






希尔排序(Shell Sort)
1959年Shell发明,第一个突破O(n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序,该方法实质上是一种分组插入方法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
比较相隔较远距离(称为增量)的数,使得数移动时能跨过多个元素,则进行一次比较就可能消除多个元素交换。D.L.shell于1959年在以他名字命名的排序算法中实现了这一思想。算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
一般的初次取序列的一半为增量,以后每次减半,直到增量为1。但这样的增量序列并不是最优的,有兴趣可以搜索了解下。
算法描述
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
动图演示
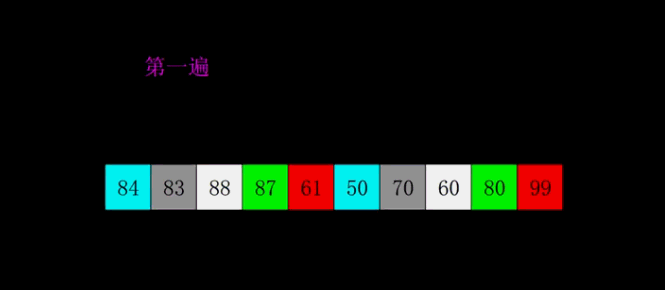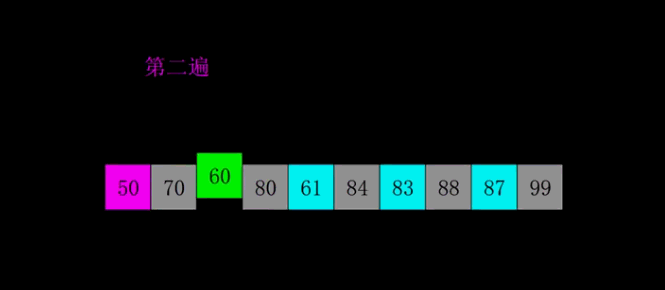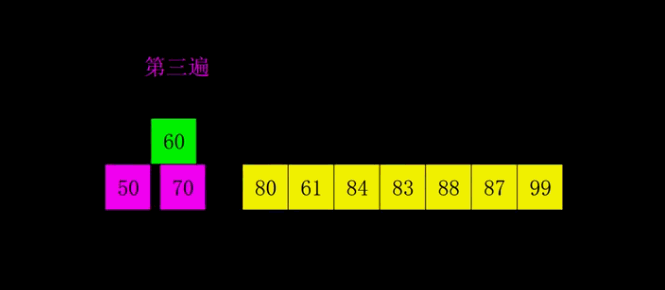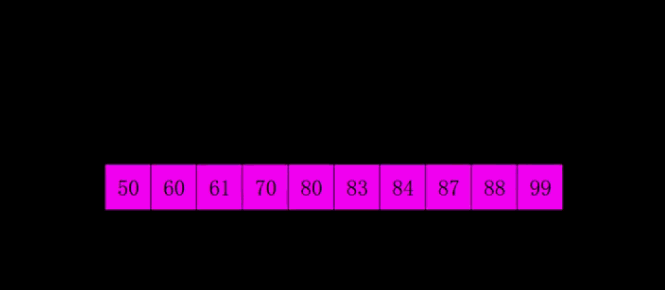
代码实现
上面的动图每一遍都是先按照增量分好组,然后再分别对每个分组执行插入操作,实际代码操作是多个分组交替执行插入的。
void shellSort(vector<int> &v)
{
int size = v.size();
for (int gap = size / 2; gap > 0; gap = gap / 2) {
// 注意:这里和动图演示的不一样,动图是分组执行,实际代码操作是多个分组交替执行插入
for (int i = gap; i < size; ++i) {
int j = i;
int tmp = v[i];
while (j - gap >= 0 && tmp < v[j - gap]) {
v[j] = v[j - gap];
j = j - gap;
}
v[j] = tmp;
}
}
}算法分析
希尔排序的核心在于增量序列的设定。既可以提前设定好增量序列,也可以动态的定义增量序列。动态定义增量序列的算法是《算法(第4版)》的合著者Robert Sedgewick提出的。需要大量的辅助空间,和归并排序一样容易实现。希尔排序是基于插入排序的一种算法, 在此算法基础之上增加了一个新的特性,提高了效率。希尔排序的时间复杂度为,希尔排序时间复杂度的下界是n*log2n。希尔排序没有快速排序算法快 O(nlogn),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(n2)复杂度的算法快得多。并且希尔排序非常容易实现,算法代码短而简单。此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。
















 4050
4050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









