansible-yault加密数据的命令是什么? #ansible-vaul!nerpl<文件名>
14.ansible-vault解密数据的命令是什么? #ansible-vault decrypt文件名》
15.ansible-vault修改密码的命令是什么? #ansible-vault rekay<文件名>
16.通过sudo给普通用户授权时使用什么关键词可以免密码执行sudo? NOPASSWD
17.什么是Ansible?
ansible是新出现的自动化运维工具,基于 Python开发,集合了众多运维工具 puppet、cfengine、chef、func、fabric的优点,实现了批量系统配置、批量程序部署、批量运行命令等功能。
ansible是基于模块工作的,本身没有批量部署的能力。真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架。
主要包括:(1)、连接插件connection plugins:负责和被监控端实现通信;(2)、 host inventory:指定操作的主机,是一个配置文件里面定义监控的主机;(3)、各种模块核心模块、command模块、自定义模块;(4)、借助于插件完成记录日志邮件等功能;(5)、playbook:剧本执行多个任务时,非必需可以让节点一次性运行多个任
务。
18.Ansible的特性
1noagents:不需要在被管控主机上安装任何客户端;
2no server:无服务器端,使用时直接运行命令即可;
3modules in anylanguages:基于模块工作,可使用任意语言开发模块;
4.yaml not code:使用yaml语言定制剧本 playbook;
5.ssh by default:基于ssh工作;
6.strong multi-tier solution:可实现多级指挥。
19.Ansible优点
1.轻量级,无需在客户端安装agent,更新时,只需在操作机上进行一次更新即可;
2.批量任务执行可以写成脚本,而且不用分发到远程就可以执行
3.使用Python编写,维护更简单,ruby语法过于复杂;
4.支持sudo。
20.Ansible是什么
自动化运维工具,基于python开发,集合了众多运维工具的优点,可以实现批量系统配置,批量程序部署,批量运行命令等。它是基于模块工作,本身没有批量部署的能力,真正批量部署的是ansible运行的模块,ansible只是提供一种框架
21.Ansible是如何工作的
Ansible 是多个部分的组合,共同成为一个自动化工具。这些主要是模块、剧本和插件。剧本通过 Ansible 自动化引擎运行。这些剧本包含的模块基本上是在主机中运行的操作。这里遵循的机制是推送机制,因此ansible将小程序推送到这些主机,这些主机被编写为系统所需状态的资源模型。
22.Ansible常用模块及作用 至少6个
Command 在远程主机执行命令 不支持管道符
Ping 主机连通性测试
Shell 在远程主机上调用shell,支持管道符
Copy 用于将文件复制到远程主机,支持设定内容和修改权限
File 创建文件,创建连接文件,删除文件等
Fetch 从远程主机拉取文件到本地,会保留目录结构
User 管理用户账号
23.什么是ansible的playbook
Playbook是ansible的配置,部署和编排语言,是基于yaml语言编写,通常使用yaml或yml结尾的文件。Playbook主要使用空格字符来指定数据结构,不用tab键。有两个基本规则:1).数据元素在同级必须有同样的缩进 2).一个对象是另一个对象的子对象时必须比父对象缩进更多
ansible使用copy模块来将/opt/aa.txt复制到/home/jack中
ansible node1 -m copy -a 'src=/opt/aa.txt dest=/home/jack/'
使用file模块,来定义/home/jack/aa.txt的权限为777,归属为所有者是jack,所属组为jack
ansible node1 -m file -a 'path=/home/jack/aa.txt owner=jack group=jack mode=777’
使用yum模块,安装httpd服务
ansible node1 -m yum -a 'name=httpd state=present’
使用user模块,创建用户student,让其是系统用户,属组为root,uid为2000
ansible node1 -m user -a 'name=student system=yes group=root uid=2000’
使用cron模块,定义一个任务,每周五的14点30分执行备份/var
ansible node1 -m cron -a 'name=“crontab test” weekday=5 hour=14 minute=30 job="/usr/bin/tar -czf /opt/var.tar.gz /var"'
将装有ansible的机器上的某个shell脚本复制到受管理的目标主机上,并返回运行结果。
---
- hosts: webservers
user: root
tasks:
- name: copy sh
copy: src=./hello.sh dest=/root/hello.sh
- name: sh hello.sh
shell: sh /root/hello.sh
register: result
- name: print result
debug: var=result verbosity=0
24.什么是 Ansible Galaxy
Galaxy 是 Ansible 角色的存储库,可以在用户之间共享,也可以直接放入剧本中执行。它还用于分发包含角色、插件和模块的包,也称为集合。ansible-galaxy-collection 命令实现类似于 ansible-galaxy 命令的 init、build、install 等。
25.Ansible 有哪些特点?
无代理——与 puppet 或 Chef 不同,没有管理节点的软件或代理。
Python - 建立在Python之上,它非常容易学习和编写脚本,并且是一种强大的编程语言。
SSH – 无密码网络身份验证,使其更加安全且易于设置。
推送架构——核心概念是将多个小代码推送到客户端节点上配置和运行操作。
设置- 这很容易设置,学习曲线非常低,并且是任何开源软件,因此任何人都可以动手操作。
管理库存– 机器的地址以简单的文本格式存储,我们可以添加不同的真实来源以使用 Openstack、Rackspace 等插件来提
RabbitMQ
1.使用RabbitMQ有什么好处?
1解耦,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦!
2.异步,将消息写入消息队列,非必要的业务逻辑以异步的方式运行,加快响应速度
3.削峰,并发量大的时候,所有的请求直接怼到数据库,造成数据库连接异常
2.RabbitMQ 中的 broker 是指什么?cluster 又是指什么?
broker 是指一个或多个 erlang node 的逻辑分组,且 node 上运行着 RabbitMQ 应用程序。cluster 是在 broker 的基础之上,增加了 node 之间共享元数据的约束。
3.RabbitMQ 概念里的 channel、exchange 和 queue 是逻辑概念,还是对应着进程实体?分别起什么作用?
queue 具有自己的 erlang 进程;exchange 内部实现为保存 binding 关系的查找表;channel 是实际进行路由工作的实体,即负责按照 routing_key 将 message 投递给 queue 。由 AMQP 协议描述可知,channel 是真实 TCP 连接之上的虚拟连接,所有 AMQP 命令都是通过 channel 发送的,且每一个 channel 有唯一的 ID。一个 channel 只能被单独一个操作系统线程使用,故投递到特定 channel 上的 message 是有顺序的。但一个操作系统线程上允许使用多个 channel 。
4.vhost 是什么?起什么作用?
vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
5.消息基于什么传输?
由于TCP连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ使用信道的方式来传输数据。信道是建立在真实的TCP连接内的虚拟连接,且每条TCP连接上的信道数量没有限制。
6.消息如何分发?
若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。
7.消息怎么路由?
从概念上来说,消息路由必须有三部分:交换器、路由、绑定。生产者把消息发布到交换器上;绑定决定了消息如何从路由器路由到特定的队列;消息最终到达队列,并被消费者接收。
消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。
通过队列路由键,可以把队列绑定到交换器上。
消息到达交换器后,RabbitMQ会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则)。如果能够匹配到队列,则消息会投递到相应队列中;如果不能匹配到任何队列,消息将进入 “黑洞”。
常用的交换器主要分为一下三种:
direct:如果路由键完全匹配,消息就被投递到相应的队列
fanout:如果交换器收到消息,将会广播到所有绑定的队列上
topic:可以使来自不同源头的消息能够到达同一个队列。 使用topic交换器时,可以使用通配符,比如:“*” 匹配特定位置的任意文本, “.” 把路由键分为了几部分,“#” 匹配所有规则等。特别注意:发往topic交换器的消息不能随意的设置选择键(routing_key),必须是由"."隔开的一系列的标识符组成。
8.什么是元数据?元数据分为哪些类型?包括哪些内容?与 cluster 相关的元数据有哪些?元数据是如何保存的?元数据在 cluster 中是如何分布的?
在非 cluster 模式下,元数据主要分为 Queue 元数据(queue 名字和属性等)、Exchange 元数据(exchange 名字、类型和属性等)、Binding 元数据(存放路由关系的查找表)、Vhost 元数据(vhost 范围内针对前三者的名字空间约束和安全属性设置)。在 cluster 模式下,还包括 cluster 中 node 位置信息和 node 关系信息。元数据按照 erlang node 的类型确定是仅保存于 RAM 中,还是同时保存在 RAM 和 disk 上。元数据在 cluster 中是全 node 分布的。
9.如何确保消息正确地发送至RabbitMQ?
RabbitMQ使用发送方确认模式,确保消息正确地发送到RabbitMQ。发送方确认模式:将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
10.死信队列和延迟队列的使
死信消息:
消息被拒绝(Basic.Reject或Basic.Nack)并且设置 requeue 参数的值为 false
消息过期了
队列达到最大的长度
队列设置:在队列申明的时候使用 x-message-ttl 参数,单位为 毫秒
单个消息设置:是设置消息属性的 expiration 参数的值,单位为 毫秒
延时队列:在rabbitmq中不存在延时队列,但是我们可以通过设置消息的过期时间和死信队列来模拟出延时队列。消费者监听死信交换器绑定的队列,而不要监听消息发送的队列。
11.使用了消息队列会有什么缺点?
1.系统可用性降低:你想啊,本来其他系统只要运行好好的,那你的系统就是正常的。现在你非要加个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性降低
2.系统复杂性增加:要多考虑很多方面的问题,比如一致性问题、如何保证消息不被重复消费,如何保证保证消息可靠传输。因此,需要考虑的东西更多,系统复杂性增大
12.RabbitMQ是什么东西?
