







MapReduce
概念
- MapReduce是一种可用于数据处理的编程模型。MapReduce程序本质上是并行运行的,MapReduce的优势在于处理大规模数据集(高并行)。
- MapReduce的任务过程分为两个阶段:map 阶段和 reduce 阶段。每个阶段都以自定义类型的K-V(K可以重复)对作为 input 和 outout ,重点是,需要我们自己实现map 和reduce 函数。
- 数据来源:HDFS, 关系型数据库,非关系型数据库等都可作为数据的来源。
- 切片:
- split(数据源),面向文件逻辑上的数据划分片,区别于hdfs切块,默认等于block的块大小,窗口机制,大小可以人为控制,并行度取决于切片的大小。为了计算向数据移动打下基础。
- 能定位到block的offset,split的偏移量一定在block内。
- map的数量取决于split的数量。同时split规定了map读取数据量
- reduce 数量取决于你的需求的结果(数据倾斜问题,10种key,一key数据量大,9key数据量小,2个reduce(1reduce处理大数据量,1reduce处理剩余9个)) (处理时间取决于数据倾斜最严重的那一台机器)
- MR 元语
相同的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
不同的key在分区(partition):相同的key分组- 为什么要有排序?
为了保证相同的key调用一次reduce
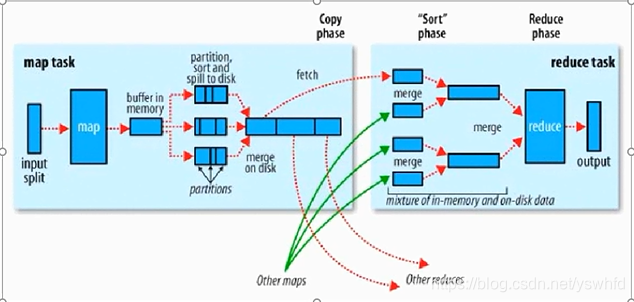
- shuffler
- 框架内部实现机制
- 分布式计算节点数据流转,连接MapTask 和 ReduceTask















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









