






Rabbitmq 集群
集群目的就是为了实现rabbitmq的高可用性,集群分为2种
- 普通集群:主备架构,只是实现主备方案,不至于主节点宕机导致整个服务无法使用
- 镜像集群:同步结构,基于普通集群实现的队列同步
普通集群
slave节点复制master节点的所有数据和状态,除了队列数据,队列数据只存在master节点,但是Rabbitmq slave节点可以实现队列的转发,也就是说消息消费者可以连接到slave节点,但是slave需要连接到master节点转发队列,由此说明只能保证了服务可以用,无法达到高可用
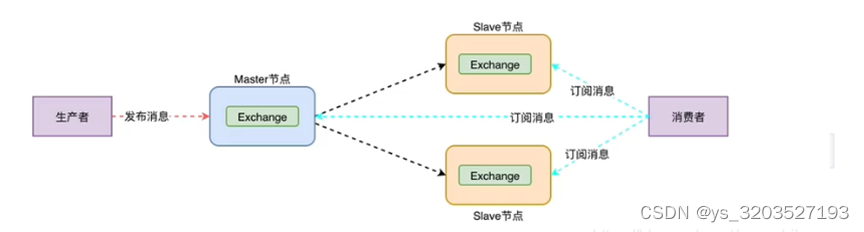
slave节点队列可以查看到,但是不会同步数据
镜像集群
基于普通集群实现队列的集群主从,消息会在集群中同步(至少三个节点)

集群架构
RabbitMQ 集群是一个或多个节点的逻辑分组,集群中的每个节点都是对等的
每个节点共享所有的用户,虚拟主机,队列,交换器,绑定关系,运行时参数和其他分布式状态等信息。
一个高可用,负载均衡的 RabbitMQ 集群架构应类似下图:
这里对上面的集群架构做一下解释说明:
1)首先一个基本的 RabbitMQ 集群不是高可用的
虽然集群共享队列,但在默认情况下,消息只会被路由到某一个节点的符合条件的队列上,并不会同步到其他节点的相同队列上。
假设消息路由到 node1 的 my-queue 队列上,但是 node1 突然宕机了,那么消息就会丢失
想要解决这个问题,需要开启队列镜像,将集群中的队列彼此之间进行镜像,此时消息就会被拷贝到处于同一个镜像分组中的所有队列上。
2)其次 RabbitMQ 集群本身并没有提供负载均衡的功能
也就是说对于一个三节点的集群,每个节点的负载可能都是不相同的,想要解决这个问题可以通过硬件负载均衡或者软件负载均衡的方式
这里我们选择使用 HAProxy 来进行负载均衡,当然也可以使用其他负载均衡中间件,如LVS等。
HAProxy 同时支持四层和七层负载均衡,并基于单一进程的事件驱动模型,因此它可以支持非常高的井发连接数。
3)接着假设我们只采用一台 HAProxy
那么它就存在明显的单点故障的问题
所以至少需要两台 HAProxy ,同时这两台 HAProxy 之间需要能够自动进行故障转移,通常的解决方案就是 KeepAlived 。
KeepAlived 采用 VRRP (Virtual Router Redundancy Protocol,虚拟路由冗余协议) 来解决单点失效的问题
它通常由一组一备两个节点组成,同一时间内只有主节点会提供对外服务,并同时提供一个虚拟的 IP 地址 (Virtual Internet Protocol Address ,简称 VIP) 。
如果主节点故障,那么备份节点会自动接管 VIP 并成为新的主节点 ,直到原有的主节点恢复。
4)最后,任何想要连接到 RabbitMQ 集群的客户端
只需要连接到虚拟 IP,而不必关心集群是何种架构。
搭建集群准备:
1、准备3个虚拟机
| 192.168.10.168 | controller | Erlang+RabbitMQ |
| 192.168.10.135 | node1 | Erlang+RabbitMQ |
| 192.168.10.140 | node2 | Erlang+RabbitMQ |
修改虚拟机名称
hostnamectl set-hostname controller
hostnamectl set-hostname node1
hostnamectl set-hostname node2
2.配置hosts
cat>>/etc/hosts<<EOL
192.168.11.163 controller
192.168.11.133 node1
192.168.11.132 node2
EOL
3.安装Erlang
由于RabbitMQ是基于Erlang(面向高并发的语言)语言开发,所以在安装RabbitMQ之前,需要先安装Erlang。
1.选择Erlang和RabbitMQ版本
这里选择RabbitMQ3.9.x、Erlang24.0,查看对应版本
- 更新基本系统,安装任何软件包之前,建议使用以下命令更新软件包和存储库
yum -y update
- 首先要先安装GCC、 GCC-C++、 Openssl等依赖模块:
yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel
- 再安装ncurses模块
yum -y install ncurses-devel
- 解压ErLang安装包
tar xf otp_src_24.0-rc1.tar.gz
mv otp_src_24.0-rc1 /usr/local/
mkdir /usr/local/erlang
cd /usr/local/otp_src_24.0-rc1/
./configure --prefix=/usr/local/erlang --with-ssl --enable-threads --enable-smp-support --enable-kernel-poll --enable-hipe --without-javac
erlang的编译需要用到java环境,如果不装,会报错如下,但不影响后续操作
make && make install
配置环境变量
vi /etc/profile
PATH=$PATH:/usr/local/erlang/bin
source /etc/profile
直接输入 erl 、得到如下图得安装成功,输入 halt(). 退出