RabbitMQ也就是消息队列中间件,消息中间件是在消息的传息过程中保存消息的容器
消息中间件再将消息从它的源中到它的目标中标时充当中间人的作用
队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用
消息队列不会保留消息,直到可以成功地传递为止,当然,消息队列保存消息也是有期限地
查看系统版本,查看内核版本,查看CPU信息,查看内存信息命令
查看系统版本:cat /etc/redhat-release
yum -y install redhat-lsb 然后 lsb_release -a
查看内核版本:uname -r
cat /proc/version
查看cpu信息:cat /proc/cpuinfo
Lscpu
查看内存信息:cat /proc/meminfo
Free -m
解释setuid,setgid,stickybit
Setuid: 针对二进制文件的(linux命令),让普通用户在执行命令时用root
(属主)
添加权限:chmod 4777 /sbin/poweroff
4: setuid 777:读写执行的最高权限
Setgid: 针对二进制文件的(linux命令),让普通用户在执行命令时用root
(属组)
添加权限:chmod 2777 /sbin/poweroff
2:setgid 777:读写执行的最高权限
Stickybit:粘滞位
只有这个目录或文件的创建者才可以删除文件 ,其他人即便有权限也无法更改
如何修改系统打开的文件数及进程数
用户打开的文件数:ulimit -n (查看打开多少文件)
Ulimit -n + 值 (修改打开的文件数)
用户打开的进程数:ulimit -u (查看打开的进程数)
Ulimit -u + 值 (修改打开的进程数)
永久修改:vi /etc/security/limits.conf
文件数: * soft nofile 65535
* hard nofile 65535
进程数: * soft nofile 65535
* hard nofile 65535
简述TCP三次握手四次断开:为什么连接的时候是三次,断开是四次
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手
为什么TIME_WAIT状态需要经过2MSL(最大报文生存时间)才能返回close状态,产生TIME_WAIT解决方案?
需要经过2MSL原因: 虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可能最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
产生TIME_WAIT解决方案:
vi /etc/sysctl.conf
1)net.ipv4.tcp_syncookies = 1
表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
2)net.ipv4.tcp_tw_reuse = 1
表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
3)net.ipv4.tcp_tw_recycle = 1
表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
4)net.ipv4.tcp_fin_timeout = 10
修改系默认的 TIMEOUT 时间
给你一台服务器你该怎么操作(服务器优化)
1) 提高用户密码的复杂程度,禁止root用户远程登录
给普通用户合理设置sudo权限,
2)优化sshd服务,修改sshd服务监听的端口号(sshd默认端口22)
进入 /etc/ssh/sshd_config 配置文件更改
3)禁用dns反向解析,提高连接效率/速度
4)关闭server上的GSS认证
GSSAPIAuthentication no
重启sshd服务,生效
防火墙服务开放端口,设置yum源
装系统时合理分配硬盘容量,将数据盘与系统盘分开
简述DNS解析过程(网站的访问流程)
1) www.baidu.com
2) 先查看本地DNS缓存,是否有域名和IP对应关系
3)如果本地DNS 缓存没有,客户端就好查看本地的hosts文件
Hosts文件路径:C盘-Windows-system32-drivers-etc-hosts
4) 如果没有,客户端就会将域名交给本地填写的DNS,客户端将请求交给本地DNS 这个过程叫做(递归查询)
5) 如果本地DNS,没有域名和IP的对应关系,就会将请求交给根DNS
6)我这没有baidu.com的IP地址,但是我知道谁有, .com的服务器(顶级域)
7)去找.com的服务器去要baidu.com的IP地址,我这没有,但是你得去找baidu.com的服务器(二级域名服务器)
8)去找baidu.com的服务器,你要说备案,肯定会有IP地址,如果没有,就是没备案
9)如果有交给本地的DNS,本地的DNS返回给客户端
第一步-第四步------(递归查询)
第五步-第八步------(迭代查询)
DNS端口号:53 协议为TCP UDP
区域传输时候用TCP ,其他时候(解析)用UPD
lsof命令是用来干啥的
lsof命令用于查看你进程开打的文件,打开文件的进程,进程打开的端口(TCP、UDP)。找回/恢复删除的文件
RAID磁盘卷做什么用的?简述raid0 ,raid1,raid5,raid1 0区别
作用:将一些小容量的硬盘,逻辑上结合到一起,然后变成大容量的硬盘
如果将硬盘做成raid盘:
硬raid:就是在服务器还没有装系统之前,先做raid(服务器又raid卡) 更好
软raid:就是在安装完操作系统之后,利用软件在进行raid(有没有raid卡都行)
Raid 0 :能够加快磁盘的读写速度,但是没有数据冗余(备份),磁盘容量是所有磁盘容量的总和,最少需要2块硬盘
Raid1:不能加快磁盘的读写速度,但是有数据冗余(备份),磁盘容量是所有磁盘容量总和的一半,最少需要2块硬盘
Raid5:既能加快磁盘读写速度,有数据冗余,磁盘容量是所有磁盘容量总和的n-1/n, 最少需要3块硬盘
Raid 1 0:raid0 raid1 的结合体
解释$0, $$, $#, $?, $@ $*各自意义
$0:表示当前执行的脚本或程序的名称
$$: 显示当前运行脚本进程
$# 表示命令行中位置参数的个数
$? 返回上一条命令的执行结果,返回值为0表示执行正确,
$@:传递给脚本的所有参数
$* 传递给脚本的所有参数
@和*区别: 他俩没有双引号的时候意思一样
有双引号的时候*是整体的整份数据,@仍然把参数看做独立的的数据
环境变量与位置变量区别
环境变量:指的是出于运行需要而有linux系统提前创建的一类变量,主要用于设置户的工作环境,包括用户宿主目录,命令查找路径,用户当前目录,登录终端等
位置变量:通过命令行为程序提供操作参数,bash引入了位置变量的概念,当执行命令操作时,第一个字段表示命令名或脚本程序名,其余的字符串参数按照从左到右的顺序依次赋值给位置变量
For循环与while循环有什么区别
For循环:使用for循环语句时,需要指定一个变量及可能的取值列表,针对每个不同的取值重复执行相同的命令序列,直到变量值用完退出循环,取值列表为for语句的执行条件
While循环:使用while循环语句时,可以根据特定的条件反复执行一个命令序列,直到该条件不再满足为止,在脚本应用,应该避免出现死循环的情况,否则后面的命令操作将无法执行,因此,循环体内的,命令序列应包括修改测试条件的语句,以便在适当时候使测试条件不再成立,从而结束循环
Shell脚本中,-eq,-ne,-gt,-lt,-le,-ge,这些符号都是什么意思
-eq:等于 -ne: 不等于 -gt: 大于
-lt:小于 -le:小于等于 -ge:大于等于
Shell脚本中,1>,1>>,2>,2>>,&>,都是什么意思
:正确重定向覆盖 1>>:正确重定向追加
2>:错误重定向覆盖 2>>:错误重定向追加
&>:混合重定向
循环语句中,break与continue有什么区别吗
Break:跳出总循环
Continue:跳出总循环,继续下一次循环
服务器巡检脚本:
vim abc.sh
#!/bin/bash
echo "服务器系统版本为:$(cat /etc/redhat-release)"
echo "服务器cpu核心数为:$(grep -c processor /proc/cpuinfo)"
echo "服务器内存总数为:$(free -h |awk '/Mem/{print $2}')"
echo "剩余内存为:$(free -h |awk '/Mem/{print $4}')"
echo "磁盘总大小为:$(lsblk |awk '/disk/{print $4}')"
echo "磁盘使用率为:$(df -h |awk '/root/{print $(NF-1)}')"
echo "网卡ip地址为:$(ifconfig |awk '/broadcast/{print $2}')"
Shell脚本中,#!/bin/bash有什么含义吗
#!/bin/bash :是一种特殊的脚本声明,表示此行以后的语句通过/bin/bash
程序来解释声明
Shell脚本中引号的作用
双引号:(””)弱转义 :将变量值直接打印出来
当变量值的内容中出现空格时,用双引号括起来,
单引号:(‘’)强转义: 直接输出内容
当变量值包含/,$等特殊含义的符号时,使用单引号括起来
三引号:(‘’’ ‘’’ 或“”“”“” “”“”“”)用来写批量的文件内容,或者批量打印内容
反撇号:(``)将某个命令结果赋值给变量
用grep命令统计/etc目录下包含“root”的所有文件目录
grep -Lr “root” /etc
用sed命令把文件中的yang替换为nan
sed -i ‘s/yang/nan/g’
awk内置变量中FNR与NR区别,FS与OFS区别
FNR:当前输入文档的当前行号,尤其输入多个文档
NR:输入数据流的当前行号
FS:字段分隔符,默认为空格或tab制表符
OFS:输出字段分隔符,默认文空格
awk统计netstat最后一列state(状态)的值

在vi编辑器里面,如何用sed和末行模式下删除nginx配置文件注释与空行
Sed命令:删除空行:sed -i '/^$/d' nginx.conf
删除注释:sed -i '/#/d' nginx.conf
末行模式:删除空行: :%g/^$/d
删除注释:: %g/#/d
为什么nginx比httpd应用场景多
.nginx:抗并发能力强,用epoll作为开发模型,在处理请求时时异步非阻塞的,
分别处理两个进程,主进程交给子进程处理(多个连接对应一个进程)
Apache:用select作为开发模型,在处理请求时是同步阻塞的,同时处理五个进程,(一个连接对应一个进程)
2…nginx:支持反向代理和 负载均衡(既支持四层,传输层,又支持七层,应用层), 配置起来比Apache简单
3.apache虽然处理静态页面能力没有nginx强,但是处理动态页面比nginx快
-nginx:适合做静态页面 -Apache:适合做动态页面
Nginx都有哪些基础命令
Nginx //开启nginx nginx -s stop //关闭nginx
Nginx -s reload //重载nginx
Nginx -s quit //从容停止nginx
