







不同分库表递增
db0
├── t_order0
└── t_order1
db1
├── t_order2
└── t_order3
业务中,有这样的表分布,
库算法:Math.abs(sell_id.hashCode()%2)
表算法:Math.abs(sell_id.hashCode()%4)
分片算法是hash,插入以下值:
库 - 表:值
db0 - t_order0 : 1001
db0 - t_order1 : 2311
db1 - t_order2 : 2312
db1 - t_order3 : 2313
这时如果利用分片键进行IN查询,比如:
select * from t_order where t_id in (1001, 2313);
也就是说,取db0 - t_order0 : 1001和db1 - t_order3 : 2313这2条记录,按说应该能正常得到结果,但事实是,会报错。
原因:
我们来看源码,io.shardingsphere.core.routing.type.standard.StandardRoutingEngine
路由
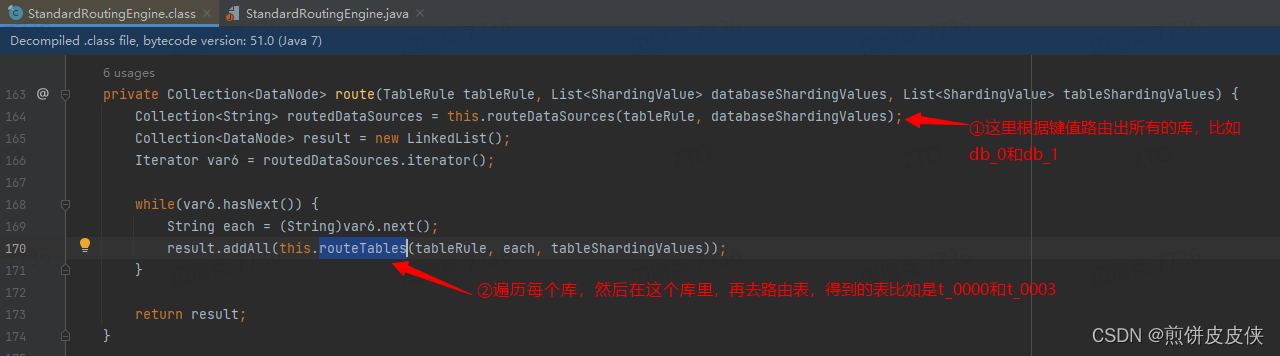
路由数据源

路由表

通过我红色的注解,应该可以清楚的看到问题的所在,db_0里根本就不存在t_0003这张表,同样db_1里也不存在t_0000这张表呀,所以此时执行
select * from t_order where t_id in (1001, 2313);
自然会报db_0.t_0003不存在的错误。
从以上源码来看,如果要解决这个错误,也很容易呀,

所以,不解为啥shardingjdbc团队,为什么没有这么支持???
以上问题,如果表分布是以下这样的,那完全不会出现上面的问题,原因嘛,通过以上的讲解,应该很容易理解吧。
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
库不从0开始
比如我的库表结构是这样的。
db1
├── t_order0
└── t_order1
db2
├── t_order0
└── t_order1
分片算法,还是以上的算法,那我路由出来的库肯定是从0开始的呀,分别会路由到db_00,db_01,面对这种情况,有个很巧妙的办法,我只要在配数据源的时候,将数据源和数据库对应起来就好,如下:
ds_00 --> db1
db_01 --> db2
如此,不管你的库是从几开始,都无所谓。















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









