






卷积神经网络(Convolutional Neural Networks, CNNs)是深度学习中用于处理具有网格结构数据(如图像、视频等)的一种特殊类型的神经网络。
1.卷积
卷积操作是CNN的核心部分,它通过滑动一个小型矩阵(称为卷积核或滤波器)在输入数据上,从而提取局部特征。卷积核(也称为滤波器或权重矩阵)是卷积神经网络(CNN)中非常重要的组成部分。它决定了如何从输入数据中提取特征。
什么是卷积核?
卷积核是一个小的矩阵(通常是3x3、5x5等),它在输入数据上滑动,并通过计算加权和来生成新的特征图。每个卷积核都有自己的权重,这些权重在训练过程中会不断调整以优化模型性能。
卷积核的作用
卷积核的主要作用是从输入数据中提取局部特征。不同的卷积核可以捕捉不同的特征,例如边缘、纹理、形状等。通过堆叠多个卷积层,CNN能够逐步提取出更复杂和高层次的特征。
什么是卷积?
想象你有一张图片,这张图片是由许多小方块组成的网格(像素)。每个小方块都有一个颜色值。卷积是一种操作,它通过一个小窗口(称为卷积核或滤波器)在图像上滑动,并在每个位置计算出一个新的值。这个新的值是基于窗口内所有像素的加权和。
特征图大小计算公式:N =( W - F + 2P)/ 2 +1
注意:除不尽就向下取整
假设:
-
图像大小: 5 x 5
-
卷积核大小: 3 x 3
-
Stride: 1
-
Padding: 1
-
(5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为: 5 x 5
API:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels: 输入通道数(如RGB图像的3个通道)
out_channels: 输出通道数(即卷积核的数量)
kernel_size: 卷积核大小(可以是单个整数或元组)
stride: 步长(默认为1)
padding: 填充(默认为0)
案例:
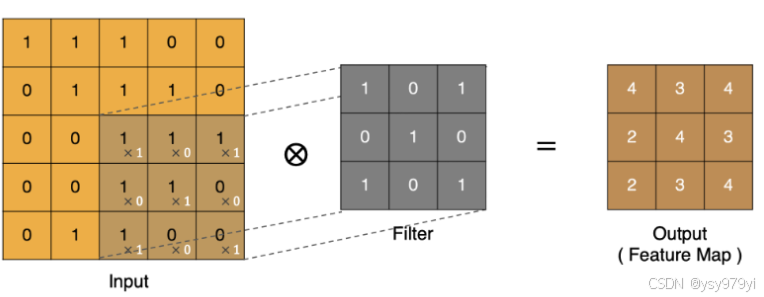
import torch
img = torch.tensor([[[[1,1,1,0,0],
[0,1,1,1,0],
[0,0,1,1,1],
[0,0,1,1,0],
[0,1,1,0,0]]]], dtype=torch.float32)
weight = torch.tensor([[[[1,0,1],
[0,1,0],
[1,0,1]]]],dtype=torch.float32)
conv = torch.nn.Conv2d(1, 1, kernel_size=3, stride=1, padding=0, bias=False)
conv.weight.data = weight
output = conv(img)
print(output)
2.池化
池化操作用于降低特征图的空间维度,常见的池化方法有最大池化(Max Pooling)和平均池化(Average Pooling)。
-
最大池化:选择每个池化区域中的最大值。
-
平均池化:计算每个池化区域中的平均值。
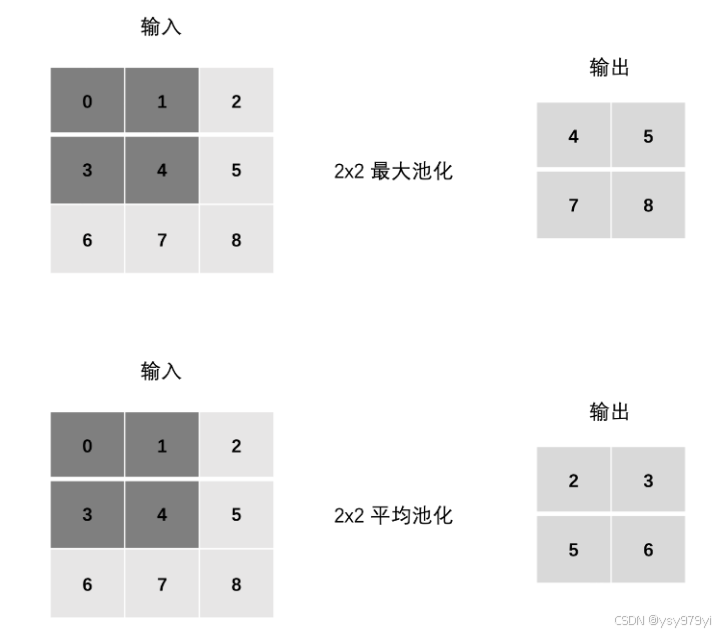
API:
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
-
kernel_size: 池化窗口大小。 -
stride: 步长(通常等于池化窗口大小)。
3.反卷积
反卷积,也叫转置卷积。
卷积是对输入图像及进行特征提取,这样会导致尺寸会越变越小,而反卷积是进行相反操作。并不会完全还原到跟输入图一样,只是保证了与输入图像尺寸一致,主要用于向上采样。从数学上看,反卷积相当于是将卷积核转换为稀疏矩阵后进行转置计算,故也被称为转置卷积。
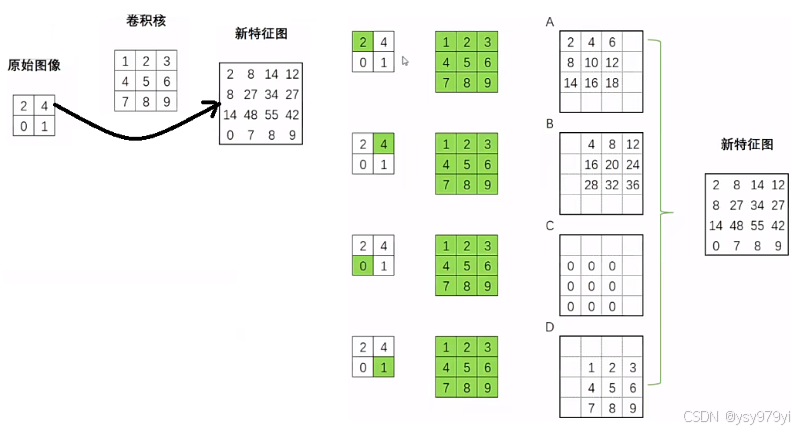
原始图像被卷一次:
API:
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
案例:
import torch
import torch.nn as nn
#x.shape=(1, 1, 2, 2)
x = torch.tensor([[[[2., 4],
[0 , 1]]]])#h.shape=(1,1, 3, 3)
h = torch.tensor([[[[1., 2, 3],
[4, 5, 6],
[7, 8, 9]]]])conv1 = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, bias=False)
conv1.weight = nn.Parameter(h)x = conv1(x)
print(x)
# tensor([[[[ 2., 8., 14., 12.],
# [ 8., 27., 34., 27.],
# [14., 48., 55., 42.],
# [ 0., 7., 8., 9.]]]], grad_fn=<ConvolutionBackward0>)
卷积与反卷积的区别:
转置卷积层的卷积㧡往往是偶数。这与传统卷积层有较大的区别。传统卷积层中如果使用偶数卷积核,则会导致图像偏移问题,而转置卷积由于是"无中生有”,因此不会存在图像偏移的情况。