Nginx -V //查看nginx版本和参数
Nginx配置文件一般分为哪几个模块
Nginx.conf配置文件分三部分
第一部分:worker模块 //全局部分;存储工作进程
第二部分:event模块 //events块涉及的指令主要影响nginx服务器与用户的 网络连接
第三部分:http模块 //包含多个server模块,一个server代表一个虚拟主机
Nginx如何开启高效传输文件模式
Nginx配置文件:vim /usr/local/nginx/conf/nginx.conf
添加:sendfile on //开启高效传输
简述Nginx正向代理与反向代理,有什么区别吗
正向代理(内部上网)客户端<--->代理-à服务端
客户端不知道代理的存在
一般用于公司客户端上网
反向代理 客户端à代理<----->服务端
客户端不知道代理的存在
代理一般是由服务器设置,加快客户端的访问速度的
区别:区别在于代理对象不一样
正向代理的对象是客户端
反向代理的对象是服务端
负载均衡作用,常用软件,优缺点
负载均衡作用:提升吞吐率,提升请求性能,提高容灾
常用软件:nginx lvs haproxy
Nginx (支持四层和七层,应用四层需要添加--with_stream)
对网络稳定性的依赖非常小,理论上能ping通就能进行负载功能
安装和配置比较简单,测试起来比较方便
可以承担高负载压力且稳定
Nginx可以通过端口检测服务器内部的故障
Nginx仅能支持http,https,和email协议
对后端服务器的健康检查,只支持通过端口来检测,不支持通过URL来检测,
不支持session保持
lvs (四层)
抗负载能力强,是工作在网络4层之上仅作分发之用,
对内存和CPU资源消耗比较低
工作稳定,自身有完整的双击热备方案,如LVS+keepalived
应用范围比较广,因为LVS工作在四层,所以他几乎可以对所有应用负载均衡,
包括http,数据库,在线聊天室等
四层对网络稳定性依赖比较大
软件本身不支持正则表达式处理,不能做动静分离
haproxy(支持七层加模拟四层转发)
支持session的保持,同时支持通过获取指定的URL来检测后端服务器的状态
Haproxy支持TCP协议的负载均衡转发,可以对mysql读进行负载均衡,对后端的mysql节点进行检测和负载均衡,haproxy负载均衡策略非常多
Nginx 负载均衡调度策略有哪些
| 调度算法 | 描述 |
| 轮询 | 按时间顺序逐一分配到不同的后端服务器(默认) |
| Weight | 加权轮询,weight值越大,分配到的访问几率越高 |
| IP_hash | 每个请求按访问IP的hash结果分配,这样来自同一IP的固定访问一个后端服务器 |
| url_hash | 按照访问URL的hash结果来分配请求,使每个URL定向到同一个后端服务器 |
| Lest_conn | 最少连接数,哪个机器连接数少就分发 |
| Hash关键数值 | Hash自定义的key |
动静分离是做什么的,有什么好处吗
动静分离:通过中间件将请求和静态请求进行分离,分离资源,减少不必要的请求消耗,减少请求延时
好处:动静分离后,即使动态服务不可用,但静态资源不会受到影响,通过中间件将动态请求和静态请求分离
简述什么是CGI,fastcgi,php-fpm
CGI:就是web服务与PHP之间的桥梁,CGI就是规定要传哪些数据,以什么样的格式传递给后方处理这个请求的协议
Fastcgi:就是用来提高CGI程序性能的,会先启动一个master解析配置文件,初始化执行环境,然后在启动多个worker
php-fpm:fastcgi的管理器
Httpd都有什么工作模式
Prefork: 多进程的工作模式
Worker 多进程多线程的工作模式
Event: 多进程多线程的工作模式,解决了长连接的问题
常见http状态码并解释
200:正常请求 301:永久跳转 302:临时跳转 400:请求参数错误
401:账号密码错误 403:权限被拒绝 404:文件没找到
413:用户上传文件大小 502:后端服务无响应
504:后端服务执行超时
Nginx怎么去做性能优化
1)当前系统结构瓶颈
观察指标
压力测试ab(httpd-tools) | webbanch
2)了解业务模式
接口业务类型
系统层次结构
3)性能与安全
性能好安全弱
安全好性能低
关系型数据库与非关系型数据库区别
关系型数据库:数据拥有固定的存储结构,通过库--表--行--列的方式存储,存储时会有表的结构化关系,过程如下:解析sql语句--连接层--磁盘存取--结构化成表,;容易理解,使用方便,易于维护 海量数据的读写效率低 高扩展性和可用性,
非关系型数据库,就是为了加快客户端的访问速度才出现的,因为所有的非关系型数据库都是尽可能的将数据放到内存当中;非关系型数据库是以key:value的形式存储的;
以键值来存储,且结构不稳定,每一个元组都可以有不一样的字段,这种就不会局限于固定的结构,可以减少一些时间和空间的开销
简述mysql,他的存储原理
MySQL: 是一个关系型数据库管理系统,是一个真正的多用户、多线程SQL数据库服务器。SQL(结构化查询语言)是世界上最流行的和标准化的数据库语言。MySQL是以一个客户机/服务器结构的实现,它由一个服务器守护程序mysqld和很多不同的客户程序和库组成。 SQL是一种标准化的语言,它使得存储、更新和存取信息更容易;
存储原理:
1)连接池:最上层负责和客户端进行连接
2)SQL接口:当SQL语句进入MySQL后,会先到SQL接口中,这一层是封装层,将传过来的SQL语句拆散,将底层的结果封装成SQL的数据格式;
3)解析器:这一层负责将SQL语句进行拆分,验证,如果语句有问题那么就返回错误,如果没问题就继续向下执行;
4).优化器:对SQL查询的结果优化处理,产生多种执行计划,最终数据库会选择最优化的方案去执行,尽快返会结果。
5)缓存:对要查询的SQL语句进行hash后缓存,如果下一次是相同的查询语句,则在SQL接口之后直接返回结果;
6)存储引擎:MySQL有很多种存储引擎,每一种存储引擎有不同的特性,他们负责组织文件的存放形式,位置,访问文件的方法等等
7)文件系统:真正存放物理文件的单位;
Sql语句分类?数据类型char与varchar区别
DDL:数据定义语言,用来建立数据库,数据对象和定义其列,如create、alter、drop;
DML:数据操纵语言,用来查询、插入、删除、修改数据库中的数据,如select、insert、update、delete;
DCL:数据控制语言,用来控制数据库组件的存取许可,存取权限等,如commit、rollback、grant、revoke;
Char与varchar区别:
Char: char类型的长度是不可变的,是一个固定长度,写入数据若小于括号里的数据
格式就为数据+空格
Varchar: varchar的长度是可变的,写入多少实际就是多少
创建成绩表并插入内容,然后删除表结构
delete与drop区别
Delete:删除表数据,但结构还存在
Drop:删除整个表结构
mysql密码忘了怎么办
[root@my ~]# vi /etc/my.cnf
[mysqld]
skip-grant-tables ##添加该行,跳过密码验证,重启mysql服务生效
怎么解决mysql乱码问题
[root@my ~]# vi /etc/my.cnf
[client]
default-character-set=utf8 //添加改行并重启mysql服务生效
mysql事务四大特性并作解释
原子性(Atomic):事务的所有操作要么全部执行,要么全部不执行,如果中途出现错误不会停止,而是回滚到事务前的状态
一致性(Consistency):如果事务执行前是一致的,那么执行后也是一致的,不能破坏关系数据的完整性以及业务逻辑上的一致性,事务按照预期实现。
隔离性(lsolation):隔离性可以防止多个事务并发时导致数据的不一致
持久性(durability):事务执行成功后对数据库修改是永久的
管理事务有哪些命令?
begin:开始事务,后边有多条数据库操作语句开始执行;
commit:开始提交一个事务,对应前边的begin操作,将事务处理的结果保存到数据文件中;
rollback:开始回滚一个事务,在begin和commit之间,将事务中的全部语句撤回,恢复到执行begin之前的数据状态;
set autocommit = 0/1; :禁用或开启自动提交,自动提交为退出mysql连接程序时,或者执行下一条DML语句;
mysql全量备份与差异备份有什么区别
全量备份:每次对数据进行完整的备份,即对整个数据库的备份,数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份的基础,备份与恢复操作简单方便,但数据库存在大量的重复,占用大量的空间,备份与恢复时间长
差异备份:备份那些自从上次完全备份之后被修改过的所有文件,备份的时间起点是从上次完整备份起,备份数据量越来越大。恢复数据时,只需恢复上次的完全备份与最近的一次差异备份。
mysql主从复制原理及三种模式
Mysql主从复制原理:主库将变更写入binlog日志,然后从库连接主库后,从库有一个I/O线程,将主库的binlog日志拷贝到自己本地,写入一个relay中继日志中,接着从库有一个SQL线程会从中继日志中读取binlog,然后执行binlog日志中的内容,也就是在本地再执行一遍SQL,这样就可以保证自己跟主库的数据是一样的
Mysql主从复制三种模式:
异步复制模式:主库执行完成一个事务后,立即将结果返回给客户端,并不关心客户端是否已经接收并处理
全同步复制模式:主库执行完成一个事务后,且所有的从库都执行该事务并返回给客户端
半同步复制模式:主库执行完成一个事务后,等待至少一个从库接收到,写入relay log日志,才能返回给客户端(介于异步复制模式和全同步复制模式之间)
Mysql什么时候会重新生成二进制日志
重启mysql服务
mysql>flush logs; //刷新日志
mysql一般如何查看二进制日志文件
Mysqlbinlog;+二进制日志文件名
mysql主键,外键
主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
外键:在一个表中存在的另一个表的主键称此表的外键。
什么是存储过程?用什么来调用?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。
调用:
1)可以用一个命令对象来调用存储过程。
2)可以供外部程序调用,比如:java程序
nginx 的优缺点
优点:占内存小,可实现高并发连接,处理响应快
可实现http服务器、虚拟主机、方向代理、负载均衡
Nginx配置简单 可以不暴露正式的服务器IP地址
缺点: 动态处理差:nginx处理静态文件好,耗费内存少,但是处理动态页面则很鸡肋,现在一般前端用nginx作为反向代理抗住压力
nginx如何进行压力测试
例如:模拟10个用户,对百度首页发起100次请求
ab -n 100 -c 10 百度一下,你就知道
如何用nginx解决前端跨域问题
使用nginx转发请求,把跨域的接口写成本域的接口,然后将这些接口转发到真正的请求地址
Nginx怎么处理请求的:
nginx接收一个请求后,首先由listen和server_name指令匹配server模块,再匹配server模块里的location,location就是实际地址
Nginx四层负载和七层负载区别是什么?