4.安装RabbitMQ:
tar xf rabbitmq-server-generic-unix-3.8.16.tar.xz
mv rabbitmq_server-3.8.16 /usr/local/
vi /etc/profile
PATH=$PATH:/usr/local/rabbitmq_server-3.8.16/sbin
source /etc/profile
cd /usr/local/rabbitmq_server-3.8.16/
cd sbin/
启动web管理插件
rabbitmq-plugins enable rabbitmq_management
后台启动rabbitmq服务
rabbitmq-server -detached
启用了rabbitmq的管理插件,会有一个web管理界面,默认监听端口15672,将此端口在防火墙上打开,则可以访问web界面:
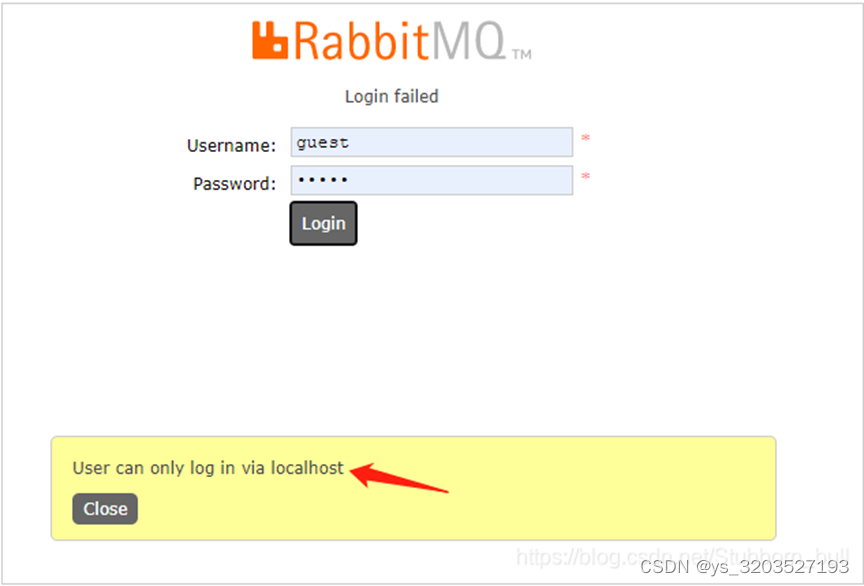
使用默认的用户 guest / guest (此也为管理员用户)登陆,会发现无法登陆,
报错:User can only log in via localhost。
那是因为默认是限制了guest用户只能在本机登陆,也就是只能登陆localhost:15672。
可以通过修改配置文件rabbitmq.conf,取消这个限制: loopback_users这个项就是控制访问的,
如果只是取消guest用户的话,只需要loopback_users.guest = false 即可。或者添加远程用户
添加远程用户
# 添加用户
rabbitmqctl add_user 用户名 密码
# 设置用户角色,分配操作权限
rabbitmqctl set_user_tags 用户名 角色
# 为用户添加资源权限(授予访问虚拟机根节点的所有权限)
rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*"
角色有四种:
- administrator:可以登录控制台、查看所有信息、并对rabbitmq进行管理
- monToring:监控者;登录控制台,查看所有信息
- policymaker:策略制定者;登录控制台指定策略
- managment:普通管理员;登录控制
这里创建用户rabbitadmin,密码rabbitadmin,设置administrator角色,赋予所有权限
rabbitmqctl add_user rabbitadmin rabbitadmin
rabbitmqctl set_user_tags rabbitadmin administrator
rabbitmqctl set_permissions -p / rabbitadmin ".*" ".*" ".*"
登录,其他两台虚拟机也是如上配置

