







AC算法初探
一、什么是AC算法
AC算法,即Aho-Corasick自动机算法。 该算法一次遍历原串便可定位所有模式串在原串中出现的位置。该算法通过所有的模式串构建一个有限状态自动机,然后用这个自动机去处理原串(只要一次遍历即可);
二、AC算法流程
AC算法总共由三部分组成,分别是a) Goto函数 b) Failure 函数 c) Output 函数
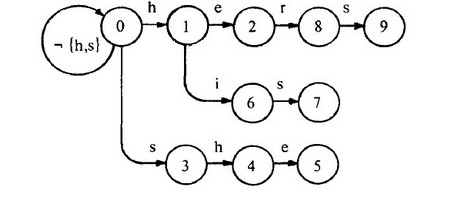
举个例子,设模式串组为{he, she, his, hers} 原串为“ushers”
下面直接给出Goto函数表、 Failure函数表以及Output函数表
a) Goto函数表
b)Failure函数表
i 1 2 3 4 5 6 7 8 9
f(i) 0 0 0 1 2 0 3 0 3
c)Output函数表
i output(i)
2 {he}
5 {she, he}
7 {his}
9 {hers}
下面开始匹配,原串"ushers"
起始状态为0;g(s, a) == fail表示失配

伪代码:
设原串为a1a2...an
begin
state <- 0
for i <- 1 until n do
begin
while g(state, ai)==fail do state <- f(state)
state <- g(state, ai)
if output(state) != empty then
begin
print i
print output(state)
end
end
end
三、 Goto函数、 Failure函数以及Output函数的构造
a) Goto函数
/** Goto 函数的构造
* 输入: 模式串组{y1, y2, ..., yk}
* 输出: g函数 和 部分构造的output函数
* 方法: 当s赋初值时, output(s) == empty
* 当a没有被定义,或是g(s, a)没有被定义时, g(s, a) == fail
*
*/
begin
newstate <- 0
for i <- 1 until k do entry(yi)
/* 起始状态的fail都置0 */
for all a (maybe a, b, c, ..., z) such that g(0, a) == fail do g(0, a) <- 0
end
procedure enter(a1a2...am):
begin
state <- 0; j <- 1
while g(state, aj) != fail
begin
state <- g(state, aj)
j <- j+1
end
for p <- j until m do
begin
newstate <- newstate + 1
g(state, ap) <- newstate
state <- newstate
end
output (state) <- {a1a2...am}
end
b) Failure函数构造
/** Failure函数构造
* 输入: goto函数 以及 部分构造的output函数
* 输出: failure函数 和 output函数
*
**/
begin
queue <- empty
/* 第一层的failure函数值置0 */
for each a such that g(0, a) == s !=0 do
begin
queue <- queue ∪ {s}
f(s) <- 0
end
while queue != empty do
begin
/* 从队列中取出一个元素r */
let r be the next state in queue
queue <- queue - {r}
for each a such that g(r, a) == s != fail do
begin
queue <- queue ∪ {s}
state <- f(r)
while g(state, a) == fail do state <- f(state)
f(s) <- g(state, a)
output(s) <- output(s) ∪ output (f(s))
end
end
end
四、非确定有限状态自动机确定化
在AC流程中,当g(r, a) == fail时, 可能需要查询多次Failure表,像这样的不确定给识别带来的反复,无疑会影响自动机工作的效率。
参考:《Efficient String Matching: An Aid to Bibliographic Search》
在AC流程中,当g(r, a) == fail时, 可能需要查询多次Failure表,像这样的不确定给识别带来的反复,无疑会影响自动机工作的效率。
/** 构造确定有限状态自动机
* 输入: goto函数 和 failure函数
* 输出: 下一步跳转函数δ函数
**/
begin
queue <- empty
for each symbol a do
begin
δ(0, a) <- g(0, a)
if g(0, a) != 0 then queue <- queue ∪ {g(0, a)}
end
while queue != empty do
begin
let r be the next state in queue
queue <- queue - {r}
for each symbol a do
if g(r, a) ==s != fail do
begin
queue <- queue ∪ {s}
δ(r, a) <- s
end
else
δ(r, a) <- δ(f(r), a)
end
end参考:《Efficient String Matching: An Aid to Bibliographic Search》















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