四层基于IP+端口进行转发
七层就是基于URL等应用层信息的负载均衡
nginx限流怎么做
限流有三种:1.正常限制访问频率(正常流量)
2.突发限制访问频率(突发流量)
3.限制并发连接数
使用Redis有哪些好处
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都很低
(2)支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
持久化是什么
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 的持久化机制是什么?各自的优缺点?
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
Redis主要消耗什么物理资源
内存
Redis事务保证原子性吗,支持回滚吗?
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
Redis集群之间是如何复制的?
异步复制
Redis集群最大节点个数是多少?
16384个
Redis哨兵的工作流程?
集群监控:负责监控 redis master 和 slave 进程是否正常工作。
消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
redis主从复制原理?
Redis主从复制的策略就是:当主从服务器刚建立连接的时候,进行全量同步;全量复制结束后,进行增量复制。当然,如果有需要,slave 在任何时候都可以发起全量同步。
tomcat的配置文件server.xml中有三个端口,他们的作用是什么?
8080:用于监听浏览器转发过来的请求
8005:关闭tomcat通信的端口。这个端口负责监听关闭tomcat的请求
8009:接受其他服务器转发过来的请求
还有一个端口是8443
8443:如果发送过来的是https请求,就将请求转发到8443端口上
zabbix官方的一句话描述zabbix:
监视任何事情适用于任何IT基础架构,服务,应用程序和资源的解决方案
为什么要使用监控
.对系统不间断实时监控
.实时反馈系统当前状态
保证服务可靠性安全性
.保证业务持续稳定运行
你们公司监控的项目有哪些
监控了CPU使用率、内存剩余、磁盘使用空间、网卡流量、web服务、mysql主从、访问日志等
如果去到一家新的公司,如何入手?
.硬件监控——路由器、交换机、防火墙
.系统监控——cpu、内存、磁盘、网络、进程、tcp
.服务监控——nginx、php、tomcat、redis、memcache、mysql
.web监控——响应时间、加载时间、渲染时间
.日志监控——ELK、(收集、存储、分析、展示)日志
安全监控——firewalld、WAF(nginx+lua)、安全宝、牛盾云、安全狗
Zabbix报警流程:
在被监控端配置监控项,然后在监控项里配置图形和触发器,然后查看 动作里能够接受信息的用户是否存在,当触发器发生变化时通知动作里的用户,然后进行用户验证,确认添加了用户和用户组,然后确认用户关联好的报警媒介,然后报警媒介调用报警脚本,报警脚本可以实现通知报警平台,从而实现通知运维人员.
请简述zabbix监控的主要特点?
1.收集监控到到数据,能够可视化表现出来,并且可以设置报警装置,及时发现问题告知运维人员
2.部署比较简单,然后自动监控大型的动态环境
3.可以分布式监控
4.可以实现内外网的结合的监控系统
Redis内存用完了会发生什么
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
为什么 Redis 需要把所有数据放到内存中?
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘,所以 redis 具有快速和数据持久化的特征,如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的性能。
在内存越来越便宜的今天,redis 将会越来越受欢迎, 如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
为什么redis是单线程
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
location的作用是什么?
location指令的作用是根据用户请求的URL来执行不同的应用,也就是根据用户请求的网站URL进行匹配,匹配成功即进行相关操作
docker容器有几种状态
四种状态:运行,已停止,重新启动,已退出
DockerFile中最常见的指定是什么?
FROM 指定基础镜像
LABEL 功能为镜像指定标签
RUN 运行指定命令
CMD 容器启动时要运行的命令
docker容器推出后,通过docker ps命令查看不到,数据会丢失吗
容器退出后会处于终止(exited)状态,此时可以通过docker ps -a查看,其中数据不会丢失,还可以通过docker start来启动,只要删除容器才会清除数据。
本地的镜像文件都存放在哪里?
docker相关的本地资源存在/var/lib/docker/目录下,其中container目录存放容器信息,graph目录存放镜像信息,aufs目录下存放具体的镜像底层文件。
RabbitMQ 怎么保证消息的稳定性?
消息持久化
ACK确认机制
设置集群镜像模式
消息补偿机制
使用什么命令查看磁盘使用空间?空闲空间呢?
df -hl
Ansible 配置,优化有什么,怎么实现的自动化
配置:
/etc/hosts文件中添加被管理服务器ip
优化:
1、 Ansible SSH 关闭秘钥检测
2、 OpenSSH连接优化
3、SSH pipelining(管道输送)加速Ansible (默认关闭)
4、 Ansible Facts缓存优化
自动化:
在管理服务器上创建文件,通过命令行将指令传输到各个被管理服务器上
MQ的优点?
异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
日志处理 - 解决大量日志传输。
消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
使用了消息队列有什么缺点
系统可用性降低 系统复杂度提高
什么是rabbitmq?
RabbitMQ是一款开源的,Erlang编写的,消息中间件; 最大的特点就是消费并不需要确保提供方存在,实现了服务之间的高度解耦 可以用它来:解耦、异步、削峰。
查看各类环境变量使用: env命令
终止进程使用: kill命令
提升mysql安全级别(同mysql优化方案)
用shell脚本取出IP地址
#!/bin/bash
ip=`ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"
echo $ip
有的机器上可能没有安装net-tools可以使用ip addr
#!/bin/sh
ip addr | grep "ens33" | awk '/^[0-9]+: / {}; /inet.*global/ {print gensub(/(.*)\/(.*)/, "\\1", "g", $2)}
磁盘满了怎么办,但用df查看还有剩余空间是什么原因呢
du / -h --max-depth=1 命令查看各个目录的占用空间,找到占用较多空间的目录
df -i 命令查看 inode 的使用率,inode 不够会导致此问题
使用 lsof 检查,怀疑是不是有可能文件已被删除,但是进程还存活的场景
如果mount目录下原来是有文件存在的,那么该目录被 mount 之后这些文件就会被隐藏,不属于该文件系统,使用du命令是看不到
Keepalived如何配置高可用,原理是什么
Keepalived软件主要是通过VRRP协议实现高可用功能的。VRRP是Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行。
如何判断mysql是否同步
Slave_IO_Running
Slave_SQL_Running;
脚本计算1+2+3….+100=?
[root@localhost ~]# cat sum.sh
#!/bin/bash
num=1
sum=0
while [ $num -le 100 ]
dosum=$(expr $sum + $num)
let num++
done
echo "1+2+3...+100="$sum
[root@localhost ~]# sh sum.sh
1+2+3...+100=5050
统计一下/var/log/nginx/access.log 日志中访问量最多的前十个 IP?
cat access_log | awk ‘{print $1}’ | uniq -c|sort -rn|head -10
或
awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -nr -k1 | head -n 10
怎么查看当前系统中每个IP的连接数
# netstat -n | awk '/^tcp/ {print $5}' | awk -F: '{print $1}' | sort | uniq -c| sort –rn
sort 命令:进行排序,-r 反向排序 -n 使用纯数字进行排序
uniq 将重复的数据仅仅列出一个来显示,uniq -c,进行计数
awk -F: '{print $1}' 以 F 为分界符,取出第一个:之前的数据
查看linux系统所有配置的命令
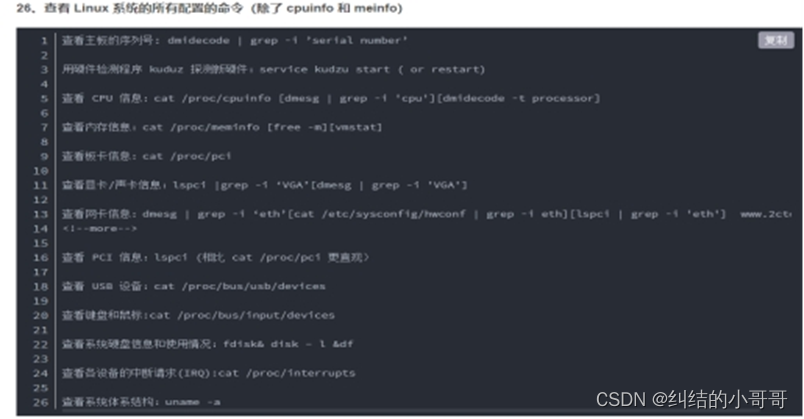
平时写过哪些Python脚本?
