







On Sunday, May 5th, I received an email from a person claiming to have access to a massive leak of API documentation from inside Google’s Search division. The email further claimed that these leaked documents were confirmed as authentic by ex-Google employees, and that those ex-employees and others had shared additional, private information about Google’s search operations.
5 月 5 日星期日,我收到了一封来自某人的电子邮件,该人声称可以访问 Google 搜索部门内部大量泄露的 API 文档。该电子邮件进一步声称,这些泄露的文件已被前谷歌员工确认为真实的,并且这些前员工和其他人分享了有关谷歌搜索业务的额外私人信息。
Many of their claims directly contradict public statements made by Googlers over the years, in particular the company’s repeated denial that click-centric user signals are employed, denial that subdomains are considered separately in rankings, denials of a sandbox for newer websites, denials that a domain’s age is collected or considered, and more.
他们的许多主张直接与谷歌员工多年来的公开声明相矛盾,特别是该公司一再否认采用以点击为中心的用户信号,否认在排名中单独考虑子域名,否认为新网站提供沙箱,否认域的年龄被收集或考虑等等。
Naturally, I was skeptical. The claims made by this source (who asked to remain anonymous) seemed extraordinary–claims like:
自然,我对此表示怀疑。该消息来源(要求保持匿名)的说法似乎非同寻常,例如:
- In their early years, Google’s search team recognized a need for full clickstream data (every URL visited by a browser) for a large percent of web users to improve their search engine’s result quality.
早年,Google 的搜索团队认识到大部分网络用户需要完整的点击流数据(浏览器访问的每个 URL),以提高搜索引擎的结果质量。 - A system called “NavBoost” (cited by VP of Search, Pandu Nayak, in his DOJ case testimony) initially gathered data from Google’s Toolbar PageRank, and desire for more clickstream data served as the key motivation for creation of the Chrome browser (launched in 2008).
一个名为“NavBoost”的系统(由搜索副总裁 Pandu Nayak 在他的司法部案件证词中引用)最初从 Google 工具栏 PageRank 收集数据,对更多点击流数据的渴望成为创建 Chrome 浏览器(于 2017 年推出)的关键动机。 2008)。 - NavBoost uses the number of searches for a given keyword to identify trending search demand, the number of clicks on a search result (I ran several experiments on this from 2013-2015), and long clicks versus short clicks (which I presented theories about in this 2015 video).
NavBoost 使用给定关键字的搜索次数来识别趋势搜索需求、搜索结果的点击次数(我从 2013 年到 2015 年对此进行了多次实验)以及长点击与短点击(我在这个2015年的视频)。 - Google utilizes cookie history, logged-in Chrome data, and pattern detection (referred to in the leak as “unsquashed” clicks versus “squashed” clicks) as effective means for fighting manual & automated click spam.
谷歌利用 cookie 历史记录、登录的 Chrome 数据和模式检测(在泄漏中称为“未压缩”点击与“压缩”点击)作为对抗手动和自动点击垃圾邮件的有效手段。 - NavBoost also scores queries for user intent. For example, certain thresholds of attention and clicks on videos or images will trigger video or image features for that query and related, NavBoost-associated queries.
NavBoost 还对用户意图的查询进行评分。例如,特定的注意力阈值以及对视频或图像的点击将触发该查询以及相关的、与 NavBoost 相关的查询的视频或图像特征。 - Google examines clicks and engagement on searches both during and after the main query (referred to as a “NavBoost query”). For instance, if many users search for “Rand Fishkin,” don’t find SparkToro, and immediately change their query to “SparkToro” and click SparkToro.com in the search result, SparkToro.com (and websites mentioning “SparkToro”) will receive a boost in the search results for the “Rand Fishkin” keyword.
Google 在主查询期间和之后检查搜索的点击次数和参与度(称为“NavBoost 查询”)。例如,如果许多用户搜索“Rand Fishkin”,但没有找到 SparkToro,并立即将其查询更改为“SparkToro”并在搜索结果中单击 SparkToro.com,SparkToro.com(以及提及“SparkToro”的网站)将“Rand Fishkin”关键字的搜索结果增加。 - NavBoost’s data is used at the host level for evaluating a site’s overall quality (my anonymous source speculated that this could be what Google and SEOs called “Panda”). This evaluation can result in a boost or a demotion.
NavBoost 的数据在主机级别用于评估网站的整体质量(我的匿名消息来源推测这可能是 Google 和 SEO 所说的“熊猫”)。此评估可能会导致升职或降职。 - Other minor factors such as penalties for domain names that exactly match unbranded search queries (e.g. mens-luxury-watches.com or milwaukee-homes-for-sale.net), a newer “BabyPanda” score, and spam signals are also considered during the quality evaluation process.
