







首先找到爬取网站
https://beijing.qfang.com/newhouse/list/n1
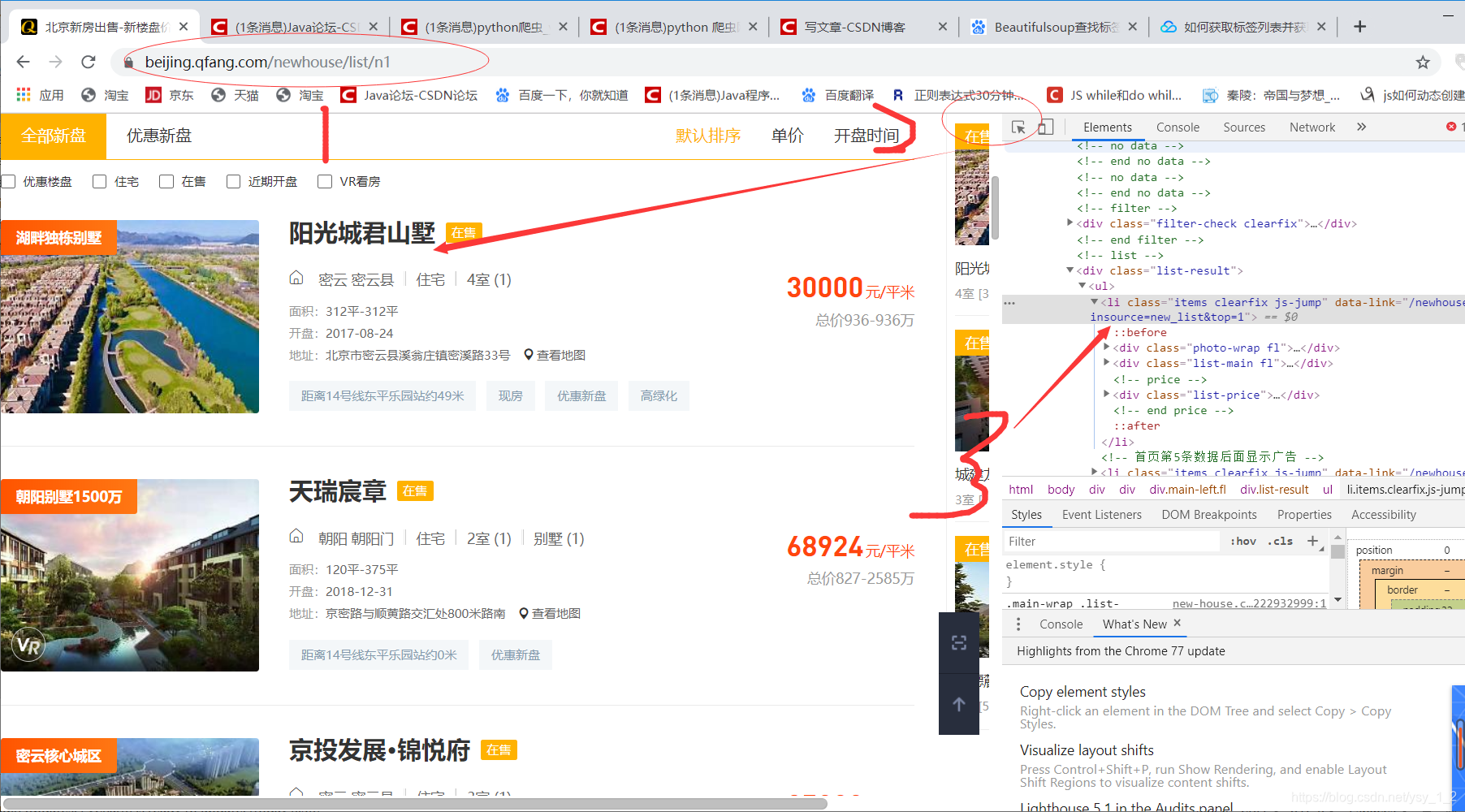
箭头点击,XPath下来你的要爬取的信息
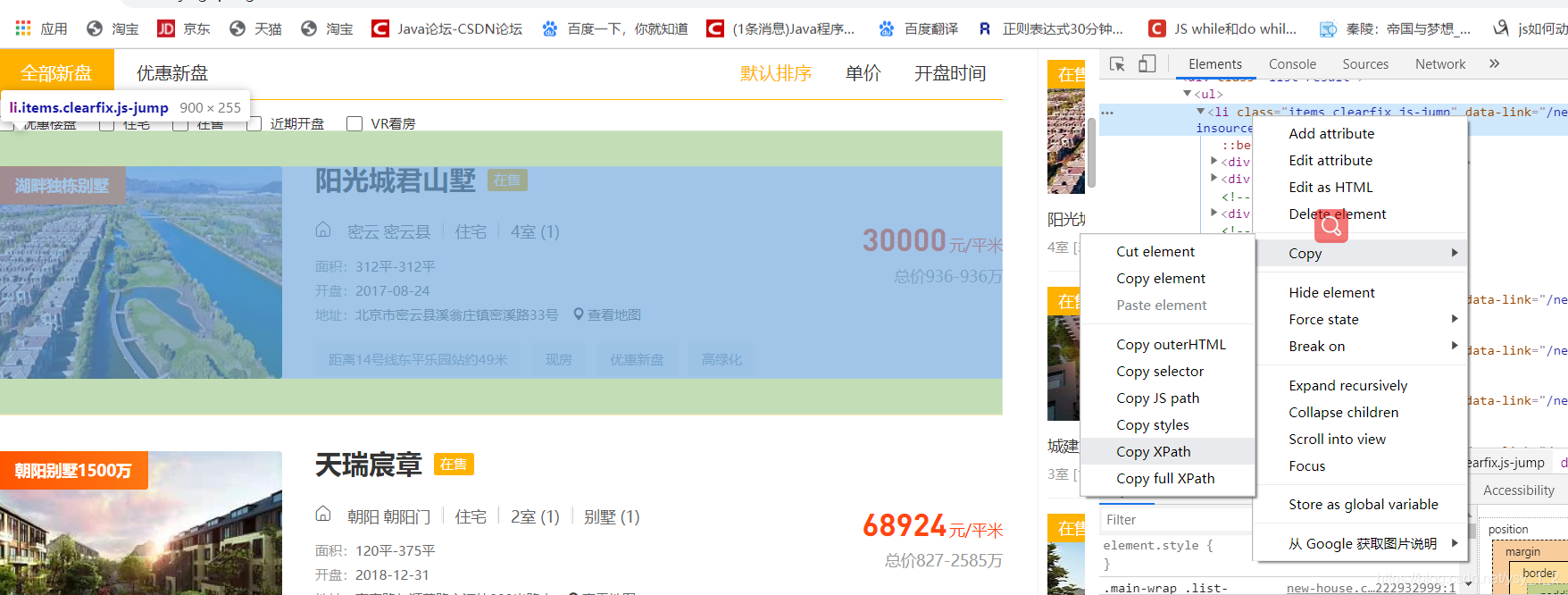
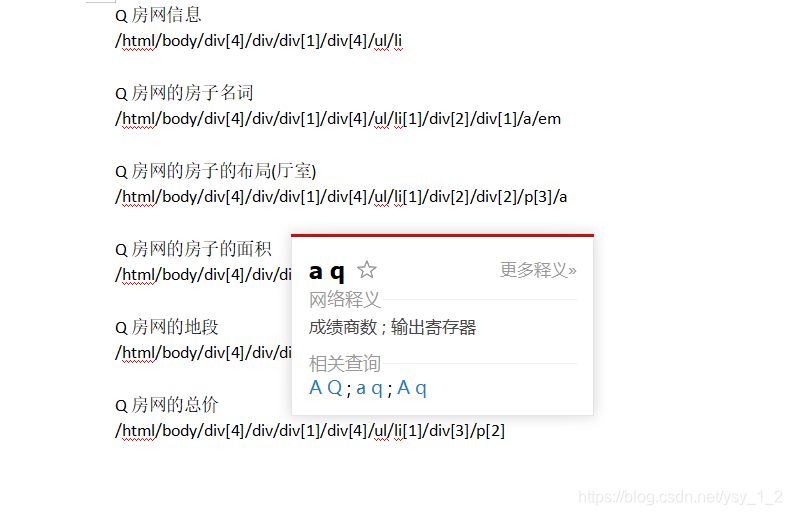
把你要爬取的信息记录下来
写入代码
from lxml import etree
import requests
import csv
import time
#写一个函数
# def writecsv(item):
# with open('qfang.csv','a',encoding= 'utf-8') as f:
# write=csv.writer(f)
# #防止出错
# try:
# write.writerow(item)
# except:
# print('write error!')
if __name__ =='__main__':
headers ={'user-Agent':'Mozilla/5.0'}
start_url="https://beijing.qfang.com/newhouse/list/n"
for x in range(1,9):
url =start_url+str(x)
#获取网址
html =requests.get(url,headers=headers)
#不能频繁获取请求
time.sleep(1)
#构造一个选择器,把文本源代码传给它
selector= etree.HTML(html.text)
xiaoqulist =selector.xpath('/html/body/div[4]/div/div[1]/div[4]/ul/li')
#循环迭代
for xiaoqu in xiaoqulist:
try:
mingcheng =xiaoqu.xpath('div[2]/div[1]/a/em/text()')[0]
layout=xiaoqu.xpath('div[2]/div[2]/p[3]/a/text()')[0]
area=xiaoqu.xpath('div[2]/div[3]/p[1]/text()')[0]
place=xiaoqu.xpath('div[2]/div[3]/p[3]/text()')[0]
money=xiaoqu.xpath('div[3]/p[2]/text()')[0]
except IndexError as a:
print(" ")
# #构造一个list
#item =[mingcheng,layout,area,place,money]
# #写一个函数
#writecsv(item)
#保存就print
print('正在抓取:',mingcheng,layout,area,place,money)
你要爬取的信息
















 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