写一个脚本查找最后创建时间是三天前,后缀是*.log的文件并删除
find .-ctime +3 -name '*.log' | rm -rf
统计 ip 访问情况,要求分析 nginx 访问日志,找出访问页面数量在前十位的 ip
Cat access.log | awk '{print $1}' | uniq -c | sort -rn | head -10
使用tcpdump监听主机为192.168.1.1 ,tcp端口号为80的数据,同时将输出结果保存输出到tcpdump.log
tcpdump 'host 192.168.1.1 and port 80' > tcpdump.log
用Python将‘123456’反转为‘654321’
‘123456’[::-1]
现在有一个文件file1
1)请用shell查询file1里面空行的所在行号
#awk '$0 ~ /^$/ {print NR}' file1
或者 grep -n "^$" file1
2)编写shellscript查询file1以abc结尾的行
grep "abc$" file1
或 sed -n '/abc$/ p' file1
3)打印出file1 文件第一到第三行
sed -n '1,3p' file1
列出当前系统中所有的网络连接(包含进程名),请写出完整操作命令
netstat -antuple:
-a 显示所有 socket,包括正在监听的。
-n 以网络 IP 地址代替名称,显示出网络连接情形。
-t 显示 TCP 协议的连接情况
-u 显示 UDP 协议的连接情况。
-p 显示指定协议信息。
-l 或--listening 显示监控中的服务器的 Socket。
-e 显示以太网统计。此选项可以与 -s 选项结合使用。
请写出5个你常用的系统或网络维护工具的名称
rhel centos ubuntu
iotop用于检查 I/O 的使用情况
htop实质上是 top 的一个增强版本。它更容易对进程排序。
ping
traceroute
请问如何使用iptables工具来阻断192.168.0.1的所有网络连接
iptable -I INPUT -s 192.168.0.1 -j DROP
Mysql客户端工具中,请问如何查询当前所有的连接进程信息
mysql -u user -p password
-e "show processlist"
发现一个病毒文件你删了他又自动创建怎么解决
ps axu 一个个排查,方法是查看可疑的用户和系统相似而又不是的进程找出进程可疑。
杀掉所有与病毒相关的进程,然后删掉病毒这个可执行文件,最后删除病毒创建的文件
TCP/IP七层模型详解
应用层 (Application):
网络服务与最终用户的一个接口。
协议有:HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
表示层(Presentation Layer):
数据的表示、安全、压缩。(在五层模型里面已经合并到了应用层)
格式有,JPEG、ASCll、DECOIC、加密格式等
会话层(Session Layer):
建立、管理、终止会话。(在五层模型里面已经合并到了应用层)
对应主机进程,指本地主机与远程主机正在进行的会话
传输层 (Transport):
定义传输数据的协议端口号,以及流控和差错校验。
协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层
网络层 (Network):
进行逻辑地址寻址,实现不同网络之间的路径选择。
协议有:ICMP IGMP IP(IPV4 IPV6) ARP RARP
数据链路层 (Link):
建立逻辑连接、进行硬件地址寻址、差错校验等功能。(由底层网络定义协议)
将比特组合成字节进而组合成帧,用 MAC 地址访问介质,错误发现但不能纠正。
物理层(Physical Layer)
你常用nginx模块来做什么
rewrite 模块,实现重写功能
access模块:来源控制
ssl 模块:安全加密
ngx_http_gzip_module:网络传输压缩模块
ngx_http_proxy_module 模块实现代理
ngx_http_upstream_module 模块实现定义后端服务器列表
ngx_cache_purge 实现缓存清除功能
请列出你了解的web服务器负载架构
Nginx,,haproxy,,keepalived,,lvs
Kafka和mq有什么区别4
作为消息队列来说,企业中选择mq的还是多数,因为像Rabbit,Rocket等mq中间件都属于很成熟的产品,性能一般但可靠性较强,
而kafka原本设计的初衷是日志统计分析,现在基于大数据的背景下也可以做运营数据的分析统计,而redis的主要场景是内存数据库,作为消息队列来说可靠性太差,而且速度太依赖网络IO,在服务器本机上的速度较快,且容易出现数据堆积的问题,在比较轻量的场合下能够适用。
RabbitMQ,遵循AMQP协议,由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
kafka是Linkedin于2010年12月份开源的消息发布订阅系统,它主要用于处理活跃的流式数据,大数据量的数据处理上
K8s service类型?
ClusterIP
集群内部容器访问地址,会生成一个虚拟IP 与pod不在一个网段。
**NodePort **
会在宿主机上映射一个端口,供外部应用访问模式。
**Headless CluserIP **
无头模式,无serviceip,即把spec.clusterip设置为None 。
LoadBalancer
使用外部负载均衡。
K8s 健康检查方式
存活性探针(liveness probes)和就绪性探针(readiness probes)
用户通过 Liveness 探测可以告诉 Kubernetes 什么时候通过重启容器实现自愈
Readiness 探测则是告诉 Kubernetes 什么时候可以将容器加入到 Service 负载均衡池中,对外提供服务。语法是一样的。
软链接和硬链接有什么区别
软连接,其实就是新建立一个文件,这个文件就是专门用来指向别的文件的
硬链接实际上是为文件建一个别名,链接文件和原文件实际上是同一个文件
软链接可以跨文件系统,可以对一个不存在的文件名(filename)进行链接,可以对目录进行连接,硬链接不可以;
两种链接都可以通过命令 ln 来创建。ln 默认创建的是硬链接。
使用 -s 开关可以创建软链接
怎么给做好的镜像添加一个文件
用UltraISO PE (光软碟通)软件打开iso镜像文件就可以填加了
说说你们公司怎么发版的(代码怎么发布的)
jenkins配置好代码路径(SVN或GIT),然后拉代码,打tag。需要编译就编译,编译之后推送到发布服务器(jenkins里面可以调脚本),然后从分发服务器往下分发到业务服务器上。如果是php的项目,可以rsync上线,但是php也可以用Jenkins来操作,php7之后也是支持编译运行,这样上线之后运行效率更快,而且一定程度上保证了代码的安全。
Linux基础命令面试题:
绝对路径用什么符号表示,当前目录,上层目录,主目录用什么表示,怎么切换目录
绝对路径:如/etc/init.d
当前目录和上层目录:./ …/
主目录:~/
切换目录:cd
怎么查看当前进程,执行退出,查看当前路径
ps exit pwd
怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?
清屏:clear
退出当前命令:ctrl+c 彻底退出
执行睡眠 :ctrl+z 挂起当前进程fg 恢复后台
查看当前用户 id:”id“:查看显示目前登陆账户的 uid 和 gid 及所属分组及用户名
查看指定帮助:如 man adduser 这个很全 而且有例子;adduser --help 这个告诉你一些常用参数;info adduesr;
Ls 命令执行什么功能?可以带哪些参数,有什么区别?
ls 执行的功能:列出指定目录中的目录,以及文件
哪些参数以及区别: a 所有文件
l 详细信息,包括大小字节数,可读可写可执行的权限等
建立软链接(快捷方式),以及硬链接的命令。
软链接:ln -s slink source
硬链接:ln link source
目录创建用什么命令?创建文件用什么命令?复制文件用什么命令?
创建目录:mkdir
创建文件:典型的如 touch,vi 也可以创建文件,其实只要向一个不存在的文件输出, 都会创建文件
复制文件:cp
修改文件权限用什么命令
Chmod 777最高 r:w:x 读:写:执行
查看文件内容有哪些命令可以使用?
vi 文件名 #编辑方式查看,可修改
cat 文件名 #显示全部文件内容
more 文件名 #分页显示文件内容
less 文件名 #与 more 相似,更好的是可以往前翻页
tail 文件名 #仅查看尾部,还可以指定行数
head 文件名 #仅查看头部,还可以指定行数
终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
终端 /dev/tty
黑洞文件 /dev/null
移动文件用哪个命令?改名用哪个命令?:
移动文件:mv
重命名:mv
删除文件用哪个命令?如果需要连目录及目录下文件一块删除呢?删除空文件夹用什么命令?
rm rm -r rmdir
怎么使一个命令在后台运行?
一般都是使用 & 在命令结尾来让程序自动运行。(命令后可以不追加空格
利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息?
ps -ef (system v 输出)
ps -aux bsd 格式输出
ps -ef | grep pid
哪个命令专门用来查看后台任务?
job -l
怎么使一个命令在后台运行?
一般都是使用 & 在命令结尾来让程序自动运行。(命令后可以不追加空格)
把后台任务调到前台执行使用什么命令?把停下的后台任务在后台执行起来用什么命令?
把后台任务调到前台执行 fg
把停下的后台任务在后台执行起来 bg
怎么查看系统支持的所有信号?
kill -l
查看当前谁在使用该主机用什么命令? 查找自己所在的终端信息用什么命令?
查找自己所在的终端信息:who am i
查看当前谁在使用该主机:who
目前常用的磁盘分区格式是什么?
常用的分区格式有: FAT16、 FAT32、 NTFS、 Linux
BIOS是什么、进入 BIOS 的设置方式有哪些?
Bios是基本输入输出的程序、系统设置信息、开机上电自检程序和系统启动自启程序。1、按delete键 2,按F2键
什么是运维?
运维是指大型组织已经建立好的网络软硬件的维护,就是要保证业务的上线与运作的正常,在他运转的过程中,对他进行维护,他集合了网络、系统、数据库、开发、安全、监控于一身的技术
Linux 内核主要负责哪些功能?
1内存管理 2、进程管理 3、进程间通信 4、虚拟文件系统 5、网络接口
查看各类环境变量用什么命令?
查看所有 env
查看某个,如 home:env $HOME
通过什么命令指定命令提示符?