4.可分离卷积
4.1 空间可分离卷积
空间间可分离卷积(Spatial Separable Convolution)是一种将标准二维卷积操作拆分为两个一维卷积操作的技术。这种技术主要用于减少计算复杂度和参数数量,同时尽量保持模型的特征提取能力。下面详细介绍空间可分离卷积的作用及其优势。
4.2 深度可分离卷积
深度可分离卷积(Depthwise Separable Convolution)是一种优化的卷积操作,旨在减少标准卷积层的计算成本和参数数量。它通常用于移动设备和其他资源受限环境中的高效神经网络架构中,如MobileNet、Xception等。
深度可分离卷积将一个完整的卷积操作分解为两个步骤:
深度卷积(Depthwise Convolution):
在这一步骤中,每个输入通道独立地应用一个卷积核。也就是说,如果有N个输入通道,那么就会有N个卷积核,每个卷积核只处理对应的单个输入通道,并生成一个对应的输出特征图。
这种方式不会改变特征图的深度(即通道数),但可以有效地捕捉每个输入通道的空间信息。
逐点卷积(Pointwise Convolution):
在深度卷积之后,使用1x1大小的卷积核对上一步得到的所有特征图进行线性组合,以增加或减少特征图的数量。1x1卷积本质上是在不同的通道之间进行信息融合,从而实现特征映射的维度变换。通过这种方式,深度可分离卷积减少了模型需要学习的参数数量和计算量。
具体来说,假设输入特征图的尺寸是H×W×D,其中H和W分别是高度和宽度,D是深度(即通道数)。如果使用标准卷积来生成K个滤波器输出,滤波器大小为F×F,那么计算复杂度大约是:
标准卷积:H×W×D×K×F×F
而深度可分离卷积的计算复杂度则是:
深度卷积:H×W×D×F×F
逐点卷积:H×W×D×K
因此,总的计算量是两者之和,相比于标准卷积显著降低。虽然这种分解可能会略微影响模型的表现力,但是通过合理设计网络结构,可以在保持较高准确率的同时大幅提高效率。这使得深度可分离卷积成为构建轻量化网络的理想选择。
5.分组卷积
2012年,AlexNet论文中最先提出来的概念,当时主要为了解决GPU显存不足问题,将卷积分组放到两个GPU中并行执行。
在分组卷积中,卷积核被分成不同的组,每组负责对相应的输入层进行卷积计算,最后再进行合并。
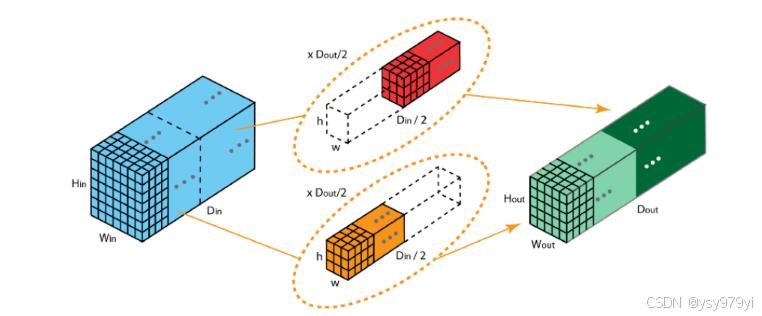
分组卷积有如下几个优势:
第一个优势是训练的高效性。
第二个优势是模型更加高效,例如,当过滤器组数增加时,模型参数就会减少。在前一个案例中,在标准的 2D 卷积中,过滤器有 h x w x Din x Dout 个参数,而在拆分为 2 个过滤器组的分组卷积中,过滤器仅有 (h x w x Din/2 x Dout/2) x 2 个参数:参数数量减少了一半。

















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