其他次要因素,例如对与非品牌搜索查询完全匹配的域名(例如 mens-luxury-watches.com 或 milwaukee-homes-for-sale.net)的处罚、较新的“BabyPanda”分数以及垃圾邮件信号也会在评估过程中予以考虑。质量评估过程。 - NavBoost geo-fences click data, taking into account country and state/province levels, as well as mobile versus desktop usage. However, if Google lacks data for certain regions or user-agents, they may apply the process universally to the query results.
NavBoost 地理围栏点击数据,考虑国家和州/省级别,以及移动设备与桌面设备的使用情况。然而,如果谷歌缺乏某些地区或用户代理的数据,他们可能会将该过程普遍应用于查询结果。 - During the Covid-19 pandemic, Google employed whitelists for websites that could appear high in the results for Covid-related searches
在 Covid-19 大流行期间,Google 对可能出现在 Covid-19 相关搜索结果中较高位置的网站采用了白名单 - Similarly, during democratic elections, Google employed whitelists for sites that should be shown (or demoted) for election-related information
同样,在民主选举期间,谷歌对应显示(或降级)选举相关信息的网站采用了白名单
And these are only the tip of the iceberg.
而这些只是冰山一角。
Extraordinary claims require extraordinary evidence. And while some of these overlap with information revealed during the Google/DOJ case (some of which you can read about on this thread from 2020), many are novel and suggest insider knowledge.
非凡的主张需要非凡的证据。虽然其中一些信息与 Google/DOJ 案件中披露的信息重叠(其中一些信息您可以在 2020 年的此帖子上阅读),但许多信息都很新颖,暗示了内幕知识。
So, this past Friday, May 24th (following several emails), I had a video call with the anonymous source.
因此,上周五,即 5 月 24 日(在发送了几封电子邮件之后),我与匿名消息人士进行了视频通话。
An anonymized screen capture from Rand’s call with the source
兰德与消息来源通话的匿名屏幕截图
Update (5/28 at 10:00am Pacific): The anonymous source has decided to come forward. This video announces their identity, Erfan Azimi, an SEO practitioner and the founder of EA Eagle Digital.
更新(太平洋时间 5 月 28 日上午 10:00):匿名消息人士决定挺身而出。这段视频公布了他们的身份,Erfan Azimi,一名 SEO 从业者,也是 EA Eagle Digital 的创始人。
Prior to the email and call, I had neither met nor heard of Erfan. He asked that his identity remain veiled, and that I merely include the quote below:
在发电子邮件和打电话之前,我既没有见过也没有听说过埃尔凡。他要求保密他的身份,我只引用以下内容:
An eagle uses the storm to reach unimaginable heights.
老鹰利用风暴达到难以想象的高度。
– Matshona Dhliwayo – 马绍纳·迪利瓦约
After the call I was able to confirm details of Erfan’s work history, mutual people we both know from the marketing world, and several of their claims about being at particular events with industry insiders (including Googlers), though I cannot confirm details of the meetings nor the content of discussions they claim to have had.
通话结束后,我确认了 Erfan 的工作经历、我们在营销界共同认识的人以及他们关于与业内人士(包括 Google 员工)参加特定活动的一些说法,但我无法确认会议的详细信息也没有他们声称进行过的讨论的内容。
During our call, Erfan showed me the leak itself: more than 2,500 pages of API documentation containing 14,014 attributes (API features) that appear to come from Google’s internal “Content API Warehouse.” Based on the document’s commit history, this code was uploaded to GitHub on Mar 27, 2024th and not removed until May 7, 2024th. (Note: because this piece was, post-publishing, edited to reflect Erfan’s identity, he’s referred to below as “the anonymous source”).
在我们的通话中,Erfan 向我展示了泄漏本身:超过 2,500 页的 API 文档,其中包含 14,014 个属性(API 功能),这些属性似乎来自 Google 的内部“Content API 仓库”。根据文档的提交历史记录,该代码于 2024 年 3 月 27 日上传到 GitHub,直到 2024 年 5 月 7 日才被删除。 (注:由于这篇文章在出版后经过编辑以反映埃尔凡的身份,因此他在下面被称为“匿名来源”)。
This documentation doesn’t show things like the weight of particular elements in the search ranking algorithm, nor does it prove which elements are used in the ranking systems. But, it does show incredible details about data Google collects. Here’s an example of the document format:
本文档没有显示搜索排名算法中特定元素的权重之类的内容,也没有证明排名系统中使用了哪些元素。但是,它确实显示了谷歌收集的数据的令人难以置信的细节。以下是文档格式的示例:

Screen capture of leaked data about “good” and “bad” clicks, including length of clicks (i.e. how long a visitor spends on a web page they’ve clicked from Google’s search results before going back to the search results)
关于“好”和“坏”点击的泄露数据的屏幕截图,包括点击时长(即访问者在返回搜索结果之前在从 Google 搜索结果中点击的网页上花费了多长时间)
After walking me through a handful of these API modules, the source explained their motivations (around transparency, holding Google to account, etc.) and their hope: that I would publish an article sharing this leak, revealing some of the many interesting pieces of data it contained, and refuting some “lies” Googlers “had been spreading for years.”