\u:显示当前用户账号
\h:显示当前主机名
\W:只显示当前路径最后一个目录
\w:显示当前绝对路径(当前用户目录会以~代替)
$PWD:显示当前全路径
$:显示命令行’$'或者’#'符号
#:下达的第几个命令
\d:代表日期,格式为week day month date,例如:“MonAug1”
\t:显示时间为24小时格式,如:HH:MM:SS
\T:显示时间为12小时格式
\A:显示时间为24小时格式:HH:MM
\v:BASH的版本信息 如export PS1=’[\u@\h\w#]$‘
通过什么命令查找执行命令?
which 只能查可执行文件
whereis 只能查二进制文件、说明文档,源文件等
怎么对命令进行取别名?
alias la=‘ls -a’
du 和 df 的定义,以及区别?
du 显示目录或文件的大小
df 显示每个<文件>所在的文件系统的信息,默认是显示所有文件系统。
df 命令获得真正的文件系统数据,而 du 命令只查看文件系统的部分情况。
如果一个linux新手想要知道当前系统支持的所有命令的列表,他需要怎么做?
使用命令compgen -c,可以打印出所有支持的命令列表。
你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
使用linux命令 ’disown -r ’可以将所有正在运行的进程移除。
哪一个bash内置命令能够进行数学运算。
bash shell 的内置命令let 可以进行整型数的数学运算。
#! /bin/bash
…
let c=a+b
使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
使用命令repquota 能够显示出一个文件系统的配额信息
【附】只有root用户才能够查看其它用户的配额。
如何查看/var/log/目录下的文件数
# ls -lR /var/log |grep "-"|wc -l //文件与目录的总个数
如何查看linux系统每个IP的连接数
# netstat -n|head -n 100|awk '/^tcp/ {print $4}'|awk -F ":" '{print $1}'|sort |uniq -c|sort -rn
42 123.78.121.167
27 127.0.0.1
介绍一下linux系统开机启动顺序
加载BIOS–>读取MBR–>Boot Loader–>加载内核–>用户层init用inittab文件来设定系统运行的等级(一般3或者5,3是多用户命令行,5是界面)–>init进程执行rc.syninit–>启动内核模块–>执行不同级别运行的脚本程序–>执行/etc/rc.d/rc.local(本地运行服务)–>执行/bin/login,就可以登录了
保存当前磁盘分区的分区表
# dd if=/dev/sda of=./mbr.txt bs=1 count=512
如何让history命令显示具体时间
$ HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S"
$ export HISTTIMEFORMAT
$ history
K8s:
简述ETCD及其特点?
etcd 是 CoreOS 团队发起的开源项目,是一个管理配置信息和服务发现(service discovery)的项目,
它的目标是构建一个高可用的分布式键值(key-value)数据库,基于 Go 语言实现。
特点:
简单:支持 REST 风格的 HTTP+JSON API
安全:支持 HTTPS 方式的访问
快速:支持并发 1k/s 的写操作
可靠:支持分布式结构,基于 Raft 的一致性算法,Raft 是一套通过选举主节点来实现分布式
系统一致性的算法。
简述ETCD适应的场景?
etcd基于其优秀的特点,可广泛的应用于以下场景:
服务发现(Service Discovery):服务发现主要解决在同一个分布式集群中的进程或服务,要如何才能找
到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听udp或tcp端口,并且
通过名字就可以查找和连接。
消息发布与订阅:在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配
置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有
消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新。应
用中用到的一些配置信息放到etcd上进行集中管理。
负载均衡:在分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署多
份,以此达到对等服务,即使其中的某一个服务失效了,也不影响使用。etcd本身分布式架构存储的信
息访问支持负载均衡。etcd集群化以后,每个etcd的核心节点都可以处理用户的请求。所以,把数据量
小但是访问频繁的消息数据直接存储到etcd中也可以实现负载均衡的效果。
分布式通知与协调:与消息发布和订阅类似,都用到了etcd中的Watcher机制,通过注册与异步通知机
制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。
分布式锁:因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致
的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
集群监控与Leader竞选:通过etcd来进行监控实现起来非常简单并且实时性强。
简述什么是Kubernetes?
Kubernetes是一个全新的基于容器技术的分布式系统支撑平台。是Google开源的容器集群管理系统
(谷歌内部:Borg)。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和
动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。并且具有完备的集群管理能力,多
层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、內建智能负载均衡
器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及
多粒度的资源配额管理能力。
简述Kubernetes和Docker的关系?
Docker 提供容器的生命周期管理和,Docker 镜像构建运行时容器。它的主要优点是将将软件/应用程序
运行所需的设置和依赖项打包到一个容器中,从而实现了可移植性等优点。
Kubernetes 用于关联和编排在多个主机上运行的容器。
简述Kubernetes中什么是Minikube、Kubectl、
Kubelet?
Minikube 是一种可以在本地轻松运行一个单节点 Kubernetes 群集的工具。
Kubectl 是一个命令行工具,可以使用该工具控制Kubernetes集群管理器,如检查群集资源,创建、删
除和更新组件,查看应用程序。
Kubelet 是一个代理服务,它在每个节点上运行,并使从服务器与主服务器通信。
简述Kubernetes常见的部署方式?
常见的Kubernetes部署方式有:
kubeadm:也是推荐的一种部署方式;
二进制
minikube
简述Kubernetes如何实现集群管理?
在集群管理方面,Kubernetes将集群中的机器划分为一个Master节点和一群工作节点Node。其中,在
Master节点运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kubescheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等
管理能力,并且都是全自动完成的。
简述Kubernetes的优势、适应场景及其特点?
Kubernetes作为一个完备的分布式系统支撑平台,其主要优势:
容器编排
轻量级
开源
弹性伸缩
负载均衡
Kubernetes常见场景:
快速部署应用
快速扩展应用
无缝对接新的应用功能
节省资源,优化硬件资源的使用
Kubernetes相关特点:
可移植: 支持公有云、私有云、混合云、多重云(multi-cloud)。
可扩展: 模块化,、插件化、可挂载、可组合。
自动化: 自动部署、自动重启、自动复制、自动伸缩/扩展。
简述Kubernetes的缺点或当前的不足之处?
Kubernetes当前存在的缺点(不足)如下:
安装过程和配置相对困难复杂。
管理服务相对繁琐。
运行和编译需要很多时间。
它比其他替代品更昂贵。
对于简单的应用程序来说,可能不需要涉及Kubernetes即可满足。
简述Kubernetes相关基础概念?
master:k8s集群的管理节点,负责管理集群,提供集群的资源数据访问入口。拥有Etcd存储服务(可选),运行Api Server进程,Controller Manager服务进程及Scheduler服务进程。
node(worker):Node(worker)是Kubernetes集群架构中运行Pod的服务节点,是Kubernetes集操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。运行docker eninge服务,守护进程kunelet及负载均衡器kube-proxy。
pod:运行于Node节点上,若干相关容器的组合(Kubernetes 之 Pod 实现原理)。Pod内包含的容器运行在同一宿主机上,使用相同的网络命名空间、IP地址和端口,能够通过localhost进行通信。Pod是Kurbernetes进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。
label:Kubernetes中的Label实质是一系列的Key/Value键值对,其中key与value可自定义。Label可以
附加到各种资源对象上,如Node、Pod、Service、RC等。一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去。Kubernetes通过Label Selector(标签选择器)查询和筛选资源对象。
Replication Controller:Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余容器数量。反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
Deployment:Deployment在内部使用了RS来实现目的,Deployment相当于RC的一次升级,其最大的特色为可以随时获知当前Pod的部署进度。
HPA(Horizontal Pod Autoscaler):Pod的横向自动扩容,也是Kubernetes的一种资源,通过追踪分析RC控制的所有Pod目标的负载变化情况,来确定是否需要针对性的调整Pod副本数量。
Service:Service(Kubernetes 之服务发现)定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,关联多个相同Label的Pod,用户不需要了解后台Pod是如何运行。
Volume:Volume是Pod中能够被多个容器访问的共享目录,Kubernetes中的Volume是定义在Pod上,可以被一个或多个Pod中的容器挂载到某个目录下。
Namespace:Namespace用于实现多租户的资源隔离,可将集群内部的资源对象分配到不同的Namespace中,形成逻辑上的不同项目、小组或用户组,便于不同的Namespace在共享使用整个集群的资源的同时还能被分别管理。
简述Kubernetes集群相关组件?
Kubernetes Master控制组件,调度管理整个系统(集群),包含如下组件:
Kubernetes API Server:作为Kubernetes系统的入口,其封装了核心对象的增删改查操作,以RESTful API接口方式提供给外部客户和内部组件调用,集群内各个功能模块之间数据交互和通信的中心枢纽。
Kubernetes Scheduler:为新建立的Pod进行节点(node)选择(即分配机器),负责集群的资源调度。
Kubernetes Controller:负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。
Replication Controller:管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。
Node Controller:管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。
Namespace Controller:管理维护Namespace,定期清理无效的Namespace,包括Namesapce下 的API对象,比如Pod、Service等。
Service Controller:管理维护Service,提供负载以及服务代理。
EndPoints Controller:管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints。
Service Account Controller:管理维护Service Account,为每个Namespace创建默认的ServiceAccount,同时为Service Account创建Service Account Secret。
Persistent Volume Controller:管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。
Daemon Set Controller:管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。
Deployment Controller:管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和Pod的更新。
Job Controller:管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目Pod Autoscaler Controller:实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
简述Kubernetes RC的机制?
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。当定义了RC并提交
至Kubernetes集群中之后,Master节点上的Controller Manager组件获悉,并同时巡检系统中当前存
活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,若存在过多的Pod副本在运行,系
统会停止一些Pod,反之则自动创建一些Pod。
简述Kubernetes Replica Set 和 Replication Controller 之间有什么区别?Replica Set 和 Replication
Controller 类似,都是确保在任何给定时间运行指定数量的 Pod 副本。不同之处在于RS 使用基于集合
的选择器,而 Replication Controller 使用基于权限的选择器。
简述kube-proxy作用?
kube-proxy 运行在所有节点上,它监听 apiserver 中 service 和 endpoint 的变化情况,创建路由规则
以提供服务 IP 和负载均衡功能。简单理解此进程是Service的透明代理兼负载均衡器,其核心功能是将
到某个Service的访问请求转发到后端的多个Pod实例上。
简述kube-proxy iptables原理?