同步cookie:
- 如何查看cookie
/usr/local/rabbitmq_server-3.8.16/var/log/rabbitmq

我的${home}目录是/root,切换到root目录下,该文件是一个隐藏文件,需要使用 ls -al 命令查看

- 同步(拷贝.cookie时,各节点都必须停止MQ服务,在node1上执行远程操作命令)
rabbitmqctl stop_app
scp /root/.erlang.cookie root@node1:/root/
scp /root/.erlang.cookie root@node2:/root/
集群搭建:
- 启动RabbitMQ服务,顺带启动Erlang虚拟机和RabbitMQ应用服务,在controller、node2、node3执行命令
rabbitmq-server -detached
2、RabbitMQ 集群的搭建需要选择其中任意一个节点为基准,将其它节点逐步加入。这里我们以 controller 为基准节点,将 node1 和 node2 加入集群。在 node1 和node2 上执行以下命令:
# 1.停止服务
rabbitmqctl stop_app
# rabbitmqctl stop会将Erlang虚拟机关闭,rabbitmqctl stop_app只关闭RabbitMQ服务
# 2.重置状态
rabbitmqctl reset
# 3.节点加入, 在一个node加入cluster之前,必须先停止该node的rabbitmq应用,即先执行stop_app
# node1加入controller , node2加入node1
rabbitmqctl join_cluster rabbit@controller
# 4.启动服务
rabbitmqctl start_app
join_cluster 命令有一个可选的参数 --ram ,该参数代表新加入的节点是内存节点,默认是磁盘节点。
如果是内存节点,则所有的队列、交换器、绑定关系、用户、访问权限和 vhost 的元数据都将存储在内存中,
如果是磁盘节点,则存储在磁盘中。
内存节点可以有更高的性能,但其重启后所有配置信息都会丢失,
因此RabbitMQ 要求在集群中至少有一个磁盘节点,其他节点可以是内存节点。
当内存节点离开集群时,它可以将变更通知到至少一个磁盘节点;
然后在其重启时,再连接到磁盘节点上获取元数据信息。
除非是将 RabbitMQ 用于 RPC 这种需要超低延迟的场景,
否则在大多数情况下,RabbitMQ 的性能都是够用的,可以采用默认的磁盘节点的形式。
另外,如果节点以磁盘节点的形式加入,则需要先使用 reset 命令进行重置,然后才能加入现有群集,重置节点会删除该节点上存在的所有的历史资源和数据。
采用内存节点的形式加入时可以略过 reset 这一步,因为内存上的数据本身就不是持久化的
3、查看集群状态
此时可以在任意节点上使用 rabbitmqctl cluster_status 命令查看集群状态,输出如下:

- UI 界面查看

镜像队列:
- 镜像的配置是通过 policy 策略的方式,以命令的方式设置 或 UI界面设置
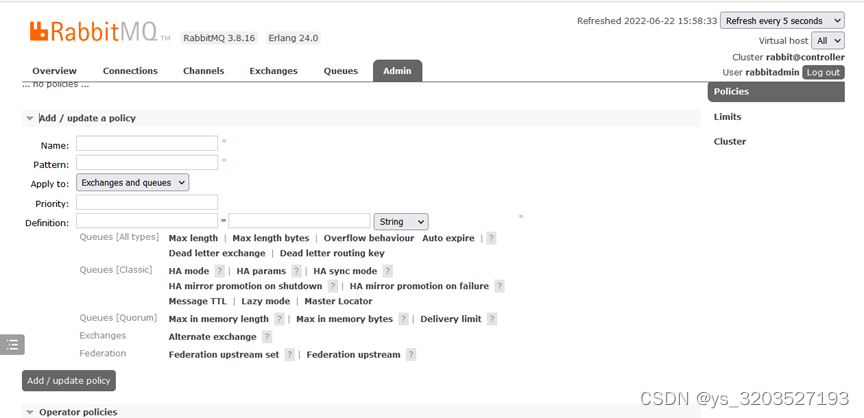
2、参数说明:
- Name:policy的名称
- Pattern: queue的匹配模式(正则表达式)
- priority:可选参数,policy的优先级
- Definition:镜像定义,包括三个部分ha-mode、ha-params、ha-sync-mode
- ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
- all:表示在集群中所有的节点上进行镜像
- exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
- nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
- ha-params:ha-mode模式需要用到的参数
- ha-sync-mode:进行队列中消息的同步方式,有效值为automatic(自动)和manual(手动)
- 对队列名称以“queue_”开头的所有队列进行镜像,并在集群的两个节点上完成进行,policy的设置命令为:
[root@ controller~]# rabbitmqctl set_policy ha-queue-two '^queue_' '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
Setting policy "ha-queue-two" for pattern "^queue_" to "{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}" with priority "0" for vhost "/" ...
[root@controller ~]#
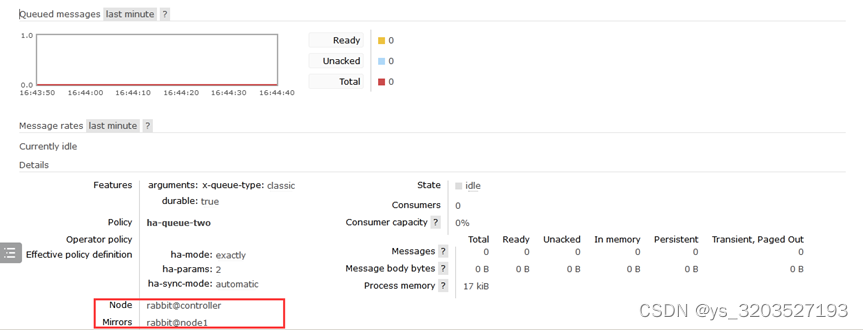
- 在任意节点(我在controller节点)创建queue_testQueue队列,并查看镜像状态