在向我介绍了其中一些 API 模块后,消息来源解释了他们的动机(围绕透明度、让 Google 承担责任等)以及他们的希望:我会发表一篇文章来分享此漏洞,揭示其中一些有趣的部分其包含的数据,并驳斥了谷歌员工“多年来一直传播的一些“谎言”。
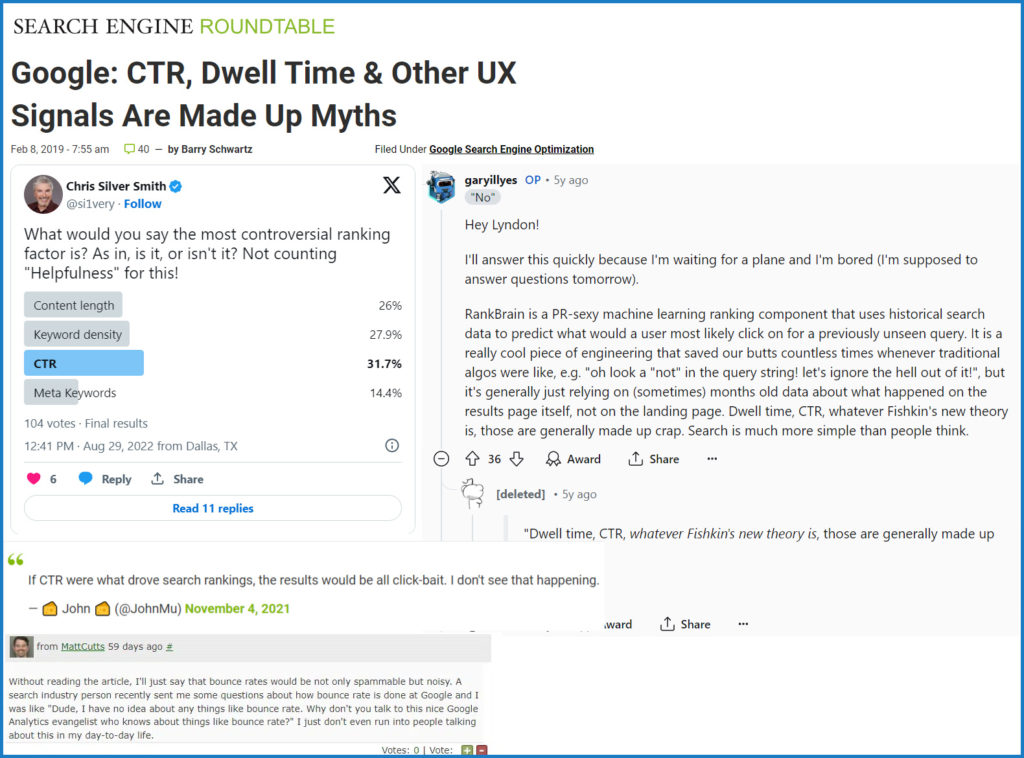
A sample of statements from Google representatives (Matt Cutts, Gary Ilyes, and John Mueller) denying the use of click-based user signals in rankings over the years
Google 代表(Matt Cutts、Gary Ilyes 和 John Mueller)否认多年来在排名中使用基于点击的用户信号的声明样本
Is this API Leak Authentic? Can We Trust It?
此 API 泄漏是真实的吗?我们可以相信它吗?
A critical next step in the process was verifying the authenticity of the API Content Warehouse documents. So, I reached out to some ex-Googler friends, shared the leaked docs, and asked for their thoughts. Three ex-Googlers wrote back: one said they didn’t feel comfortable looking at or commenting on it. The other two shared the following (off the record and anonymously):
该过程中关键的下一步是验证 API 内容仓库文档的真实性。 因此,我联系了一些前 Google 员工朋友,分享了泄露的文档,并询问了他们的想法。三名前谷歌员工回信说:其中一人表示,他们对看到或评论这件事感到不舒服。另外两人分享了以下内容(非正式且匿名):
- “I didn’t have access to this code when I worked there.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