Kubernetes从1.2版本开始,将iptables作为kube-proxy的默认模式。iptables模式下的kube-proxy不
再起到Proxy的作用,其核心功能:通过API Server的Watch接口实时跟踪Service与Endpoint的变更信
息,并更新对应的iptables规则,Client的请求流量则通过iptables的NAT机制“直接路由”到目标Pod。
简述kube-proxy ipvs原理?
IPVS在Kubernetes1.11中升级为GA稳定版。IPVS则专门用于高性能负载均衡,并使用更高效的数据结
构(Hash表),允许几乎无限的规模扩张,因此被kube-proxy采纳为最新模式。
在IPVS模式下,使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。iptables规则链是一
个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹
配。
可以将ipset简单理解为一个IP(段)的集合,这个集合的内容可以是IP地址、IP网段、端口等,iptables
可以直接添加规则对这个“可变的集合”进行操作,这样做的好处在于可以大大减少iptables规则的数量,
从而减少性能损耗。
简述kube-proxy ipvs和iptables的异同?
iptables与IPVS都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙
而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规
模扩张。
与iptables相比,IPVS拥有以下明显优势:
1、为大型集群提供了更好的可扩展性和性能;
2、支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
3、支持服务器健康检查和连接重试等功能;
4、可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。
简述Kubernetes中什么是静态Pod?
静态pod是由kubelet进行管理的仅存在于特定Node的Pod上,他们不能通过API Server进行管理,无法
与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对他们进行健康检
查。静态Pod总是由kubelet进行创建,并且总是在kubelet所在的Node上运行。
简述Kubernetes中Pod可能位于的状态?
Pending:API Server已经创建该Pod,且Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜
像的过程。
Running:Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状
态。
Succeeded:Pod内所有容器均成功执行退出,且不会重启。
Failed:Pod内所有容器均已退出,但至少有一个容器退出为失败状态。
Unknown:由于某种原因无法获取该Pod状态,可能由于网络通信不畅导致。
简述Kubernetes创建一个Pod的主要流程?
Kubernetes中创建一个Pod涉及多个组件之间联动,主要流程如下:
1、客户端提交Pod的配置信息(可以是yaml文件定义的信息)到kube-apiserver。 2、Apiserver收到指令后,通知给controller-manager创建一个资源对象。
3、Controller-manager通过api-server将pod的配置信息存储到ETCD数据中心中。
4、Kube-scheduler检测到pod信息会开始调度预选,会先过滤掉不符合Pod资源配置要求的节
点,然后开始调度调优,主要是挑选出更适合运行pod的节点,然后将pod的资源配置单发送到
node节点上的kubelet组件上。
5、Kubelet根据scheduler发来的资源配置单运行pod,运行成功后,将pod的运行信息返回给scheduler,scheduler将返回的pod运行状况的信息存储到etcd数据中心。
简述Kubernetes中Pod的重启策略?
Pod重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判
断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相
应操作。
Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
Always:当容器失效时,由kubelet自动重启该容器;
OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器;
Never:不论容器运行状态如何,kubelet都不会重启该容器。
同时Pod的重启策略与控制方式关联,当前可用于管理Pod的控制器包括ReplicationController、Job、
DaemonSet及直接管理kubelet管理(静态Pod)。
不同控制器的重启策略限制如下:
RC和DaemonSet:必须设置为Always,需要保证该容器持续运行;
Job:OnFailure或Never,确保容器执行完成后不再重启;
kubelet:在Pod失效时重启,不论将RestartPolicy设置为何值,也不会对Pod进行健康检查。
系统运维面试题
linux下查看服务程序占用的端口命令是什么?
netstat -apnt
cat -n file 1 file 2 命令是什么意思?
把a和b文件连在一起,然后输出到屏幕并打印行号。
什么命令可以从文件的每一行中截取指定内容数据。
Cut
liunx下查看磁盘使用基础命令是?
df
Dockerfile中RUN指令是什么意思?
容器启动时要运行的命令
kubemetes中pod的弹性伸缩适应 应用负责变化,以下选项能完成弹性伸缩的是?
HPA
docker中删除所有停带状态的容器命令是什么
docker rm $(sudo docker ps -a -q)
请用一句话解释进程与线程的差别
一个进程可以多线程,一个线程只对应一个进程。
对一个目录来说,rwx分别代表什么含义?
r读,w写,x执行
请用一句话解释下列linux命令用途: top grep mv find du cat wc chmod awk crontab netstat xargs ps uniq对以上命令进行翻译
top:查看进程、性能使用情况
grep:文本搜索
mv:文件的移动和改名
find:目录下查找文件
du:查看文件或目录使用空间
cat:查看文本
wc:统计字节数,字数,行数
chmod:赋权
awk:文本处理语言
crontab:定时命令
netstat:显示网络状态
xargs:给命令产生参数
ps:查看进程
unqid:删除文本相邻的重复行
Linux centos7.0后面lts是什么意思?
长时间维护版本
请尽可能简单地描述什么是死锁以及死锁生产的几个必要条件。
就是两个进程,无限期的阻塞,互相等待的过程。
必要条件:1:互斥 2:请求与保持 3:不剥夺 4:循环等待,缺一不可
接触的服务器的品牌,型号?
接触的服务器产品型号:戴尔的dell_r720x3
Linux开启启动过程
内核引导,运行init,初始化,建立终端,用户登录。
常见的缓存数据库有哪些
redis、memcached,mongodb
什么时候使用Redis,什么时候使用memcache呢
如果对持久化有需求就redsi,如果简单的key/value存储就选memcached。
我们运维常用的监控软件有哪些
Nagios cacti ganglia prometheus zabbix open-falcon
Zabbix监控有哪两种模式,并作简述
主动模式:被监控端主动将采集到的数据,发送给监控端
被动模式:zabbix默认的模式,监控端定时的向被监控端拿数据
Ansible做什么用的,有哪些特点
常见的自动化运维工具:Ansible saltstack puppet
Ansible是一款简单的运维自动化工具,只需要使用ssh协议连接就可以来进行系统管理,自动化执行命令,部署等任务。
Ansible的特点
- ansible不需要单独安装客户端,也不需要启动任何服务
2、ansible是python中的一套完整的自动化执行任务模块
3、ansible playbook 采用yaml配置,对于自动化任务执行过一目了然
Ansible模块中command,shell,user的作用
Command:ansible默认的模块,用来执行命令
Shell:专门用来执行shell命令的模块,和command模块一样,参数基本一样
Ansible-doc常用命令,解释-j,-l,-s
-j:以json格式显示所有模块信息
-l: 列出所有的模块
-s:查看模块常用参数
Cron计划任务的工作机制
分 时 日 月 周
Ansible都有哪些结构组成
Ansible
是Ansible的命令工具,核心执行工具;一次性或临时执行的操作都是通过该命令执行。
Ansible Playbook
任务剧本(又称任务集),编排定义Ansible任务集的配置文件,由Ansible顺序依次执行,yaml格式。
Inventory
Ansible管理主机的清单,默认是/etc/ansible/hosts文件。
Modules
Ansible执行命令的功能模块,Ansible2.3版本为止,共有1039个模块。还可以自定义模块。
Plugins
插件,模块功能的补充,常有连接类型插件,循环插件,变量插件,过滤插件,插件功能用的较少。
API
提供给第三方程序调用的应用程序编程接口。
使用grant设置root用户密码和权限,禁止远程登录链接数据库
Grant all on *.* to ‘root’ @’ip地址’ identity by ‘密码’
网络运维面试题
防火墙有几种类型
(1)防火墙有包过滤防火墙、(2)代理服务器防火墙、(3)状态监视器防火墙
简述生成树的协议
(1)是一种工作在OSI网络模型中的第二层(数据链路层)的通信协议,基本应用是防止交换机冗余链路产生的环路.用于确保以太网中无环路的逻辑拓扑结构.从而避免了广播风暴,大量占用交换机的资源
(2)工作原理:生成树协议工作原理:任意一交换机中如果到达根网桥有两条或者两条以上的链路.生成树协议都根据算法仅仅保留一条,把其他切断,从而保证任意两个交换机之间只有一条单一的活动链路。因为这种生成的这种拓扑结构,很像是以根交换机为树干的树形结构.故为生成树协议。
(3)端口状态STP端口状态
端口状态 端口能力
Disabled 不收发任何报文
Blocking 不接收或者转发数据,接收但不发送BPDU,不进行地址学习
Listening 不接收或者转发数据,接收并发送BPDU,不进行地址学习
Learning 不接收或者转发数据,接收并发送BPDU,开始进行地址学习
Forwarding 接收或者转发数据,接收并发送BPDU,进行地址学习
(4)特点:(1)生成树协议提供一种控制环路的方法。采用这种方法,在连接发生问题的时候,你控制的以太网能够绕过出现故障的连接。
(2)生成树中的根桥是一个逻辑的中心,并且监视整个网络的通信。最好不要依靠设备的自动选择去挑选哪一个网桥会成为根桥。
(3)生成树协议重新计算是繁冗的。恰当地设置主机连接端口(这样就不会引起重新计算),推荐使用快速生成树协议。
(4)生成树协议可以有效的抑制广播风暴。开启生成树协议后抑制广播风暴,网络将会更加稳定,可靠性、安全性会
STP,RSTP,MSTP有什么区别?