上图Node中的+1表示备份,下图中的Mirrors就是备份的节点,若controller宕机了node1就会代替controller继续提供服务
测试:首先关闭controller节点
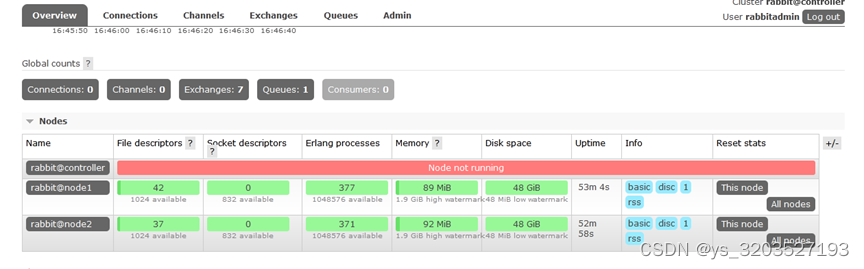
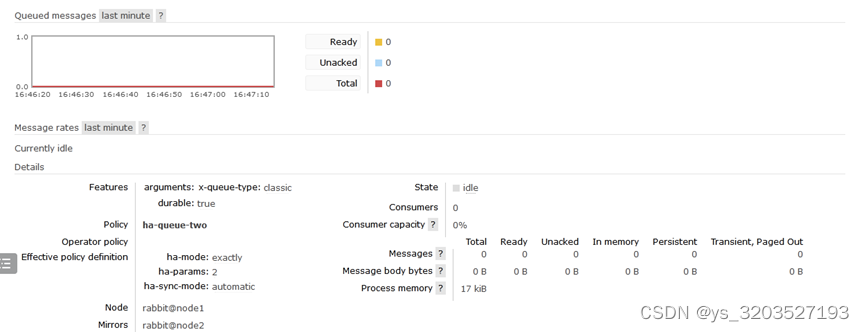
然后查看node1节点上的镜像状态,发现在node2节点也进行了备份,以此说明:就算整个集群只剩下一台机器了,依然能消费队列里面的消息
5、复制系数
若ha-mode 的值为 all ,代表消息会被同步到所有节点的相同队列中,如果你的集群有很多节点,那么此时复制的性能开销就比较大,此时需要选择合适的复制系数。
通常可以遵循过半写原则,即对于一个节点数为 n 的集群,只需要同步到 n/2+1 个节点上即可。
6、集群的关闭与重启
没有一个直接的命令可以关闭整个集群,需要逐一进行关闭。但是需要保证在重启时,最后关闭的节点最先被启动。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的那个节点启动,默认进行 10 次连接尝试,超时时间为 30 秒,如果依然没有等到,则该节点启动失败。
这带来的一个问题是,假设在一个三节点的集群当中,关闭的顺序为 node1,node2,node3,如果 node1 因为故障暂时没法恢复,此时 node2 和 node3 就无法启动。想要解决这个问题,可以先将 node1 节点进行剔除,命令如下:
rabbitmqctl forget_cluster_node rabbit@node1 --offline
此时需要加上 -offline 参数,它允许节点在自身没有启动的情况下将其他节点剔除。
7、解除集群
重置当前节点:
# 1.停止服务
rabbitmqctl stop_app
# 2.重置集群状态
rabbitmqctl reset
# 3.重启服务
rabbitmqctl start_app
重新加入集群:
# 1.停止服务
rabbitmqctl stop_app
# 2.重置状态
rabbitmqctl reset
# 3.节点加入
rabbitmqctl join_cluster rabbit@node1
# 4.重启服务
rabbitmqctl start_app
完成后重新检查 RabbitMQ 集群状态:
rabbitmqctl cluster_status
除了在当前节点重置集群外,还可在集群其他正常节点将节点踢出集群
rabbitmqctl forget_cluster_node rabbit@node3
8、变更节点类型
我们可以将节点的类型从RAM更改为Disk,反之亦然。假设我们想要反转rabbit@node2和rabbit@node1的类型,将前者从RAM节点转换为磁盘节点,而后者从磁盘节点转换为RAM节点。为此,我们可以使用change_cluster_node_type命令。必须首先停止节点。
# 1.停止服务
rabbitmqctl stop_app
# 2.变更类型 ram disc
rabbitmqctl change_cluster_node_type disc
# 3.重启服务
rabbitmqctl start_app
- 清除 RabbitMQ 节点配置
# 如果遇到不能正常退出直接kill进程
systemctl stop rabbitmq-server
# 查看进程
ps aux|grep rabbitmq
# 清除节点rabbitmq配置
rm -rf /var/lib/rabbitmq/mnesia
















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









