






在工作中,发现starrocks建表语句中必须指定分桶键,对比比较熟悉的hive,很疑惑,明明是在分区的基础上才会分桶,在starrocks里为什么可以直接不分区而分桶,在网上没找到答案,看了官方文档明白了:数据分布 @ Data_distribution @ StarRocks Docs
总结一句话:在starrocks中,是使用hash算法来分桶得出的tablet来进行数据备份的,故建表时必须指定分桶键
下文简洁说原因:
1、存储:
- 在starrocks一张table会被拆成多个Tablet来存
-
这些Tablet又会在多个BE中存多个副本,来保证数据的高可靠
-
具体原理:
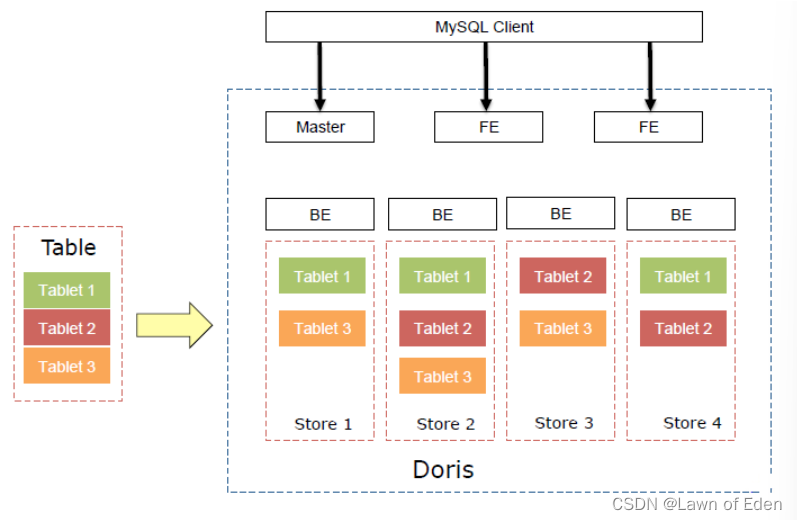
故:
-
tablet是starrocks中是数据均衡和恢复的最⼩单位
-
数据导入和查询最终都下沉到所涉及的 Tablet 副本上
2、数据分布
在starrocks中有两种数据分布方式:
-
Hash 数据分布方式:一张表为一个分区,分区按照分桶键和分桶数量进一步进行数据划分。——不分区只分桶
-
Range+Hash 数据分布方式:一张表拆分成多个分区,每个分区按照分桶键和分桶数量进一步进行数据划分。——分区+分桶
其中:
- sr中分桶算法是hash算法,即将有相同分桶键的哈希值的数据存到一个tablet里
- 又是按照tablet来在BE备份,来存储
- 所以sr建表必须指定分桶键
(在sr中仍是分区比分桶范围更大,只不过对比hdfs,hdfs是按文件存,不分区,就存储整个文件,而sr是按照更细粒度的tablet来存)















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