1、迁移不同
1、STP:STP不能快速迁移,即使是在点对点链路或边缘端口,也必须等待时间延迟,网络才能收敛。
2、RSTP:RSTP可以快速迁移,却不能按vlan阻塞冗余链路。
3、MRSTP:MRSTP允许不同vlan的流量沿各自的路径分发,实现快速迁移不阻塞。
2.2、负载分担不同
1、STP:STP都采用了一棵STP tree,负载分担不可实现。
2、RSTP:RSTP都采用了一棵STP tree,负载分担不可实现。
3、MRSTP:MRSTP采用了每个VLAN一棵生成树,可以将多个VLAN的生成树映射为一个实例,实现负载分担。
2.3、字段利用不同
1、STP:STP对BPDU中type字段的利用,只使用了其中的两个位。
2、RSTP:RSTP对BPDU中type字段的利用,使用了所有的八个位。
3、MRSTP:MRSTP对BPDU中type字段的利用,使用了所有的八个位
请写出568A与568B线序
568A 白绿、绿、 白橙、蓝 白蓝、橙 白棕、棕
T568B :白橙、橙 白绿、蓝 白蓝、绿 白棕、棕
路由器和交换机属于几层设备
路由器属于三层设备,交换机(通常所指的)属于二层设备
查看编辑本地策略,可以在开始/运行中输入什么命令?
gpedit.msc
将 FAT32 转换为 NTFS 分区的命令是什么?
convert x: /fs:ntfs x:表示要转换的分区
知道现在流行的SAN网络平台吗?它主要是为计算机的哪个领域提出的一个解决方案?
SAN 是指存储区域网络,它是一种高速网络或子网络,提供在计算机与存储系统之间的数据 传输。一个 SAN 网络由负责网络连接的通信结构、负责组织连接的管理层、存储部件以及 计算机系统构成,从而保证数据传输的安全性和力度。
讲述 RIP 和 OSPF,它们的区别、特点。
RIP 协议是一种传统的路由协议,适合比较小型的网络,但是当前 Internet 网络的迅速发展 和急剧膨胀使 RIP 协议无法适应今天的网络。
OSPF 协议则是在 Internet 网络急剧膨胀的时候制定出来的,它克服了 RIP 协议的许多缺陷。
RIP 是距离矢量路由协议;OSPF 是链路状态路由协议。
RIP&OSPF 管理距离分别是:120 和 110
1)RIP 协议一条路由有 15 跳(网关或路由器)的限制,如果一个 RIP 网络路由跨越超过 15跳(路由器),则它认为网络不可到达,而 OSPF 对跨越路由器的个数没有限制。
2)OSPF 协议支持可变长度子网掩码(VLSM),RIP 则不支持,这使得 RIP 协议对当前 IP 地 址的缺乏和可变长度子网掩码的灵活性缺少支持。
3)RIP 协议不是针对网络的实际情况而是定期地广播路由表,这对网络的带宽资源是个极 大的浪费,特别对大型的广域网。OSPF 协议的路由广播更新只发生在路由状态变化的时候, 采用 IP 多路广播来发送链路状态更新信息,这样对带宽是个节约。
4)RIP 网络是一个平面网络,对网络没有分层。OSPF 在网络中建立起层次概念,在自治域 中可以划分网络域,使路由的广播限制在一定的范围内,避免链路中继资源的浪费。
5)OSPF 在路由广播时采用了授权机制,保证了网络安全。
上述两者的差异显示了 OSPF 协议后来居上的特点,其先进性和复杂性使它适应了今天日趋庞大的 Internet 网,并成为主要的互联网路由协议
介绍一下 ACL 和 NAT?NAT 有几种方式?
ACL:1、访问控制列表(ACL)是应用在路由器接口的指令列表(规则),用来告诉路由器 哪些数据包可以接收转发,哪些数据包需要拒绝;
2、ACL 的工作原理 :读取第三层及第四 层包头中的信息,根据预先定义好的规则对包进行过滤;3、使用 ACL 实现网络控制:实现 访问控制列表的核心技术是包过滤;
4、ACL 的两种基本类型(标准访问控制列表;扩展访 问控制列表)
NAT:改变 IP 包头使目的地址,源地址或两个地址在包头中被不同地址替换。 静态 NAT、动态 NAT、PAT
STP 协议的主要用途是什么?为什么要用 STP?
主要用途:
1、STP 通过阻塞冗余链路,来消除桥接网络中可能存在的路径回环;
2、当前活 动路径发生故障时,STP 激活冗余链路恢复网络连通性;
原因:交换网络存在环路时引起:广播环路(广播风暴);桥表损坏;
什么是静态路由?什么是动态路由?各自的特点是什么?
静态路由是由管理员在路由器中手动配置的固定路由,路由明确地指定了包到达目的地必须 经过的路径,除非网络管理员干预,否则静态路由不会发生变化。静态路由不能对网络的改 变作出反应,所以一般说静态路由用于网络规模不大、拓扑结构相对固定的网络。 静态路由特点
什么是动态路由?
1)它允许对路由的行为进行精确的控制;
2)减少了网络流量;
3)是单向的;
4)配置简单。 动态路由是网络中的路由器之间相互通信,传递路由信息,利用收到的路由信息更新路由器 表的过程。是基于某种路由协议来实现的。常见的路由协议类型有:距离向量路由协议(如 RIP)和链路状态路由协议(如 OSPF)。路由协议定义了路由器在与其它路由器通信时的一 些规则。动态路由协议一般都有路由算法。其路由选择算法的必要步骤
(1)向其它路由器传递路由信息;
(2)接收其它路由器的路由信息;
(3)根据收到的路由信息计算出到每个目的网络的最优路径,并由此生成路由选择表;
(4)根据网络拓扑的变化及时的做出反应,调整路由生成新的路由选择表,同时把拓扑变化 以路由信息的形式向其它路由器宣告。
动态路由适用于网络规模大、拓扑复杂的网络。 动态路由特点:
1)无需管理员手工维护,减轻了管理员的工作负担。
2)占用了网络带宽。
3)在路由器上运行路由协议,使路由器可以自动根据网络拓朴结构的变化调整路由条目;
PAT 和 NAT 有什么区别?
PAT 叫端口地址转换,NAT 是网络地址转换,由 RFC 1631 定义。PAT 可以看做是 NAT 的一部 分。在 NAT 时,考虑一种情形,就是只有一个 Public IP,而内部有多个 Private IP,这个时候 NAT 就要通过映射 UDP 和 TCP 端口号来跟踪记录不同的会话,比如用户 A、B、C 同时访问 CSDN,则 NAT 路由器会将用户 A、B、C 访问分别映射到 1088、1098、23100(举例而已, 实际上是动态的),此时实际上就是 PAT 了。
由上面推论,PAT 理论上可以同时支持(65535 - 1024)= 64511 个连接会话。但实际使用中 由于设备性能和物理连接特性是不能达到的,CISCO 的路由器 NAT 功能中每个 Public IP 最多 能有效地支持大约 4000 个会话。
交换机是如何转发数据包的?
交换机通过学习数据帧中的源 MAC 地址生成交换机的 MAC 地址表,交换机查看数据帧的目 标 MAC 地址,根据 MAC 地址表转发数据,如果交换机在表中没有找到匹配项,则向除接受 到这个数据帧的端口以外的所有端口广播这个数据帧。
简述 STP 的作用及工作原理。
作用:
(1) 能够在逻辑上阻断环路,生成树形结构的拓扑;
(2) 能够不断的检测网络的变化,当主要的线路出现故障断开的时候,STP 还能通过计算激 活阻起到断的端口,起到链路的备份作用。
工作原理:
STP 将一个环形网络生成无环拓朴的步骤: 选择根网桥(Root Bridge)
选择根端口(Root Ports) 选择指定端口(Designated Ports)
生成树机理每个 STP 实例中有一个根网桥 ,每个非根网桥上都有一个根端口 ,每个网段有一个指定端口,非指定端口被阻塞 STP 是交换网络的重点,考察是否理解。
.NAT 的原理及优缺点?
原理:转换内部地址,转换外部地址,PAT,解决地址重叠问题。
优点:节省 IP 地址,能够处理地址重复的情况,增加了灵活性,消除了地址重新编号,隐藏了内部IP 地址。
缺点:增加了延迟,丢失了端到端的 IP 的跟踪过程,不能够支持一些特定的应用(如:SNMP),需要 更多的内存来存储一个 NAT 表,需要更多的 CPU 来处理 NAT 的过程.
说说 ARP 的解析过程。
ARP 用于把一个已知的 IP 地址解析成 MAC 地址,以便在 MAC 层通信。为了确定目标 的 MAC 地址,首先查找 ARP 缓存表。如果要查找的 MAC 地址不在表中,ARP 会发送一个广 播,从而发现目的地的 MAC 地址,并记录到 ARP 缓存表中以便下次查找
.DHCP 的作用是什么,如何让一个 vlan 中的 DHCP 服务器为整个企业网络分配 IP 地址?
作用:动态主机配置协议,为客户端动态分配 IP 地址.
配置 DHCP 中继,也就是帮助地址.(因为 DHCP 是基于广播的,vlan 或路由器隔离了广播)
把上个命令的参数作为cd参数使用
cd !$
BASH和DOS之间的基本区别是什么?
BASH和DOS控制台之间的主要区别在于3个方面:
1. BASH命令区分大小写,而DOS命令则不区分;
2. 在BASH下,/ character是目录分隔符,\作为转义字符。在DOS下,/用作命令参数分隔符,\是目录分隔符
3. OS遵循命名文件中的约定,即8个字符的文件名后跟一个点,扩展名为3个字符。BASH没有遵循这样的惯例。
223. Linux的基本组件是什么?
就像任何其他典型的操作系统一样,Linux拥有所有这些组件:内核,shell和GUI,系统实用程序和应用程序。Linux比其他操作系统更具优势的是每个方面都附带其他功能,所有代码都可以免费下载。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









